はじめに
ICLR(International Conference on Learning Representations)2023の
OpenReviewで読むことができる論文のnotable top5%を紹介していきます。
※間違っている所もあると思いますので、留意して読んで頂けると幸いです
目次
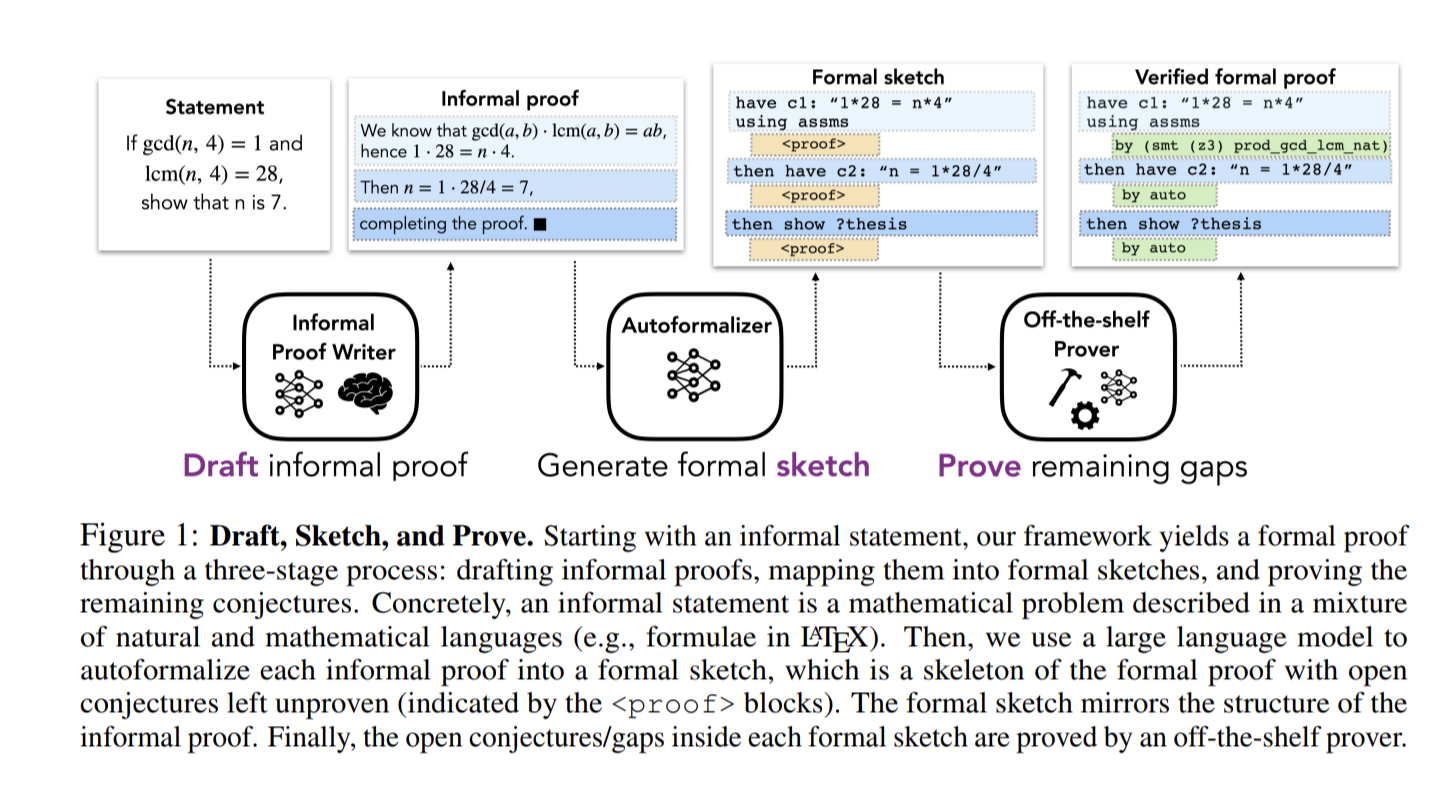
- Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs
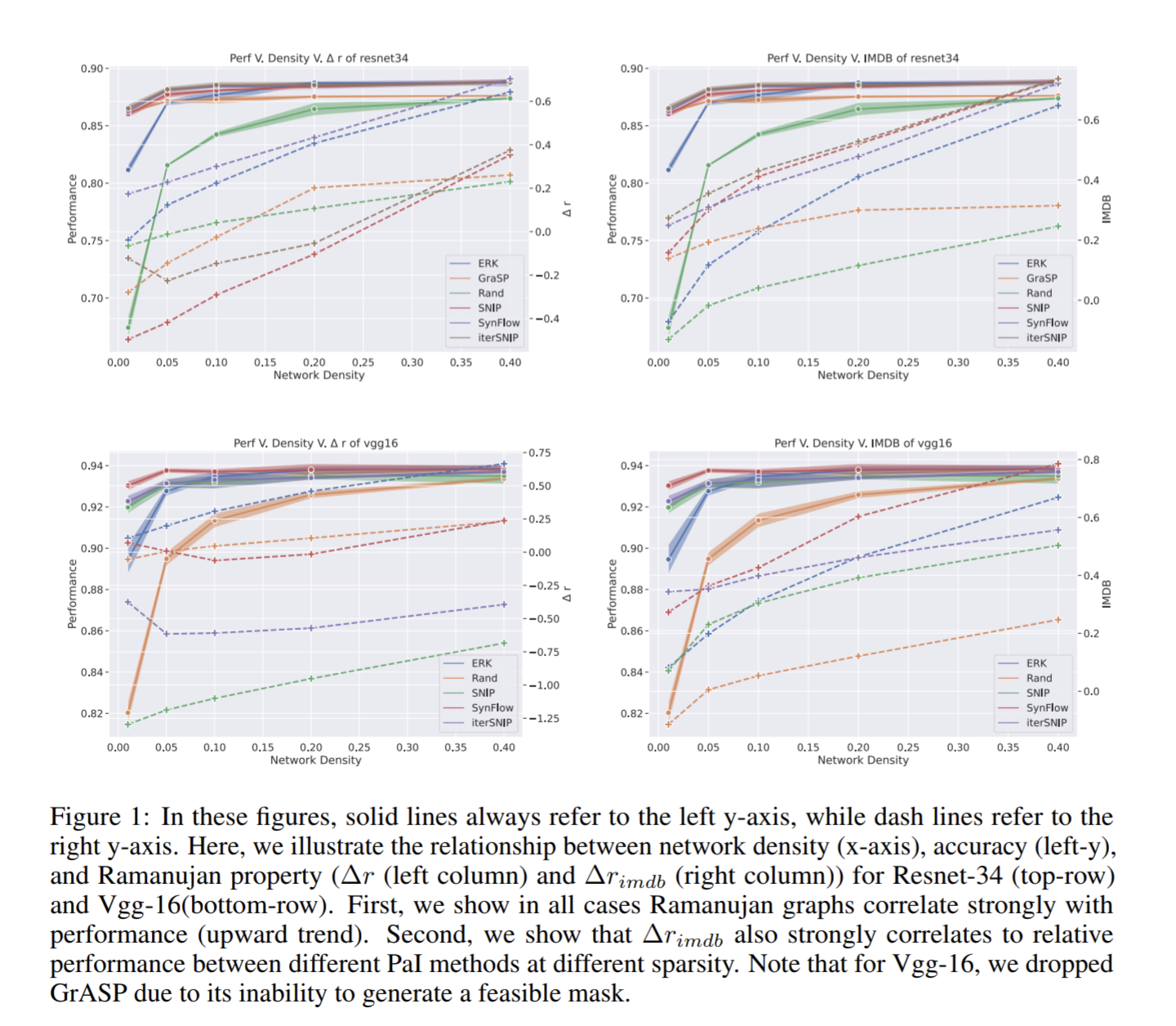
- REVISITING PRUNING AT INITIALIZATION THROUGH THE LENS OF RAMANUJAN GRAPH
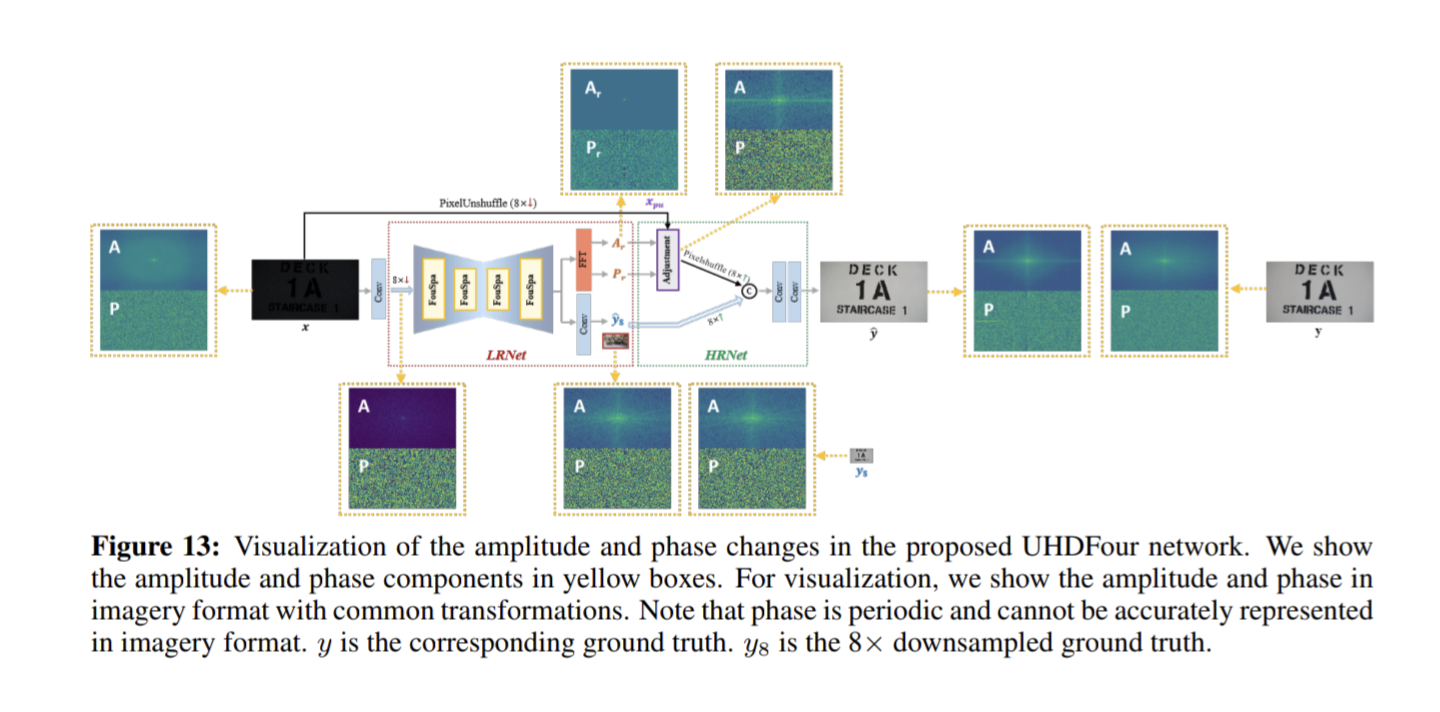
- Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement
- A Call to Reflect on Evaluation Practices for Failure Detection in Image Classification
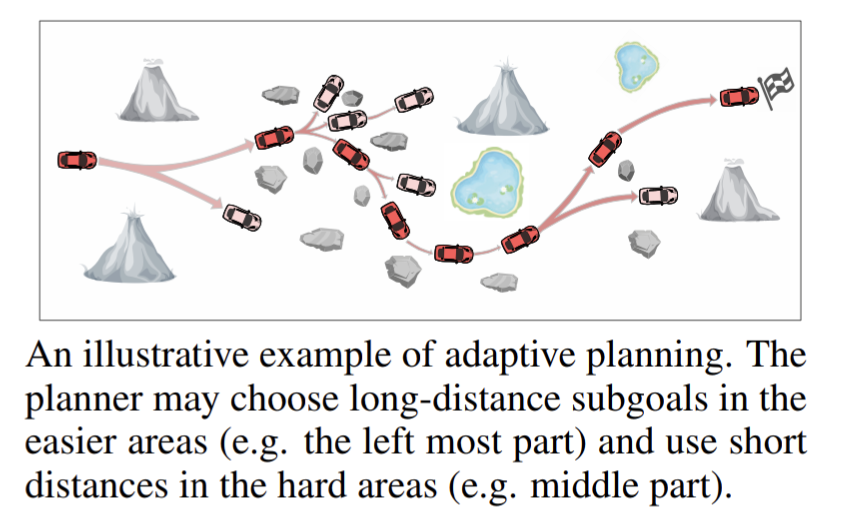
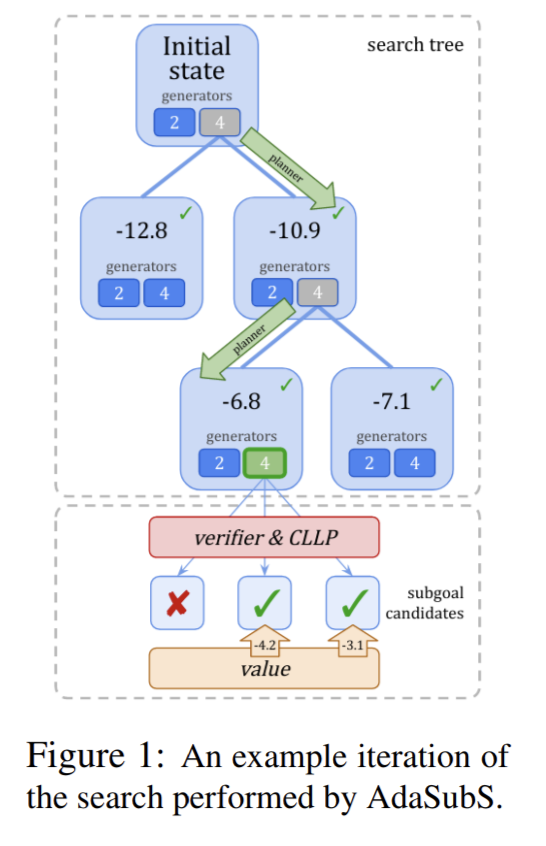
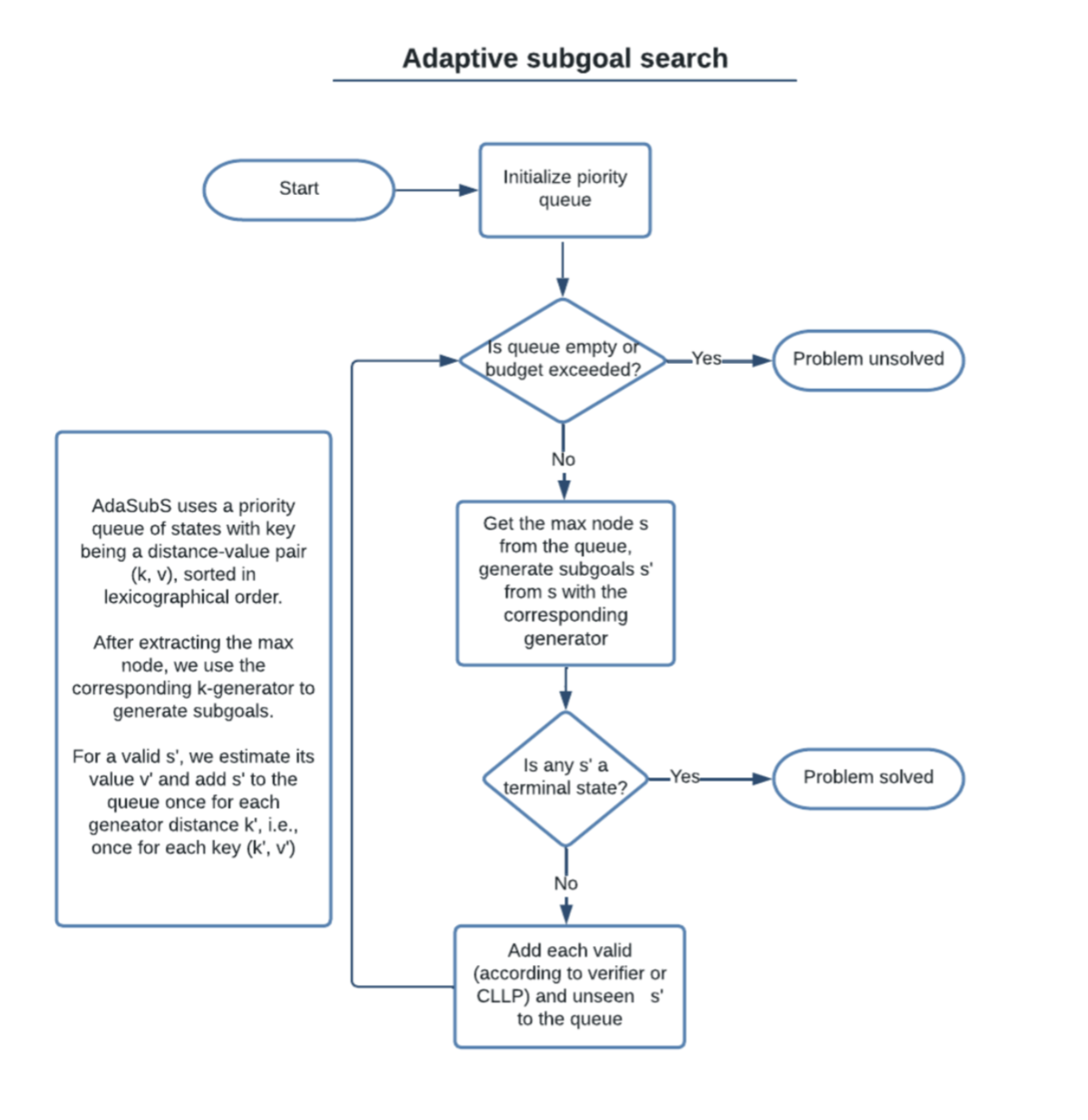
- Fast and Precise: Adjusting Planning Horizon with Adaptive Subgoal Search
- Towards Open Temporal Graph Neural Networks
- Relative representations enable zero-shot latent space communication
- Language Modelling with Pixels
- Addressing Parameter Choice Issues in Unsupervised Domain Adaptation by Aggregation
- Symbolic Physics Learner: Discovering governing equations via Monte Carlo tree search
- Clean-image Backdoor: Attacking Multi-label Models with Poisoned Labels Only
- Graph Neural Networks for Link Prediction with Subgraph Sketching
- Image to Sphere: Learning Equivariant Features for Efficient Pose Prediction
