はじめに
2021年3月にE資格の研修を受けたとき、「GoogleColaboratoryはいいぞ!」的な話があったので、
使ってみたという話(食わず嫌いはよくないからね)
手始めとして、サンプルのデータを使用して学習を試みてみます。
今回実施すること
注)今回はお試しで実施しているので簡単なことしかしてません、、すみません、、、
今回実施することとしては主に下記2点です。
● GoogleColaboratoryでPyTorch Lightningを使えるようにする(GPU設定含む)
● サンプルのデータセットを使用して、学習を実施してみる
※サンプルのデータとしては、scikit-learnのirisデータセットを使ってます。
本当はMNISTを使いたかったんですけど、ダウンロード重いので勘弁してください、、、
環境
OS:GoogleColaboratoryが使えればなんでもOK
※私はWindows10を使用しました
また、GoogleColaboratoryを使用するためにはGoogleアカウントが必要になります。
事前に用意しておきましょう。
そもそも GoogleColaboratory / Pytorch Lightningとはなんぞや?
GoogleColaboratory とは?
Google社が無料で提供している機械学習の教育や研究用の開発環境です。
下記の特徴があります。
● 環境構築が不要
● GPU への無料アクセス
● 簡単に共有
開発環境はJupyter Notebookに似たインターフェースとなっており、とっつきやすいです。
また、Numpy、Pandas、Matplotlib、Scikit-learnなど、データ分析に必要なパッケージが
一通り揃っているので、すぐに利用することができます。
Pytorch Lightning とは?
Pytorch Lightning は、機械学習を実装する上で学習用のループ処理などの
学習精度向上とは関わりのない処理を簡易に書けるようにするPytorchのラッパーです。
Pytorch Lightningを使用すると、学習精度向上とは関わりのない処理はサクッと実装し、
その分だけ学習精度向上に直結する処理に時間を費やすことができます。
また、コードがスッキリするので可読性も向上します。
それでは、次の章から作業していきましょう!
GoogleColaboratoryを開き、設定する
① Googleアカウントにサインインし、GoogleDriveドライブにアクセスします。
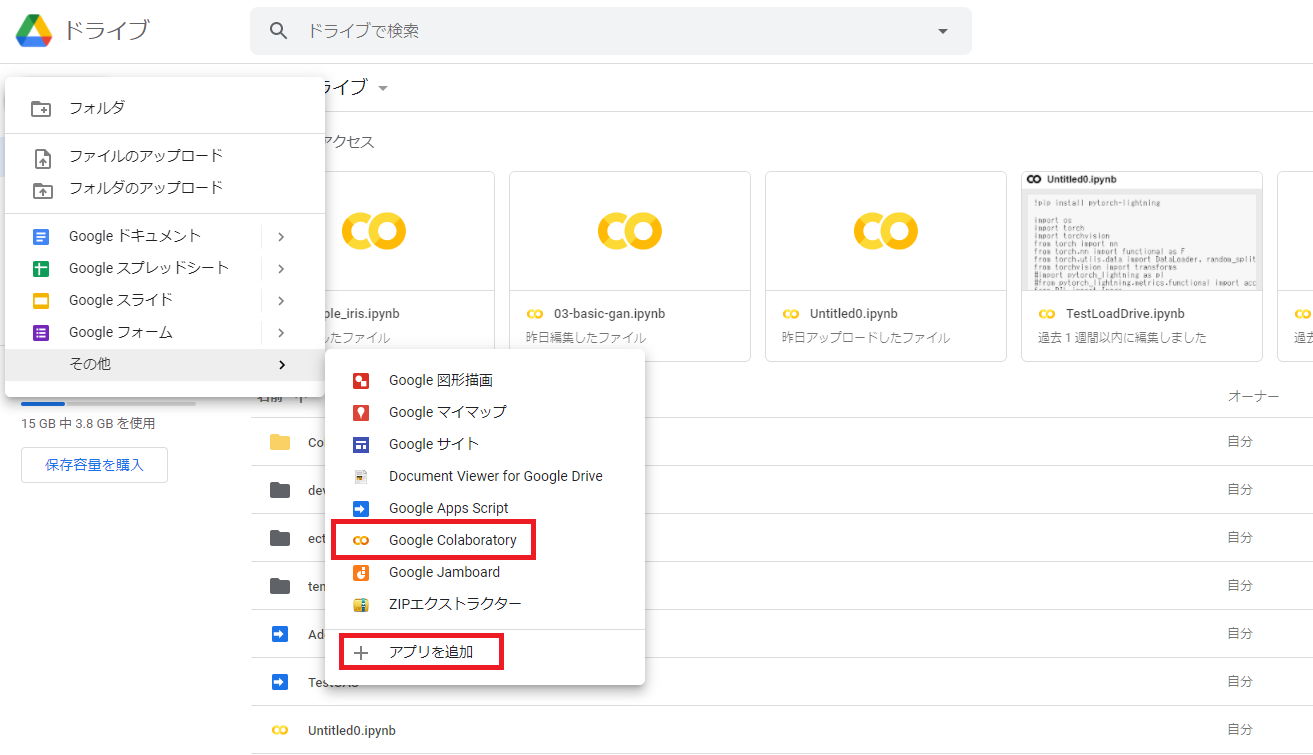
アクセス後、「新規」→「その他」→「Google Colaboratory」をクリックする。
「Google Colaboratory」の項目が存在しない場合は、「アプリを追加」をクリックする。
 |
|---|
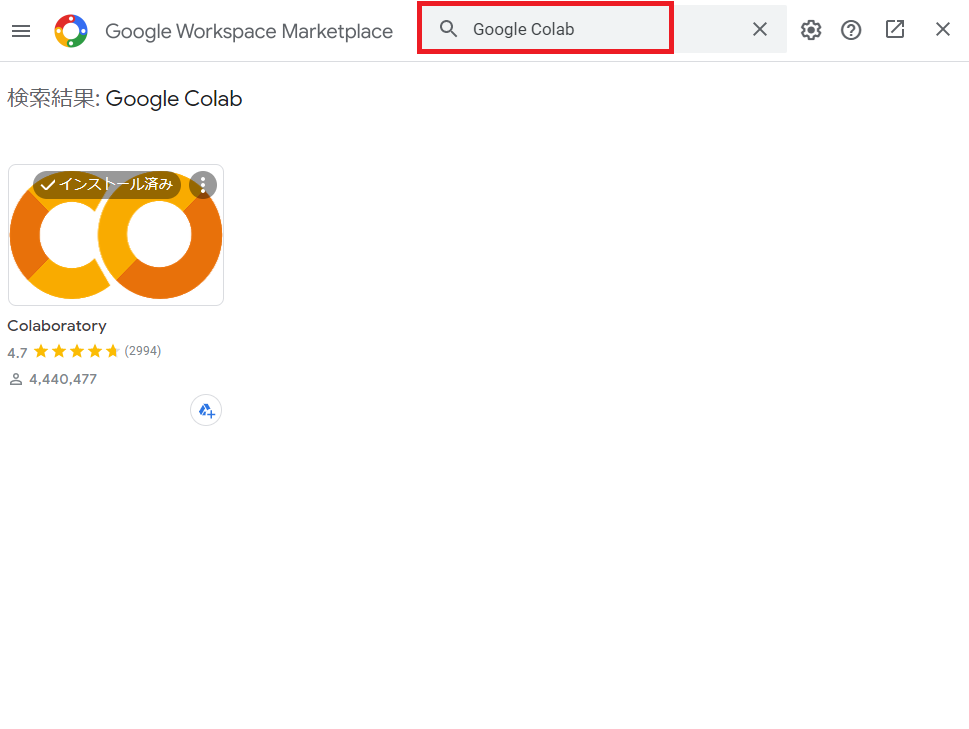
② アプリの追加で、Google Colaboratoryを追加する。
※①にて、「新規」→「その他」→「Google Colaboratory」が表示された方は実施不要です。
①で「アプリを追加」をクリックした後、Google Workspace Marketplaceが表示されるので、
ColaboratoryとかGoogle Colabとかで検索してインストールする。
インストールすると、手順①の「新規」→「その他」→「Google Colaboratory」が表示されます。
 |
|---|
