はじめに
「本番環境でやらかしちゃった人 Advent Calendar 2022」の16日目の記事になります。
今年で3年連続イベント参加となりますが、今回もやらかしたことを公開して懺悔したいと思います。
今回は本番リリース直前の話となるので、イベントの趣旨と少しずれておりますが、本番リリース直前の機器ということでインパクトはかなり大きかったことと、一瞬で簡単にぶっ壊せてしまったお手軽さを悪い例として知ってもらうため公開しようと思いますのでご了承ください。
【過去のやらかし】
序章
アプリを含めた総合試験も無事?に終わり、1年ほど続いたシステム更改案件もようやく終わりが見え始めた頃、実際の本番環境のネットワークへ繋ぐための接続前確認と本番リリース時の手順リハーサルを行うためにデータセンターに赴いておりました。
外のネットワークとは切り離された状態だったことから、作業用として事前にレンタルしていたCiscoのスイッチに前もって準備していたコンフィグを投入・設定反映・保存を行い、新システムのネットワークに接続。
また、新システムではシステム外にあるNTPサーバに問い合わせる設計となっていたため、切り離された状態ではNTP同期できないことから、一時的な作業とはいえ、せっかくなのでCiscoのルータやスイッチで設定できる簡易NTPサーバの機能も有効にして、擬似的に外部NTPサーバのように見せかけるように設定しました。
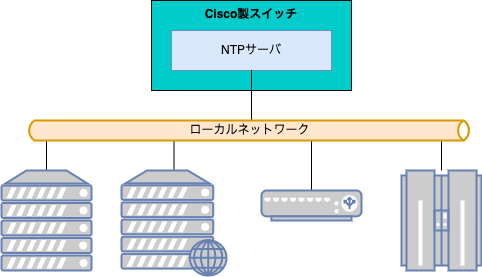
前準備の甲斐もあり、1日目の作業は無事完了。
さっさと作業用の機器を片付けて足早に帰宅しました。

混沌の始まり
作業2日目。
2日目ともなれば準備も慣れたもので、作業用の机や椅子、作業用のCiscoスイッチやPCをケーブルで繋ぎ、1日目よりも早く準備が完了しました。
順調順調!
ということで作業開始しようとしたところ、ほどなく私が担当していたBIG-IPのクラスタが切り離されたり妙な挙動をし始める。
昨日もこれまでもこんな事象は出なかったのに・・・ケーブル繋ぎ間違えたりしたか?
ひとまず、仮に繋いでいたケーブルを再チェック&ケーブル抜き挿し。

念の為、冗長化しているBIG-IP2台ともに再起動をしたところ・・・症状悪化・・・
変わらずクラスタも組めず、2台いるBIG-IPのうち、1台だけBIG-IPのサービスの根幹となるmcpdプロセスがなぜだかリスタートを繰り返している・・・
Broadcast message from systemd-journald@hostname.example.com (Fri YYYY-MM-DD hh:mm:ss JST): logger[10709]: Re-starting devmgmtd
Broadcast message from systemd-journald@hostname.example.com (Fri YYYY-MM-DD hh:mm:ss JST): logger[10836]: Re-starting mcpd
嫌な未来が頭によぎりながら、周辺装置のログなども確認したところ・・・ん?
1993-01-01 00:00:05: 〜〜何かしらのログ〜〜
あぁ、今年って1993年だっけ?・・・あれ?今って正月だっけ?・・・ってこれだ〜〜〜!!
