はじめに
ICLR(International Conference on Learning Representations)2023の
OpenReviewで読むことができる論文のnotable top5%を紹介していきます。
※間違っている所もあると思いますので、留意して読んで頂けると幸いです
目次
- View Synthesis with Sculpted Neural Points
- AutoGT: Automated Graph Transformer Architecture Search
- Crossformer: Transformer Utilizing Cross-Dimension Dependency for Multivariate Time Series Forecasting
- Betty: An Automatic Differentiation Library for Multilevel Optimization
- Offline RL with No OOD Actions: In-Sample Learning via Implicit Value Regularization
- Win: Weight-Decay-Integrated Nesterov Acceleration for Adaptive Gradient Algorithms
- Towards Stable Test-time Adaptation in Dynamic Wild World
- MocoSFL: enabling cross-client collaborative self-supervised learning
- DaxBench: Benchmarking Deformable Object Manipulation with Differentiable Physics
- 3D generation on ImageNet
- Rethinking the Expressive Power of GNNs via Graph Biconnectivity
- Sparse Mixture-of-Experts are Domain Generalizable Learners
- Token Merging: Your ViT But Faster
- Learnable Behavior Control: Breaking Atari Human World Records via Sample-Efficient Behavior Selection
- Image as Set of Points
View Synthesis with Sculpted Neural Points
研究背景:
view synthesis とは、複数画像から3D視点を生成するタスクであり、拡張現実(AR)や仮想現実(VR)などに応用される。
既存の方法(例えばNeRF)はシーンの幾何学情報をニューラルネットワーク(MLP)でパラメータ化しているが、計算効率に欠点がある。

提案手法:
点群を用いたSculpted Neural Points(SNP)を提案。
