さて、数学の苦手なsakaettがMicrosoft Azure ML Studioで機械学習をやってみるシリーズ第2回。
今回は、
https://archive.ics.uci.edu/ml/datasets.html
から、ポルトガル産ワインの等級データを取得して、ワインの等級を予測してみます。
データのダウンロードと修正
https://archive.ics.uci.edu/ml/datasets/Wine+Quality の「Data Folder」からダウンロードできます。今回は赤ワインを分析するので、winequality-red.csvをダウンロードしましょう。
(なんかicsにもう一つ別のワインのデータがあるようです。今度やってみよう)
中身ですが、以下のようになってます。日本でcsvというと「,」で区切るのですが、海外では「;」も多いのですかね。そういえばMySqlAdminでも「;」がデフォだった気がします。
"fixed acidity";"volatile acidity";"citric acid";"residual sugar";"chlorides";"free sulfur dioxide";"total sulfur dioxide";"density";"pH";"sulphates";"alcohol";"quality"
7.4;0.7;0;1.9;0.076;11;34;0.9978;3.51;0.56;9.4;5
7.8;0.88;0;2.6;0.098;25;67;0.9968;3.2;0.68;9.8;5
7.8;0.76;0.04;2.3;0.092;15;54;0.997;3.26;0.65;9.8;5
11.2;0.28;0.56;1.9;0.075;17;60;0.998;3.16;0.58;9.8;6
7.4;0.7;0;1.9;0.076;11;34;0.9978;3.51;0.56;9.4;5
7.4;0.66;0;1.8;0.075;13;40;0.9978;3.51;0.56;9.4;5
7.9;0.6;0.06;1.6;0.069;15;59;0.9964;3.3;0.46;9.4;5
Azure ML Studioでは、「,」で区切ってあげないといけないようですので、変換しましょう。テキストエディタを使っても良いですが、私はMacBookでこの記事を書いてるので、コンソール立ち上げてシェルスクリプトで変換します。(ちなみにこのMacBook Airは、昔在籍していた女性向けソーシャルゲームの会社から退職金がわりにもらったものです)
cat winequality-red.csv | sed "s/;/,/g" > wine-red.csv
ちなみに、Google先生にカラム名の翻訳をお願いすると、「酸性度」、「揮発性酸度」、「クエン酸」、「残留糖」、「塩化物」、「遊離二酸化硫黄」、「総二酸化硫黄」、「密度」、「pH」、「硫酸塩」、「アルコール」「品質」だそうです。ワインの成分のデータですね。色や香りのデータが入ってないのが気になります。どこのブドウで作ったとか、影響のありそうな不純物のデータなども入ってはいないようです。
データをML Studioにアップロードする。
では、csvファイルをML Studioにアップします。
画面右下の「+NEW」を押します。DataSetを選択しましょう。