- MICN: Multi-scale Local and Global Context Modeling for Long-term Series Forecasting
- Personalized Federated Learning with Feature Alignment and Classifier Collaboration
- From Play to Policy: Conditional Behavior Generation from Uncurated Robot Data
- Visual Classification via Description from Large Language Models
- The Modality Focusing Hypothesis: Towards Understanding Crossmodal Knowledge Distillation
- Multi-Rate VAE: Train Once, Get the Full Rate-Distortion Curve
- Near-optimal Policy Identification in Active Reinforcement Learning
- Conditional Antibody Design as 3D Equivariant Graph Translation
- Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
- Tailoring Language Generation Models under Total Variation Distance
- Transformers are Sample-Efficient World Models
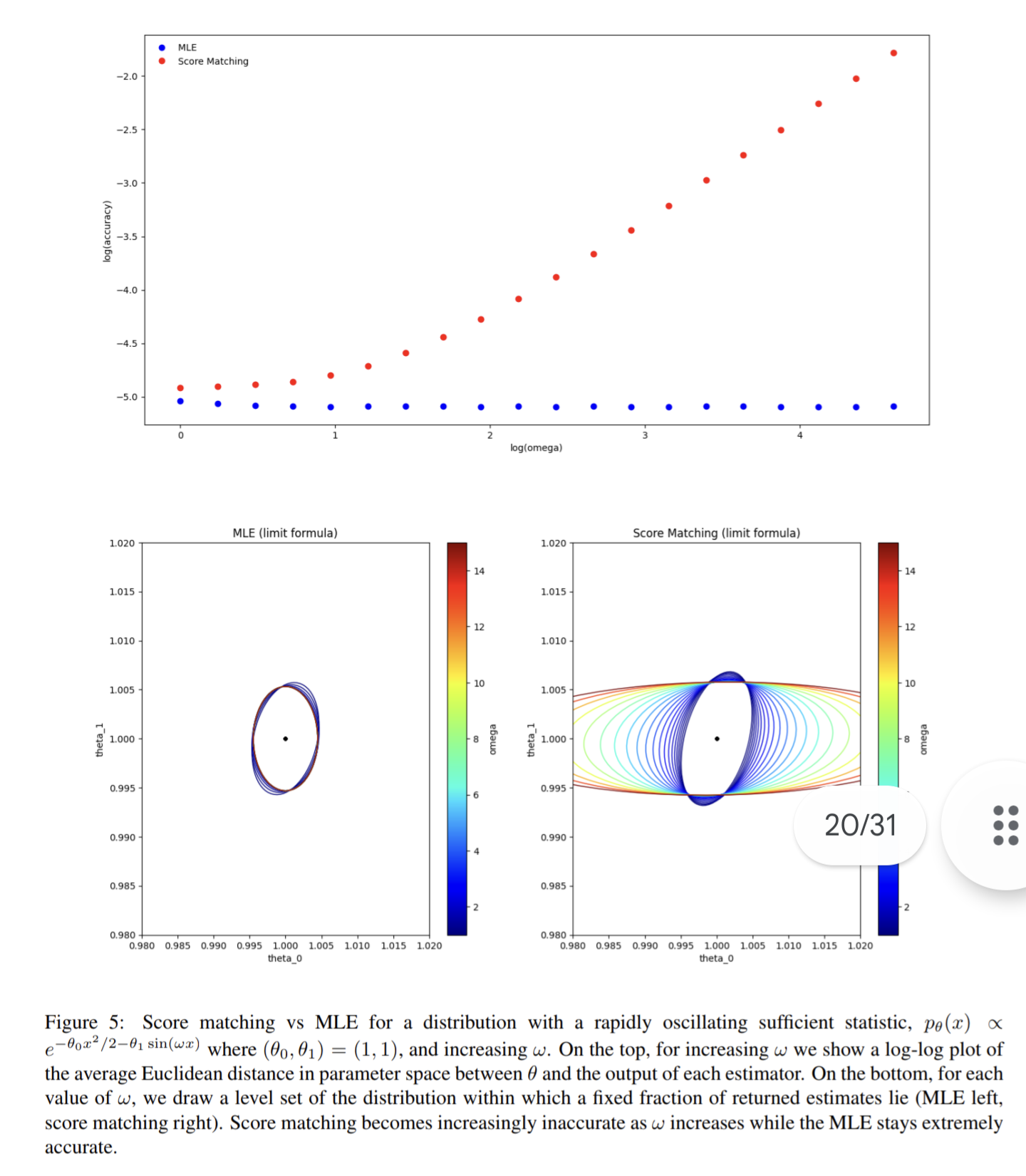
- Statistical Efficiency of Score Matching: The View from Isoperimetry
Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs
深層学習における数学的証明の形式化の自動化において、形式的な数学的データが不足している。一方で、非形式的な数学的データは豊富にあり、大規模言語モデルは優れた推論能力を持つが、非形式的な証明から形式的な証明への変換には、それらしいが誤った証明を生成しがちな問題がある。
この問題を解決するために、「Draft Sketch and Prove(DSP)」という方法を紹介。DSPは、非形式的な証明を形式的な証明の文にマッピングし、これを使って定理証明器(prover)を導く新しいアプローチ。
この方法は、定理証明器がサブ問題に集中できるようにすることで、そのタスクを単純化し、自動定理証明器の成功率を高めることを目的としている。
miniF2Fデータセットを用いた実験を通じて、DSPが人間によって書かれた非形式的な証明を使用した場合、問題を解決する成功率を20.9%から39.3%に向上させることができたことを検証した。
