0. はじめに
0.1 はじめに
2020年7月28日から8月7日にわたって開かれたUSENIX OpML 2020 の発表とその資料を見てみました。24件あるので、一件(1時間ぐらい)ペースでわかる範囲でまとめました。このため、私の瞬発力でわかる範囲しか記載していません。
また、USENIXの頁には、USENIXを支援してねとあります。そして、slack等の議論に入るためには、USENIXの会員であることが必要です。システム研究の発表の場を応援したい場合、会員になりましょう。
Open Access Media
USENIX is committed to Open Access to the research presented at our events. Papers and proceedings are freely available to everyone once the event begins. Any video, audio, and/or slides that are posted after the event are also free and open to everyone. Support USENIX and our commitment to Open Access.
0.2 概要
OSSとして使えるか、それともOSSを活用して構築したかの観点で分けると、以下のような分類になるかと思う。
見ていて興味深かったのは以下のとおりである。
- 機械学習データのラベルを付与するコストにVMware(6.3)やGoogle(6.4)が言及していた。費用対効果の関係は難しいと感じた。Googleは、高コストのため直近効果が見えるところに焦点を当てたが、VMwareは多少効果が出るなら高コストにも目をつぶって開発したように見える。ある意味、会社のポリシーが出ていて面白かった。
- ベイズ最適化は、いろいろ用いられている。LinkedIn(4.2)やSigOpt(7.3)
- 障害対策では、障害修正又はユーザ教育すべきは面白い観点と思ったWallMartLabs(2.1)。また、障害が、機械学習起因とインフラ起因に分けると、後者のの方が多いという知見があり役に立ったGoogle(7.1)。
- 機械学習のワークフローに関しては、いろんな会社がシステムを構築しており、揺籃期にあるNetflix(2.2)、Intuit(5.2, 7.2)、NVIDIA(6.2)。これ以外にも、シミュレータによるワークフロー最適化等あり、しばらくはホットな分野と思った。
0.2.1. OSSで使えるもの
- NVIDIAのRAPIDS (1.2)
- IntelのAnalytics-Zoo (4.3, 4.4)
- PyTorchの配備サーバ(FlexServe)(5.1)
- NetflixのMetaflow (5.4)
- Capital Oneによるプライバシー保護ソフトの紹介(8.1)
0.2.2. 提案など
- IBMらによるDLSpec(機械学習再現のための仕様定義) (1.1)
- WallMartLabsによる障害対策 (2.1)
- NetflixによるRunway(モデルライフサイクル管理) (2.2)
- ServiceNowによるSaaS WorkflowでのAI適用の難しさ(3.1)
- HopsworksによるACIDを保持する分散データパイプライン(3.2)
- IBMらによる大規模機械学習フレームワークのトレースとシミュレーションによる運用最適化(3.3)
- ルクセンブルグ大学による説明可能性の実用化に向けた課題(3.4)
- モバイルデバイス向けの近傍探索アルゴリズムの最適化(4.1)
- Linkedinでの推薦アルゴリズムのバンディットアルゴリズムによる最適化(4.2)
- IntuitによるMLOpsフレームワークの紹介(5.2)
- Adobe Targetでの推論エンジン構築(5.3)
- メルカリによる違反商品検知(6.1)
- NVIDIAの自動運転解析プラットフォーム(6.2)
- VMwareによる性能分析プラットフォームの紹介(6.3)
- Googleによる運用自動化の紹介(6.4)
- Googleによる10年にわたる機械学習フレームワークの経験(7.1)
- IntuitによるKubernetes上の分析フレームワーク(7.2)
- SigOptによるベイズ最適化による学習の最適化(7.3)
- Facebookでの機械学習の担当者管理システム(8.2)
1. GPUを使った深層学習とデータ科学
1.1. DLSpec: A Deep Learning Task Exchange Specification

IBM研究所&イリノイ大による発表
深層学習の標準定義形式がない。このため共有、実行、再実行及び比較が難しくなっている。この問題の解決のため、我々は、DLSpecという形式を提案する。これにより、モデル、データセット、ソフトウェアおよびハードウェアの深層学習仕様の定義が可能になる。この仕様は、数百の深層学習で用いている。
なお、スライドでは、具体的なスクリプトの例などが記載されている。
1.2. End-to-End Data Science on GPUs with RAPIDS

