1. 概要
本研究では、航空画像における小物体検出のための新しいDETRモデル「DQ-DETR」を提案しています。従来のDETRモデルは固定数のオブジェクトクエリを使用するため、画像内のオブジェクト数が大きく異なる航空画像データセットには適していませんでした。DQ-DETRは以下の3つの主要コンポーネントを導入することでこの問題を解決します:
- カテゴリカル計数モジュール
- 計数ガイド付き特徴強化
- 動的クエリ選択
これらのコンポーネントにより、画像内のオブジェクト数に応じてクエリ数を動的に調整し、小物体の位置情報を強化します。実験結果では、DQ-DETRがAI-TOD-V2データセットにおいてState-of-the-artの性能を達成し、従来手法を大幅に上回ることが示されました。
2. 研究背景と課題
近年、物体検出タスクにおいてDETR (DEtection TRansformer) に基づくモデルが大きな成功を収めています。しかし、航空画像における小物体検出では依然として課題が残されていました。
主な問題点は以下の2つです:
- オブジェクトクエリの位置情報が小物体検出に適していない
- 固定数のクエリを使用するため、画像間でオブジェクト数に大きな差がある場合に対応できない

図1: 既存DETRモデルのクエリ戦略比較
図1は、既存のDETRモデルのクエリ戦略を比較しています。Deformable DETRは300個の疎なクエリを使用し、DDQ-DETRは900個の密なクエリを使用しています。しかし、いずれも固定数のクエリであるため、画像内のオブジェクト数が大きく異なる場合に対応できません。
例えば、AI-TOD-V2データセットでは、一枚の画像に含まれるオブジェクト数が10未満のものから1500以上のものまで大きな幅があります。固定数のクエリを使用すると、以下のような問題が生じます:
- オブジェクト数が少ない画像: 不要なクエリによる偽陽性(FP)の増加
- オブジェクト数が多い画像: クエリ数不足による未検出(FN)の増加
これらの課題に対応するため、本研究では動的にクエリ数を調整する新しいアプローチを提案しています。
3. 提案手法の詳細説明
DQ-DETRは以下の3つの主要コンポーネントから構成されています:
- カテゴリカル計数モジュール
- 計数ガイド付き特徴強化
- 動的クエリ選択
3.1 全体のアーキテクチャ
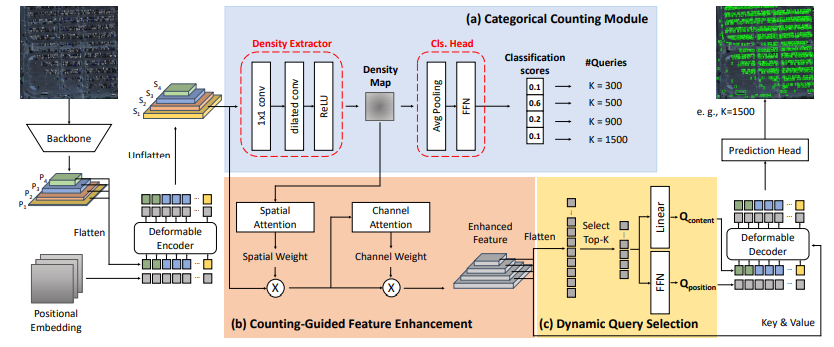
図2: DQ-DETRの全体のアーキテクチャ
DQ-DETRの全体構造は図2のようになっています。基本的なDETRモデルの構造を踏襲しつつ、以下の新しいモジュールを導入しています:
- (a) カテゴリカル計数モジュール
- (b) 計数ガイド付き特徴強化モジュール
- (c) 動的クエリ選択モジュール
処理の流れは以下の通りです:
- 入力画像からCNNバックボーンを用いてマルチスケール特徴を抽出
- Transformerエンコーダで視覚特徴を生成
- カテゴリカル計数モジュールでTransformerデコーダで使用するオブジェクトクエリ数を決定
- 計数ガイド付き特徴強化モジュールでエンコーダの視覚特徴を強化
- 動的クエリ選択モジュールでオブジェクトクエリを洗練
3.2 カテゴリカル計数モジュール
このモジュールは画像内のオブジェクト数を推定します。密度抽出器と分類層から構成されています。
