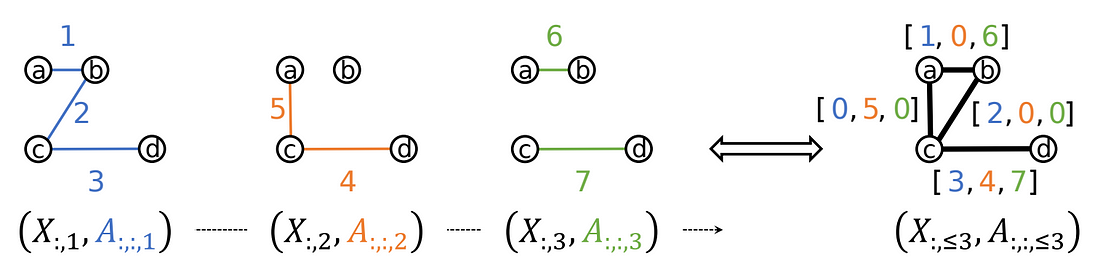はじめに
ICLR(International Conference on Learning Representations)2023の
OpenReviewで読むことができる論文のnotable top5%を紹介していきます。
※間違っている所もあると思いますので、留意して読んで頂けると幸いです
目次
- Encoding Recurrence into Transformers
- Modeling content creator incentives on algorithm-curated platforms
- Transfer NAS with Meta-learned Bayesian Surrogates
- Scaling Up Probabilistic Circuits by Latent Variable Distillation
- A Kernel Perspective of Skip Connections in Convolutional Networks
- WikiWhy: Answering and Explaining Cause-and-Effect Questions
- The Role of Coverage in Online Reinforcement Learning
- Is the Performance of My Deep Network Too Good to Be True? A Direct Approach to Estimating the Bayes Error in Binary Classification
- Offline Q-learning on Diverse Multi-Task Data Both Scales And Generalizes
- What learning algorithm is in-context learning? Investigations with linear models
- Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning
- When and Why Vision-Language Models Behave like Bags-Of-Words, and What to Do About It?
- Confidence-Conditioned Value Functions for Offline Reinforcement Learning
- On the Sensitivity of Reward Inference to Misspecified Human Models
- Time Will Tell: New Outlooks and A Baseline for Temporal Multi-View 3D Object Detection
- Dichotomy of Control: Separating What You Can Control from What You Cannot
- Learning where and when to reason in neuro-symbolic inference
- On the duality between contrastive and non-contrastive self-supervised learning
- DreamFusion: Text-to-3D using 2D Diffusion
- Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
- Universal Few-shot Learning of Dense Prediction Tasks with Visual Token Matching
- Mitigating Gradient Bias in Multi-objective Learning: A Provably Convergent Approach
- ReAct: Synergizing Reasoning and Acting in Language Models
- Do We Really Need Complicated Model Architectures For Temporal Networks?
Encoding Recurrence into Transformers
RNN層を、Self-Attentionのpositinal encoding matrixに書き換える手法を提案。
この書き換える行列はRecurrence Encoding Matrix (REM)と呼ばれ、再帰構造をMulti-head Attentionのpositional encodingに変換することが可能。
これにより、再帰構造を簡単にTransformerに組み込むことが可能であり、REMを用いた、Self-Attention with Recurrence (RSA) が提案された。RSAは、REMの再帰的な帰納バイアスを利用し、Transformerよりも優れたサンプル効率を達成することができる。
また、Self-Attentionは残りの非再帰特徴をモデル化するために使用される。
REM, Self-Attentionの比率は学習データによって調整され、RSAモジュールの有効性は4つの学習タスクによって示された。
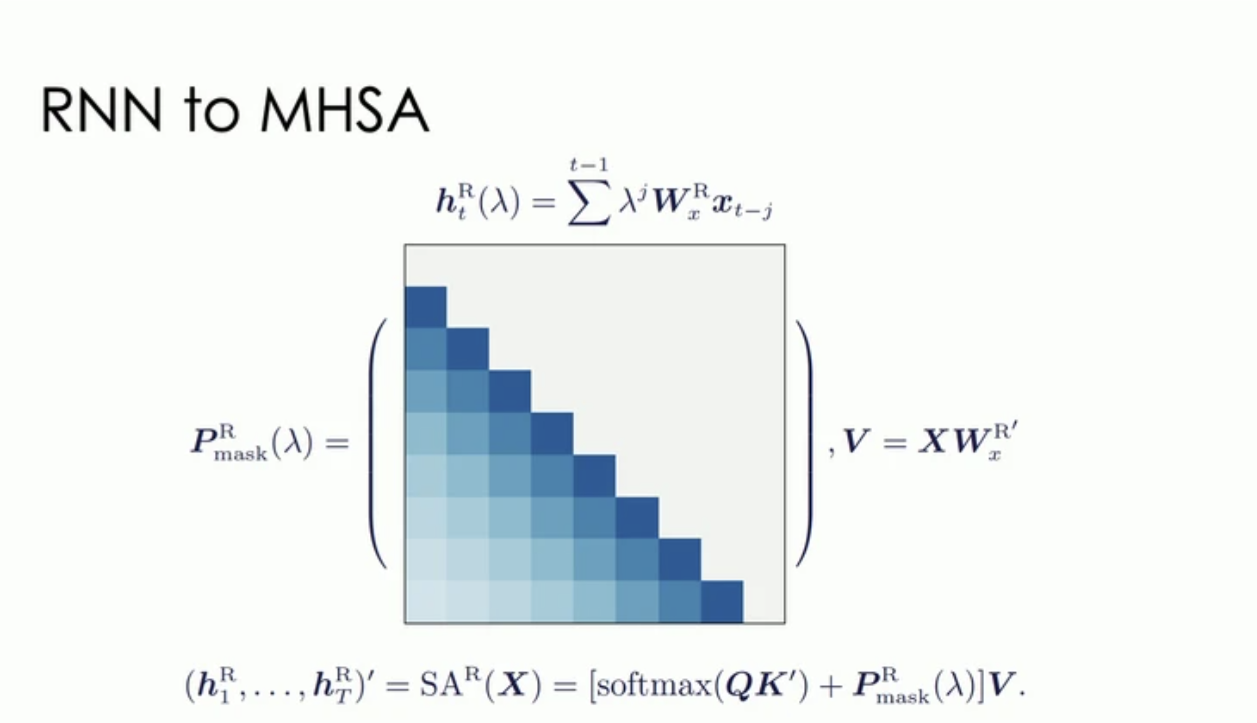
ICLR 2023 Encoding Recurrence into Transformers Oral. https://iclr.cc/virtual/2023/oral/12649.