一連の複数画像(シーン)を3D空間の点群として表現し、それをレンダリングするが、レンダリング過程を微分可能な数学的操作として定義する。これにより損失勾配を計算可能とする。
点群は、3D情報を抽出する技術(MVS)によって再構築され、その後不要な点の削除や重要な点の追加を行う(Point Sculpture)と呼ばれる技術を用いて最適化される。これにより正確で詳細な3D表現を実現し、精度の向上を図る。
また、球面調和関数を使用することで、異なる方向からの照明条件を効率的に近似し、物体表面の複雑な環境を表現することができる。

先行研究と比べてどこがすごいか:
NeRFよりも視覚的品質が優れており、レンダリング速度が100倍速い。
技術や手法の新規性、重要な部分:
SNP技術は、再構築されたポイントクラウドのエラーや穴に対する堅牢性を大幅に向上させる。さらに球面調和を用いた、視点に依存した点群特徴量と、点群ベースの新しいレンダリングパイプラインを導入している。
どうやって有効だと検証したか:
様々なベンチマーク(DTU, LLFF, NeRF-Synthetic, Tanks&Templesなど)での評価を行い、すべてのベースラインに対して同等またはより良い性能を示している。
AutoGT: Automated Graph Transformer Architecture Search
研究背景
グラフに対するTransformerの設計は、従来人の労働と専門知識によって行われていた。この論文では、Graph Transformerの自動設計に焦点を当て、最適なアーキテクチャとEncoding手法の自動発見を目指す。
提案手法
Transfomer構造とGraph Encodingを統合した、Automated Graph Transformer (AutoGT)を提案。
Graph EncodingにAttention機構を用いて、モデルの性能推定を行う。
これにより、Graph Transformerの設計を自動化。
先行研究との比較
先行研究では、非グラフデータ(テキストや画像など)のTransfomerの自動設計に焦点が当てられていたが、この研究では、グラフの特性を考慮することでGraph Transformerの自動設計を行った。
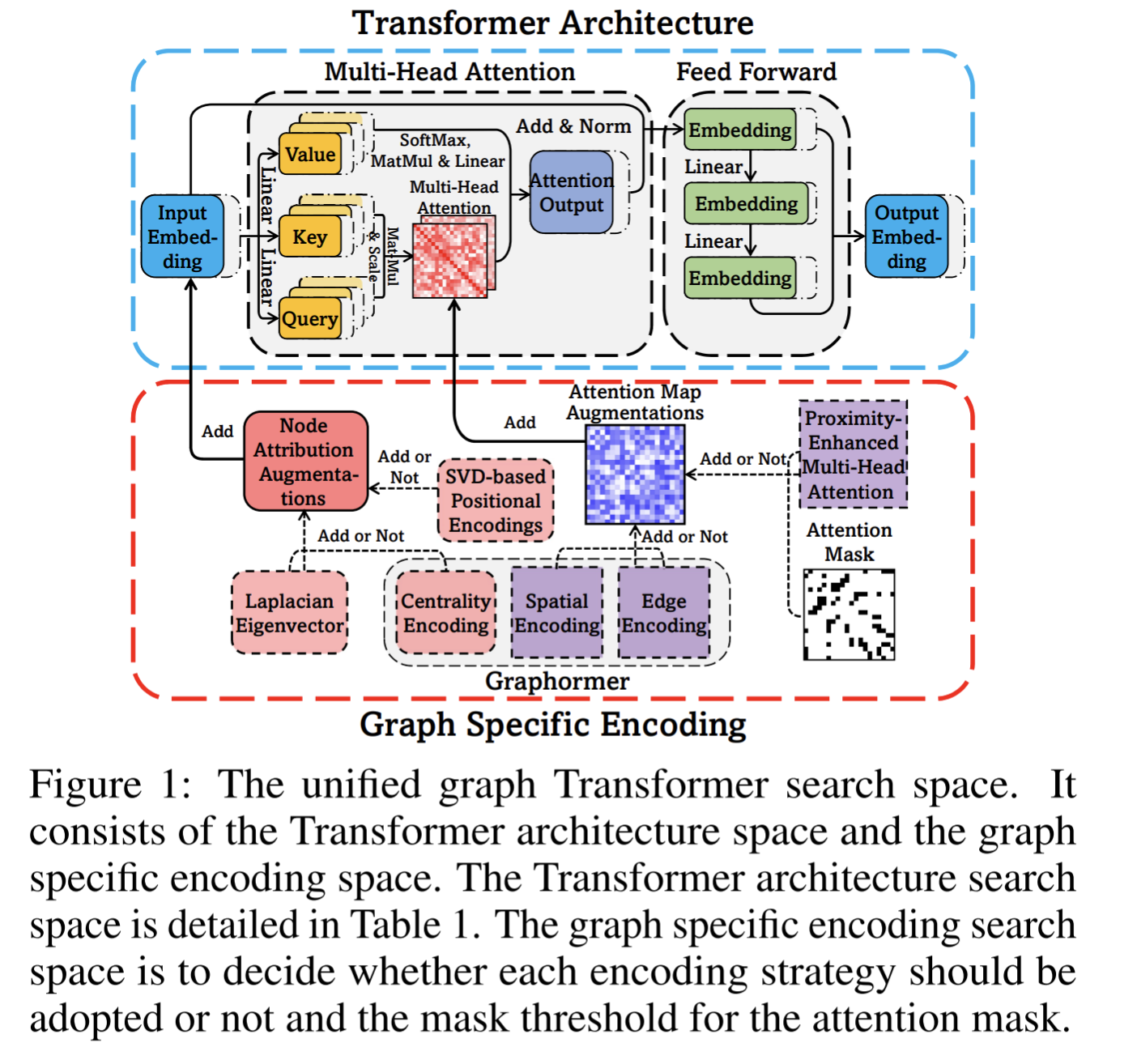
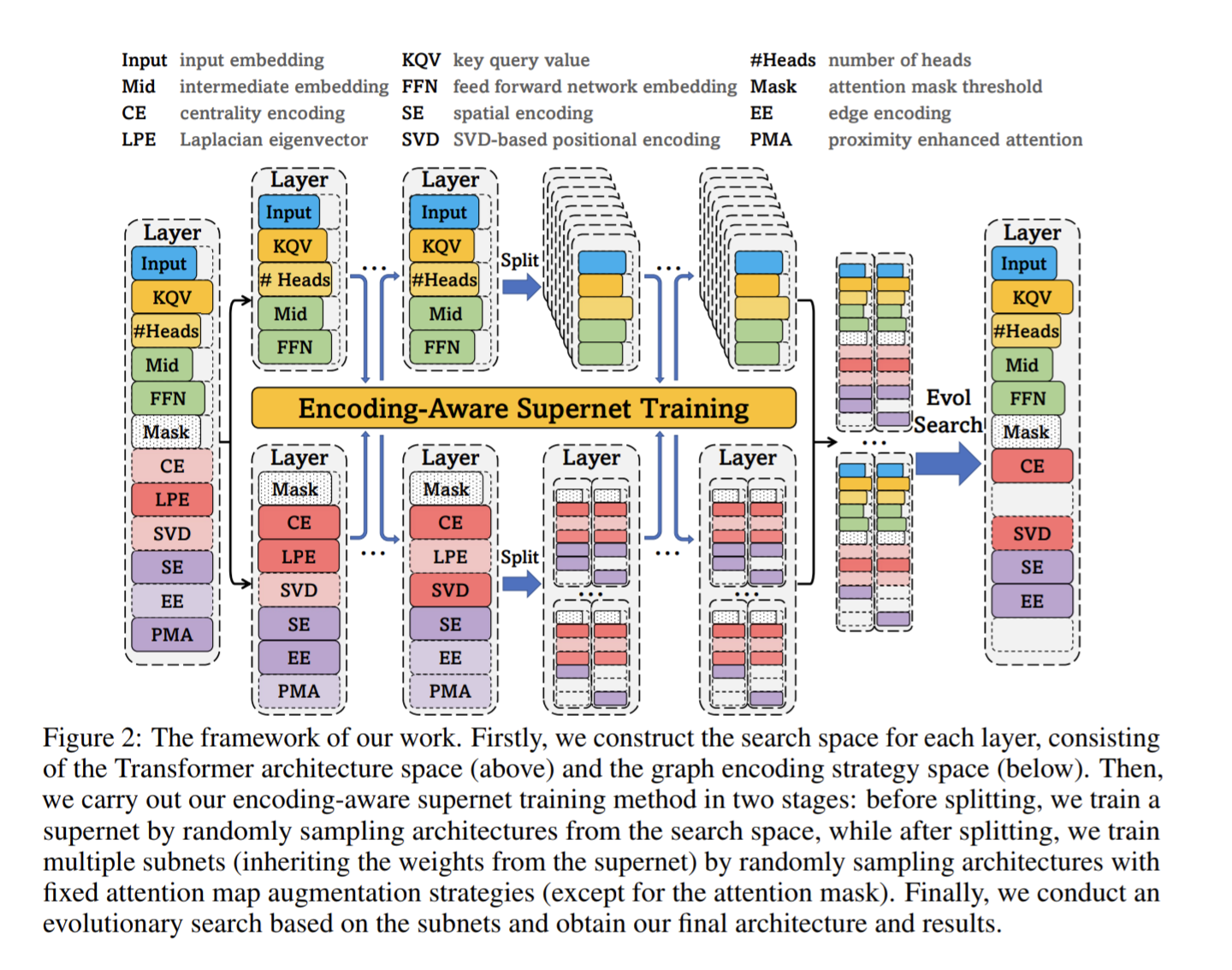
技術や手法の新規性
Figure1の下半分のように、Attention maskやエッジ埋め込みなどのグラフ固有のモジュールを追加するか否かを決める(「Encoding戦略を決める」という)。
Figure2はそれを決める部分の詳細を示す。
NAS(Neural Architecture Searc)のように、Super netに、現在のネットワーク構造の情報(モジュール同士の接続情報など)と対象のグラフデータなどを入力とし、最適なネットワーク構造の情報を出力(推論)する。
このSuper netを学習することで、最適な構造を決めることができる。
検証方法