-
密度抽出器:
- エンコーダのマルチスケール視覚特徴(EMSV特徴)の中で最も大きな特徴マップを入力として使用
- 一連の拡張畳み込み層を通して密度マップを生成
- 拡張畳み込みにより、受容野を拡大し小物体の長距離依存関係を捉える
-
オブジェクト数分類:
- 2つの線形層からなる分類層を使用
- オブジェクト数Nを4つのレベルに分類
- N ≤ 10
- 10 < N ≤ 100
- 100 < N ≤ 500
- N > 500
回帰ではなく分類を採用している理由:
- AI-TOD-V2データセットでは画像ごとのオブジェクト数に大きな差があり(1〜2267個)、正確な数値を回帰することが困難
- 分類の方がモデルの学習が安定する
3.3 計数ガイド付き特徴強化モジュール (CGFE)
このモジュールは、カテゴリカル計数モジュールで生成された密度マップを用いてエンコーダのEMSV特徴を洗練します。空間のcross attentionとチャンネルのattentionの2つの操作を行います。
-
空間のcross attention:
- 密度マップをダウンサンプリングし、EMSV特徴と同じ形状のマルチスケール計数特徴マップを生成
- 平均プーリングと最大プーリングを適用し、7x7畳み込みとシグモイド関数を通して空間attention mapを生成
- 生成された空間attention mapとEMSV特徴を要素ごとに掛け合わせて空間強化特徴を得る
-
チャンネルのattention:
- 空間強化特徴に対して平均プーリングと最大プーリングを適用
- 共有MLPを通してチャネルアテンションマップを生成
- チャネルアテンションマップと空間強化特徴を掛け合わせて最終的な計数ガイド付き強化特徴マップを得る
これらの操作により、小物体の空間情報が強化されます。
3.4 動的クエリ選択
このモジュールでは、カテゴリカル計数モジュールの結果に基づいてTransformerデコーダで使用するクエリ数Kを決定します。
- N ≤ 10 の場合: K = 300
- 10 < N ≤ 100 の場合: K = 500
- 100 < N ≤ 500 の場合: K = 900
- N > 500 の場合: K = 1500
また、CGFEモジュールで強化された特徴マップを用いてクエリの内容と位置情報を改善します:
- 強化された特徴マップをピクセルレベルでフラット化
- 分類スコアに基づいて上位K個の特徴を選択
- 選択された特徴を用いてクエリの内容と位置情報を生成
- クエリの内容: 線形変換を適用
- クエリの位置: FFNを用いてバイアスを予測し、元のアンカーボックスを洗練
これにより、画像の密度(混雑または疎)に基づいてクエリが調整され、小物体の検出が容易になります。
4. 評価実験と結果
4.1 データセットと評価指標
主な実験はAI-TOD-V2データセットを用いて行われました。
- AI-TOD-V2データセット:
- 28,036枚の航空画像、752,745個のアノテーション付きオブジェクト
- 平均オブジェクトサイズ: 12.7ピクセル (86%のオブジェクトが16ピクセル未満)
- 1枚の画像あたりのオブジェクト数: 1〜2667個 (平均24.64個、標準偏差63.94)
評価指標:
- AP (Average Precision): AP50からAP95までの平均値 (IoUの閾値を0.05間隔で変化)