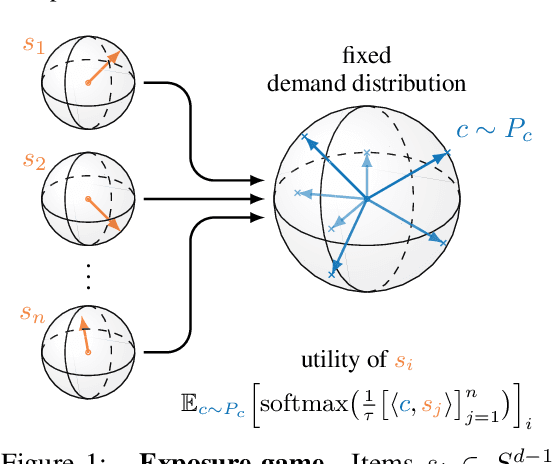
Modeling content creator incentives on algorithm curated platforms
Youtube, Instagram, TikTokなどのオンラインプラットフォーム上では、クリエーターたちがユーザーの興味を引くために競争している。彼らの作品は、そのオンラインプラットフォーム上の仕様に大きく依存している。
より多くのユーザーの興味を引くため、クリエーターはその仕様に合わせて戦略をたてる。
この論文では、これらのダイナミクスを「exposer game」と呼ばれるモデルで形式化する。
このモデルを用いて、プラットフォームの仕様がクリエーターの行動に与える影響を形式的に分析している。
このモデルは、モダンな因子分解や深層二段塔アーキテクチャを含む多くのアルゴリズムを考慮に入れている。
MovieLensとLastFMのデータセットを用いて、エクスポージャーゲームの結果を実証した結果、アルゴリズムの探索性とコンテンツの多様性、モデルの表現力とジェンダーベースのユーザーとクリエーターのグループに対するバイアスとの間に強い依存関係があることが示されている。
また、一見無害に見えるアルゴリズムの選択でも、このゲームの結果に大きな影響を与えることを証明している。
https://iclr.cc/virtual/2023/poster/10716.
Transfer NAS with Meta learned Bayesian Surrogates
ニューラルアーキテクチャサーチ(NAS)において新しいSurrogate-Model(サロゲートモデル)を提案。サロゲートモデルとは、簡単にいうと評価するシステムの代わりに結果を出力する代理モデル。
探索を高効率にするSurrogate-Modelとはなんなのか
異なるデータセットに対する以前のアーキテクチャ評価をメタ学習することで、計算コストを削減し、異なるデータセットやタスクに対するロバスト性を向上。
メタ学習入門
従来のニューラルアーキテクチャサーチ(NAS)手法は、新しい問題が出てくるたびに、最適なアーキテクチャをゼロから探索する必要があった。これは非常に計算コストが高く、また、新しいデータセットや実験条件に対するロバスト性が不足している場合が多い。
しかし、この研究では、以前に解決した問題で有効だったアーキテクチャを新しい問題に適用することで、これらの課題を解決している。
どのように適用するかというと、サロゲートモデルを用いて、以前の問題でのアーキテクチャ評価を「メタ学習」することにより、新しい問題に対しても高速かつ効率的に最適なアーキテクチャを探索できるようになる。
さらに、この手法は複数のデータセットで高い性能を示している。
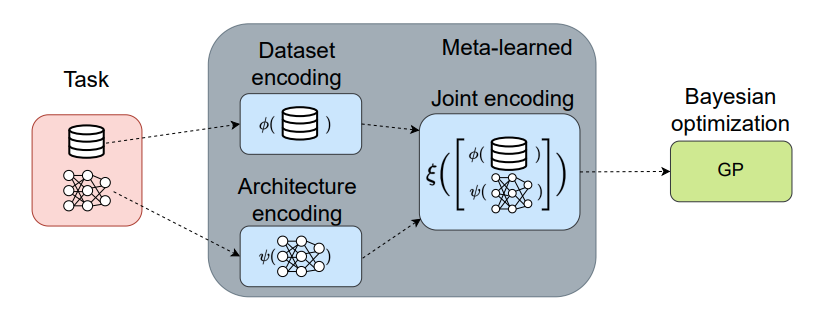
https://openreview.net/forum?id=paGvsrl4Ntr
Scaling Up Probabilistic Circuits by Latent Variable Distillation
確率回路(Probabilistic Circuits: PCs)をスケーリングアップするための新しい手法を提案。PC内のパラメーターの数が増加すると、パフォーマンスがすぐに頭打ちになる。これは、optimizerが大規模なPCの表現力を最大限に活用できていないことを意味する。