AutoGTを既存の手作業によるベースラインと比較し、COX2_MD、BZR_MD、PTC_FM、DHFR_MD、PROTEINS、DBLPなどのデータセットでの平均精度と標準偏差において、既存のモデルよりも優れた性能を示す。
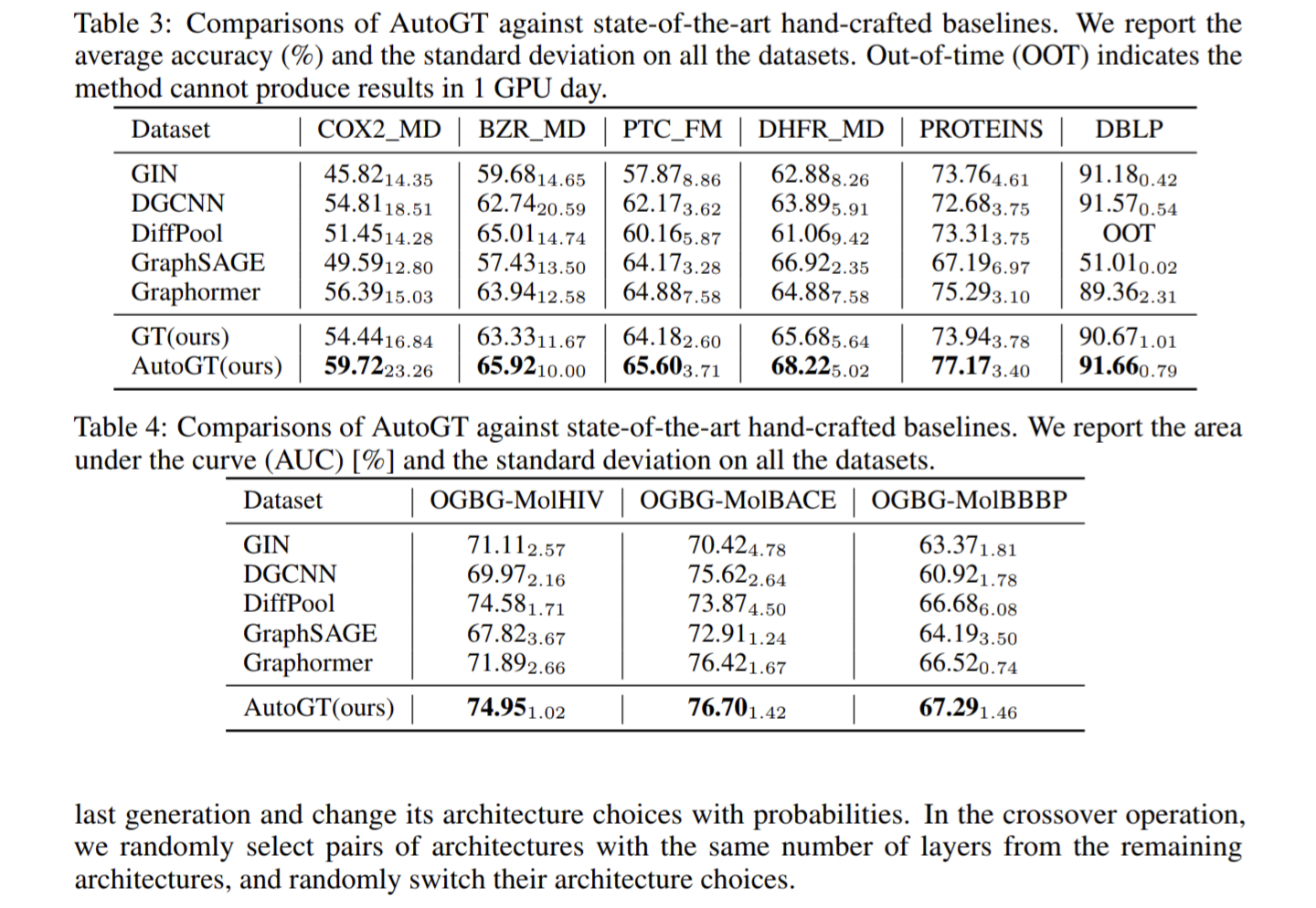
Crossformer: Transformer Utilizing Cross-Dimension Dependency for Multivariate Time Series Forecasting
研究背景
MTS(多変量時系列予測)は、気候、エネルギー、金融など多くの分野で重要であるが、
長期的な依存関係を捉えるTransformerベースの既存モデルは、次元の異なる特徴量間の依存関係(クロス次元依存性)を無視していることが多い。
提案手法
Crossformerは、DSW(Dimension-Segment-Wise)埋め込みとTSA(Two-Stage Attention)層を使用して、クロス次元依存性と異なる時刻同士の関係性(クロスタイム依存性)を効果的に捉える。
DSW埋め込みでは、各次元の時系列データをsegmentという2次元特徴ベクトルとして埋め込む。
HED(Hierarchical Encoder-Decoder)は、異なるスケールで情報を使用し、最終予測に組み合わせる。
先行研究との比較
従来のトモデルは、時系列データのクロスタイム依存性のみを重視し、クロス次元依存性を明示的に捉えていないという問題がある。
これらのモデルは、特定の時刻における全次元の特徴量を単一のベクトルに埋め込むことで、クロスタイム依存性のみに焦点を当てている。
Crossformerはこの問題に取り組み、クロス次元依存性とクロスタイム依存性の両方を捉えることで、MTS予測の精度を向上させている。
技術や手法の新規性
多変量時系列(MTS)予測において、クロス次元依存性を明示的に利用するTransformerモデルとして初である。
有効性の検証
実験は、6つの実世界のデータセット(気温変化、気象データなど)を使用して行われ、Crossformerは既存の最先端モデルと比較して優れた性能を示した。
Betty: An Automatic Differentiation Library for Multilevel Optimization
Offline RL with No OOD Actions: In-Sample Learning via Implicit Value Regularization
Win: Weight-Decay-Integrated Nesterov Acceleration for Adaptive Gradient Algorithms
研究背景
大規模なデータセットでのトレーニングは、計算上の課題を伴う。
また、既存のアルゴリズムである確率的勾配降下法(SGD)やAdamは、疎なデータセットでの学習などの特殊な状況に弱く、収束速度や精度が下がってしまう。
提案手法
本論文では、AdamWやAdamのような適応型勾配アルゴリズムを強化するための新しい技術であるWeight-decay-Integrated Nesterov acceleration(Win)を提案。