NVIDIAによるGPU活用ライブラリの紹介
- 各種ライブラリ
- cuDF/cuIOは、pandasのGPU版であり、データ処理を含むデータロードを高速にできる。フィルタリングやCSV読み込みが10倍もしくはそれ以上になる。
- DLPack と
__cuda_array_interface__により、様々なデータ解析ソフトと、データ交換ができる。 - cuMLは、scikit-learnのGPU版である。開発中であり、ほしい機能があればリクエストしてほしい。scikit-learnをCPUで実行した場合に比べて、6倍の性能向上になる。
- xgboostは、ライブラリ自体にGPU機能が組み込まれている。CPUに比べて、最大17倍速となっている。
- cuGraphは、ページランクなどを高速化するグラフ演算ライブラリでNetworkXより100倍以上早くなる。
- OpenUCXは、InfinbandやNVLinkを介したGPUデバイスの通信を高速にできる。また、ucx-py(Pythonモジュール)を提供している。
- RAPIDSは、簡単に使い始められる。(Google Colabなど)
2. モデルのライフサイクル
2.1. Finding Bottleneck in Machine Learning Model Life Cycle
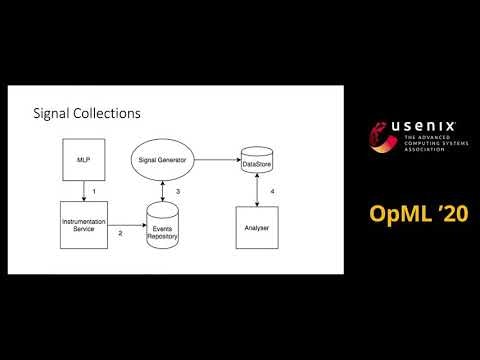
WallMartLabsによる発表であり、障害対策のやり方(修正するか、教育するか)という意味で参考になる。
MLのパイプライン構築後2年以上たっているが、いろいろと障害が出ている。
それを、分析するアナライザーを構築した。(5頁)アナライザーでは、まず、製品チームのユーザを、エキスパート、中間層、初心者の3種類に分けた。エキスパートはほとんど見ず、中間層と初心者が見るエラーは、教育訓練(ET Education & Training) が必要と判断した。そして、エキスパートを含め50%以上の人員が見たエラーは、プラットフォームの改善 (SoP Simplicity of Platform) が必要と判断した。
イベントの分類の詳細
| 分類 | エキスパート | 中間層 | 初心者 | その他 |
|---|---|---|---|---|
| SoP (システム改善) | >50 | >65 | >80 | |
| SoP (システム改善) | >50 | 週5回以上エキスパートが冗長な作業が必要なイベント | ||
| ET (教育訓練改善) | <10 | >65 | >80 | |
| ET (教育訓練改善) | <10 | >50 | >75 | 週5回以上冗長な作業が必要なイベント |
2.2. Runway - Model Lifecycle Management at Netflix
Netflixによる発表で、モデルライフサイクル管理ツール (Runway) を作った話。
Runway導入以前
- モデルを生成および利用した人がわからない。
- 既存モデルを見つける方法及び、どんなデータや特徴量が入っているモデルかがわからない。
- モデルのリリース方法が決まっていない。
- モデルの検証方法が決まっていない。
- モデルの監視および警報システムがない。
- 上記のため、計算機資源を無駄遣いする。
Runwayの現在提供している機能
- モデルに関する情報を管理し変更を追跡する機能
- 既存モデルを発見し、その関連情報を理解できるユーザインターフェース(UI)
- モデルの検証、リリース、監視および警報の定型パス
- Runwayとプログラム的に容易に連携できるSDKやクライアント
Architecture
アーキテクチャーは、以下からなり、モデルの情報を管理している。
- Java/Python SDK
- UI (React)
- WebApp (Scala, akka, Amazon Aurora)
- Batch Jobs (Spark)
3. 特徴量、説明可能性、分析
3.1. Detecting Feature Eligibility Illusions in Enterprise AI Autopilots

