Vision Transformerの特徴マップを高密度化する軽量な変換手法「LiFT」
LiFT: A Surprisingly Simple Lightweight Feature Transform for Dense ViT Descriptors
概要
Vision Transformer (ViT)の特徴マップを高密度化する新しい軽量な手法「LiFT」を紹介します。LiFTは事前学習済みViTの出力特徴マップを2倍の解像度に拡大し、物体検出やセグメンテーションなどの密な予測タスクの性能を向上させます。従来の手法と比べて計算コストを大幅に抑えながら、高い性能向上を実現しています。
背景と課題
Vision Transformerは画像認識タスクで高い性能を示していますが、パッチ分割による粗い特徴マップが密な予測タスクでの性能を制限していました。
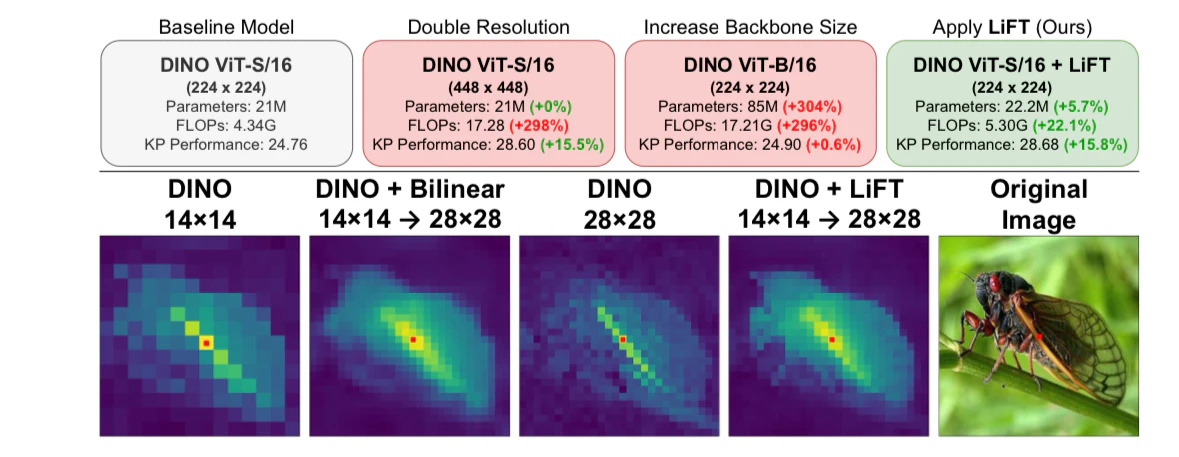
従来は特徴マップの密度を上げるために、(1)モデルサイズを大きくする、(2)入力解像度を上げるという2つの方法がありましたが、いずれも計算コストが大幅に増加するという課題がありました。
例えば、DINO ViT-S/16からDINO ViT-B/16に拡大すると、パラメータ数が304%増加します。また入力解像度を2倍にすると、計算量が298%増加してしまいます。
提案手法
LiFTは、以下のような特徴を持つ軽量な特徴変換モジュールです:
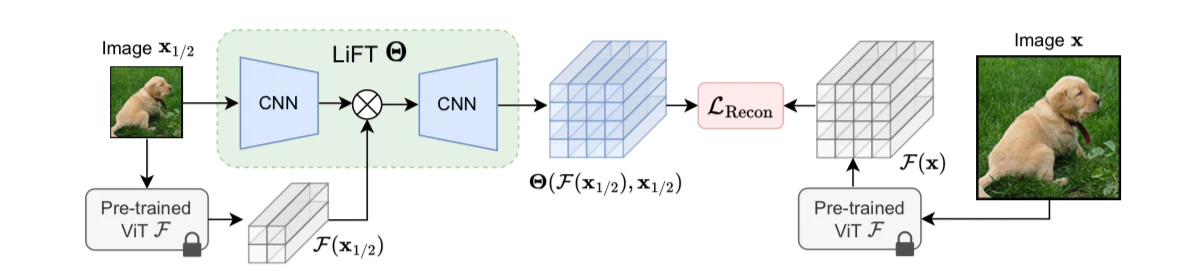
- ViTの出力特徴マップと元画像の両方を入力として受け取ります
- 小さなCNNで元画像から細かい特徴を抽出
- U-Net風のモデルで特徴を融合し、2倍の解像度の特徴マップを生成
- 自己教師あり学習で訓練可能
学習には以下のような再構成損失を使用します:
L_Recon = d(F(x), Θ(F(x_1/2), x_1/2)) + d(F(x_1/2), Θ(F(x_1/4), x_1/4))
ここで、F(x)はViTの特徴抽出、Θ(・)はLiFTモジュール、dはコサイン距離を表します。
実験結果
SPair-71kのキーポイント対応付けタスクでの性能比較:
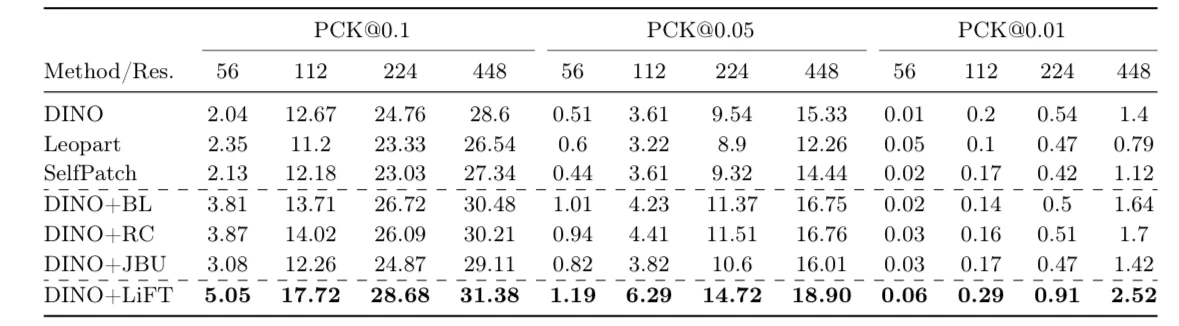

- DINO+LiFTは全ての解像度でベースラインを上回る性能を達成
- 特に低解像度(56x56)での性能向上が顕著
- パラメータ数の増加はわずか5.7%、計算量の増加は22.1%に抑制
さらに以下のタスクでも性能向上を確認:
- DAVISビデオセグメンテーション
- COCO物体検出・セグメンテーション
- 教師なし物体発見
まとめと考察
LiFTの主な利点:
- 軽量で効率的な特徴マップの高密度化
- 様々なViTバックボーンに適用可能
- 複数回の適用による更なる高密度化も可能
今後の展望:
- より大規模なモデルへの適用
- 新しいタスクへの応用
- 構造の最適化
本研究は、ViTの密な予測タスクにおける性能向上を、計算効率を維持しながら実現する新しい手法を提案しました。実用的な計算コストで高い性能が得られることから、
参考文献
Saksham Suri, Matthew Walmer, Kamal Gupta, Abhinav Shrivastava. "LiFT: A Surprisingly Simple Lightweight Feature Transform for Dense ViT Descriptors". University of Maryland, College Park.