この方法は、ネステロフ加速と重み減衰を効果的に組み合わせている。また、損失関数の一次および二次テイラー近似を使用し、更新には、保守的ステップ(Conservative Step)と無謀なステップ(Reckless Step)を組み合わせて収束を加速させる。
この方法は、LAMBやSGDなどの他の最適化手法にも拡張できる。
先行研究との比較
Winは、重み減衰とネステロフ加速プロセスを直接統合する点に関して、先行研究とは異なる。
以前の方法では、ネステロフ加速の性能をうまく活用できなかったり、AdamWのような適応型アルゴリズムが汎化性能の問題に直面していた。
Winによる、重み減衰との統合により、より良い収束能力と汎化能力が得られる。
技術や手法の新規性、重要な部分
新規性は、重み減衰をネステロフ加速と効果的に組み合わせる点。
この技術は、近似点法(PPM)に触発された動的な正則化と、Tailor近似化された損失関数を使用し、AdamW、Adam、LAMB、SGDなど様々なオプティマイザーに適用可能です。この統合により、顕著な計算オーバーヘッド増加なしに、収束速度と性能が向上している。
有効性の検証
Winの有効性は、CNNとTransformerアーキテクチャを使用した視覚分類と言語モデリングタスクでの広範な実験を通じて検証された。その結果、Win加速アルゴリズムは、収束速度と全体的なパフォーマンスの両方で非加速バージョンを大幅に上回ることが示された。
Towards Stable Test-time Adaptation in Dynamic Wild World
研究背景:
ドメインシフトが存在する場合、深層ネットワークは一般化に苦労することが認識されている。このようなドメインシフトは、天候の変化やセンサーの劣化など、実際のアプリケーションでよく起こります。この問題に対処するために、テスト時適応(TTA)の多くの方法が提案されている。
提案手法:
バッチ正規化(Batch Normalization, BN)がTTAの安定性を妨げる要因であることが特定された。代わりに、バッチに依存しない正規化レイヤー(例えば、グループ正規化やレイヤー正規化)がTTAにおいてより安定していることが観察された。しかし、これらの正規化レイヤーを使用したTTAも常に成功するわけではなく、多くの失敗例があります。この問題に対処するため、鋭敏度認識かつ信頼性の高いエントロピー最小化手法(Sharpness-Aware and Reliable entropy minimization, SAR)が提案されている。この手法は、大きな勾配を持つノイズの多いテストサンプルの一部を除去し、モデルの重みを平坦な最小点に導くことで、残りのノイズの多いサンプルに対してロバストにする。
有効性の検証:
様々な正規化レイヤーを持つモデルでのTTAのパフォーマンスが検証された。特に、異なるノルムレイヤーを使用したモデル(BN、GN、LN)で、混合分布シフトやオンラインで不均衡なラベル分布シフトの下でのTTAの効果が評価されました。その結果、R-50-GNとVit-LNはR-50-BNよりも安定していることが示されたが、常に成功するわけではなく、いくつかの失敗例もあった。