FROM LOCAL FILEを選ぶと、以下の画面が表示されます。

UPするファイルを選択し、SELECT A TYPE...は「Generic CSV File with a header」のままでOKです。(1行目がカラム名になっているので)
右下のチェックをクリックするとアップロードが開始されます。
完了すると、下の図のように、画面下に表示されますので、右のOKを押して完了です。最近はこういうUIが流行りなんでしょうか?
右側のSaved DataSetsの中の「My DataSets」に、アップしたデータが入っていたら完了です。さっそくExperementsに置いてみましょう。
置いたCSVの下の◯を右クリックしてVisualizeを選択すると、以下のようにデータを表示できます。ちゃんとアップされてるか確認してみましょう。
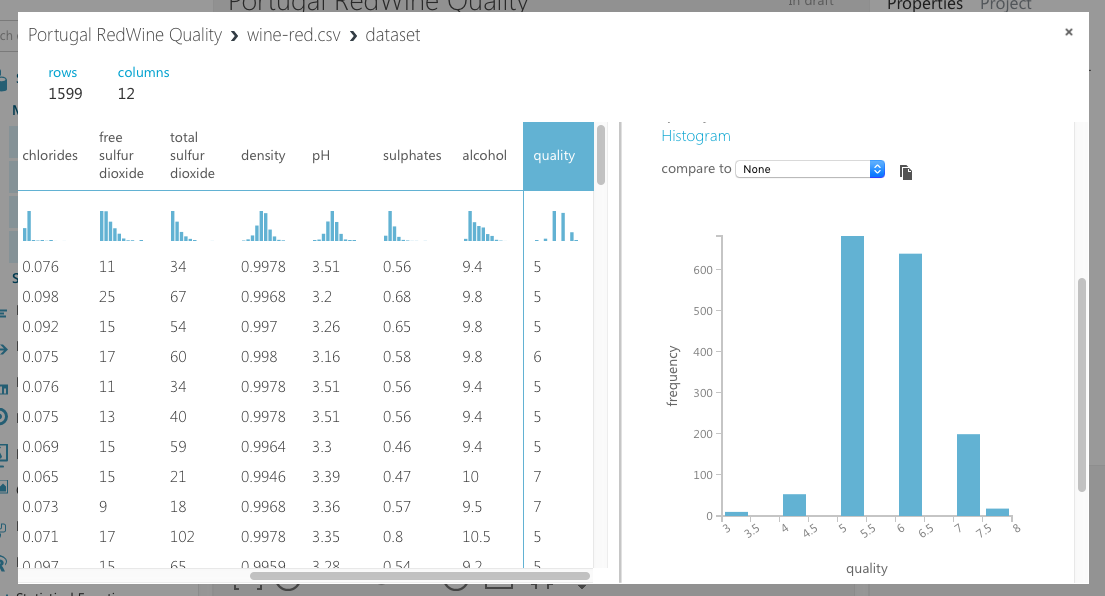
列を選択するとその中身が右側にグラフで表示されます。便利ですね。しかしこの「列を選択」という感覚は、RDBMSになれた身には違和感があります。
今回予測するのは、この「quality」の値です。どうやら3,4,5,6,7,8の6種類あるようですね。5と6が異常に多いのは、この品質が一番大衆的だからでしょうか?。3,4は料理酒が何かかな?。私はワインの味はあまりわからないのですが、飲みやすいのが好きです。しかし居酒屋でワインを飲むと悪酔いするのはなぜでしょう?。それも機械学習で予測できるのでしょうか?
本当は、取り込む前に、値の無い(DBで言うとnull)列がある場合はその行を除外したり0にしたりとかの処理が必要なのですが、今回はすべての列にデータが入っているのでそのまま投入しました。(ちなみに0にすると、その値も学習されてしまうので注意。普通は行ごと除外するようです)
データを「学習用」と「テスト用」に分ける
機械学習では、データを学習して予測できるようにするわけですが、本当に予測できるか確認するためのテストデータも必要です。
そこで、データを学習用とテスト用に分けます。
ちなみに、大きい学習モデルを作成すると、分けるタイミングを間違えて、テスト用データが学習されてしまって100%の予測精度が出た、なんてマヌケなことがありがちなので注意しましょう。
データを行単位で分割するには、Data Transformationの「Sample and Split」の「Split Data」を使います。

csvを分割するのですから、csvからsplit dataにつなげます。ちなみに、ドラッグandドロップでExprrimentに配置できるものを「Module」と呼びます。Moduleの「◯」をマウスでポイントしたままにすると、下の図のように、その◯がどのようなデータを受け取るのか、あるいはどのようなデータが出力されるのか表示されるので便利です。

