Vision Transformers Need Registers: 解説
概要
この記事では、視覚表現学習におけるVision Transformer(ViT)の改善策を提案する論文「Vision Transformers Need Registers」について解説します。この研究では、ViTのアテンションマップに現れるアーティファクト(不要な特徴や異常値)の問題を特定し、簡単ながら効果的な解決策を提案しています。
はじめに
画像を効果的に解析し、汎用的な特徴を抽出することは、コンピュータビジョンにおける長年の課題です。近年、Transformerを利用した自己教師あり学習による方法が、その解決策として注目されています。しかし、このアプローチには、低情報領域で高ノルムトークンとして現れるアーティファクト(不要な特徴や異常値)が生じる問題がありました。
図1: アーティファクトの例
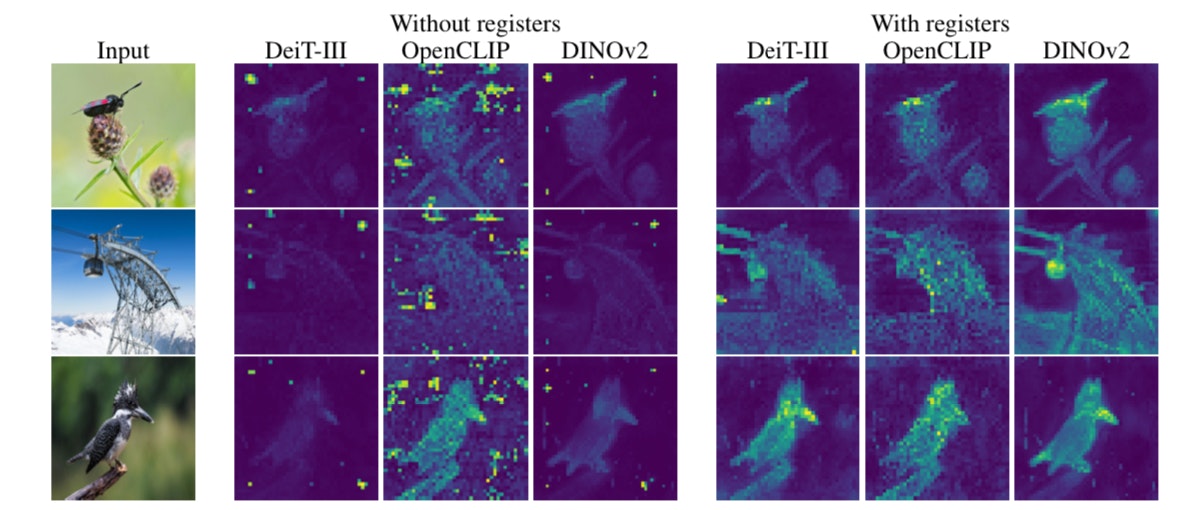
上記の図は、Vision Transformerが生成するアテンションマップにおいて、アーティファクトがどのように現れるかを示しています。左が提案手法無しで、右が提案手法(Register)を用いた場合です。右と左を比較すると、確かにノイズの様なものが高ノルムトークンとして誤って強調されていることが観察できます。
提案手法
研究チームは、アーティファクトがViTの内部計算に使われるトークンであることを発見しました。これに対する解決策として、入力シーケンスに追加の「レジスタトークン」を導入することで、これらの問題を修正します。このアプローチにより、アーティファクトを根本から解決し、ViTモデルの性能を向上させることが可能になります。
図2: 提案手法の概念図
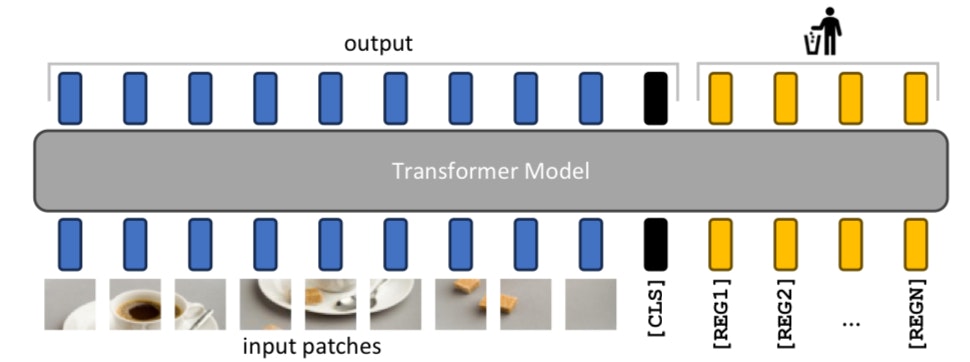
図2は、入力シーケンスにレジスタトークンを追加することでアーティファクトがどのように修正されるかを示しています。提案手法は、パッチ埋め込み層の後に新しいトークンとして明示的にレジスタトークンを追加することで、モデルがこれらをレジスタとして使用することを学習できるようにします。これらのトークンは学習可能な値を持ち、ViTの最後には、[CLS]トークンとパッチトークンのみが画像表現として使用され、レジスタトークンは破棄されます。
このアプローチにより、ViTモデルからアーティファクトを完全に取り除くことができ、密度の高い予測タスクとオブジェクト発見において性能を向上させます。
評価実験
図3: 実験結果
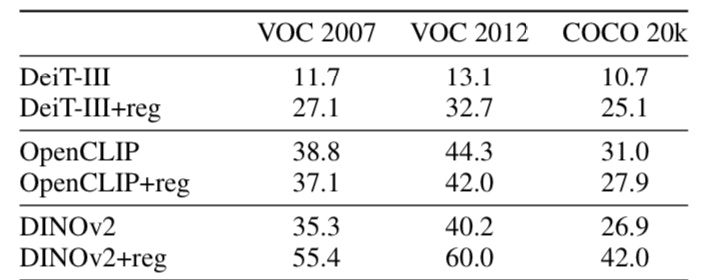

図3は、提案手法を適用した後のPASCAL VOC 2007、2012、およびCOCO 20kデータセットに対して行われた教師無しオブジェクト検出タスクの結果を示しています。この結果では、レジスタトークンを追加したDINOv2モデルが、追加しない場合に比べて大幅に改善されたことが観察されました。
また、レジスタトークンの定性評価から、異なるレジスタトークンが異なる注目パターンを持ち、シーン内の異なるオブジェクトに注目することが自然に生じることが明らかになりました。これは、レジスタトークンがモデルの学習過程において特定の制約を必要としないことを示しています。
結論
「Vision Transformers Need Registers」は、DINOv2モデルなどのVision Transformer (ViT) モデルの特徴マップに現れるアーティファクト(不要な特徴や異常値)を特定し、これが複数の代表的なモデルに共通する現象であることを発見しました。これらのアーティファクトは、Transformerモデルの出力で外れ値のノルム値に相当するトークンに対応し、モデルが低情報エリアからのトークンを自然に再利用し、異なる目的のために再目的化するという解釈を提案しています。その対策として、入力シーケンスに追加のトークンを付加するシンプルな手法を提案し、これによりアーティファクトが完全に除去され、密集予測タスクとオブジェクト発見のパフォーマンスが向上することを発見しました。さらに、この解決策がDeiT-IIIやOpenCLIPなどの教師あり学習モデルにおいても同様のアーティファクトを除去することができ、提案手法の一般性を確認しています。
Githubで実装コードも公開されているので、良かったら試してみると良いかもしれません。
https://github.com/kyegomez/Vit-RGTS
参考文献: 「Vision Transformers Need Registers」, 著者 [Timoth{'e}e Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski], 掲載会議 [The Twelfth International Conference on Learning Representations] 2024.