ServiceNow社の発表である。
SaaS業務用ワークフロー会社(SalesforceやServiceNow)は、ワークフローデータを活用したAIモデルの学習を、利用者が容易にAI適用できるようにしている。しかし、実際に、利用者が活用することは難しい。というのは、業務や運用情報とともにAIの知識が必要なためである。我々の挑戦は、どうやってそのステージに利用者を持っていくかである。
結論として、AIは、売り手市場ではない。ワークフローに対するAI適用では、AIの支援が必要な研究課題である。AIの精度だけが課題ではなく、AI適用も課題である。
3.2. Time Travel and Provenance for Machine Learning Pipelines
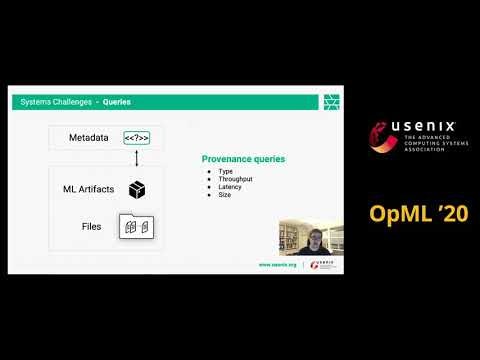
Hopsworks社の発表で、一般的にはデータパイプラインでは、データの状態を保持しない。しかし、データベースと同様に、状態を保持できるようにした話である。これのより、障害に対する復旧がより強固にできるようになった。
機械学習パイプライン(ML pipeline)は、機械学習アプリケーションの製品化の事実上のパラダイムとなっている。これにより、データから特徴量を取り出し、モデルを学習させる。データパイプラインは、一般的に、状態を持たない。このため、障害が起こった場合、再計算を行う。しかし、データベースは、状態を保持するプロトコルを持っている。近年、データパラレル処理フレームワークは、状態を保持するようになってきた(注1)。
本研究のHopsworksでは、Apache HudiをベースにHopsFSを使ってストレージを管理している。そして、Change-Data-Capture (CDC)イベントでトランザクションの同期を行っている。ML pipelineも、同様に障害に対処できる必要がある。Hopsworksでは、前述のCDCイベントで実現している。一方、他のML pipeline(注2)でも、メタデータ管理機構を持っており同様のことができる。ただし、ユーザーがプログラムする必要がある、
Hopsworksにより、インフラ側で状態を保存できるようになった。これにより、データ版数管理や時間経過確認ができるようにして、再現性やデバッグが容易にできるようにする。
- (github)logicalclocks/hopsworks
-
Implicit Provenance for Machine Learning Artifacts
- Hopsworks Provenance Architectureの紹介資料。大まかな構成図あり
- (USENIX FAST 17)HopsFS: Scaling Hierarchical File System Metadata Using NewSQL Databases
-
(github)hopshadoop/hops
- HopsFSを含むソースコード
注1:ACIDデータレークプラットフォームの例
注2:従前のML Pipeline
3.3. An Experimentation and Analytics Framework for Large-Scale AI Operations Platforms
研究者やエンジニアが、大規模AIワークフローシステムで運用戦略を考案したり、評価するためのトレースベースの実験及び分析フレームワークを説明する。IBM開発の製品レベルのAIプラットフォームによる分析データを用いて、システム及びシミュレーションモデルを構築した。合成トレースにより、パイプラインスケジューリング、クラスタリソース割り当て及びそれ以外の分析もできるようになった。
なお、分析は、SimPyというイベント分析ツールを拡張して、PipeSimを構築してシミュレートを行った。詳細は、OpMLの拡張資料(以下)に記載している。
3.4. Challenges Towards Production-Ready Explainable Machine Learning