惨劇はなぜ起こってしまったか
結論から言うとCiscoスイッチに設定していた疑似NTPサーバの時間が1993年1月1日になっていたことが原因でした。
ではなぜ1日目の作業では問題が発生しなかったのに2日目の作業で起こってしまったか。
| 順番 | 1日目作業 | 2日目作業 |
|---|---|---|
| 1 | 電源ON | 電源ON |
| 2 | 時刻設定&設定投入&保存 | ケーブル接続 |
| 3 | ケーブル接続 |
はい。1日目作業で設定したCiscoスイッチの設定を保存していたため、2日目作業では設定作業はやっていなかったんですね。
それ自体は良いことですが、レンタルしたCiscoスイッチはハードウェアクロックを備えていない機器であったことから1日目の作業終わりで片付けた際に、1日目のケーブル接続前に設定した時刻設定が消えてしまい、2日目電源を入れた際にデフォルトの時間となる1993年1月1日に戻ってしまったことで惨劇が起こってしまったわけですね。
なお、ハードウェアクロックを備えている機器であれば、電源を抜き挿ししたとしても時間の情報がハードウェアクロックに保存されるため、いきなり30年近くタイムリープするようなことはありません。
また、NTPサーバ側が極端に現実と異なる時間となった場合であっても、クライアント側がslewモードという徐々に時刻を合わせる設定としていれば、システム内機器が一気に集団タイムリープするような事もありません。
幸い、BIG-IP以外はslewモード設定ができない一部機器がタイムリープしたのを除き、影響はありませんでしたが、最終的にBIG-IP1台だけはOSの再インストールする羽目になってしまいました・・・
詳細が長くなるので、時間がある方は以下続きをどうぞ。
時間がない方は以下まとめをどうぞ。
過去に取り残されたBIG-IP
BIG-IP2台中1台だけというのも腑に落ちませんが、エラーログが出力され続けている主系のBIG-IPのみネットワークから切り離し、調査開始。
単体にしても症状が変わることはなく、該当サービスを再起動しても、機器を再起動しても改善する様子を見せないため、ひとまず再起動を繰り返していたmcpdサービスに対してstraceコマンドでトレースを仕掛け、デバッグを実施。
[root@hostname:INOPERATIVE:] log # strace bigstart start mcpd
execve("/bin/bigstart", ["bigstart", "start", "mcpd"], [/* 36 vars */]) = 0
brk(0)
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x555de000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/usr/lib/perl5/CORE/tls/i686/sse2/libperl.so", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
stat64("/usr/lib/perl5/CORE/tls/i686/sse2", 0xffc04b40) = -1 ENOENT (No such file or directory)
(略)
また、余計な時刻情報を保持してしまっているファイルがあるのではないかという推測の基、ひとまず正常に動いていた3日前くらいから現在までに更新されているファイルを洗い出すため、一時ディレクトリなどを除くようにして以下コマンドを実行。
find / -mtime -3 -ls 2>/dev/null | egrep -v " /proc| /sys| /dev| /run| /var/run"