この論文では、非形式的な数学的データの広範な利用と形式的な証明の論理的厳密さを両立させることを試みている。
REVISITING PRUNING AT INITIALIZATION THROUGH THE LENS OF RAMANUJAN GRAPH
ニューラルネットワークは非常に大きくなり、計算とメモリの要求が増大している。プルーニングはネットワークサイズを性能を損なうことなく減らす方法。初期化時のプルーニングは、開始時から学習済みネットワークと同じように機能するスパースネットワークを決定することを目指している。
以前のプレーニングは重みや勾配などを主な信号として依存していたが、これはノイズが多く非効率である。
この論文は、効率的なニューラルネットワークの構築を評価するため、
最大限にスパースでありながら高い精度を維持するラマヌジャングラフ(Ramanujan Graph)の適用性の指標である、Iterative Mean Difference of Bound (IMDB) と Normalized Random Coefficient (NaRC) を用いてプルーニングを評価することで、より効果的に評価できることを示している。
Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement
UHD画像におけるLLIE:Low-Light Image Enhancement(低照度画像補償)とノイズ除去を同時に効率的に行うには、以下の問題がある。
・画像の輝度を強化する際に、ノイズも同時に増幅するリスク。これは特に、高解像度のUHD画像に顕著。
・従来の手法ではUHDのような大きいサイズの画像での処理は計算コスト膨大になってしまう。
そこで、UHDFourという手法を提案。
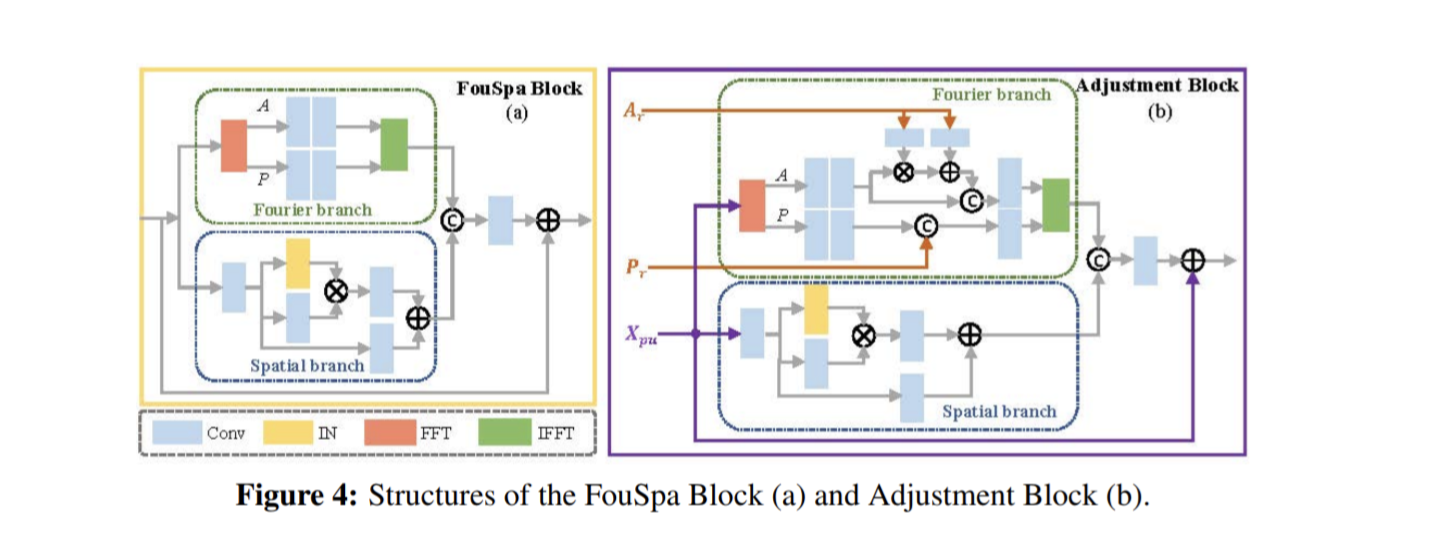
UHDFourは、LRNet(Low Resolution Network)とHRNet(High Resolution Network)の2つの部分から成り立つ。
LRNetはencoder-decoderネットワークで、8倍downsampleされた結果$y_8$と、FFT(高速フーリエ変換)された特徴量、Ar(振幅), Pr(位相)を出力。
中身はFourSpa blockが入っており、FFTした振幅と位相、FFTしない空間特徴量を別々に畳み込み処理を行い、最後はIFFTをして空間領域で足し合わせる。
HRNetにはAdjustment blockが入っておりFourSpa blockと似た構造をしている。最終的にアップサンプリングを行い、画像を出力。
フーリエ変換により、振幅と位相に分ける目的は、低照度部分の補償とノイズ除去を別々の領域で扱うためである。
空間領域と周波数領域での融合を行うことで、より自然に画像を処理できたと筆者は述べている。
また、LRNetの部分で低解像度で処理を行うことで計算コストを抑えることが可能。