そこで、**潜在変数の蒸留(Latent Variable Distillation)**という手法を用いて、確率回路の性能を大幅に向上させる方法を提案。
具体的には、Transformerベースの深い生成モデルから確率回路に潜在変数を割り当てることで、確率回路の最適化にガイダンスを提供している。
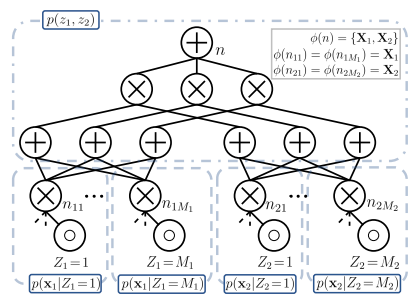
https://openreview.net/pdf?id=067CGykiZTS
A Kernel Perspective of Skip Connections in Convolutional Networks
畳み込みニューラルネットワーク(CNN)におけるスキップ接続(Residual Networks、ResNets)の性質を、Gaussian ProcessとNeural Tangent kernelsを通じて研究。
ReLU活性化関数を用いた場合、スキップ接続を使用しない同じカーネルと比較して、これらのresidualカーネルの固有値が多項式的に同じ速度で減衰することを示した。
一方、residualカーネルはより局所的に分布が偏っていることも示した。
さらに、スキップ接続により、条件数が少なくなることで、勾配降下法より高速な収束を可能にすることを示した。
WikiWhy: Answering and Explaining Cause and Effect Questions
The Role of Coverage in Online Reinforcement Learning
Is the Performance of My Deep Network Too Good to Be True? A Direct Approach to Estimating the Bayes Error in Binary Classification
Offline Q learning on Diverse Multi Task Data Both Scales And Generalizes
What learning algorithm is in context learning? Investigations with linear models
ICL(in-context learning)とは、モデルのパラメータを変えずに、入力データ側で工夫して学習させる方法。
例えば、chatgptにいきなり複雑なプロンプトを入力するよりも、複雑なプロンプトを分解して説明したり、例などを用いて入力した方が精度が上がる。
Transformer系のモデルは、このICLに対して優れた性能を示しており、
この論文では、Transformer系のモデルは、線形モデルに対して既存の学習アルゴリズム(例えば、勾配降下法や最小二乗法)を暗黙的に実装していることを数学的、既存アルゴリズムとの比較、および実験より証明した。
また、層の深さやデータのノイズレベルに応じて、予測モデルが変わることも明らかにした。
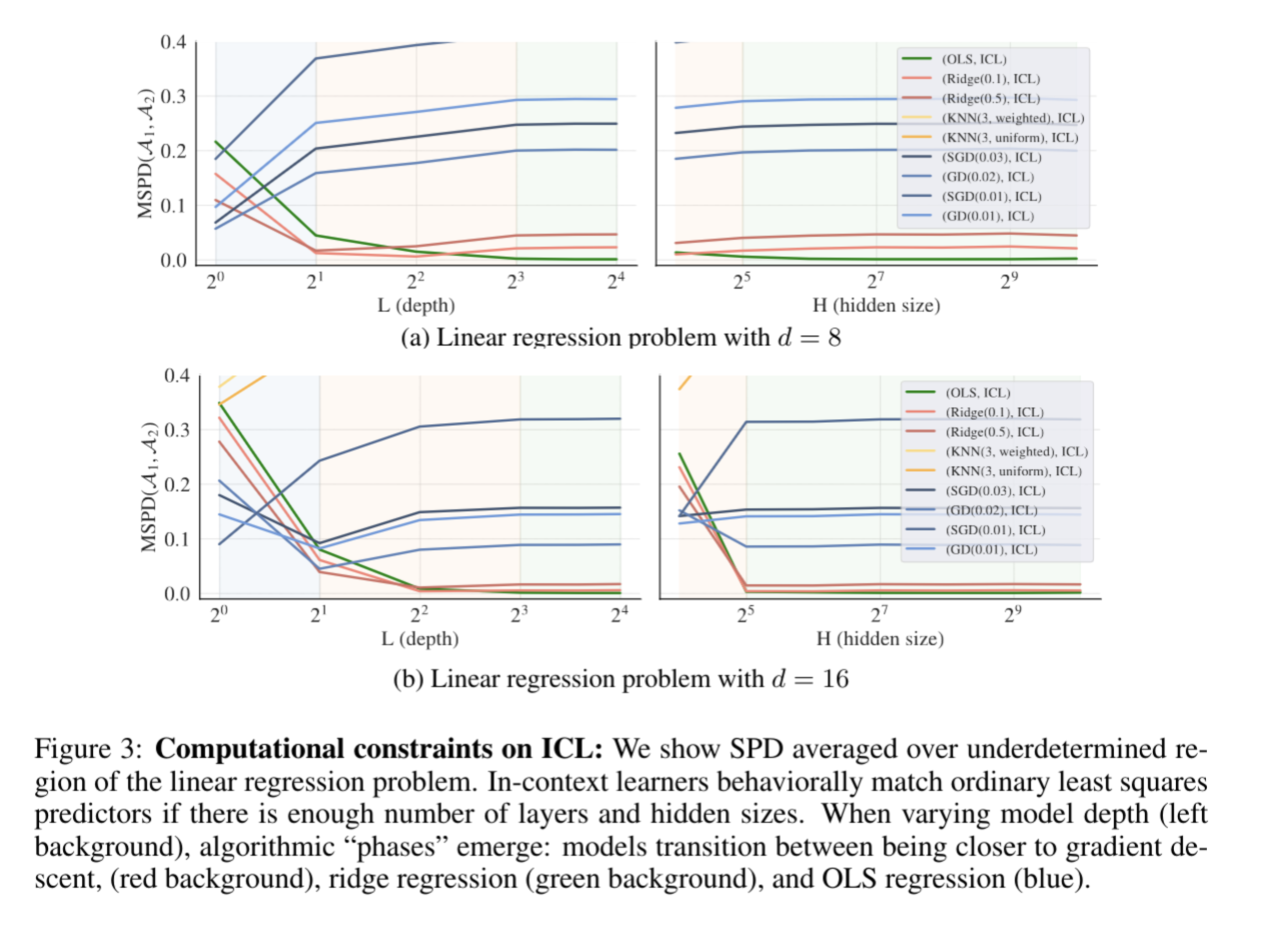
https://openreview.net/forum?id=0g0X4H8yN4I
Towards Understanding Ensemble, Knowledge Distillation and Self Distillation in Deep Learning
When and Why Vision Language Models Behave like Bags Of Words, and What to Do About It?