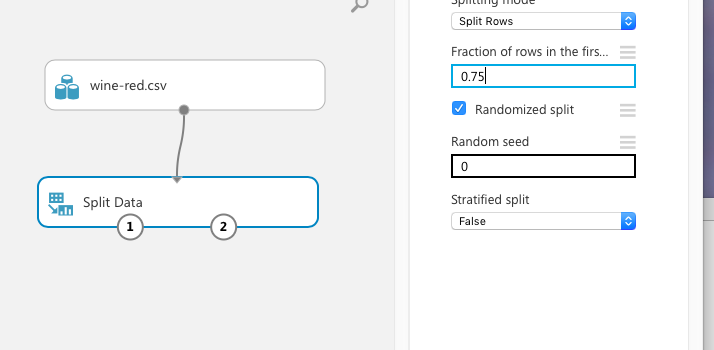
分割は割合で指定します。Experience上でモジュールを選択すると、右側に各種値の入力画面が表示されるので、画面に置いたSplit Dataモジュールを選択して下さい。
右側の「Fraction of rows ...」に分割割合を小数点で入力します。機械学習では小数点を扱うことが多いです。0が最小で1が最大というやつですね。慣れましょう。ここでは0.75にしてみます。75%が、Split Dataモジュールの下の、左側の◯から出て行きます。左を学習用データにして、残り25%をテスト用データにします。
アルコリズムを決める
機械学習には、話題のニューラルネットワークから、サポートベクターマシン、デシジョンツリーなど、様々なアルゴリズムがあります。学習させるアルゴリズムを決めるのはなかなか難しく、複数のアルゴリズムを試してみて決めることも多いのですが、分類する対象や目的によってある程度分類できるので、その中から複数のアルゴリズムを試してみましょう。
右のメニューから「Machine Learning」を開き、「Initialize Model」を開きます。以下のように表示されます。

アルゴリズムにも種類がありそうです。ここは以下のようにカテゴリ分けされています。
- Anomaly Detection -- 例外検知。データが異常な状態のものを抽出するアルゴリズムです。急に温度が上がったり、人が侵入したりなどに使えそうです。
- Classification -- クラス分類します。「男性か女性か」「犬か猫か鳥か」といった分類をしたい場合に使います。
- Clustering -- 「教師なし学習」で、グラフ上でデータの集まりを調べます。全体の傾向を見たりするのに使います。
- Regression -- 価格や温度など、数値を予測するのに使います。第一回ではこちらを使用して自動車の価格を予測しました。
今回は、3から8まであるワインの等級を調べます。すべてのデータが必ずどれかに分類され、4.8とか7.15という等級はありませんから、Classificationの中から選びましょう。

なんかたくさん出てきました。一つ一つの内容の説明はドキュメントを見ましょう。この中から一つ選択し、ML Studioの画面右下にあるQuiq Helpから解説に飛ぶことができます。英語ですが、Google翻訳様がかなり正確に翻訳してくれます。
この中では、アルゴリズムを2種類に分けています。
- Two-class ...「AかBか」「犬か猫か」2種類に分類するためのアルゴリズム
- Multiclass ... 「AかBかCか」など、3種類以上に分類するためのもの
- One-vs-All ... これは特別なモジュールで、Two-classのアルゴリズムを使ってMultiClassの分類を行うのに使用します。
今回は、ワインの等級を3から8までに分類するから、当然Multiclassから選びます。One-vs-allを使ってもよさそうです。(2クラス分類でも、何回かに分けて学習すれば複数に分けられる点は覚えておきましょう)
今回は、とりあえず「マルチクラスロジスティック回帰」を使ってみましょう。「Multiclass Logistic Regression」モジュールを選択して配置します。