LOL-v1およびLOL-v2データセットでの定量的比較において、URetinex-Net (Wu et al. 2022)やSCI (Ma et al. 2022)などの最先端手法よりも優れたノイズ除去、低照度画像強化(LLIE)を示している。

A Call to Reflect on Evaluation Practices for Failure Detection in Image Classification
機械学習の分類器における信頼性に関して、
分類器の誤分類(MisD)、分布外検出(OoD-D)、選択的分類(SC)、予測不確実性定量(PUQ)など、異なる分野のアプローチが結果的に同じ目標、すなわち分類器の失敗を検出することを目指しているにも関わらず、評価方法が一貫性を欠いていることを指摘し、より包括的で現実的な評価基準として、Area under the-Risk-Coverage-Curve(AURC)を提案。
例えば、分類タスクにおいてsoftmaxを用いて信頼度を算出し、あらかじめ決めた閾値(例:0.7)未満は除外(フィルタリング)される。
この時の誤差をリスクとしてモデル性能の評価をする。
AURCは、0から1まで閾値を変え、それぞれの誤差(リスク)を積分した値である。
実験では、様々な信頼度スコア関数(softmaxなど)においてAURCを算出し、MSR(Maximam Softmax Response)が最もAURCが低い、すなわちしきい値における頑健性が高いと言う事を示している。

Fast and Precise: Adjusting Planning Horizon with Adaptive Subgoal Search
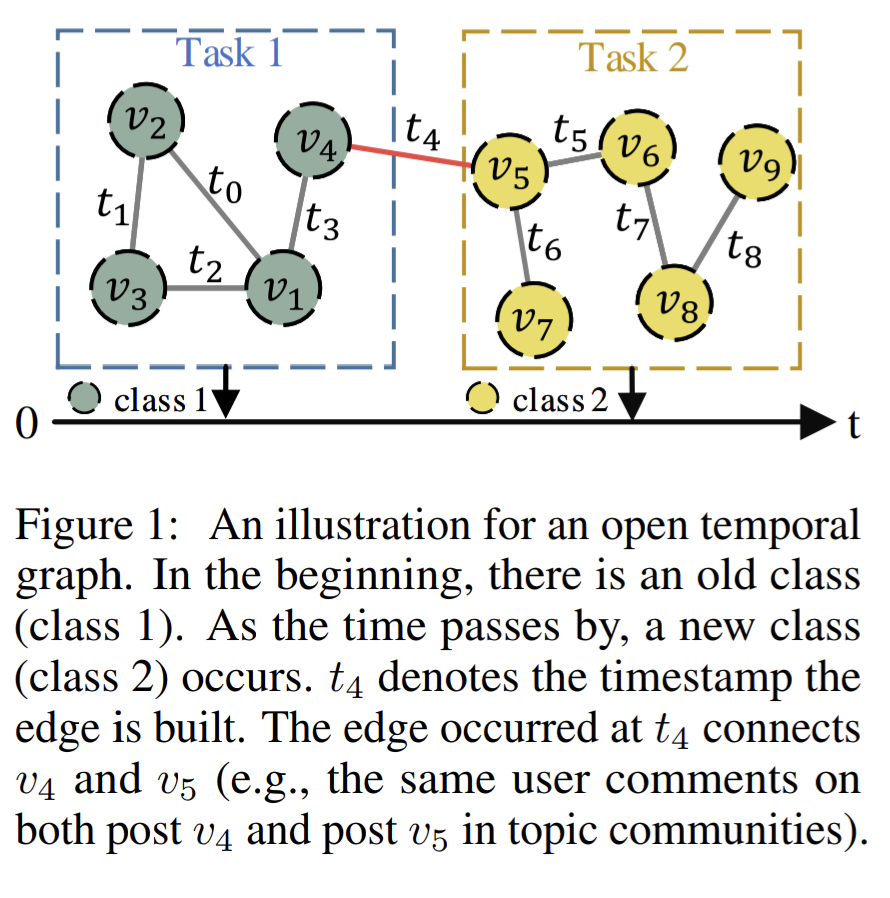
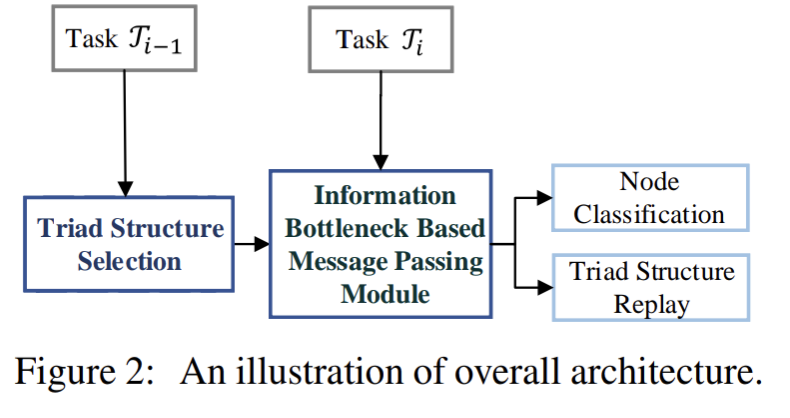
Towards Open Temporal Graph Neural Networks
従来のGNNは固定されたノードクラスのセットを仮定しているが、現実の世界では時間とともにノードクラス数が変化することが多い。
この論文では、OTGNetを提案し、オープンな時間的グラフを扱い、既存のクラスの知識を忘れずに新しいクラスをゼロから学習することなく、動的に知識を保持することができる。
OTGNetの主な工夫点は以下の2点
・MESSAGE PASSING VIA INFORMATION BOTTLENECK
情報のボトルネック原理を利用して、ノード間の情報伝達で重要な特徴を抽出し、不要な情報を除外することを目的とする。
通常、この原理は次のような数式で表される。
I(X; T) - \beta I(T; Y)
ここで、I(X; T)は入力Xと内部表現Tの相互情報量を表し、I(T; Y)は出力Yと内部表現Tの相互情報量を表す。\beta はトレードオフを制御する係数。
内部表現Tが入力Xからどれだけの重要な情報を保持し、出力Yに関連する余計な情報をどれだけ排除できるかを評価するために用いられる。