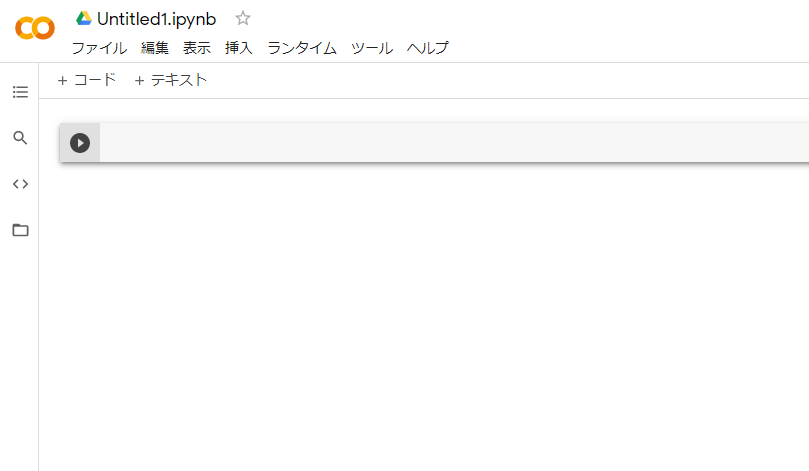
Google Colaboratoryを開くとこのようになります。
 |
|---|
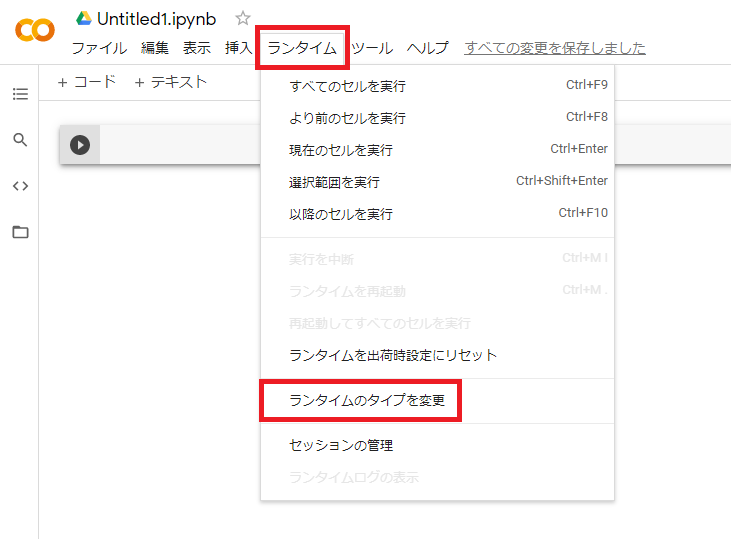
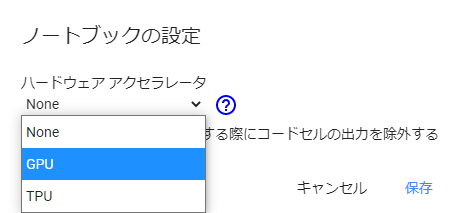
③ GPUを使えるようにする。
デフォルトだとGPUが使えないので、設定する必要があります。
「ランタイム」→「ランタイムのタイプを変更」をクリックする。
 |
|---|
ハードウェアアクセラレータがNoneになっているので、GPUに変更する。
 |
|---|
④ Google Colaboratory上でPyTorch Lightningをpipする。
PyTorchはimportできますが、PyTorch Lightningはimportできないのでpipする必要があります。
セルに下記コードを貼り付け、実行します。
# pytorch_lightningのインストール
!pip install pytorch_lightning --quiet
※ --quiet:出力なしでコマンドを実行する
下記のコードでバージョンを確認できます
import torch
import pytorch_lightning as pl
torch.__version__, pl.__version__
('1.8.1+cu101', '1.2.6')
これで、GoogleColaboratoryでGPUを使用した学習の準備が完了しました。
PyTorch Lightningで学習を実施する
工程ごとに簡易的な説明は記載します。
今回は、動作確認がメインのため詳細な説明は割愛します。
まずは必要なパッケージをimportします。
import torch
import torch.nn as nn
import torch.nn.functional as F
import pytorch_lightning as pl
from sklearn.datasets import load_iris
irisデータセットをロードします。
● iris['data']:アヤメの特徴量(ガクの長さ、ガクの幅、花弁の長さ、花弁の幅)が150個分格納されています。
※150×4のNumpy配列となります
● iris['target']:150個のデータそれぞれの花の種類が格納されています。
※0の場合:'setosa'
1の場合:'versicolor'
2の場合:'virginica' を表しています。
つまり、irisの分類は4次元の特徴量を使用した3値分類のタスクになります。
# データセットの読み込み
iris = load_iris()
x = iris['data'] # 入力値
t = iris['target'] # 目標値
先ほど読み込んだirisのデータ型はNumpyとなっています。
PyTorchを使用する場合は、torch.Tensor型に変換する必要があるので、
torch.Tensor型に変換します。
ここで注意すべきことは、目標値tの型に関してです。
目標値tの型はタスクによって変える必要があります。
● 回帰の場合:torch.float32
● 二値分類の場合:torch.float32
● 多値分類の場合:torch.int64
→今回は3値分類のため、torch.int64とします。
# PyTorch の Tensor 型へ変換
x = torch.tensor(x, dtype=torch.float32)