MocoSFL: enabling cross-client collaborative self-supervised learning
研究背景:
従来の協調自己教師あり学習(SSL)スキームは、高い計算コストと大量のローカルデータ要件があるため、クロスクライアントアプリケーションには適していない。
提案手法:
「MocoSFL」という新しいフレームワークを提案。これは、スプリットフェデレーテッドラーニング(SFL)とモメンタムコントラスト(MoCo)に基づいている。MocoSFLは、大きなバックボーンモデルを小さなクライアントサイドモデルと大きなサーバーサイドモデルに分割し、クライアントのローカルデバイスでのみ小さなクライアントサイドモデルを処理する。
先行研究と比べてどこがすごいか:
先行研究では、フェデレーテッドラーニング(FL)が、ラベル付きデータに基づいた協調学習で大きな成功を収めたが、自己教師あり学習(SSL)との組み合わせは、データが独立同一分布(IID)である場合にのみ良好な性能を示していた。
技術や手法の新規性、重要な部分:
MocoSFLは、SFL-V1とMoCo-V2の組み合わせであり、ユニークな3つのコンポーネントを有する:(i) ベクトルの連結、(ii) 共有特徴メモリの使用、(iii) 高頻度の同期による非IID性能の改善。
どうやって有効だと検証したか:
非IIDデータにおける性能向上:同期頻度の増加により非IID精度が大幅に改善されることを示した。クライアントサイドモデルのカットレイヤーの選択に基づく結果が提示された。
DaxBench: Benchmarking Deformable Object Manipulation with Differentiable Physics
3D generation on ImageNet
Rethinking the Expressive Power of GNNs via Graph Biconnectivity
研究背景:
既存のGNNは、Weisfeiler-Lehman(WL)テストの枠組みに基づいて設計されていたが、その表現力には限界がある。
提案手法: 著者たちは、双連結性を利用してGNNの表現力を向上させる新しい手法「Generalized Distance Weisfeiler-Lehman(GD-WL)テスト」を提案。
先行研究と比べてどこがすごいか:
従来のGNNは、グラフの双連結性のような重要な構造的特徴を捉えることができなかったが、提案手法はこれを可能にする。
GD-WLは、双連結性問題に対して証明可能な表現力を持つことが示されている。
技術や手法の新規性・重要な部分:
GD-WLは、ノード間の距離情報をWL集約手順に直接組み込むことで、従来のWLテストの問題を解決する。
エッジ双連結性と頂点双連結性の両方を識別する能力を持つことを、理論的に証明した。
有効性の検証:
合成データセットと実世界のデータセットの両方で実験を行い、GD-WLが従来のGNNアーキテクチャを一貫して上回ることを示した。