- APvt, APt, APs, APm: 非常に小さい、小さい、小、中サイズのオブジェクトに対するAP
4.2 主な実験結果
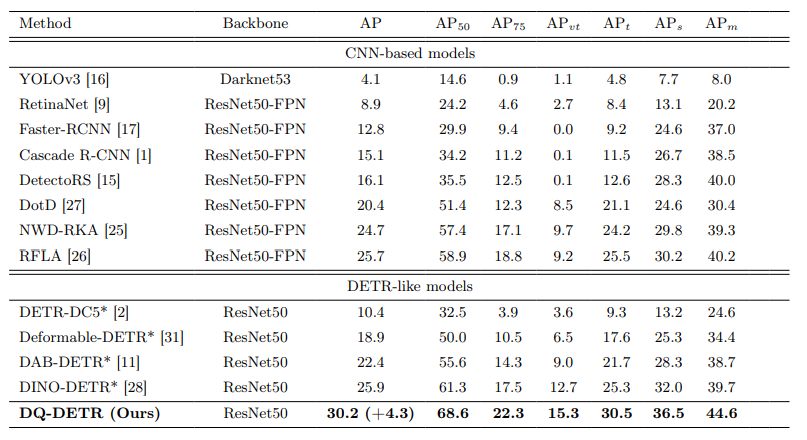
図3: AI-TOD-V2データセットにおける実験結果
図3は、AI-TOD-V2テストセットにおける実験結果を示しています。DQ-DETRは以下の点で優れた性能を示しています:
- 最高のAP (30.2%) を達成
- ベースラインと比較して、APvt (+20.5%)、APt (+20.6%)、APs (+14.1%)、APm (+12.3%) で大幅な改善
- 特に非常に小さいオブジェクト (APvt) と小さいオブジェクト (APt) で顕著な性能向上
4.3 Ablation study
提案手法の各コンポーネントの有効性を検証するため、Ablation studyが行われました。
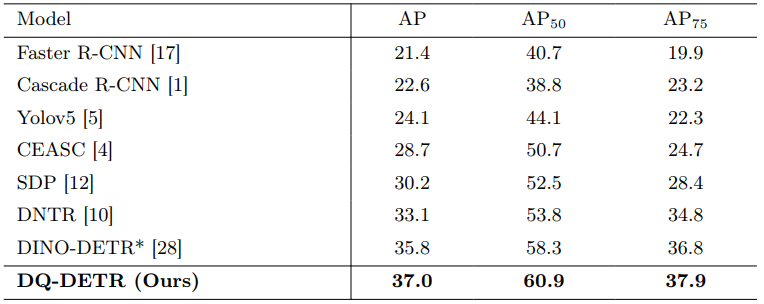
図4: Ablation studyの結果
図4から、以下のことが分かります:
- カテゴリカル計数モジュールと動的クエリ選択のみで、ベースラインから+2.2 APの改善
- 特徴強化を加えることで、さらに+2.1 APの改善
- 全てのコンポーネントを組み合わせることで、最高の性能 (30.2 AP) を達成
また、画像内のオブジェクト数に応じた性能分析も行われました:
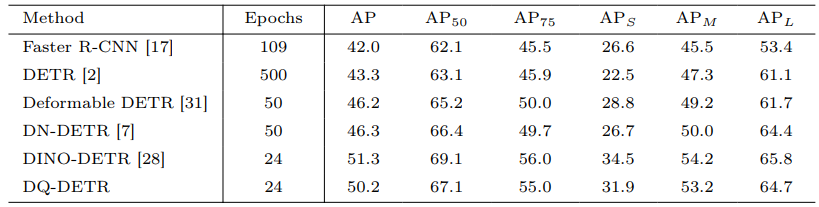
図5: オブジェクト数別の性能比較
図5から、以下のことが観察できます:
- オブジェクト数が少ない場合 (N ≤ 10、10 < N ≤ 100)、DQ-DETRは少ないクエリ数でベースラインを大きく上回る性能を示す
- オブジェクト数が非常に多い場合 (N > 500)、DQ-DETRはより多くのクエリを使用することで、特に非常に小さいオブジェクト (APvt) の検出で大幅な改善を達成
5. 結論と今後の展望
DQ-DETRは、航空画像における小物体検出のための新しいDETRベースのモデルとして、以下の点で大きな成果を上げました:
- カテゴリカル計数モジュール、計数ガイド付き特徴強化、動的クエリ選択という3つの新しいコンポーネントの導入
- 画像内のオブジェクト数に応じてクエリ数を動的に調整する機能の実現
- 小物体の位置情報を強化する効果的な手法の提案
- AI-TOD-V2データセットにおいてState-of-the-artの性能を達成
今後の研究の方向性としては、以下のような点が考えられます:
- より大規模なデータセットでの検証
- 異なるドメインや応用分野への適用
- 計算効率のさらなる改善
- 他のTransformerベースのモデルへの提案手法の適用
DQ-DETRの成功は、物体検出タスクにおけるTransformerモデルの可能性をさらに広げるものであり、今後の研究開発に大きな影響を与えると期待されます。
参考文献
- Liu, H. I., Huang, Y. X., Shuai, H. H., & Cheng, W. H. (2024). DQ-DETR: DETR with Dynamic Query for Tiny Object Detection. arXiv preprint arXiv:2404.03507v5.