t = torch.tensor(t, dtype=torch.int64)
入力値xと目標値tをTensorDatasetで一つにまとめます。
TensorDatasetでまとめておくことで、後段処理にてData Loaderを使用することができます。
Data Loaderはデータをランダムに並べ替えたりバッチサイズごとにデータをまとめたりすることができる便利なヤツです。
# 入力値と目標値をまとめる
dataset = torch.utils.data.TensorDataset(x, t)
今回は学習の評価としてホールド・アウト法を使用します。
簡単に説明すると、学習用、評価用、テスト用にデータセットを分割して、
評価/テスト時に学習で使用したデータが混在しないようにします。
それぞれ下記の用途に使用されます。
● 訓練用データ:重みの学習に使用
● 検証用データ:学習済モデルが汎用性があるのかどうかを検証するために使用
● テスト用データ:テストに使用します
# 各データセットのサンプル数を決定
# train : val: test = 60% : 20% : 20%
n_train = int(len(dataset) * 0.6)
n_val = int(len(dataset) * 0.2)
n_test = len(dataset) - n_train - n_val
求めた学習/検証/テストのサンプル数に従い、datasetを分割します。
PyTorchに用意されているランダムにデータセットを分割する関数を使用します。
乱数を扱うため、乱数のシードの固定して再現性の確保をしとくのが良いでしょう。
# データセットの分割
# ランダムに分割を行うため、シードを固定して再現性を確保
torch.manual_seed(0)
train, val, test = torch.utils.data.random_split(dataset, [n_train, n_val, n_test])
ミニバッチ学習を実施するためにData Loderを用意します。
● batch_size:ミニバッチのサイズ
● shuffle:ミニバッチを作成する際にデータをシャッフルするかどうか
● drop_last:バッチサイズがデータサンプルに対して割り切れない場合に除外するかどうか
# バッチサイズの定義
batch_size = 10
# Data Loader を用意
# shuffle はデフォルトで False のため、訓練データのみ True に指定
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
test_loader = torch.utils.data.DataLoader(test, batch_size)
ネットワークを定義します。
PyTorch Lightningでは、ネットワークの継承にLightningModuleを指定する必要があります。
入力層に関して、入力データはアヤメの特徴量(ガクの長さ、ガクの幅、花弁の長さ、花弁の幅)のためノードは4つ
中間層に関して、ノート数はテキトーに4つ
出力層に関して、3値分類のためノードは3つ
順伝搬は、「全結合(FC1)→活性化(ReLU)→全結合(FC2)→Softmax」のように処理されます。
forward関数にSoftmax処理の記述がないのは、
損失関数であるcross_entropy内にsoftmaxの処理も入っているためです。
※accuracyの算出に関して注意事項があります。