学習方法を決める
アルゴリズムを学習させるから「機械学習」です。学習させるモジュールは、同じMachine Learningの「Train」にあります。「Learn」では無いんですね。いろいろなモジュールがありますが、「Train Model」を選びます。このモジュールは様々なアルゴリズムを学習するのに使うモジュールです。「Train」のほかのモジュールは、アルゴリズムのパラメータを総当たりで試す機能があるものなどがありますが、時間がかかります。
※ちなみに、アルゴリズムのパラメータは普通は機械学習で自動に求まりますが、中にはそうでないパラメータがあり、人間が決める必要があります。これを「ハイパーパラメータ」と呼ぶそうです。ハイパーですよハイパー。◯ンダムの世界以外でハイパーなんて言葉を使う機会に遭遇するとは、長生きはするものです。でも、普通のプログラムの感覚だと、逆に機械学習が自動で決めるほうを内部パラメータとか呼んでほしい気がします。
それはさておき、学習するには、学習するアルゴリズムと学習用データが必要ですので、「Train Model」の左にLogistic Regressionを、右にSplit Dataの左から出てくる学習用データをつなげます。

Train Modelの右側に赤いアイコンが出てますね。これはエラーが発生している、設定不足などを表します。マウスでこのTrain Modelを選択しましょう。
「Label column」とあります。ラベルというのは、機械学習の文脈では、学習する「回答」のことです。つまりここでは「答えの列を選べ」と言われているわけです。

「Launch column selector」を押しましょう。列を選択できるようになります。
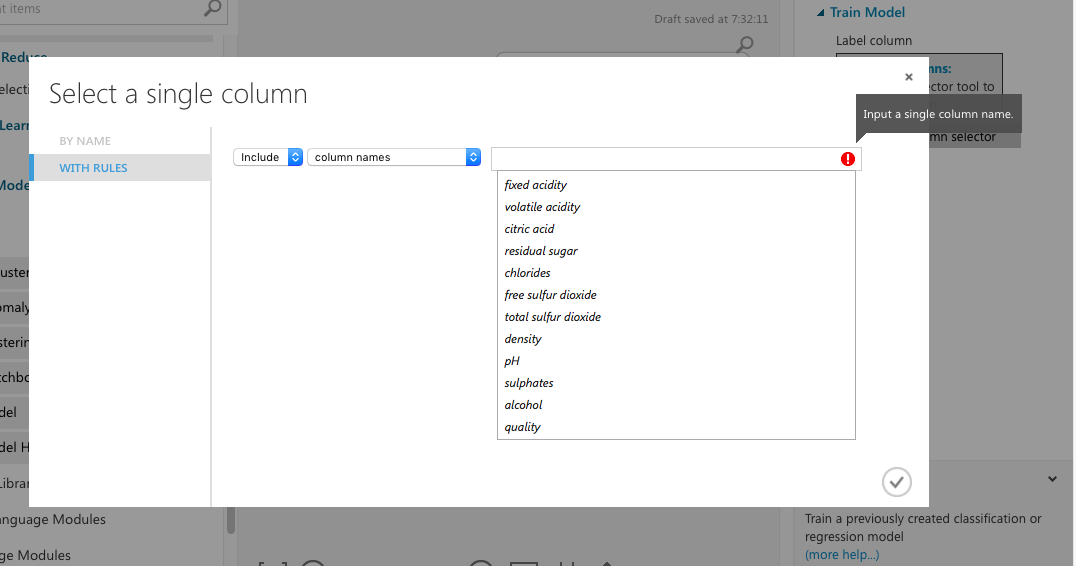
この画面は今後もよく使います。機能をざっと説明すると。
- 一番左で、カラム名で決めるか、ルールで決めるかを選びます。
- 真ん中のプルダウン。includeが「含む」excludeが「除外する」です。
- その隣、今回は「column names」列名で選びます。
- 一番左で列名を選択します。今回は「quality」列を選びます。
右下のチェックを押して列の選択を完了してください。これで、学習の準備は完了です。
学習結果をテストする。「Score」と「Evaluate」
さて、Azure ML Studioにも学習した結果を簡単にテストする仕組みがあります。前にSplit Dataでデータを学習用とテスト用に分割したことを思い出してください。
学習したモジュールをテストするには「Score」を使用します。実験の右のScoreを展開するといろいろ出てきますが、ここでは「Score Model」を使います。Score Modelを配置し、左側にTrain Modelからの出力をつなげます。右側にはSplit Dataからのテストデータを接続してください。
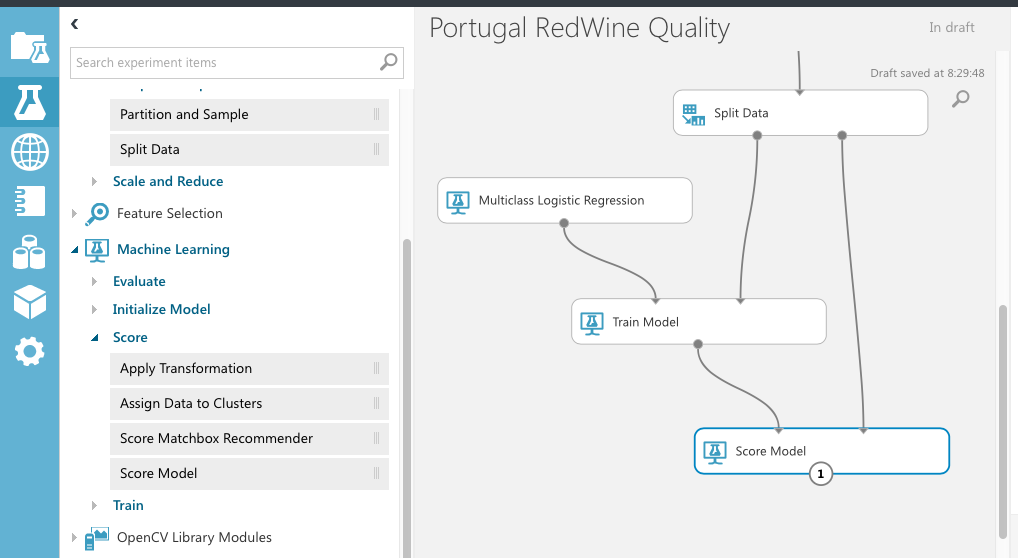
続いて、テスト結果をわかりやすく表示するために、「Evaluate Model」モジュールを配置します。