ルクセンブルグ大学の研究で、説明可能性を実用に組み込むにあたっての教訓である。
機械学習は、いろんな組織で重用されるようになっている。機械学習のアルゴリズムは、ほぼ完全な正確性を提供するようになっているが、決定プロセスには不透明感が残る。機械学習の規制強化の観点で、医療や金融などの分野で、説明可能性は重要になっている。このため、我々は、産業パートナーと共同研究を行ってきた。本研究では、説明可能性をフレームワークを組み込む際の教訓等を紹介する。
説明には、2つの軸がある。inherentか、Post-hocか、及びLocalかGlobalかである。これにより、説明能力と識別能力の関係性、及びモデルや予測の信頼性を議論することができる。(11頁)産業界に適用する場合には、post-hocフレームワークは、local/global説明を行うことができることを考慮すべきである。(12頁)また、説明方法は、グラフ等による可視化(13頁)及びテキストの説明(14頁)の2つがある。
産業アプリケーションでは、3つの点が重要である。すなわち、データの品質、タスクやモデルの依存性、セキュリティである。
- 説明可能性フレームワークは、画像及び自然言語処理に焦点が当たっている。
- テーブル型データのデータ品質はあまり考慮されていない。このため説明可能性は下がる。
- もしテーブル型データの場合は、データ可視化を信頼する必要がある。
推奨事項は
- フレームワーク設計においては、産業のニーズをより考慮すべきである。
- 異なるデータ書式に対応した説明フレームワークの系統的なユーザ検証が必要である。
- モデル依存性は、モデル固有にするか、モデル一般として処理するかを決める。
- タスク依存性は、様々な種類の説明方法がある。
推奨方法
- タスクを実施する前に、必要な説明を明確に定義する。
- 説明フレームワークを系統的にレビューしておく
- 堅牢性があるか?例えば、モデルの理由についてアクセスできた場合、ほかのモデルを選択する攻撃することができないなど
- 新研究として、説明が提供された場合、初期のデータセットを復旧することができるか
推奨方法
- 敵対的攻撃方法をシミュレートし、大丈夫かを確認する。
- データセットを復旧できるか確認する。
4. アルゴリズム
4.1. RIANN: Real-time Incremental Learning with Approximate Nearest Neighbor on Mobile Devices

カリフォルニア大学Merced校とバージニア工科大学による発表である。
近似最近傍探索(ANN: Approximate Nearest Neighbor)は、モバイルデバイス上の多くのアプリケーションで使われる。ANNでのリアルタイムの追加学習が、伸びてきている。しかし、追加学習を現在のANNで行うことは、モバイルデバイスで短時間に処理する必要があり難しい。
我々は、モバイルデバイス向けのグラフベースANNを、索引及び検索方法として導入した。3つの改良をおこなった。
- 動的ANNグラフ構築
- 統計予測モデル(Statistical Prediction Model)
- 解析的性能推測モデル (Analytical Performance Model)
現在のグラフベースANN構築アルゴリズムは、動的なANN構築に対応していない。このため、HNSWをベースに動的ANNグラフ構築アルゴリズムを作成した。
統計予測モデルの作成は、勾配ブースティング(Gradient Bossted Dicision trees)を使って、3つのハイパーパラメータ(H)、データサイズ(B)、再現率(R)を用いて推測を行った。学習はサーバでオフラインで行う。推論はモバイルデバイスでオンラインで行う。そして、学習の手順は、合成索引データの生成、学習データの生成、損失関数により評価を繰り返すことにより行った。
解析的性能推測モデルにより、索引生成時間及び検索時間を推測した。
これらの改善を行った結果、我々のSamsung S9上の実験では、再現率(recall)や検索時間を維持したまま、デフォルトのANNに比べて2.42倍性能向上をはかることができた。
4.2. Rise of the Machines: Removing the Human-in-the-Loop