詳細はページ下記の補足に記載しています。
class Network(pl.LightningModule):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(4, 4)
self.fc2 = nn.Linear(4, 3)
def forward(self, x):
h = self.fc1(x)
h = F.relu(h)
h = self.fc2(h)
return h
def training_step(self, batch, batch_idx):
x, t = batch
y = self(x)
loss = F.cross_entropy(y, t)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('train_acc', acc, on_step=True, on_epoch=True, prog_bar=True)
return loss
def validation_step(self, batch, batch_idx):
x, t = batch
y = self(x)
loss = F.cross_entropy(y, t)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
self.log('val_loss', loss, on_step=False, on_epoch=True)
self.log('val_acc', acc, on_step=False, on_epoch=True)
return loss
def test_step(self, batch, batch_idx):
x, t = batch
y = self(x)
loss = F.cross_entropy(y, t)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
self.log('test_loss', loss, on_step=False, on_epoch=True)
self.log('test_acc', acc, on_step=False, on_epoch=True)
return loss
def configure_optimizers(self):
optimizer = torch.optim.SGD(self.parameters(), lr=0.01)
return optimizer
これまでで用意したデータおよびネットワークを使用して学習を実施します。
まずは、乱数のシードを固定します。
ん?さっきもシード固定したのでは?
先ほど固定したシードはPyTorchの乱数シードであり、PyTorch Lightningの乱数とは別物らしいです(ソースは研修)。
そのため、ここでPyTorch Lightningの乱数のシードを固定して再現性を確保します。
LightningModuleを継承したネットワークはTrainerによって学習を行うことができます。
Trainer はデフォルトで値が指定されているため、引数を与えなくても使い始めることができますが、
今回は以下の3つを指定します。
● gpus:使用する GPU の数(GPU が使用可能な場合のみ)
● max_epochs:学習を行うエポック数
● deterministic:決定的な計算の有無(再現性確保のため)
# シードを固定して再現性を確保
pl.seed_everything(0)