これで準備が整いました!。画面下の「RUN」で実行してみましょう。
結果は?
実行したら、「Evaluate Model」の下の◯の「Visualize」で表示してみます。ちゃんと予測できているでしょうか?

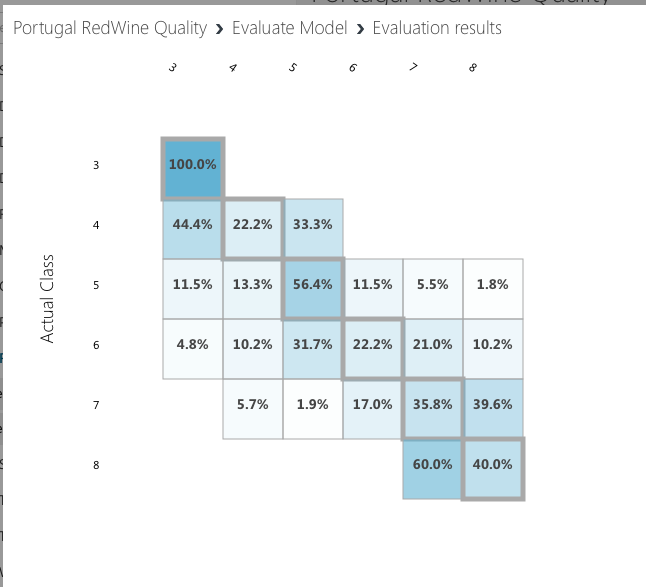
このグラフですが、縦が実際の値、横が予測した値です。「Qualityが5のものを、Qualityが5であると予測した確率」のように表示されています。
これを見ると、Qualityが3のものを5と予測したのが100%.....だめじゃん。なんだよこれ。
どうやら数学が出来ない文系エンジニアに機械学習は無理のようです。みなさんあきらめましょう。Microsoftのバーカ!。
なーんて思ってはいけません。機械学習はトライアンドエラーです。アルゴリズムの気持ちになって考えてみましょう。
学習データ量の調整
機械学習では、学習データとして投入されたデータを学習しますが、どの列をどれだけ(行数)学習するかはこちらで決めてあげる必要があります。当然、たくさん学習したことをよく覚えて、そちらに偏ります。人間と一緒ですね。
もう一回、元のデータを見てみましょう。

