今回はデータを二つのうちいずれかに分類する予測を行います。前回までは、Azure ML Studioの使い方の説明を兼ねて書きましたが、今回からはそこらへんは少し省略します。
部屋の占有率の分類。占有されているか否かを調べる
今回は、部屋が占有されているか否かを調べます。以下のURLからデータセットを取得しましょう。
https://archive.ics.uci.edu/ml/datasets/Occupancy+Detection+
今回はzipです。解凍すると、ファイルが3つあります。名前からして、一つはトレーニング用のようです。
データは以下のようになっています。日付、温度、湿度、光、CO2、湿度、占有率とあります。先頭列はプライマリキーのようですね。占有率が「0:占有されてない」「1:占有されている」を、室内の温度や湿度、二酸化炭素濃度から判定するようです。室内にこれらを計測するセンサーでも配置されているのでしょう。
"date","Temperature","Humidity","Light","CO2","HumidityRatio","Occupancy"
"1",2015-02-11 14:48:00,21.76,31.1333333333333,437.333333333333,1029.66666666667,0.00502101089021385,1
"2",2015-02-11 14:49:00,21.79,31,437.333333333333,1000,0.00500858127480172,1
"3",2015-02-11 14:50:00,21.7675,31.1225,434,1003.75,0.0050215691326541,1
"4",2015-02-11 14:51:00,21.7675,31.1225,439,1009.5,0.0050215691326541,1
"5",2015-02-11 14:51:59,21.79,31.1333333333333,437.333333333333,1005.66666666667,0.00503029777867882,1
今回は一番サイズの大きい「datatest2.txt」を使用します。ファイル名をわかりやすく「occupancy2.csv」に変更しました。
カラム名と値がずれるのは良く無いので、先頭の列のカラム名に「id」を追加してml StudioにUPしました。
データのクリーニングと調整
機械学習の作業のほとんどは、データのクリーニング(NULLが入ってる行を削除したり、など)に費やされるそうです。