# 学習を行う Trainer
net = Network()
trainer = pl.Trainer(gpus=1, max_epochs=30, deterministic=True)
実際に学習をするためには、Trainerのfitメソッドを実行します。
引数には以下の3つを指定します。
● net:LightningModuleを継承して定義したネットワーク
● train_loader:学習用の DataLoader
● val_loader:検証用の DataLoader
# 学習の実行
trainer.fit(net, train_loader, val_loader)
学習済みのネットワークを用いて、テストデータに対する結果を取得します。
結果を取得するためにはtrainer.testを実行します。
# テストデータで検証
trainer.test(test_dataloaders=test_loader)
# 結果表示
trainer.callback_metrics
検証結果はこんなカンジでした。
{'test_acc': tensor(0.9333, device='cuda:0'),
'test_loss': tensor(0.7354, device='cuda:0'),
'train_acc': tensor(0.9000, device='cuda:0'),
'train_acc_epoch': tensor(0.8778, device='cuda:0'),
'train_acc_step': tensor(0.9000, device='cuda:0'),
'train_loss': tensor(0.8155, device='cuda:0'),
'train_loss_epoch': tensor(0.7546, device='cuda:0'),
'train_loss_step': tensor(0.8155, device='cuda:0'),
'val_acc': tensor(0.8667, device='cuda:0'),
'val_loss': tensor(0.6433, device='cuda:0')}
以上で学習までの一連の動作を確認することができました。
※上記ソースをひとまとめにしたソースを補足に記載しました。
終わりに
今回は、Google Colaboratory上でPyTorch Lightningを使用して学習を実施してみました。
使った第一印象としては、「セットアップがめっちゃ楽だー」につきますね。
あと「無料でGPUが使える」、「ブラウザで動かすのでOSに依存しない」というのも強いですね。
また、私個人の見解ですが、他の方法と比べてどうなのかも記載しておきます。
他の方法としては、下記2点があるかなと思いますが、
● 1:ローカルマシン上に環境を構築
● 2:AWS等のクラウドにEC2を用意して環境を構築
1は、環境構築に失敗したときのリカバリーが大変だったり、GPU周りの設定でなぜかこけたり。。。
2は、機械学習向けのp系インスタンスの価格がなかなか高かったり。。。
Google Colaboratoryであれは「環境構築が楽」かつ「無料利用可能」なので上記問題を解消できます。
しかし、Google Colaboratoryは長時間(12時間以上)の連続利用ができないデメリットがあり、
処理時間がかかる学習に関しては向いていません。
ただ、簡単なモデルの評価だったり、機械学習の勉強に使うのであれば、
Google Colaboratory全然ありだと思いました!