ビジョンと言語のモデル(VLMs)がどれだけオブジェクトと属性の関係を理解しているかを評価するための新しいベンチマーク、ARO(Attribution, Relation, and Order)を提案。
AROは、オブジェクトの属性を理解するためのテスト、関係性を理解するためのテスト、順序に敏感かどうかを評価するテストなどが含まれている。既存のベンチマークよりもはるかに大規模で、50,000以上のテストケースを提供しており、これにより、VLMsの関係性や順序に対する理解がより詳細に評価できる。
著者は、VLMsが関係性や順序に対する理解が不足している場合に、要素のランダムな袋詰め=bags-of-wordsのように振る舞うことがあると指摘。これを解決するための方法として、composition-aware hard negative miningという手法を提案。
この手法は、ネガティブな例(つまり、モデルが誤って予測しがちな例)を選ぶ際に、構成的な情報(要素間の相互関係や順序など)を考慮する。
AROベンチマークを用いて、提案された手法が順序や構成に関するタスクでの性能を大幅に向上させることを示した。
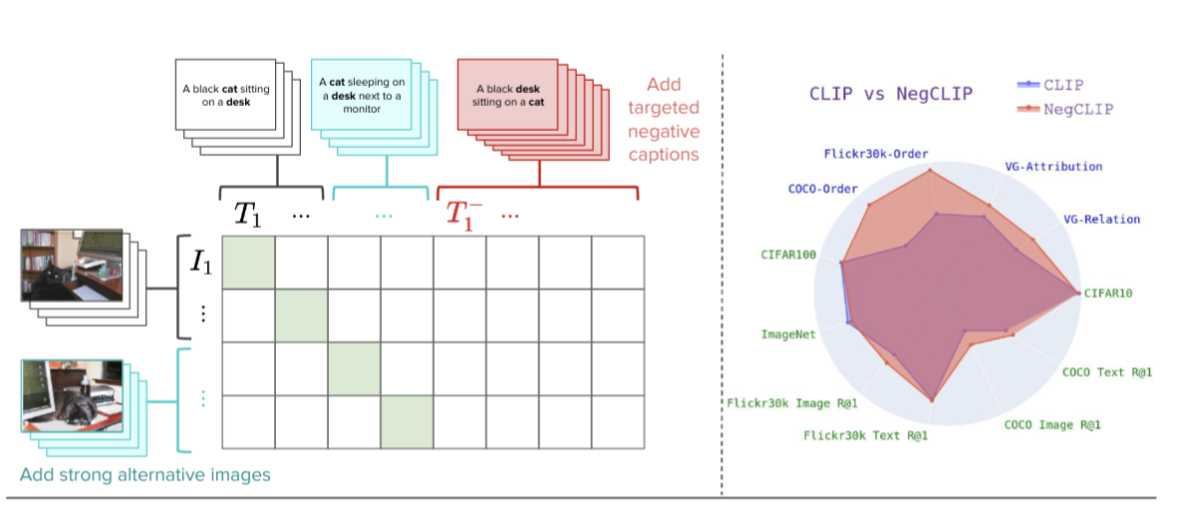
https://openreview.net/forum?id=KRLUvxh8uaX
Confidence Conditioned Value Functions for Offline Reinforcement Learning
On the Sensitivity of Reward Inference to Misspecified Human Models
Time Will Tell: New Outlooks and A Baseline for Temporal Multi View 3D Object Detection
3Dオブジェクト検出において、過去の長時間のフレーム関係と短期的な時間でのフレーム関係を組み合わせて(fusion)推論する新しい手法を提案。