LinkedInでの様々な最適化の取り組みの解説である。
推薦通知、ニュースランキング、人の推薦、職の推薦などほとんどの大規模オンライン推薦システムは、複数の計測値をベースに最適化する必要があります。それらのパラメータ群により、ビジネス値が改善されます。これらのパラメータは、A/Bテスト等により改善が行われますが、時間がかかります。このため、バンディットアルゴリズムで最適化を行います。今回は、ベイズ最適化(のトンプソンサンプリング)を用いて処理を行った。今後の課題として、別のバンディットアルゴリズムを活用していきたいと考えている。例えば、UCB (Upper Confidence Bound Algorithm)や、EI (Expected Improvement)などを考えている。
4.3. Cluster Serving: Distributed Model Inference using Big Data Streaming in Analytics Zoo
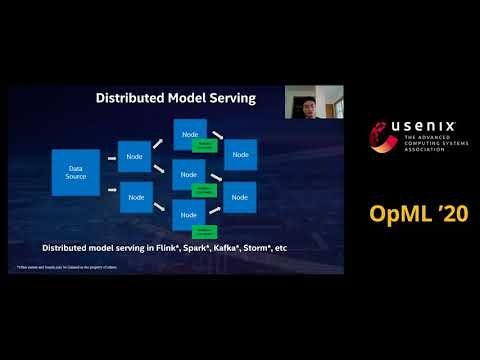
Intelの機械学習推論フレームワーク(Analytics-Zoo)の紹介である。データ分析パイプラインは、複雑であり機械学習そのものよりも、データの処理など様々な実装が大変である。そして、フレームワークは、スケーラビリティを満たす必要があり、ラップトップから分散した巨大データまで対応する必要がある。
これらの要件を満たすため、Analytics-Zooを我々は作成した。これは、BigDLでは、Sparkしか対応していないが、同ソフトでは、様々な機械学習フレームワーク(TensorFlow/PyTorch etc)に対応している。
モデルとアルゴリズムについては、推薦、時系列、コンピュータビジョン、自然言語学習を対象としている。機械学習ワークフローとしては、AutoML,及びクラスターサービングに対応している。そして、パイプラインについては、TensorFlow/PyTorch/Spark等の活用にフォーカスしている。
簡単な使い方チュートリアルは、Docker利用前提に記載している。
感想:NVIDIAのTriton Inference Serverの、Intel版ソフトに見えました。
4.4. Scalable AutoML for Time Series Forecasting using Ray

時系列予測は、様々なアプリケーションで使われている。例えば、通信業者のネットワークの品質分析、データセンター運用でのログ分析、高価値の装置のメンテナンスなどで使われている。これらの時系列予測で、機械学習や深層学習が使われる。この分析方法は、従来の方法に比べて高い性能を示している。
しかし、時系列予測を、機械学習で行うのはノウハウ等が必要である。容易に分析するために、自動機械学習(AutoML)を適用してみた。該当ツールは、UCBのRISELabの作成したRay上に作成し、ハイパーパラメータ探索等を行った。本講演では、初期ユーザーによる利用まで説明する。
まず、RayOnSparkにより、大規模インフラでの演算が可能になる。その上で、AutoTSを動いて、ハイパーパラメータ探索を行う。なお、Project Zouwuは、Analytics-zooの通信業者向け時系列予測である。Zouwuの構成要素の一つがAutoTSがあり、時系列分析パイプラインを行う。
利用例としては、以下がある。
- SKTelecomでのネットワーク品質予測
- Neusoft(中国)の(監視ソフト)RealSight APM
参考資料
- RayOnSpark: Running Emerging AI Applications on Big Data Clusters with Ray and Analytics Zoo
- Scalable AutoML for Time Series Prediction Using Ray and Analytics Zoo
5. モデル配備戦略
5.1. FlexServe: Deployment of PyTorch Models as Flexible REST Endpoints

PyTorchのモデルを配備できるフレームワークFlexServeを開発した。これにより、TensorFlowの静的グラフ等に変換することなくモデルを配備することができる。なお実装は、githubに公開している。
5.2. Managing ML Models @ Scale - Intuit’s ML Platform

(会計ソフト会社)Intuitでは、機械学習モデルは、巨大かつセンシティブなデータから作られる。このため、高いレベルのセキュリティやコンプライアンスが必要となる。Intuitの機械学習プラットフォームでは、モデルライフサイクル管理は、GitOps, SageMaker, Kubernetes及びArgo Workflowで作られている。
これらにより、200%以上の性能改善を行っている。今後とも改善を続けていく
5.3. Edge Inference on Unknown Models at Adobe Target