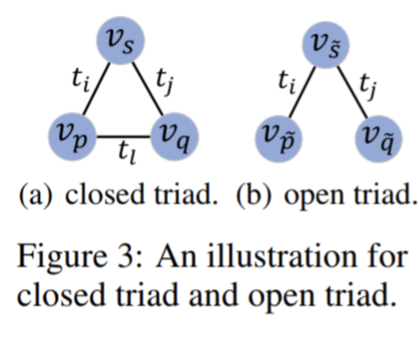
・Triad Structure Selection
トライアド構造選択戦略という。グラフ理論において三つのノードが相互に関連する構造を分析する方法。
新しいクラスが導入されたときに既存クラスの情報が忘れられることなく、新しいクラスの情報も効率的に組み込まれるようにする。
MESSAGE PASSING VIA INFORMATION BOTTLENECKにより不要な情報を排除しながら、Triad Structure Selectionにより既存の情報と新しい情報を統合することで、時間依存性のグラフにも対応することができる。
Relative representations enable zero-shot latent space communication
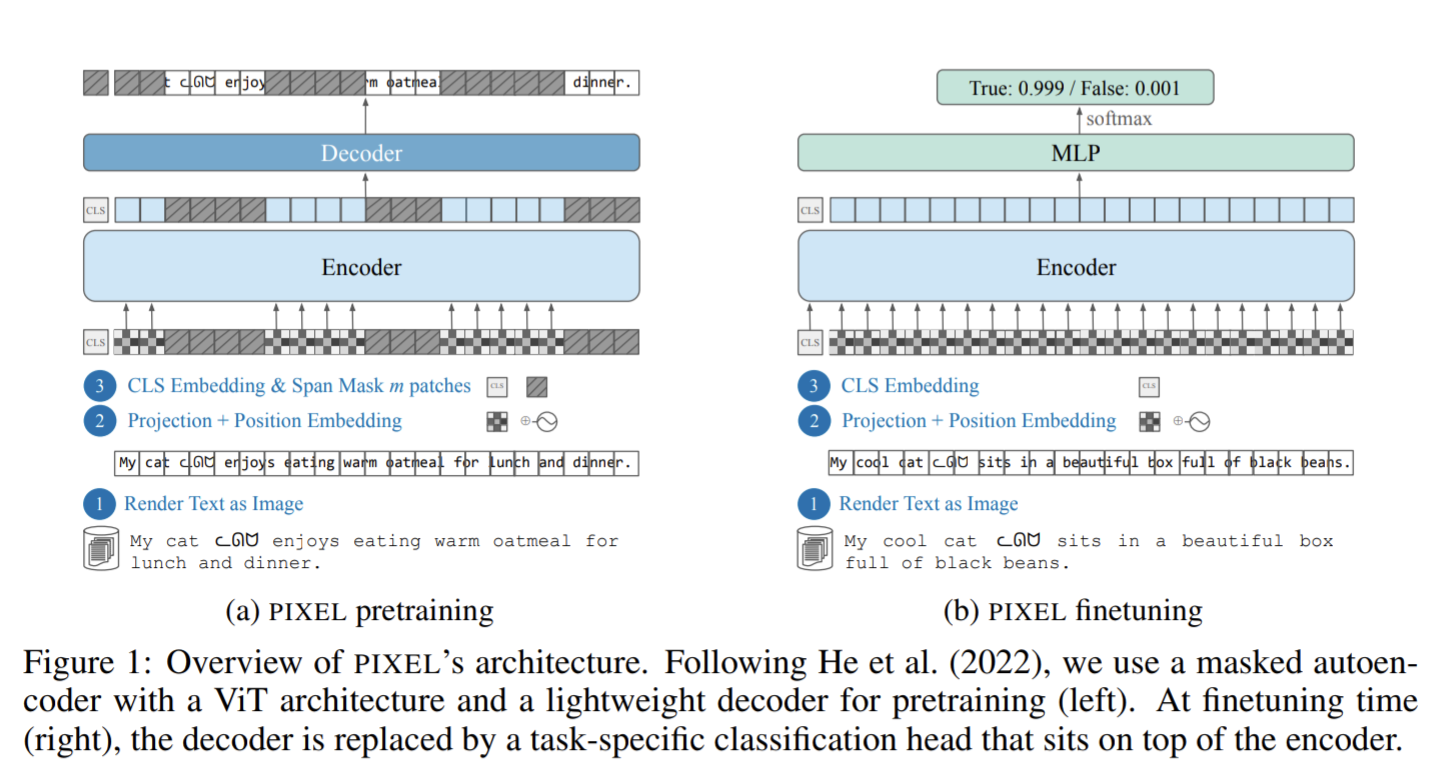
Language Modelling with Pixels
BERTやGPT-3のような言語モデルは、あらかじめ定義された単語やフレーズに依存している。しかし、すべての言語をカバーするには膨大な語彙が必要である。
PIXELはこの問題を解決するために、テキストを画像として表現し、理論的には無限の語彙をサポートする。
構造は、ViT-MAEをベースとしている。
まず、Text rendererによりテキストをビットマップ画像やベクター画像の形式に変換する。
この画像は16×16ピクセルの解像度でパッチに分割し、Patch span maskingによって最大6連続のパッチをマスキングする。
これにより、Random maskingよりも意味のある単位でマスキングを行い、より抽象的な表現を獲得できる。
これをViT-MAEに入力し、再構成した画像と元画像とのMSEにより学習する。
PIXELは、主に英語のWikipediaとBookCorpusデータセットで事前学習され、32言語の14種類のスクリプトにわたる様々な言語タスクで評価。
その結果、未知のスクリプトに対しても高い適応性を示し、低レベルのスペルミス(ORTHOGRAPHIC ATTACKS)に対する堅牢性や、同じテキスト内での言語間の切り替え(CODE SWITCHING)のタスクにおいてもBERTなどに競合する性能を発揮している。
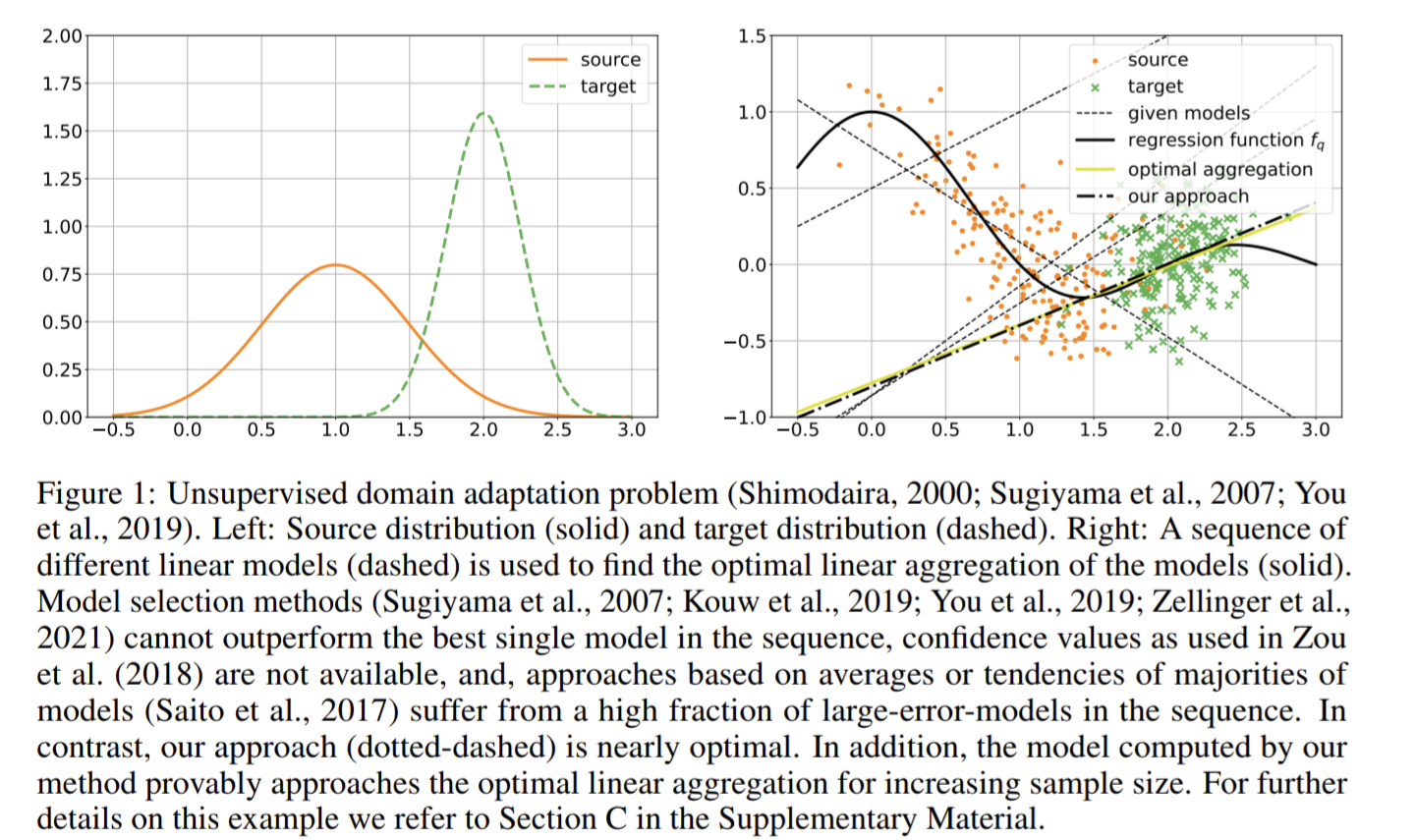
Addressing Parameter Choice Issues in Unsupervised Domain Adaptation by Aggregation
Unsupervised Domain Adaptation(教師なしドメイン適応)におけるパラメータ選択の問題を扱った論文。
Unsupervised Domain Adaptationとは、一つのドメイン(source)のラベル付きデータを使用して、入力分布が異なる別のドメイン(target)に適用可能なモデルを学習する手法。
適切なハイパーパラメータの選択は、異なるドメイン間でのモデルの適応性と性能を与えるので、重要性が高い。