補足
注意事項:accuracyの算出に関して
PyTorch Lightningには下記のaccuracy関数が存在します。
from pytorch_lightning.metrics.functional import accuracy
このAPIはPyTorch Lightningのバージョンによっては異なる挙動をする可能性があります。
おそらくだが、'1.2.0'以前と以降で処理に変更が加わっているかも、、、
そのため、accuracy関数を使用していた部分は下記のように置き換えて実施しました。
# 変更前
self.log('train_acc', accuracy(y, t), on_step=True, on_epoch=True, prog_bar=True)
# 変更後
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
self.log('train_acc', acc, on_step=True, on_epoch=True, prog_bar=True)
コピペ用ソース
学習までの処理を一括で実施してくれるようにソースをまとめたので貼っておきます。
!pip install pytorch_lightning --quiet
import torch
import torch.nn as nn
import torch.nn.functional as F
import pytorch_lightning as pl
from sklearn.datasets import load_iris
# データセットの読み込み
iris = load_iris()
x = iris['data'] # 入力値
t = iris['target'] # 目標値
# PyTorch の Tensor 型へ変換
x = torch.tensor(x, dtype=torch.float32)
t = torch.tensor(t, dtype=torch.int64)
# 入力値と目標値をまとめる
dataset = torch.utils.data.TensorDataset(x, t)
# 各データセットのサンプル数を決定
# train : val: test = 60% : 20% : 20%
n_train = int(len(dataset) * 0.6)
n_val = int(len(dataset) * 0.2)
n_test = len(dataset) - n_train - n_val
# データセットの分割
# ランダムに分割を行うため、シードを固定して再現性を確保
torch.manual_seed(0)
train, val, test = torch.utils.data.random_split(dataset, [n_train, n_val, n_test])
n_test = len(dataset) - n_train - n_val
# バッチサイズの定義
batch_size = 10
# Data Loader を用意
# shuffle はデフォルトで False のため、訓練データのみ True に指定
train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val, batch_size)
test_loader = torch.utils.data.DataLoader(test, batch_size)
class Network(pl.LightningModule):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(4, 4)
self.fc2 = nn.Linear(4, 3)
def forward(self, x):
h = self.fc1(x)
h = F.relu(h)
h = self.fc2(h)
return h
def training_step(self, batch, batch_idx):
x, t = batch
y = self(x)
loss = F.cross_entropy(y, t)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('train_acc', acc, on_step=True, on_epoch=True, prog_bar=True)
return loss
def validation_step(self, batch, batch_idx):
x, t = batch
y = self(x)
loss = F.cross_entropy(y, t)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
self.log('val_loss', loss, on_step=False, on_epoch=True)
self.log('val_acc', acc, on_step=False, on_epoch=True)
return loss
def test_step(self, batch, batch_idx):
x, t = batch
y = self(x)
loss = F.cross_entropy(y, t)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
self.log('test_loss', loss, on_step=False, on_epoch=True)
self.log('test_acc', acc, on_step=False, on_epoch=True)
return loss
def configure_optimizers(self):
optimizer = torch.optim.SGD(self.parameters(), lr=0.01)
return optimizer
# シードを固定して再現性を確保
pl.seed_everything(0)
# 学習を行う Trainer
net = Network()
trainer = pl.Trainer(gpus=1, max_epochs=30, deterministic=True)
# 学習の実行
trainer.fit(net, train_loader, val_loader)
# テストデータで検証
trainer.test(test_dataloaders=test_loader)
# 結果表示
trainer.callback_metrics