今回、欠損値は無いようですのでこのままで良いでしょう。
次に、学習に使用するデータと使用しないデータを見極めます。今回、IDはPrimary keyなので不要です。また、「date」ですが、2015-02-11のデータだけのようです。時刻が関係する環境なのか不明ですが、とりあえずdateも使用しないことにします。
不要な列を下に流さないようにするには、「Select Columns in DataSet」を使います。データをSplitしてから、以下のようにしてみました。
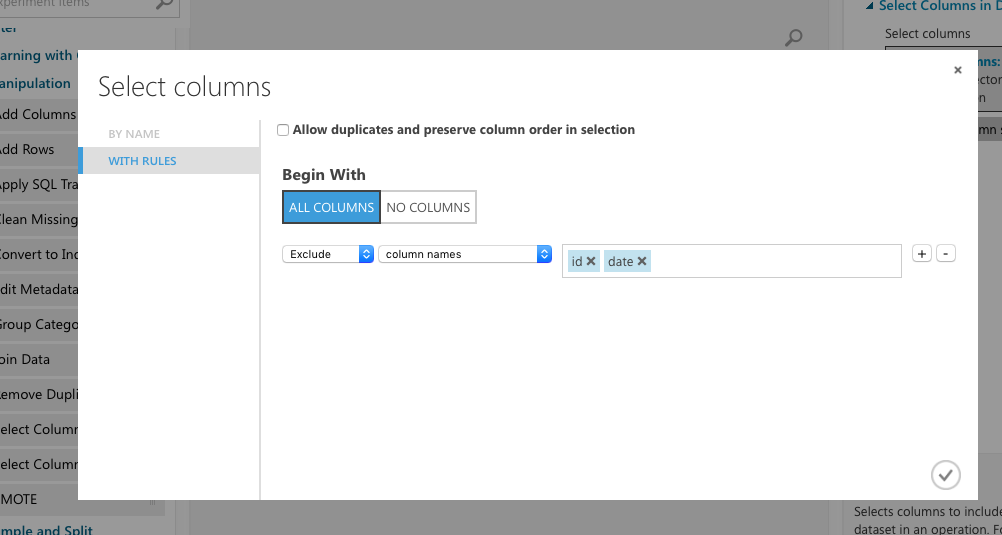
さっそく実験をやってみる。
今回はふたつのうちのいずれかなので、アルゴリズムはTwo Class Boosted Decision Treeを使ってみます。以下のようになります。
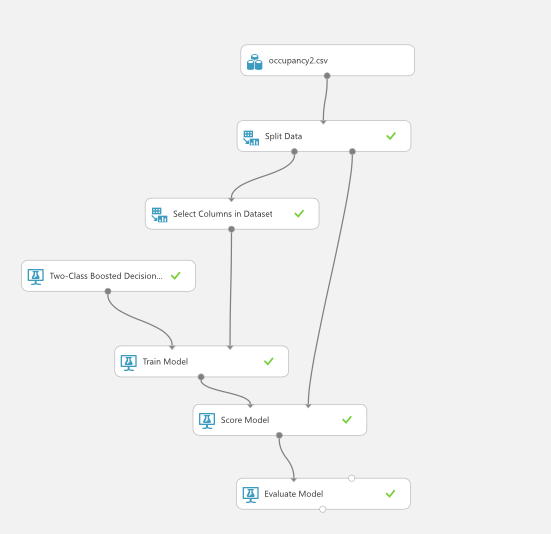
さっそく結果を見て見ましょう。
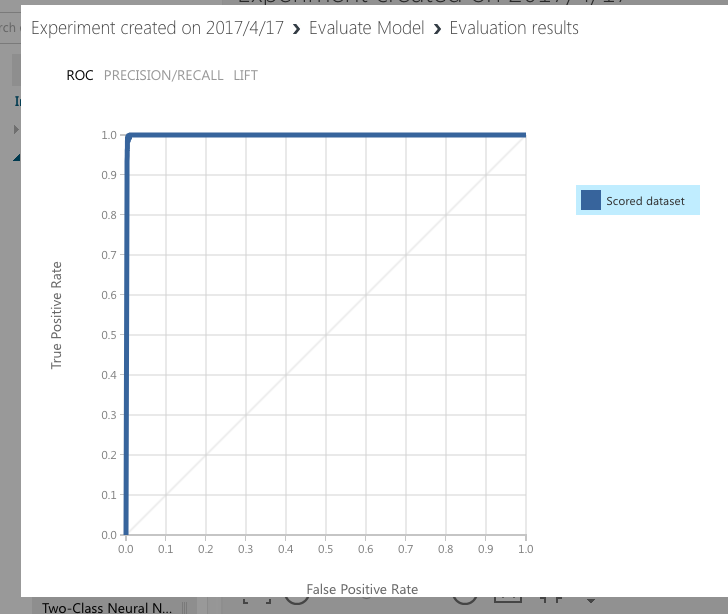
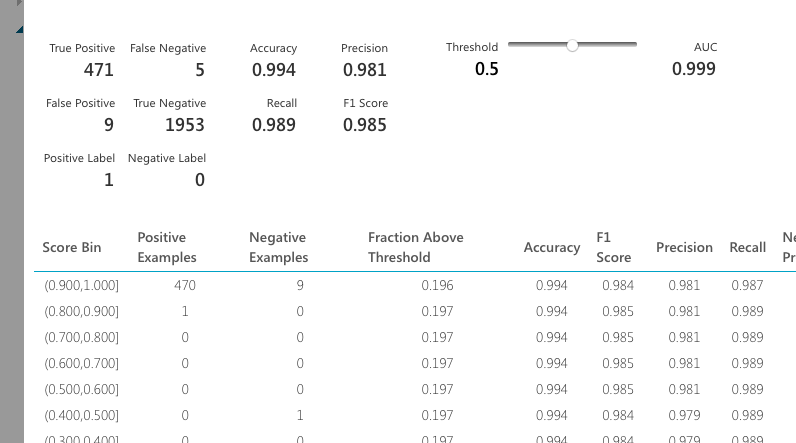
この結果ですが、なんかの間違いではないのかというくらい正確に予測しています。
まず、上のグラフですが、ROC曲線といいます。このグラフは「y軸をまっすぐ登っていって、上のほうでxに向かう」形になるほど良いとのことですので、これは完璧ではないでしょうか?
下の図の値ですが、解説は以下のURLが詳しいかと思います。
http://ibisforest.org/index.php?F値
的中率が0.994、再現率が0.989、True Positive(今回の場合、1を正しく1と予測したものの数)が471、True Negative(同じく、0を正しく0と予測した)も1953個。False系は間違えた個数ですので、いかに正確かがわかります。
今回のまとめ
このように、センサーから取得したデータなどで、ある程度因果関係が明らかなものにはめっぽう強いです。
もちろん、それなら機械学習を使うまでも無い、かもしれませんが、今回の元のcsvの中身を見て、今回の結果を判定するプログラムを書け、と言われると困るかと思います。おそらく無理ではないかと。
このように、データ量や判定する項目の数が人間の手に余る場合にも、機械学習は力を発揮します。何も画像認識とかだけではない、という事ですね。
おそらく、企業内にはデータベースなどに莫大なデータが溜まっていると考えられます。それちを利用して機械学習で、何らかの予測を行えれば、面白いことになりそうです。