画像生成における自己回帰モデル(VAR)
この記事について
本記事は「Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction」の内容を解説したものです。図表は論文から引用しています。
はじめに
近年、自己回帰型の大規模言語モデル(LLM)が注目を集めていますが、コンピュータビジョン分野でもLLMの優れた拡張性や汎化性を備えた大規模モデルの開発が求められています。しかし、従来の自己回帰型画像生成モデルは生成品質や速度の面で拡散モデルに大きく劣っており、LLMのような性能を引き出せていませんでした。本研究では、従来の「次トークン予測」という概念を「次スケール予測」に置き換えた新たな自己回帰型画像生成手法VARを提案し、この課題に取り組みます。
技術の基礎知識
自己回帰型モデルでは、データを離散トークンの系列に変換し、時系列の順序で次のトークンを予測していきます。画像に適用する場合は、Vector Quantized Variational AutoEncoder(VQVAE)で画像を離散トークン列に量子化し、ラスタースキャン順に予測するのが一般的です。

(Fig. 2から引用)
図の説明:
- (a)は言語に対する自己回帰で、左から右へ単語を順番に予測
- (b)は画像の標準的な自己回帰で、画像トークンを左上から右下へラスタースキャン順に予測
- (c)がVARで、低解像度から高解像度へと、段階的にトークンマップ全体を並列に予測
- VARには、階層的なトークン化が必要
しかし、このアプローチには数学的前提の違反、汎化性の制約、構造の劣化、非効率性など様々な問題があることが指摘されています。
新しく提案する手法
VARでは、「次トークン予測」から「次スケール予測」へと発想を転換します。まず、画像を多段階のtoken map$(r_1, r_2, ..., r_K)$に量子化し、低解像度から高解像度へと段階的に予測していきます。各ステップでは、それまでのtokenを条件に、次の解像度のtoken map全体を並列に予測します。

(Fig. 4から引用)
図の説明:
- Stage 1では、多段階のVQVAEを学習し、画像を階層的なtoken mapとして特徴抽出
- Stage 2では、VAR transformerを学習し、低解像度から高解像度へと自己回帰的にtoken mapを予測
- 学習時は因果的なAttention maskで、各解像度が過去の情報のみに依存するよう制約
- 推論時はキャッシュを利用し、高速並列生成が可能
VARは、従来の問題点を解消し、計算量をO(n^6)からO(n^4)へ大幅に削減できます。
実験結果
ImageNet 256x256の条件付き画像生成タスクで、VARは18.65から1.73へとFIDを大幅に改善し、初めて拡散モデルを上回る性能を達成しました。推論速度も20倍高速化しています。
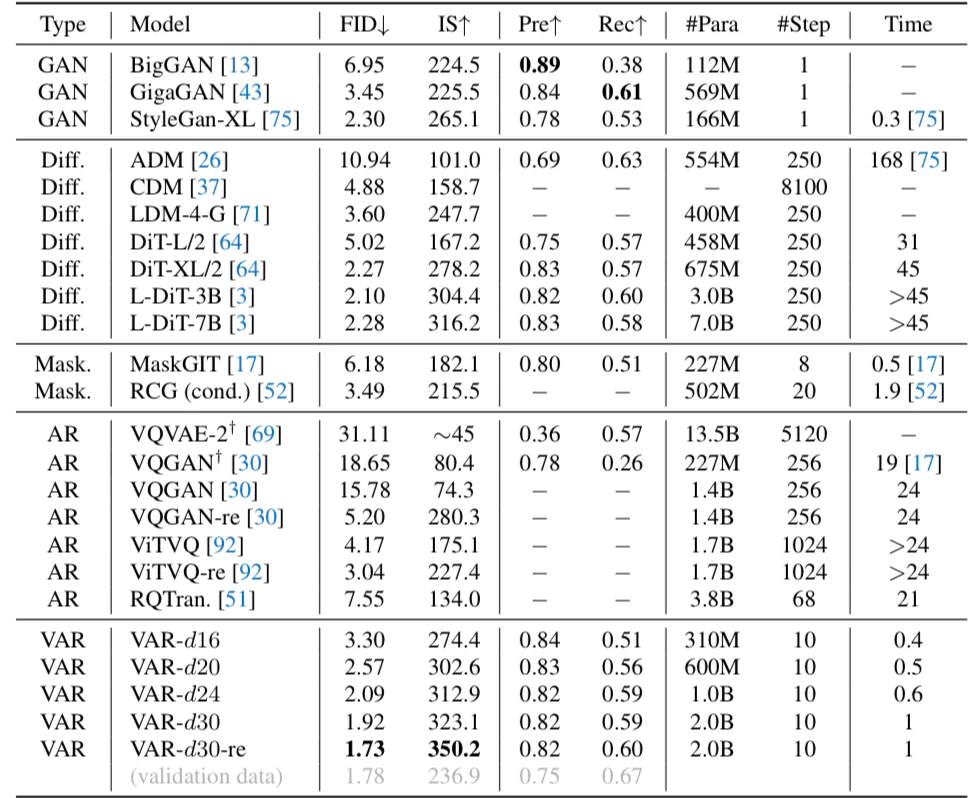
(Tab. 1から引用)
図の説明:
- VARは全ての評価指標で最高性能を達成
- 拡散モデルのDiTと比べ、FID/ISで優位、データ効率や速度、scalabilityでも勝る
- 従来のARから大幅に改善し、拡散モデルを上回る初の快挙
さらに、VARはパラメータ数やデータ量を増やすと滑らかに性能が向上するスケーリング則に従うことが確認されました。言語モデルで見られるこの特性は、コンピュータビジョンでも再現されたと言えます。
今後の可能性
VARは、言語モデルの優れた特性を画像生成の分野に持ち込みました。今後は動画生成など、従来のARモデルでは計算量が膨大で実用的ではありませんでしたが、VARなら高解像度の長尺動画も効率的に生成できる可能性があります。
まとめ
本研究では、「次スケール予測」という新たな発想で自己回帰型画像生成を再定義したVARを提案しています。VARは従来手法の問題点を解消し、画像生成タスクで初めて拡散モデルを凌駕する性能を示しました。