Sparse Mixture-of-Experts are Domain Generalizable Learners
Token Merging: Your ViT But Faster
研究背景:
Vision Transformers(ViT)がNLPからコンピュータビジョンに導入されて以来、効率性を高めるために特定のドメインに特化したトランスフォーマーハイブリッドが主流になっている。
提案手法:
ToMeは、似たようなトークンをトランスフォーマー内で組み合わせ、プルーニングと同等の速さでより正確に実行。トレーニングを必要とせず、大規模モデルにも最小限の精度低下で適用できる。
先行研究との比較:
既存のトランスフォーマーモデルを高速化するために、より高速なアテンション、機能のプルーニング、ドメイン固有モジュールの導入などが試みられてきたが、これらの方法はトレーニングが必要であり、動的なトークン数の変化によりバッチ処理が困難であるという問題がある。
技術や手法の新規性、重要な部分:
ToMeは、各トランスフォーマーブロック内でトークンを組み合わせることで、少ないトークン数で高いスループットを実現。特に、トークンの組み合わせにおいては、最も類似したトークンを選択することが重要であり、このプロセスは効率的なバイパーティトマッチングアルゴリズムによって行われる。
検証方法:
トレーニング済みのMAEモデルを使用して、画像、ビデオ、オーディオの各モダリティでのToMeの効果を検証した。その結果、ToMeは状態の最先端モデルと比較して競争力のあるスピードと精度を達成。
Learnable Behavior Control: Breaking Atari Human World Records via Sample-Efficient Behavior Selection
Image as Set of Points
研究背景:
従来の画像解析手法(ConvNetsやViTs)は、画像をピクセルの配列やパッチのシーケンスとして扱い、局所的またはグローバルな範囲で特徴を抽出する。
提案手法:
本研究では、画像を非構造化された点の集合として扱い、これらの点をクラスタリングすることで特徴を抽出する。
先行研究との比較:
本手法は、従来のConvNetsやViTsに依存せず、クラスタリングアルゴリズムに基づく新しいアプローチを採用している。
この方法は、異なるデータドメイン(例えば、点群とRGBD画像)に対して高い汎用性を示している。
技術や手法の新規性、重要な部分:
コンテキストクラスターは、画像を点の集合とみなし、単純化されたクラスタリングメソッドを適用している。これにより、視覚的解釈と学習の過程が容易になる。
新規性は、コンボリューションやアテンションに頼らず、クラスタリングに基づく特徴抽出を行う点。
検証方法
ImageNet-1K、ScanObjectNN、MS COCO、ADE20Kなどの複数のベンチマークデータセットでの画像分類、点雲分類、物体検出、インスタンスセグメンテーション、意味セグメンテーションなどのタスクにおいて、Context Clustersを評価し、ConvNetsやViTsと比較して同等またはそれ以上のパフォーマンスを達成している。