Adobe社のAdobe Targetにおける高スループットを実現する推論ソリューションを構築するためのノウハウを解説している。Adobeでは、エッジをJavaで動かし、データフォーマットをONNXで動かしている。もちろん、信頼性を確保するために検証を行っている。
5.4. More Data Science, Less Engineering: A Netflix Original
Netflixが開発したMLワークフローツールMetaflowの紹介講演である。
本ワークフローツールでは、以下の機能を提供している。
- Model Development
- Feature Engineering
- Versioning
- Architecture
- Job Scheduler
- Compute Resources
- Data Warehouse
参考資料
6. 実世界でのMLOps
6.1. Auto Content Moderation in C2C e-Commerce
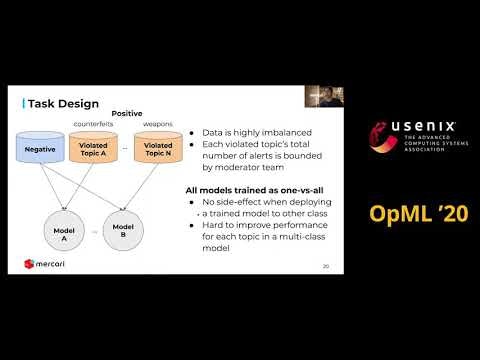
メルカリによるマルチモーダルによる違反商品検知の検出率の向上など。(日本語のプレスリリース出ているので省略)
6.2. Inside NVIDIA’s AI Infrastructure for Self-driving Cars

NVIDIAによる発表
MagLevは、NVIDIA社内の統合 (End-to-End) AIプラットフォームであり、自動運転ソフトウェア (DRIVE) の開発を目的としている。数千GPUおよび数PBのデータの解析プラットフォームを紹介する。
システムは、インフラ層、コンテナ管理層そして、アプリケーションからなる。インフラ層から説明すると、計算リソースのDGXとAWS、およびクラウドベースのVRシミュレータConstellationからなる。コンテナ管理層としては、APOLLOがあり、内部のプロビジョニングおよび、モニターシステムでありKubernetesの管理を行う。
また、WebUIとして、キュレーション(選択)UIも備えており、夜間の歩行者がいるデータをラベル付けする仕組みを備えている。
感想:1年前(参考資料2019)の発表では、ワークフローをYAMLで記載していた。しかし、今回はラベリングを見直すUIまでYAMLで定義できる(資料16頁)ようになった。いわゆるGitOpsが隅々に適用できるよう機能拡張しているように見えた。
6.3. Challenges and Experiences with MLOps for Performance Diagnostics in Hybrid-Cloud Enterprise Software Deployments
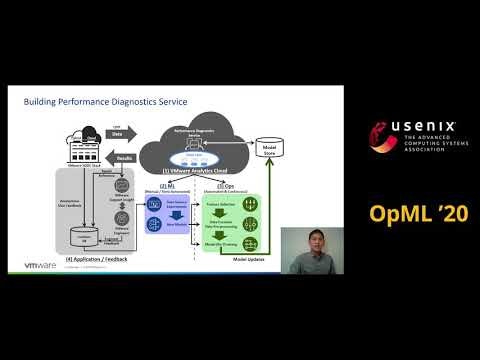
エンタープライズハイブリッドクラウド環境で、機械学習ベースの性能診断のVMwareソリューションの説明である。項目としては、データ管理、モデル提供や配備、システム性能のドリフト、モデル特長の選択、集中的なモデル学習パイプライン、適切なアラームの閾値、及び説明可能性である。また、ここ4年のエンタープライズ顧客運用の経験を紹介する。
データセンターで、性能問題を検知し原因を特定することは大変難しい。従来のルールベースの方法では限界がある。このため、VMwareでは、機械学習ベースの分析サービス(VMware Analytics Cloud)を提供している。
6.4. Automating Operations with ML