なんか5と6が多いですね。学習結果が5と6に偏って判定されている点から見ても、これが影響を与えていそうです。
では、学習データの量を調整してみましょう。さすがにDrag & Dropばかりで飽きてきたので、今回はR言語を使ってみます。
実は、これから使う方法は、以下のURLのサンプルを修正したものです。
右の「R Language Modules」から「Execute R Script」を選択し、Split dataとTrain Modelの間に接続します。

左側にある、スクリプトの書いてあるテキストボックスをクリックすると、下のように大きく表示されるようになりますので、ここにスクリプトを入力します。

今回は、以下のコードでqualityが3,4,7,8のデータを増やしてみました。
# 左のポートからのデータを変数dataset1に代入
dataset1 <- maml.mapInputPort(1) # class: data.frame
# data.setに、12列目(quality)のデータが3以外のデータを入れる
data.set<-dataset1[dataset1[,12]!=3,]
# posに、12列目が3のデータを入れる
pos<-dataset1[dataset1[,12]==3,]
# data.setにposを1:50の割合でバインドする
for (i in 1:50) data.set<-rbind(data.set,pos)
# dataset1にバインド済みのdata.setを入れる
dataset1 <- data.set
data.set<-dataset1[dataset1[,12]!=4,]
pos<-dataset1[dataset1[,12]==4,]
for (i in 1:10) data.set<-rbind(data.set,pos)
dataset1<-data.set
data.set<-dataset1[dataset1[,12]!=7,]
pos<-dataset1[dataset1[,12]==7,]
for (i in 1:3) data.set<-rbind(data.set,pos)
dataset1<-data.set
data.set<-dataset1[dataset1[,12]!=8,]
pos<-dataset1[dataset1[,12]==8,]
for (i in 1:30) data.set<-rbind(data.set,pos)
dataset1<-data.set
# 出力ポートにdataset1を出力する
maml.mapOutputPort("dataset1");
では、RUNして、結果を見てみましょう。
なんかだいぶマシになりました!!。でも、まだ実用的ではないですね。
とりあえず3分割してみる。
上の図を見ると、Actual つまり実際の値のうち5,6がほかの値に予測される場合も多そうです。ならいっそ、まずは3,4と5,6と7,8の3分割にしてみましょうか。
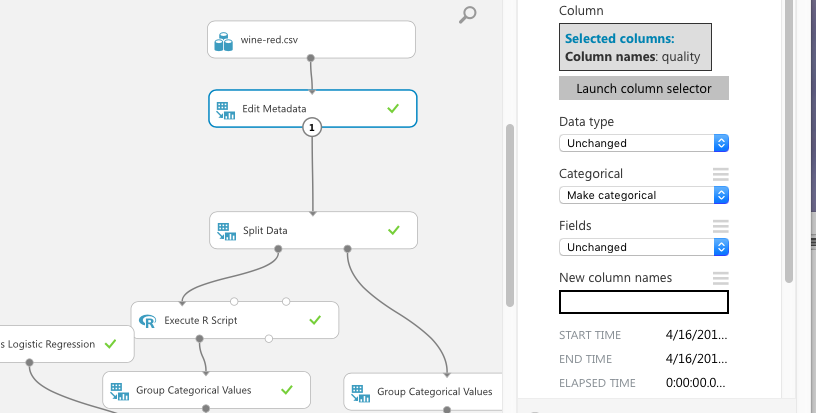
3分割にするには、quality列の中身をグループごとに書き換える必要があります。その場合、Data Transformationの中のManipurationの「Group Categorical Values」を使います。
その前に、同じ場所にある「Edit MetaData」モジュールを使って、quality列をカテゴリにします。下の図のように、Edit Metadataを使用し、quality列に「Make Categorical」を指定します。これをやっておかないとグループを作成するときにエラーとなります。
値のグループ化ですが、少しわかりにくいです。RでQuality列の値を見てデータを増やしているので、今回は面倒なのでその後にGroup Categorical Valuesモジュールを配置します。