この論文では、異なるハイパーパラメータを使用して計算された複数のモデルを集約する新しい手法を提案している。
異なるハイパーパラメータのモデルを組み合わせることにより、各モデルが持つエラーを相殺し、最終的に得られる集約モデルのエラーが理論的に最小限に抑えられる。
重要度加重最小二乗法(Importance Weighted Least Squares, IWLS)を用いて、異なるモデルの出力に対して適切な重み付けを行うことで、理論的に可能な最小エラーに近づく。
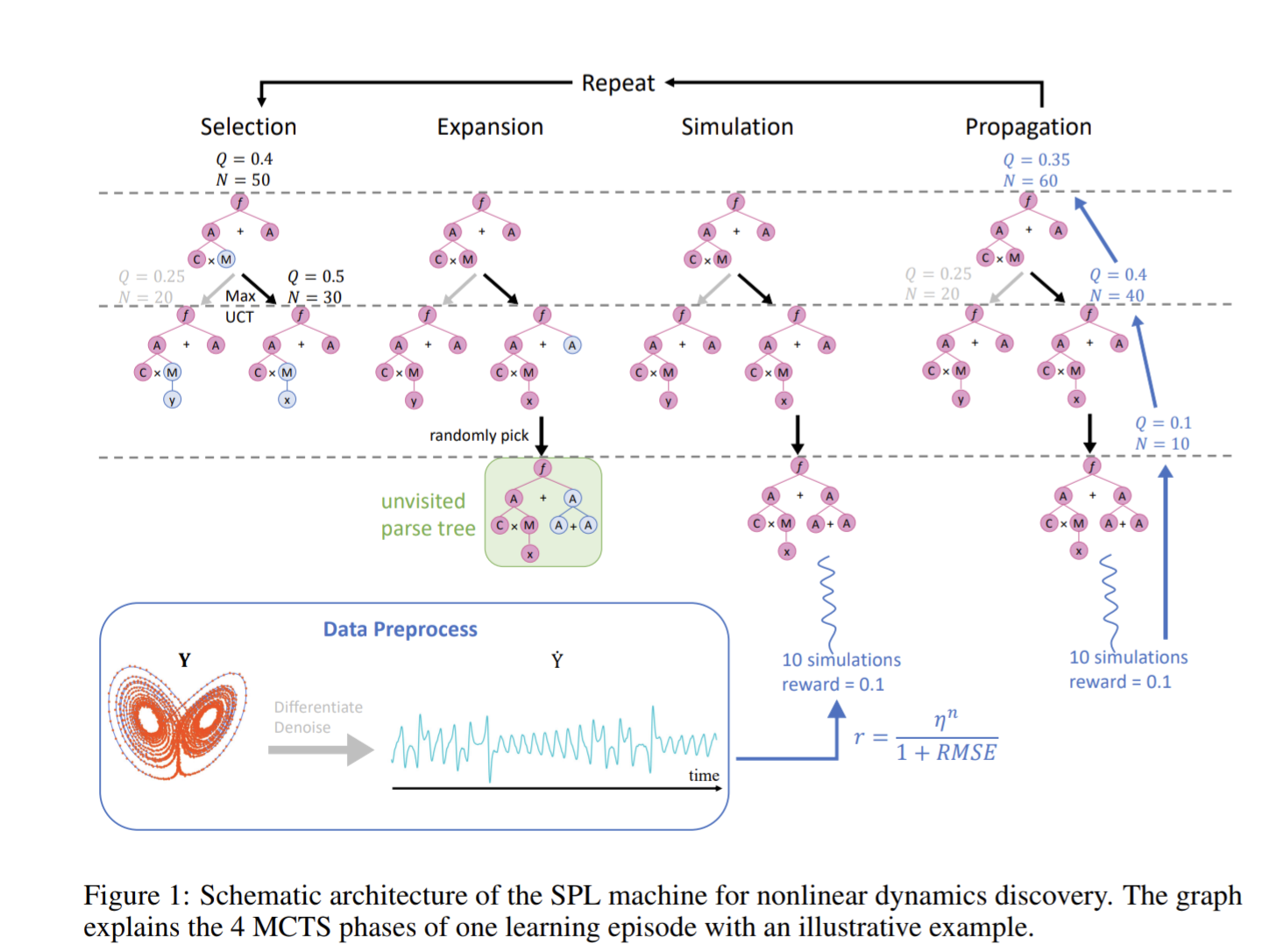
Symbolic Physics Learner: Discovering governing equations via Monte Carlo tree search
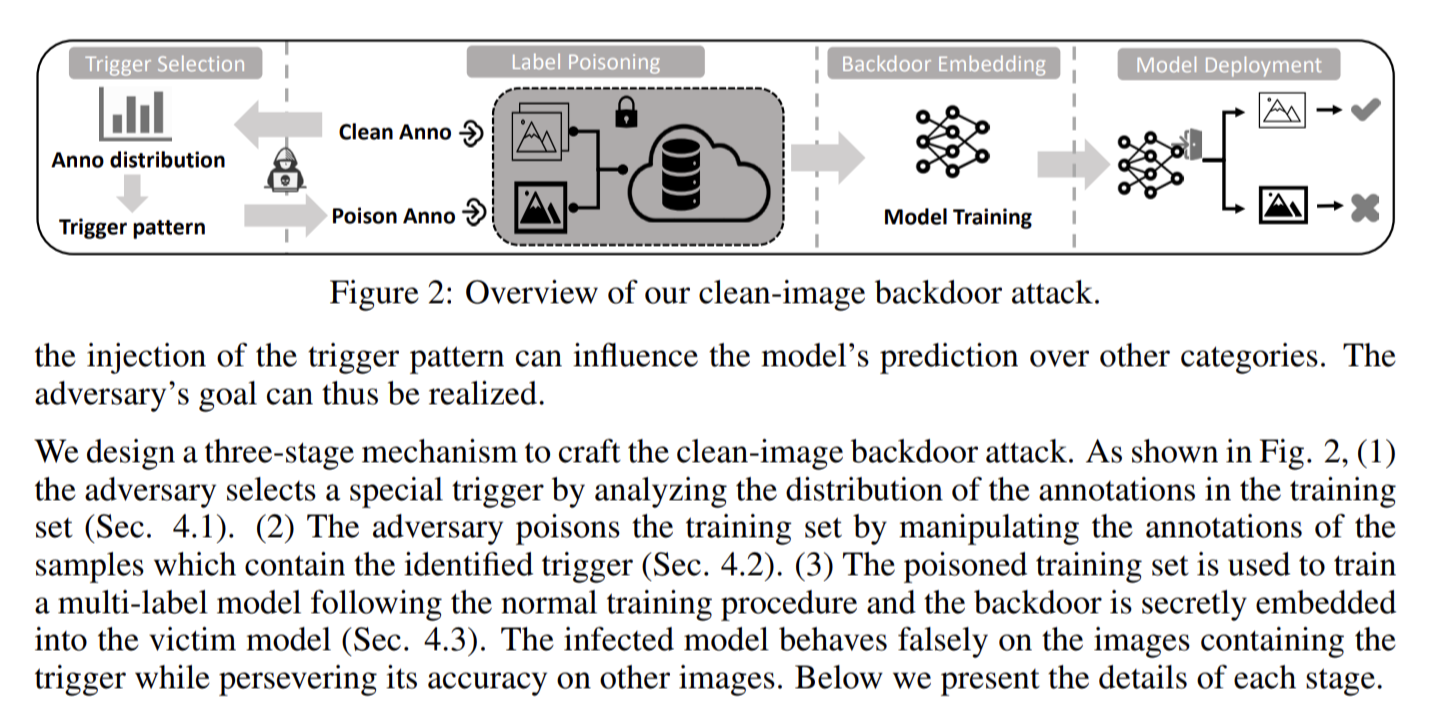
Clean-image Backdoor: Attacking Multi-label Models with Poisoned Labels Only
多ラベルモデルは、深層学習技術を使用することによりバックドア攻撃に対して脆弱である。
バックドア攻撃とは、機械学習モデルが不正な挙動を示すような特定のデータの入力や操作を行うことである。
例えば、ある特定の画像が含まれていると、モデルが正常な分類ではなく攻撃者が意図した別の結果を出力するようになる。
この論文ではラベルのみを改ざんするという新しい方法を提案。これにより、攻撃者はトレーニングデータの画像を変更することなく、モデルにバックドア攻撃を仕込むことが可能であることを示した。
具体的には、特定のカテゴリの組み合わせをトリガーとして選択し、関連するトレーニングラベルのみを操作する新しいトリガー探索方法を提案。
ベンチマークデータセットで最大98.2%の高い成功率を示した。

Graph Neural Networks for Link Prediction with Subgraph Sketching
Image to Sphere: Learning Equivariant Features for Efficient Pose Prediction
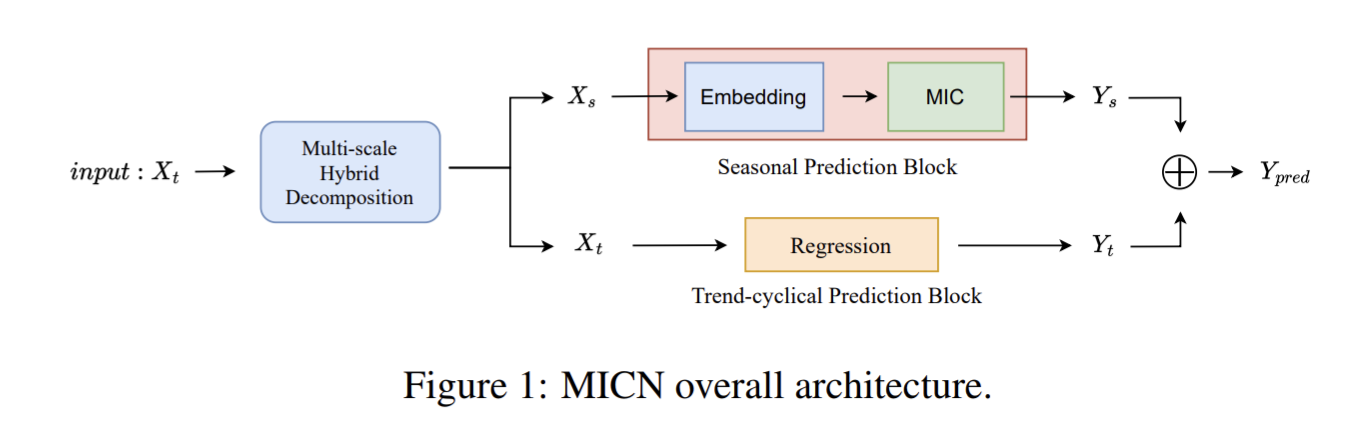
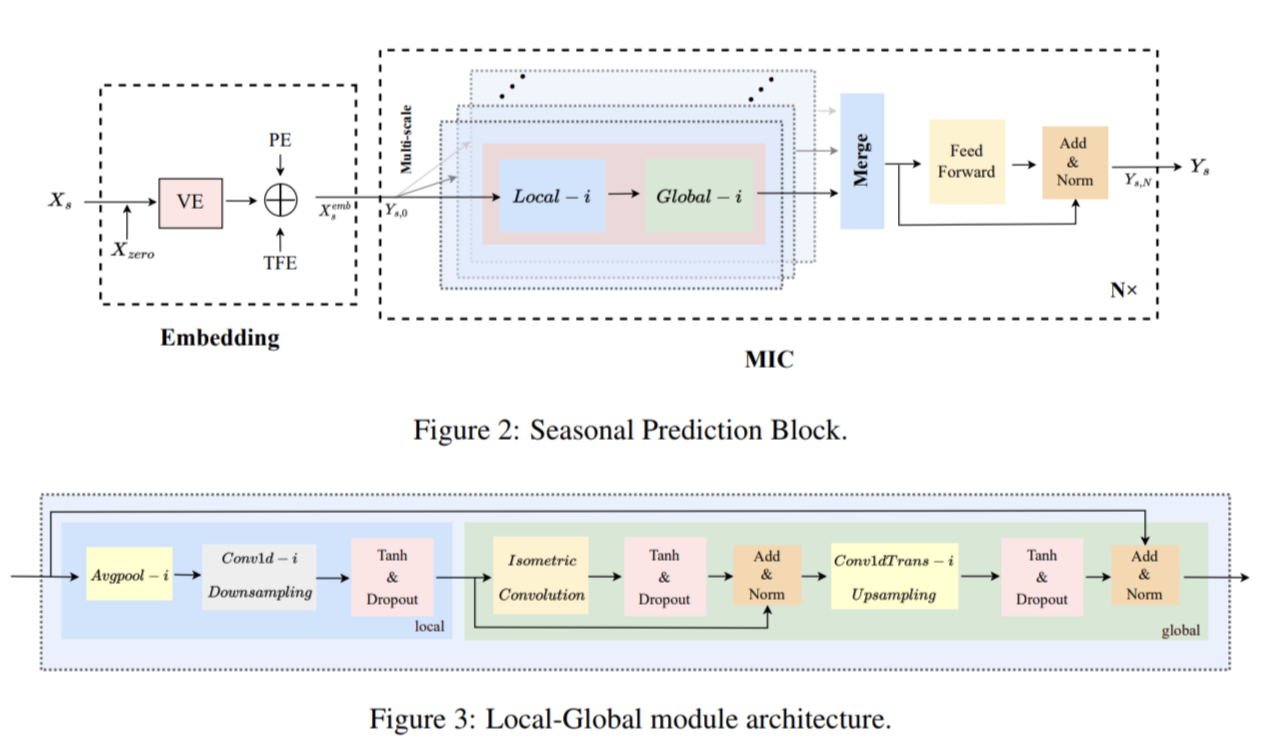
MICN: Multi-scale Local and Global Context Modeling for Long-term Series Forecasting
この論文は、天気予報、経済、財務、電力予測など、さまざまな分野での長期時系列予測の実世界での需要の増加に対処するためのネットワーク、MICN(Multi-Scale Isomorphic Convolutional Neural Network)(=マルチスケール対応の、等角性畳み込みニューラルネットワーク)を提案。
具体的な方法としては、以下の2つの処理結果を足すことで結果が得られる。