機械学習の応用例として、良く提案されるシステム運用について概括する。すなわち、1)異常検知、2)監視/警報、3)容量予測、4)セキュリティ、5)資源スケーリングである。これらについて、我々の経験に基づいて、機械学習モデルテクニックの限界を示す。また、良い結果を示すアプリケーションを紹介する。
最後に、どこに、機械学習を使えば、うまく使えるかについて言及する。
様々な研究から以下のことがわかる。
- ログからの異常検知(研究課題) 特にログ自身は、S/N比が悪いのでラベリングが難しい、
- 警報トリアージ(困難) 高品質のラベル付けが必要である。
- セキュリティ(困難) セキュリティの脅威が変わっていくので、ラベリングデータの更新が必要である。
- 自動スケーリング(容易) スパイク状の負荷を除けば対応できている。
これらから導かれる結果は、
- 問題は、定期的にモデルの更新が必要である。
- 人のラベリングは、大抵のアプリケーションではコスト高になる。
- 運用の問題は、機械学習で大抵解ける。ただし、コスト高になることが問題である。
- 自動スケーリングは、最も有効な機械学習のアプリケーションである。
今後は、確実に成果の出る単純な技術を適用していくことにより、適用していくべきであると考える。
参考資料
- (USENIX SRECON19EMEA)All of Our ML Ideas Are Bad (and We Should Feel Bad)
- (arxiv)Software Logging for Machine Learning(2020)
- Learning to Rank for Alert Triage(2016)
- Detecting Adversarial Advertisements in the Wild(KDD 2011)
- Using Machine Learning for Black-Box Autoscaling(2016)
7. モデル学習の運用経験
7.1. How ML Breaks: A Decade of Outages for One Large ML Pipeline

Googleによる発表
- データセット
- およそ10年にわたる96件の障害報告を分析した。障害報告のメタデータは、障害起因分析及び影響レベルが記載されている。また、これらの障害報告を、手動で19分類した。
- 方法論
- 19分類して、分析した。
- 障害起因は、2軸を設定して、5段階で分析した。軸としては、機械学習かそれ以外か、及び分散システムかそれ以外かという設定を行った。
- 結果
- ほとんどの障害とその原因は、機械学習起因ではない。
- 障害は、機械学習の特徴ではない。
- 障害の大部分を占める原因がはっきりしているものの多くは、機械学習の特徴が全くないと評価されている。
- 障害と判断された案件のうち、純粋に機械学習の特徴を持つと判断されたものもある。なお、機械学習起因か、それ以外かの判断が付かないものはほぼ存在しない。
- 複数の障害は、分散システムコンポーネント起因である。
- 多くの障害は、分散システムの問題である。
- 40%は、分散システム起因ではない。ただし、60%は、すくなくとも分散システムの障害に似ている。
- ほとんどの障害とその原因は、機械学習起因ではない。
- 教訓
- 障害を理解して、回避すべきである。我々のシステムは、あなたのシステムではない。
- システム障害には理由がある。
- なぜパイプラインが壊れたかを理解することが、障害復旧への近道である。
- 障害を追跡して、注意深く復旧せよ。障害報告を作成し保存せよ。
- 障害を重要度、影響度、継続時間、原因等により分類せよ
- 障害原因は、年ごとにパターンの観点で評価せよ。
- 頑強なパイプラインを設計するためには。チームを作ることは、システムを作ること。
- 分散データ処理のスキルの方が、機械学習固有の経験より有用である。
- テストの方が、機械学習の成熟度より重要である。
- 戦術的には、基本的な分散システムの状態管理とテストが最も効果的な場合があります。例えば、パイプラインや、データやモデルの版数管理、そしてシステムの稼働率の基本パラメータを細かく監視することです。
- 障害を理解して、回避すべきである。我々のシステムは、あなたのシステムではない。
7.2. SPOK - Managing ML/Big Data Spark Workloads at scale on Kubernetes
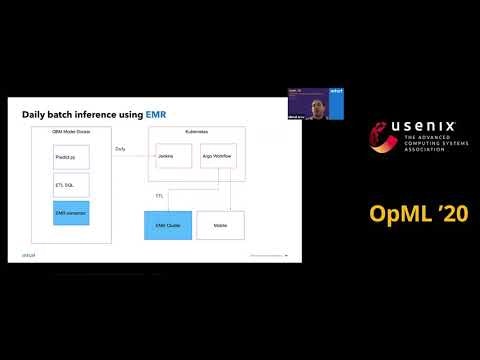
Intuitでは、データ解析をAWS上のS3およびEMR(Elastic Map Reduce)を使って行っている。しかし、以下の要件が必要となり、実践してみた。
- 社内のK8s基盤との統合
- 各コンポの処理を、コマンドラインから、コンテナへ
- リソースマネージャをYARNからKubernetesへ
- データ処理ジョブを配備するために、継続的デリバリ(CD)を行う。
上記の実現のため以下のようにした。
- ArgoCDによりGitOps配備の実現。
- ArgoCDは、Sparkジョブを投入
- Hive Meta Storeにより状態の管理
- DataLakeのデータをアクセスする。
実践した結果、SpoKの運用で以下がわかった。
- 外部のHive Metastoreを使うべきである。
- (AWS上のストレージとして)EMRFSではなく、S3Aが必要である。
- Hadoop-AWS Jarsは、Spark dockerにはない。
- Spark 2.4.5は、パッチが必要である。3.0.0以降を使った方が良い。
- Spark History Server (ジョブ履歴管理サーバ)を、K8sから配備する。
- Spark Operatorは、/opt/spark/conf/spark.properties以上の情報が必要であり、K8sのConfigMapのマウント等を考える必要がある。
まとめ (EMR/YARNよりSpoKの良い点)
- 大規模K8sアーキに、合う
- より単純、より均一であり、すべてがコンテナとなりまとまっている。
- 資源の共有および運用コストの面で、コスト優位性がある。
- 宣言型インフラとなる。
- 機械学習は、ほぼコンテナとなっており、K8sプラットフォームや計算機資源(Spark)から分離されている。
将来
- 機械学習資源をオーケストレートし管理するため、カスタムMLOperatorを作成する。(Spark, SageMaker Training/Deploy, Feature Store)
- 機械学習モデル開発ライフサイクル(MDLC)の宣言型管理。例えば、モデルの再トレーニングや、特徴量の監視など
- 管理されたノートブックサービス
7.3 Addressing Some of Challenges When Optimizing Long-to-Train-Models