画面右で、グループ化する列を指定します。Output ModeはInplaceにします。この場合はquality列がグループ化した値で上書きされます。Appendにすると列が追加されます。
次に、値をどう変換するか決めます。今回は2,3と4,5と6,7をそれぞれlow,mid,highにします。
まず、Default Label Name に変換後の値の初期値を入力します。カラム名ではないので注意してください。ここでは「low」を入力します。
次に、New number of labelsに、変換する値の数を入力します。今回はlow, mid,highなので「3」です。選択すると、その下に、デフォルト以外の設定項目ができます。
Name of label 1には「mid」と入力します。その下のComma-spaced ..には、「5,6」と入力します。残りは同様に「high」「7,8」です。
学習データを変換するなら、テストデータも同じです。Gorup Categorical Valuesを左クリックしてコピペし、Split Dataの右側の出力とScore Modelの右側の入力の間に入れましょう。
RUNすると、以下の結果が出ました。

うーんどうでしょう。多分、実際のワインの等級付けは、人が飲んだり見たりして決めてるのでしょうから、きっと誤差もあるはず。ならこの結果でもそこそこ予測できてるのかもしれません。
学習したレコード数が1000件ちょいと少ないのも原因かもしれません。データにはワインの成分だけが入っていて、見た目、例えば透明度とか香りの情報はも無いですから、それが原因かもしれません。まだ研究の必要があるようです。
精度を上げてみる。
もう少し精度を上げてみましょう。機械学習においてはトライアンドエラーと書きましたが、今回はまず「ハイパーパラメータ」を修正してみます。
ハイパーパラメータとは、機械学習において、学習ではなく人の手によって渡されるパラメータのことです。Azure ML Studioには、このパラメータを範囲を指定することによって、ランダムまたは総当たりでの試行を自動で行ってくれる便利なモジュール「Tune Module HyperParameters」があります。
まず、モジュールを以下のように配置してみましょう。もっと上から分岐したほうが見やすいのですが、今回は「Group Categorical values」から分岐しました。このようにAzure ML Studioでは、複数のアルゴリズムを同時に試すことができます。Tune Modelの場所にTune Model HyperParameterを置きます。
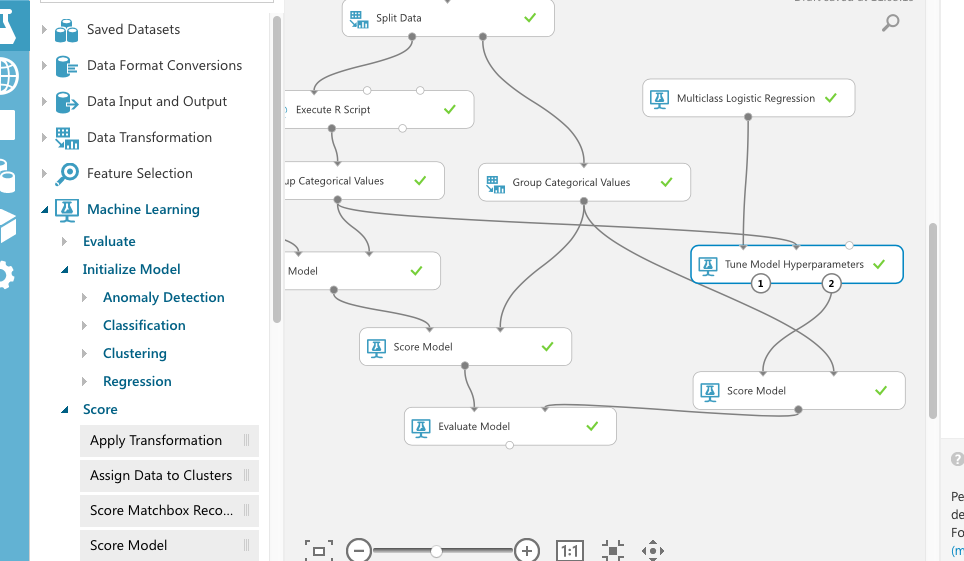
次に、Tune Hyper Parameterに接続しているMuliticass Logistic Regressionを選択してください。右の画面の上のセレクトで「Parameter Range」を選択すると、各パラメータがカンマ区切りに変わるので、その値をTune Model HyperParameterが試してくれます。