先行研究では、時間的な考慮がオブジェクトの認識を改善するために有用であることが示されているが、限られた履歴しか使用していないため、その効果は限定的であった。
長期的な履歴で粗いマッチングと短期的なマッチングで細かいマッチングを行い、両者を融合することで高い性能を達成している。
先行研究ではこのような粒度の違いを考慮した融合は少ない。
nuScenesデータセットで先行研究に比べて明確に高い性能を示している。具体的には、Mean Average Precision(mAP)で5.2%、Normalized Detection Score(NDS)で3.7%の向上が確認されている。
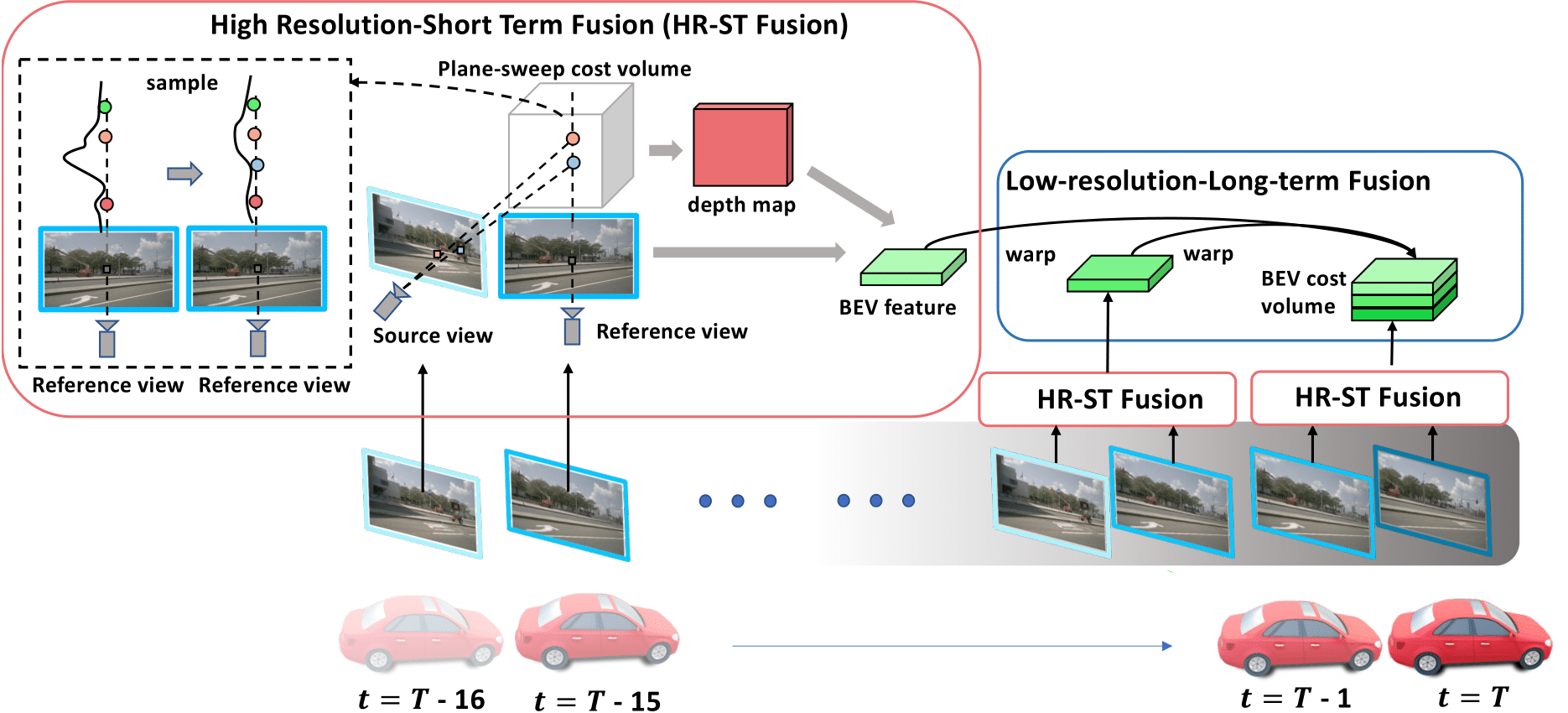
https://openreview.net/forum?id=H3HcEJA2Um
Dichotomy of Control: Separating What You Can Control from What You Cannot
Learning where and when to reason in neuro symbolic inference
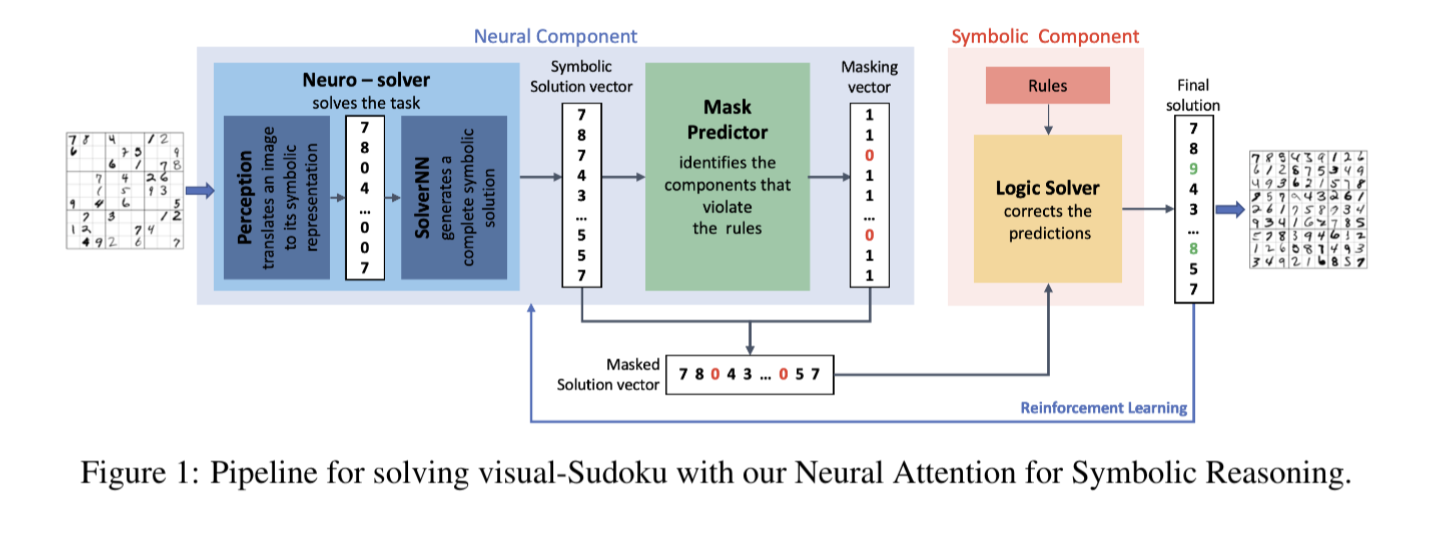
ニューラルネットワークの出力に対する「厳格な制約」の統合が非常に重要であり、AIに対する信頼を高めるために必要である。しかし、既存の方法はこの問題に対して十分な解決策を提供していないと指摘。
この論文での手法は、その問題を解決し、効率と正確性のバランスを取ることができる。
symbolic reasoning module、neuro-symbolic perspectiveの2つのモジュールを提案。
symbolic reasoning moduleは、タスク間での制約による損失など、全体な予測誤差を修正する。
一方、neuro-symbolic perspectiveは、タスク自体の予測誤差を減らすのに集中させる。これにより、制約なしの推論のコストと、推論時に全てを網羅的に推論するのにかかるコストとの間で良いバランスが取れる。