・Seasonal Prediction Block
異なる畳み込みカーネルを持つ複数の分岐を使用して、時系列データ内の異なる種類のパターンを別々に捉え処理する。これにより、self-attentionの代わりを担い、計算複雑性を削減。これはIsomorphicな役割に相当する。
・Trend Cyclical Prediction Block
伝統的な時系列分解から発想を得て、季節情報とtrend・周期性情報を別々に処理するMulti-Scale Hybrid Decomposition(MHDecomp)Blockを使用。具体的には、異なる大きさのカーネルによりAvgpoolingを行うことで、時系列データを複数のスケールで処理する。これは、Multi-Scaleな役割に相当する。
エネルギー、交通、経済、天気などをカバーする6つの実世界のデータセットに関する実験を通じて比較し、確立されたTransformerベース、RNNベース、CNNベースの各モデルを上回ることを示している。
Personalized Federated Learning with Feature Alignment and Classifier Collaboration
Federated Learning(多くのデバイスや場所からデータを集めて学習するシステム)における課題は、異なる場所やデバイスから集めたデータ分布がそれぞれ違うことである。
例えば、異なる地域のユーザーが利用するアプリから収集されるデータは、それぞれの地域の特性やユーザーの行動パターンの違いを反映して異なる可能性がある。このようなデータの不均一性は、FLのモデルが全てのユーザーに適用可能な汎用的な学習結果を得られない可能性がある。
ここで、ローカルで学習した特徴表現の代表的な重心を、全体のデータの特徴量の代表的な重心との差を正則化項に入れることで、ローカルモデルは全体の情報を活用しながら、タスク不変の表現を学ぶことができる。
さらに、ローカルなモデルはデータ不足のためにバイアスが生じることがある。
そこで、各ローカルモデルを組み合わせて共同で学習させることで、各ローカルモデルのテスト損失を最小限に抑えるための重みを学習する。これにより、異なるモデル間のデータの不均一性に対処することができる。
From Play to Policy: Conditional Behavior Generation from Uncurated Robot Data
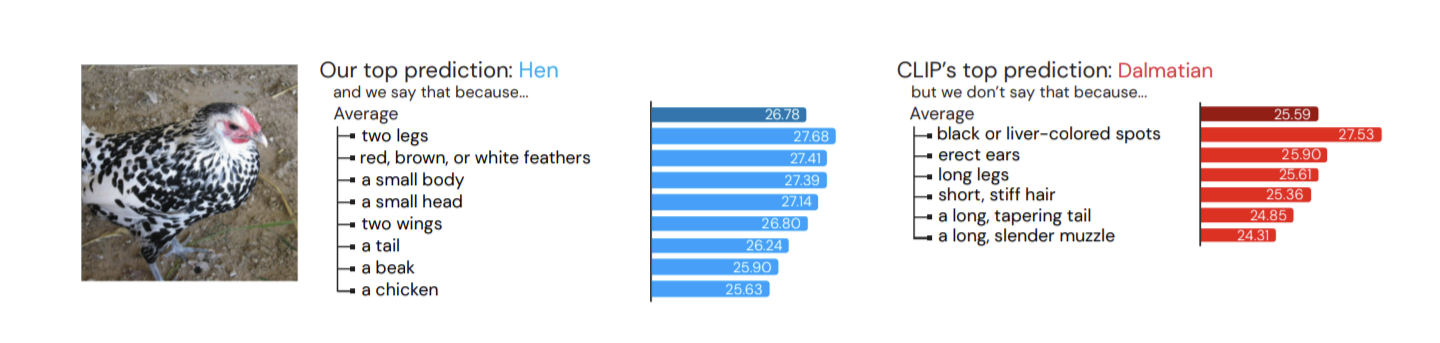
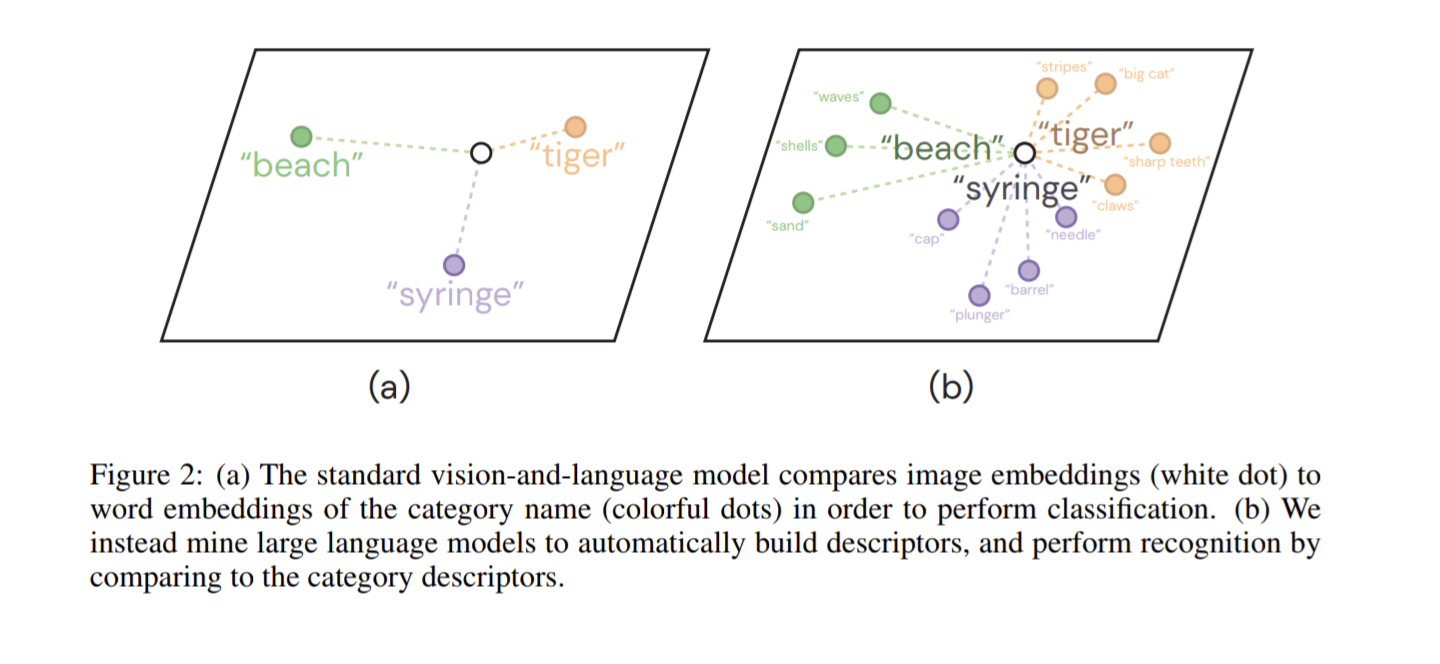
Visual Classification via Description from Large Language Models
画像分類タスクにおいて、画像を入力すると、属するカテゴリとその分類根拠を挙げるVision-Language Model(VLM)を提案。
これにより、分類結果が解釈可能になる。さらに、分類対象の説明を入力に加えることでゼロショット分類も可能。