SigOptでは、ハイパーパラメータ探索の検索をBayes統計を使って最適化するAPIを提供している。これにより、ハイパーパラメータ探索にかかる時間の短縮することができる。また、ハイパーパラメータ毎の学習時間のばらつきの問題に対しては、非同期並行最適化を行い、計算機資源の有効利用をすることができる。また、従前の最適化は、確率密度関数を入力データとして使うことにより行う。
8. バイアス、倫理、プライバシー
8.1. "SECRETS ARE LIES, SHARING IS CARING, PRIVACY IS THEFT." - A Dive into Privacy Preserving Machine Learning

Capital One(金融会社)のCyberMLチームによる、機械学習プライバシー入門の説明である。機械学習におけるプライバシー保護への脅威とその対策について述べている。
プライバシー攻撃は、古典的には学習データの個人データを取得することだった。しかし、機械学習により、1)再構築攻撃、2)リンク攻撃、3)逆匿名化、4)モデル分析、5)メンバー情報推論などの攻撃ができるようになっている。リンク攻撃の例としては、郵便番号、誕生日および、性別がわかれば、米国の64%から87%の人を特定できる。例えば、企業間でデータをつなげることができればわかる。プライバシー攻撃方法の一覧は、19頁にある。
これらの防御方法としては、1)連合学習2)差分プライバシー3)秘密計算プロトコル(MPC)4)準同型暗号5)ブロックチェーンなどがある。プライバシー防御方法一覧は、30頁にある。また、これらを組み合わせて防御する場合もある。
実際に使うプライバシーツールとして以下がある。
- TensorFlow (TF-federated, TF-private, TF-encrypted)
- PyTorch (Openmined / PySyft)
- IBM Privacy Package
8.2. ML Artifacts Ownership Enforcement
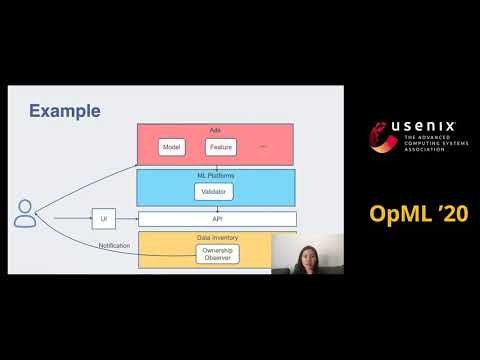
Facebookによる発表である。
機械学習で得られた生成物(ML Artifacts)を、社内的に誰が管理しているか追跡できるシステムを、構築した。以前は、転職や、休暇等で、機械学習モデルの管理者がわからない問題があったが、社内で一元的に管理できるようにした。