visual-Sudokuというタスクで、既存の最先端の手法よりも優れた性能を示した。また、視覚的なシーングラフ予測にも有用であると示している。
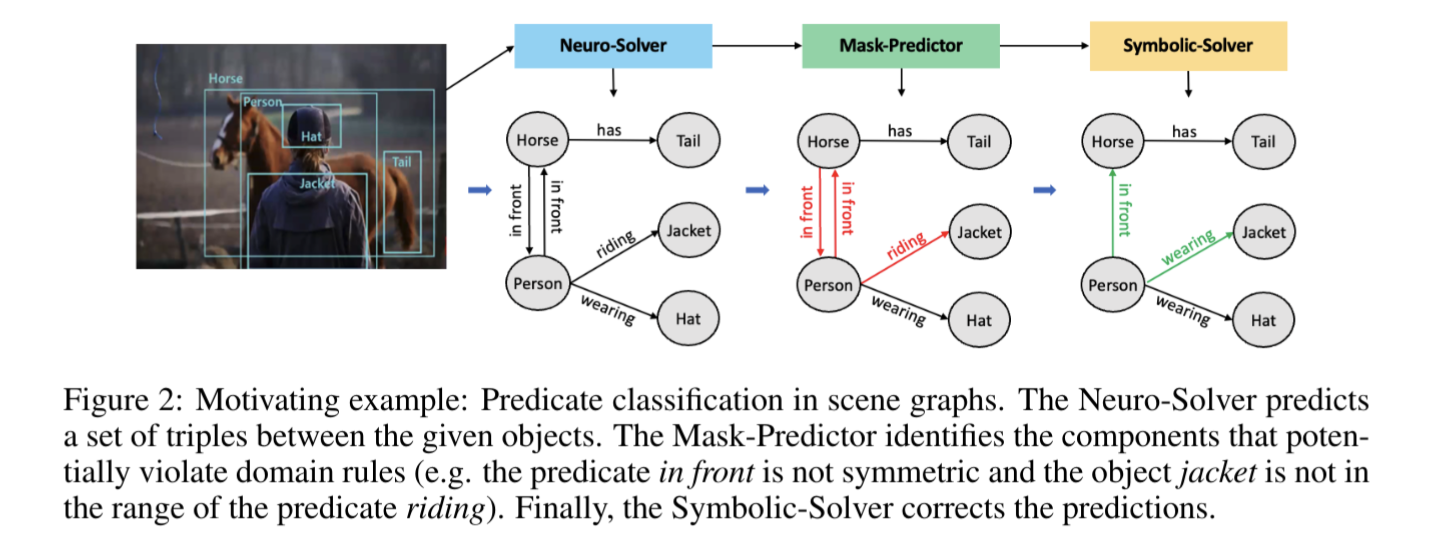
On the duality between contrastive and non contrastive self supervised learning
DreamFusion: Text to 3D using 2D Diffusion
Sampling is as easy as learning the score: theory for diffusion
models with minimal data assumptions
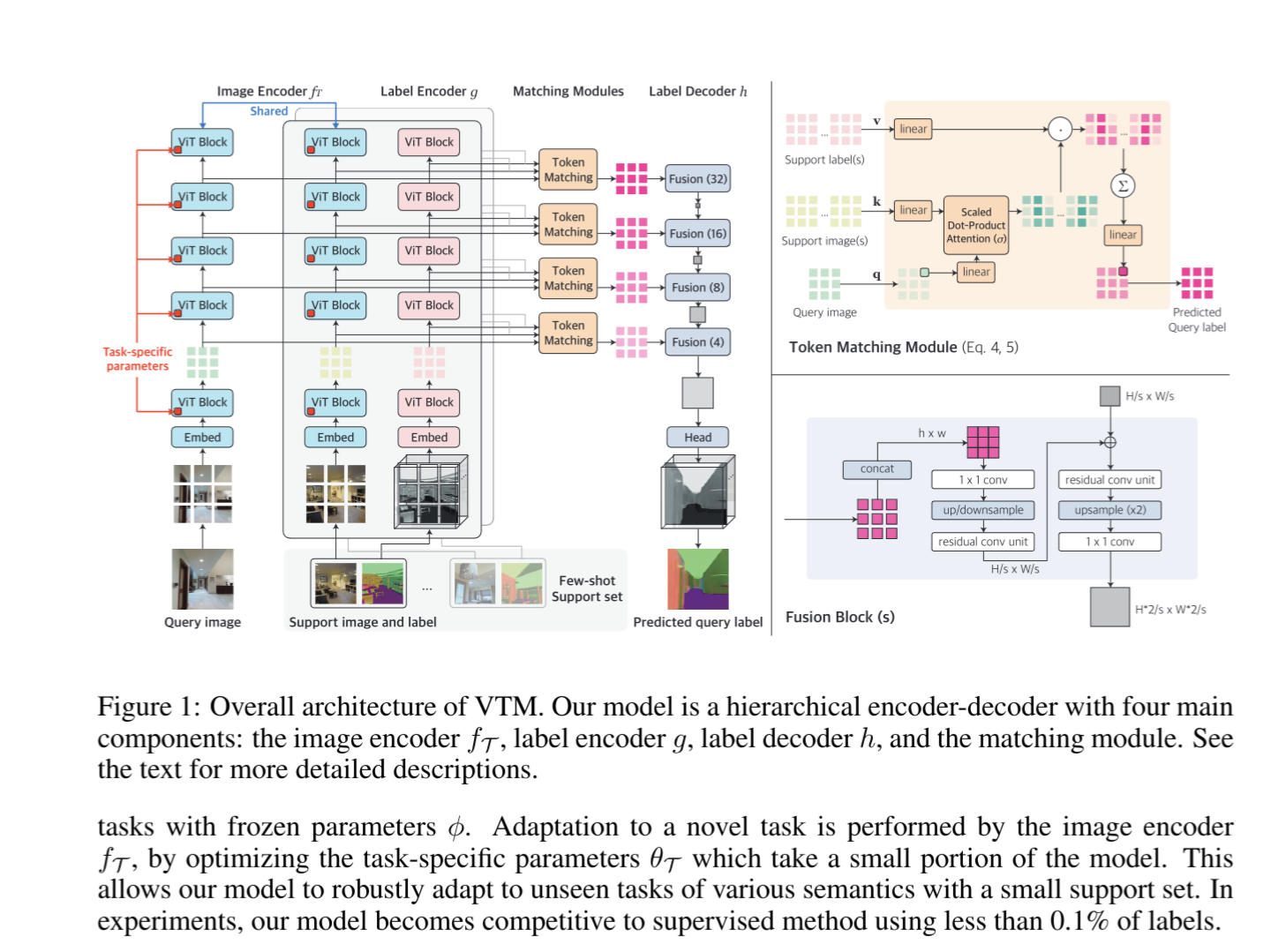
Universal Few shot Learning of Dense Prediction Tasks with Visual Token Matching
Dense Prediction(画像内の各ピクセルに対して何らかの推論を行う手法)において、
Visual Token Matching(VTM)という手法を提案。
VTMは、入力画像と、サポートセット内の画像とラベルのTokenに基づいて非パラメトリックなマッチングを行う。これにより、少数のラベル付きデータからでも効率的にタスクに適応することができる。
また、多くのパラメータをタスク間で共有することで、*未見の新しいタスクに対しても迅速に適応することが可能」。
これまでのfew-shot learningは、特定のタスク(例:セグメンテーションのみ)に限定されていた。
VTMにより、任意のDense predictionに対応可能な、ユニバーサルなfew-shot learningモデルを作成。