※調査方法について以下でもまとめているので、参考にどうぞ。
出力された更新ファイル一覧から手当たりしだいに中身を確認していったところ、「/var/log/datastor」というログファイルで妙なログを発見。
1 Oct 4 13:38:12 hostname.example.com ---------------------------------------------
2 Oct 4 13:38:12 hostname.example.com Mon Oct 4 13:38:12 JST 2021
3 Oct 4 13:38:12 hostname.example.com Running datastor.startup.pre script
4 Oct 4 13:38:12 hostname.example.com --- datastor.start.pre ---
5 Oct 4 13:38:13 hostname.example.com Disk enabled: (true)
6 Oct 4 13:38:13 hostname.example.com Store size: (0)
7 Oct 4 13:38:13 hostname.example.com /usr/bin/setdb datastor.cache.size 0
8 Oct 4 13:38:13 hostname.example.com Line 2474 for [Configsync.LocalConfigTime]:
9 Oct 4 13:38:13 hostname.example.com value of '-408244412' fails min/max (0/214783647) test
10 Oct 4 13:38:13 hostname.example.com Total of 1 errors in /config/BigDB.dat.tmp
11 Oct 4 13:38:13 hostname.example.com setdb: syntax errors!! /config/BigDB.dat not updated!
12 Oct 4 13:38:13 hostname.example.com no change - datastor cache size stays at (0)
13 Oct 4 13:38:13 hostname.example.com /usr/bin/setdb datastor.store.size 0
14 Oct 4 13:38:13 hostname.example.com Line 2474 for [Configsync.LocalConfigTime]:
15 Oct 4 13:38:13 hostname.example.com value of '-408244412' fails min/max (0/214783647) test
16 Oct 4 13:38:13 hostname.example.com Total of 1 errors in /config/BigDB.dat not updated!
17 Oct 4 13:38:13 hostname.example.com setdb: syntax errors!! /config/BigDB.dat not updated!
18 Oct 4 13:38:13 hostname.example.com no change - datastor store size stays at (0)
19 Oct 4 13:38:13 hostname.example.com Done pre script
20 Oct 4 13:38:18 hostname.example.com ---------------------------------------------
見たところ何かsyntax errorが表示されていたり、BigDB.dat not updated!と表示されていたり、負数の値となっていたり気になる点がちらほら。
ログに書かれている通り、「BigDB.dat」の指定行を見てみると「/var/log/datastor」にかかれていた負数と同じ値が記録されていました。
(略)
[Configsync.LocalConfigTime]
default=0
type=integer
realm=private_local
min=0
max=2147483647
scf_config=false
display_name=Configsync.LocalConfigTime
value=-408244412
(略)
じゃあ、実際どういう値が入るのが正しいのか?ということで正常に動いているBIG-IPの値を見てみると「1671148800」のような値が入っている。
この数字の並びはUNIX時間っぽい・・・ということでおもむろにUNIX時間→日付に変換してみると・・・ビンゴ!
見事現在の時間に近い値が出てきました。
というわけで、約30年前にタイムリープしてしまったことで、「BigDB.dat」のConfigsync.LocalConfigTimeという値がオーバーフローしてしまい、負数が記録されたことでmcpdサービス起動→負数のため起動できず→mcpdサービス再起動→...と無限ループに陥ったようです。
ひとまず「BigDB.dat」をバックアップした上で、Configsync.LocalConfigTimeの値をUNIX時間で現在時刻に近い時間に修正して再起動したところ、なんとか再起動ループを繰り返していた事象を止めることができました。
2台のうち1台だけ壊れた原因
「BigDB.dat」はクラスタ構成の主系で管理され、主系の「BigDB.dat」ファイルが待機系となるもう一台に同期されることでクラスタ構成を維持していることから、同期を司る主系のmcpdサービスが「BigDB.dat」のエラーで起動できず、同期ができなかったため、待機系は無事だったかと思われます。
さらなる混沌へ・・・
ここまでで確か2〜3日は時間を潰していたわけですが、ひとまずクラスタの再組込も完了し、障害時の切り替えも問題がなさそうなので、ようやく本来の作業へ・・・と思いきや、なぜか、リンクダウン等行った際に毎回出力されるはずのBIG-IPサービス系ログの一部が出力されていないことが判明。
BIG-IPのOS系ログはちゃんと出力されており、サービス系ログもまったく出力されないわけではなく、特定のプロセスのログだけ出力されていないようでした。
「BigDB.dat」の問題のときも含めてサポートに何度も連絡はしているものの、サポート側もお手上げのようで有力な情報は得られず。
色々と追っていくとログファイルに出力されていないログも、journaldのログには出力されているようで、おそらくjournaldからsyslog-ngに引き渡す部分で詰まっているだろうというところまでは判明。

ちなみにBIG-IPのベースはCentOSとなりますが、ログサービスはデフォルトのrsyslogではなく、昔からsyslog-ngサービスを使ってログ出力しています。
もう少し時間があれば特定できたかもしれませんが、諸々のリカバリを踏まえた以降のスケジュールを考えるとここでタイムアップ。
事象が事象なので、きちんと戻るのか心配ではあったもののOS再インストール&事前のフルバックアップからリストアすることで何とか復旧できました。
※これで戻らなかったら機器交換&再構築しか無かったので本当にギリギリな状態でした。
惨劇を起こさないためにできること
NTPの時刻逆進が起こった場合、冗長構成の機器が切り替わったり、誤った時間が記録されることでアプリ等に影響が及んだりするという危険性は理解していたつもりでしたが、大幅な時間の逆進が行われることで、OSの入れ直しまで行うことになるとは思ってもいませんでした。
テストなどで一時的にNTPサーバが必要になったときは、ネットワーク機器の簡易NTPサーバを使うのではなく、せめて仮想サーバを準備して、不意に時間が何十年も戻らないような構成を組むようにしましょう。
〇〇年問題やうるう秒といった問題があれだけのニュースになるのは、今回のような問題が潜んでいるからなんだなと、身にしみて感じた件でした。
NTP一つでシステムが動かなくなってしまうことも起こり得るので、惨劇を起こさないためにも時刻を扱う場合は慎重に行うようにしましょう。