ここでは、Range Builderを使って範囲と個数を指定することもできるので、いろいろ試してみましょう。ここに固定値を(カンマ区切りでなく、値を一つ)入力すると、その値はそれで確定されます。

Tune Hyper Parameterを選択すると、右側でパラメータを試す方法を選べます。Random系がランダム、Entier gridがすべての組み合わせでしょうか。また、最適化する対象を選べます。Accureryが的中率、Recallが再現率などです。
いろいろ試してみましょう。パラメータを試す個数を上げると、そのぶん時間もかかるので注意です。
RUNしてから、Tune Hyper Parametersの右下の○でVisualizeすると、今回適用したパラメータが表示されるので、それをアルゴリズムに入力することができます。

さて、結果を見てみましょう。Evalute Modelに二つ入力があると、結果を比較してくれます。
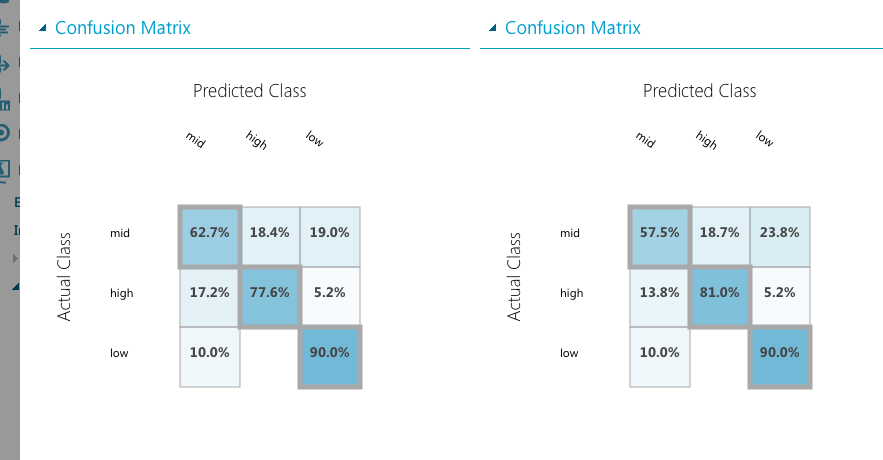
midの予測率が下がり、highが80%になりました。いろいろパラメータを変更して試してみましょう。もしかしたら、R言語で値を増やしたときに増やしすぎてmidの学習が弱くなっているのかもしれません。あるいはほかのアルゴリズムのほうが良いのかも知れませんね。
今回は、Rでqualityが3のものを増やす数を1:35にしたら下のようになりました。

mid、つまりqualityが5,6のものの精度がまだ低めですが、案外こんなものかもしれません。ワインの等級はおそらく人のが飲んでみて決めていると考えると、「中位のワイン」は判定が難しいのかもしれませんね。私もめちゃくちゃ美味しい日本酒と不味い日本酒はわかりますが、普通くらいと言われると困りますし。