10個のDense prediction タスクで実験をした。(semantic segmentation (SS), surface normal (SN), Euclidean distance (ED), Z-buffer depth (ZD),
texture edge (TE), occlusion edge (OE), 2D keypoints (K2), 3D keypoints (K3), reshading (RS),
and principal curvature (PC))
VTMは、少ない数のラベル付き例(全訓練セットの0.004%以下)を使用しても、多くのタスクで教師あり方法と同等またはそれ以上の性能を発揮した。
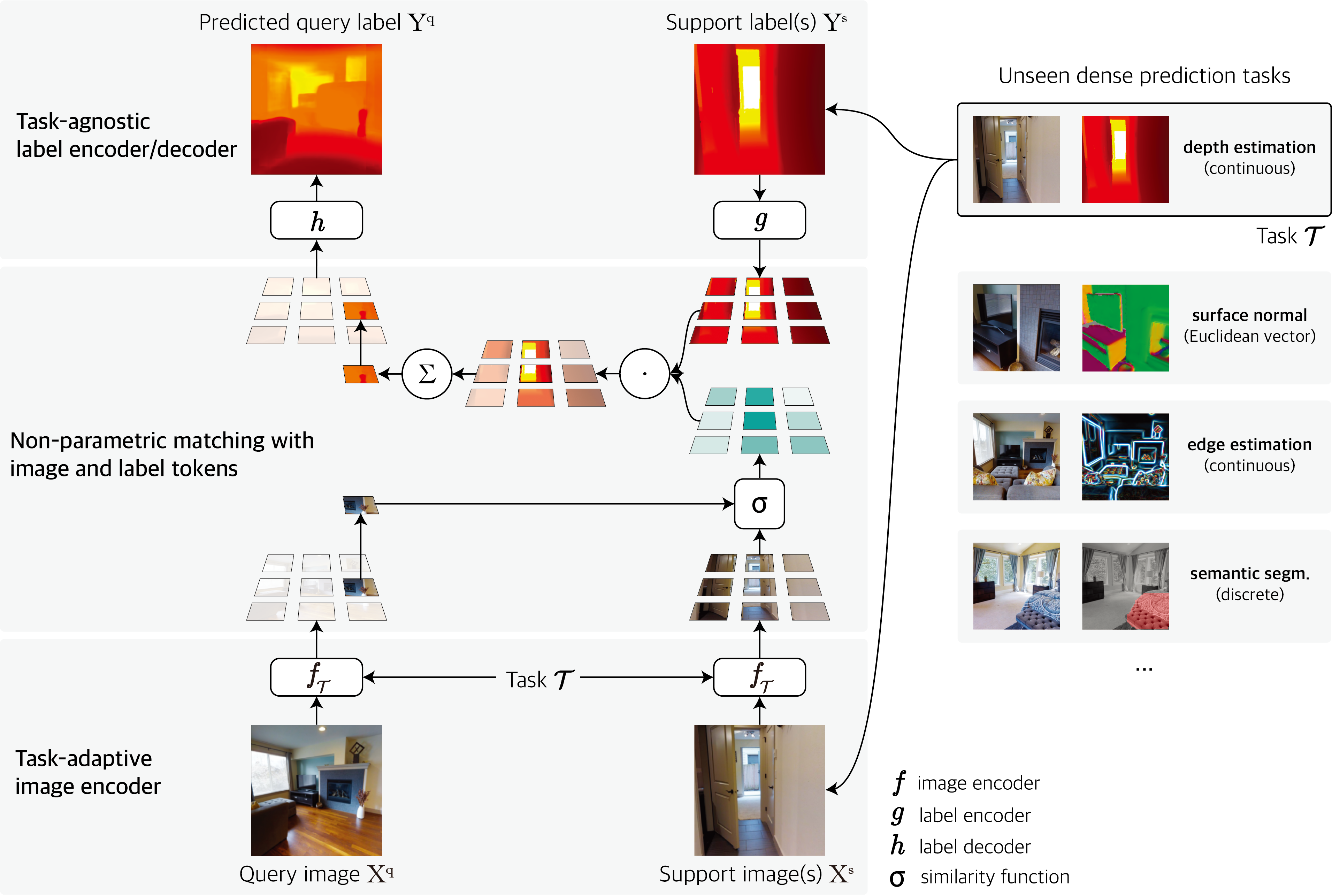
https://openreview.net/forum?id=88nT0j5jAn
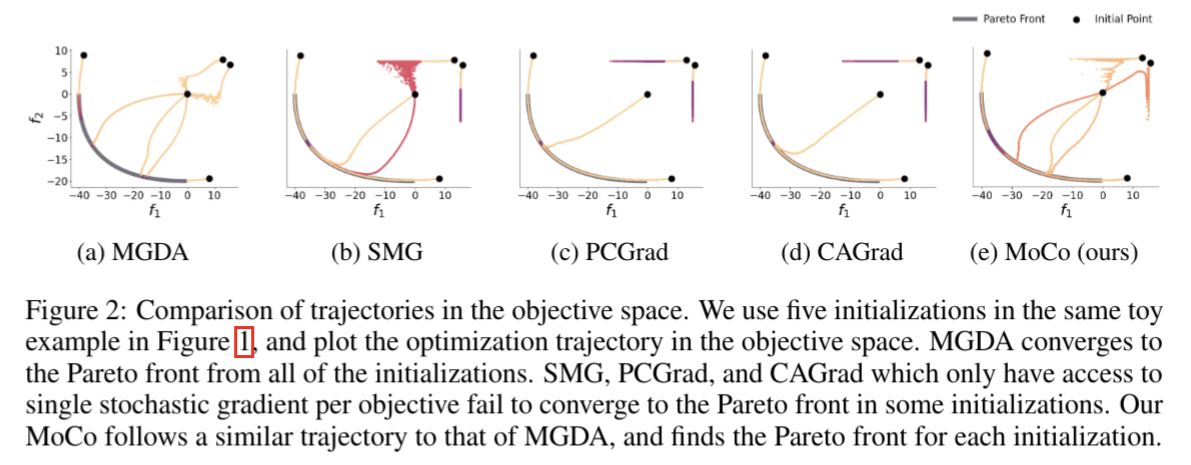
Mitigating Gradient Bias in Multi objective Learning: A Provably Convergent Approach
Multi-objective Learningにおける最適化(Multi-objective Optimization)における勾配バイアス(Gradient Bias)を軽減する、MoCo(多目的勾配保証)と呼ばれる新しい方法を開発。非凸設定でもバッチサイズを増やすことなく収束を保証できる。
既存の確率的多目的勾配方法(例:MGDA, PCGrad, CAGradなど)は、バイアスのあるノイズ勾配方向を採用しており、実験的な性能が低下する傾向がある。この論文の方法は、バッチサイズを増やすことなく収束を保証できる点が特徴。
Multi-objective Learning(多目的学習)は、複数の目的関数を同時に最適化する学習手法。
例えば、機械学習モデルが精度と速度、または公平性と効率性など、複数の目標を同時に達成する必要がある場合に用いられる。