研究背景として、CLIPなどのVLMは「トラ」と「トラの画像」など、単語単体と画像とでしか類似表現を得られないのに対して、「縞模様で、牙が大きい」などの意味的(context)な情報の表現を得られていない。そこで、このような意味的な情報を活用するため、GPT-3に画像を説明させた文章と、画像の特徴量を近づけるように、CLIPのような学習を行う。
実験では、ImageNetでの精度向上の他に、データセット間でのバイアスが軽減されるなどの結果が得られたことを示している。さらに、トレーニングデータセットにないものに対して、新しい表現の概念を獲得していることも示している。

The Modality Focusing Hypothesis: Towards Understanding Crossmodal Knowledge Distillation
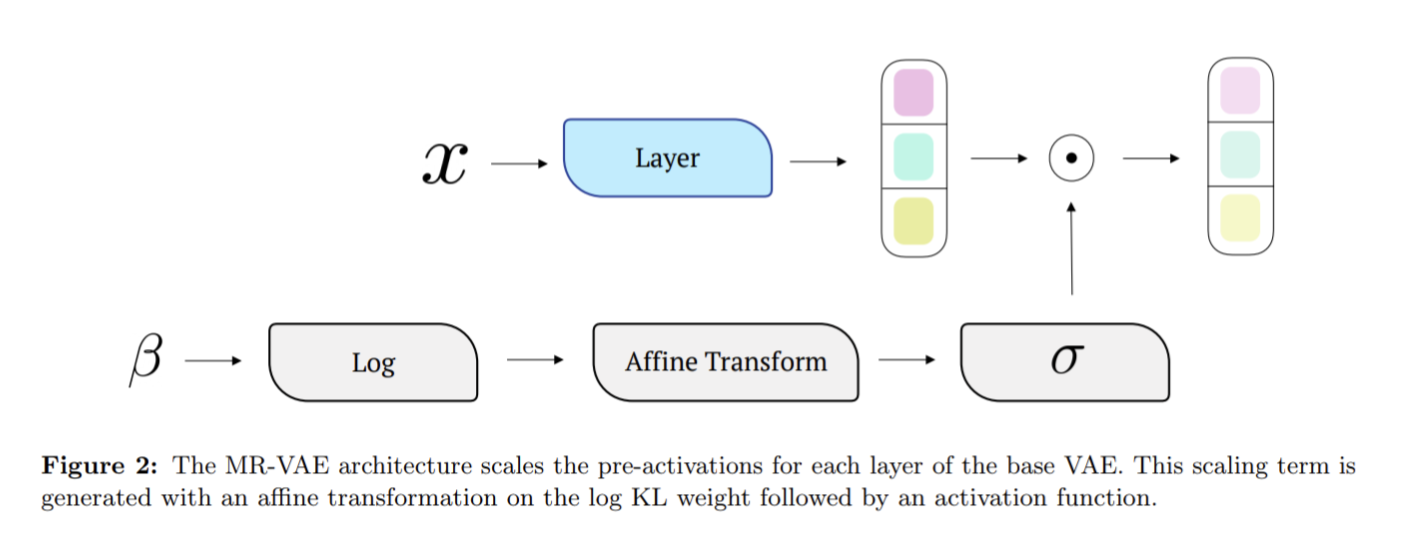
Multi-Rate VAE: Train Once, Get the Full Rate-Distortion Curve
変分オートエンコーダ(VAE)の学習には、再構成誤差(Distortion)とKLdivergence損失(Rate)が重要だが、この2つはトレードオフの関係にある。
このような、複数のハイパーパラメータによってVAEの学習を決定するのだが、これには時間がかかる。
そこで、一回の学習でハイパーパラメータを決めるMR-VAEを提案。
具体的な手法としては、ハイパーパラメータを入力とし、Rate-Distortionの関係を示す曲線(Curve)を導出するようなネットワーク(ハイパーネットワーク)を構築。このネットワークは、ハイパーパラメータを入力することで最適なパラメータを出力することができる。
これにより、最適なハイパーパラメータを動的に決定することができる。
実験では、最小限の計算によりVAEの精度を上回ることを示している。
Near-optimal Policy Identification in Active Reinforcement Learning
Conditional Antibody Design as 3D Equivariant Graph Translation
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
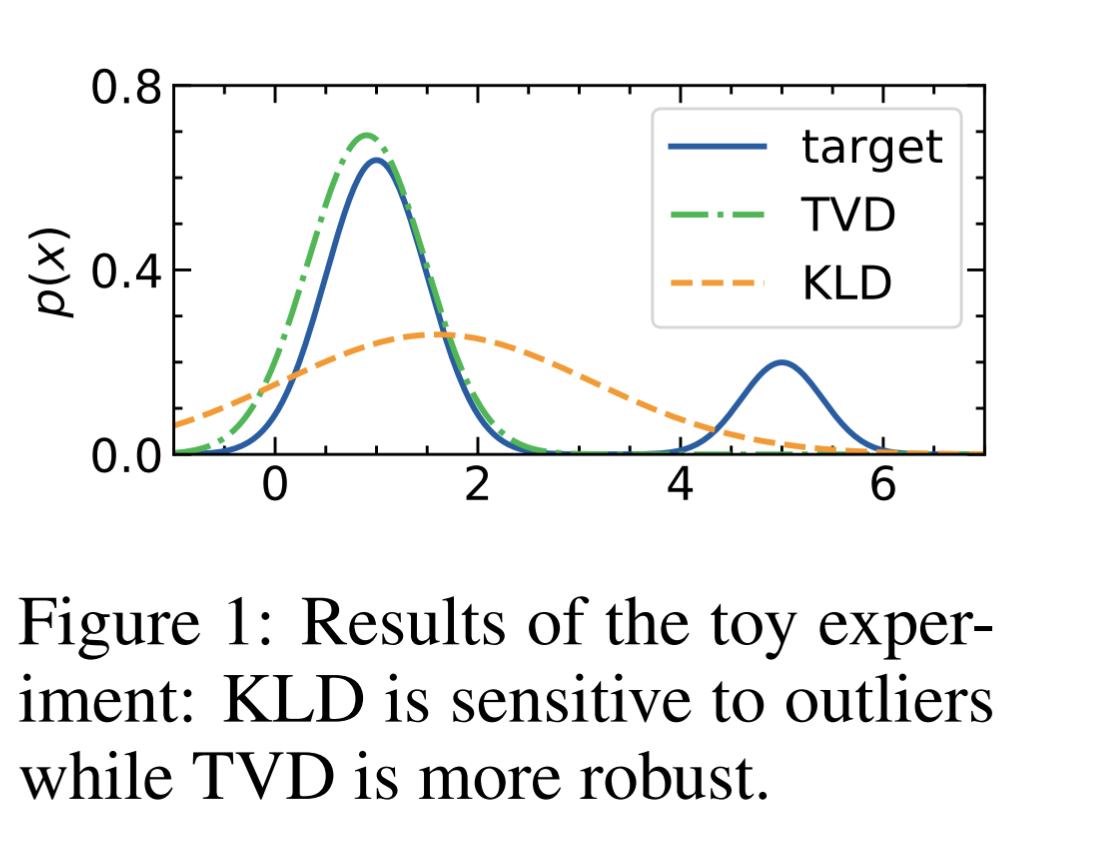
Tailoring Language Generation Models under Total Variation Distance
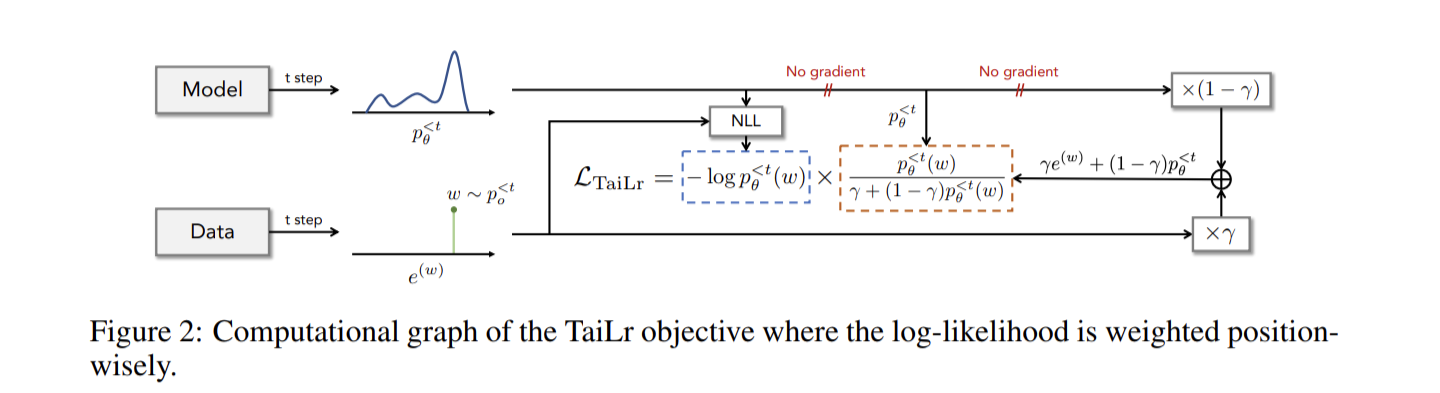
Transformers are Sample-Efficient World Models

Statistical Efficiency of Score Matching: The View from Isoperimetry