勾配バイアスとは、多目的最適化の過程で各目的関数の勾配が不均等に扱われることを指す。これが起こると、一部の目的関数が他の目的関数よりも優先されてしまい、全体の最適化がうまく行かない可能性がある。
勾配バイアスを軽減することで、各目的関数が均等に扱われ、よりバランスの取れた解が得られる。
非凸関数は、局所最適解が複数存在する可能性があり、そのため全体の最適解を見つけるのが一般には困難である。そのため、この手法は有用である。
パレート最適化とは
ReAct: Synergizing Reasoning and Acting in Language Models
Do We Really Need Complicated Model Architectures For Temporal Networks?
SNSのフォロー、フォロワー関係などのような、
時間により変動するグラフネットワークを学習するタスク、いわゆるTenporal Graph Learning(TGL)において複雑なモデルが本当に必要かどうかを問題にした。
著者らはGraphMixerというシンプルなアーキテクチャを提案しており、このモデルはノード間のリンク、つまりノード間の関係・繋がりの予測において優れた性能を発揮している。
先行研究では、RNN(Recurrent Neural Network)やSAM(Self-Attention Mechanism)が一般的に使用されているが、この論文ではそれらが必ずしも必要でないことを示している。
GraphMixerは三つの主要なモジュールから成り立っている。
link-encoder:MLP(Multi-Layer Perceptrons)を用いて時間的なリンクの情報を要約。
node-encoder:近傍のaverage poolingを用いてノード情報を要約。
MLP-based link classifier:エンコーダの出力を基にMLPを用いてリンク予測を行う。
Reddit Wiki MOOC LastFM GDELT GDELT-ne GDELT-eなどのデータセットにより比較実験をし、有意性を示した。