会社業務ではGitHub Enterprise(以下GHE)のお守りをしています。
運用改善や数度のバージョンアップを経験した結果、少しずつ(主にインフラ面での)運用の感覚が分かってきたので、記事にまとめます。
システムの構成
今回取り上げる会社のGitHub Enterprise環境はこんな感じのものです。
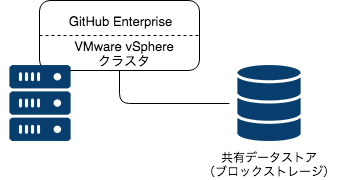
GHEは、プライベートクラウドとして構築されたVMware vSphere上のインスタンスとして稼働しています。ストレージとして、クラスタ共有のブロックストレージをマウントしています。
利用ユーザはエンジニアだけでも数百人程度、加えてマシンユーザや非エンジニアユーザからの利用もかなりの数があります。数十システムのソースコード管理・コラボレーションサービスとして利用されているという状況です。
アクティビティとしては、おおむね週に1500 Pull Requestsぐらい出ているようです。

なお、執筆時点のバージョンはGHE 2.15.1です(極力最新になるように努めています)。
ナレッジあれこれ
インスタンスはそれなりに強いものを
GHEのドキュメントでは、利用規模に応じたインスタンスのスペックについて、次のような推奨値を出しています。
| Seats | vCPUs | Memory | Attached storage | Root storage |
|---|---|---|---|---|
| 10-500 | 2 | 16 GB | 100 GB | 200 GB |
| 500-3000 | 4 | 32 GB | 250 GB | 200 GB |
| 3000-5000 | 8 | 64 GB | 500 GB | 200 GB |
| 5000-8000 | 12 | 72 GB | 750 GB | 200 GB |
| 8000-10000+ | 16 | 128 GB | 1000 GB | 200 GB |
しかしながら、表はかなり利用頻度が低い状況を想定しているようです。たぶん普通は、これだけのスペックでは足りません。
そもそもこの値は古代のGHE 2.1の頃から更新されていない様子がある上、特に最近はGHE 2.14からリソース消費が激しくなったように思います。
GitHub Enterprise 2.12 → 2.14 にしてパフォーマンスデグレしてると思うのでサポートに連絡しつつしぶしぶオーバーサイズなスケールアップをして、お話の結果「うん、スケールアップしてCPUに余裕出てるね^^」と言われて「は?」ってなっている。
— そらは (@sora_h) 2018年8月22日
同意しかないですね……。
GHEの内部実装はあまりはっきり示されていないですが、ワークロードとしては細かいIOが大量に発生します。この事はドキュメントの別の箇所に記載されています。
The amount of physical memory allocated to your GitHub Enterprise instance can have a large impact on overall performance and application responsiveness. The system is designed to make heavy use of the kernel disk cache to speed up Git operations. We recommend that the normal RSS working set fit within 50% of total available RAM at peak usage.
https://help.github.com/enterprise/2.15/admin/guides/installation/recommended-alert-thresholds/#monitoring-memory-usage
したがって、次の条件を守ることが重要らしいと理解するに至りました。
- メモリを十分に積む
- 会社のインスタンスは、数度のスケールアップを経て、現在メモリ128GBで運用しています)
- できるだけOSにキャッシュ領域を与え、ブロックストレージへのアクセスを減らす
- 高速(低レイテンシ高スループット)なブロックストレージを用意する
- 会社のインスタンスはSSDストレージをバックエンドとして利用しています
ちなみに、GHEは色々なデーモン(application, mysql, elasticsearch, redis, etc...)が1インスタンスに相乗りしているらしく、ワークロードとしてもかなり複雑に見えます。例えば、急にresqueのIOが大量に発生したりします。
そういった点からも、リソースは多めに積んでおくに越したことはありません。
停止を覚悟する
ドキュメントによると、GHEの利用形態として3つのモードがあるとされています。
- 単に1インスタンスで動作するモード(この記事ではスタンドアロンモードと呼びます)
- 高可用性モード(HA configuration)
- クラスタリングモード(clustering configuration)
このうち、クラスタリングモードは複数ノード構成を取れる……らしいのですが、伝え聞くところによると採用している企業はわずか(本当に大量の利用がある組織のみ)で、運用も大変になるとのことでした。ドキュメントでもわざわざ「採用を検討するなら連絡くれよ」というぐらい珍しい構成のようです。
Clustering is designed for specific scaling situations and is not intended for every organization. If clustering is something you'd like to consider, please contact your dedicated representative or our account management team at sales@github.com.
https://help.github.com/enterprise/2.15/admin/guides/clustering/clustering-overview/
というわけで、普通の組織はスタンドアロンモードorHAモードの2択です。
さて、スタンドアロンモードの時に困るのは、可用性をどう担保するかです。
- インスタンス障害を起こして利用できなくなるのは困る
- 大きなアップデート時には再起動が必要
- セキュリティアップデートであっても再起動を求められることがある
困ったことに、これらの問題をHAモードなら回避できるか!? というと、そうではないらしいです。
Zero downtime upgrades. To prevent data loss and split-brain situations in controlled promotion scenarios, place the primary appliance in maintenance mode and wait for all writes to complete before promoting the replica.
https://help.github.com/enterprise/2.15/admin/guides/installation/about-high-availability-configuration/
つまり、ハードウェア・ソフトウェアの障害をactive-standby構成で回避できるというだけで、ゼロダウンタイムを目指すための構成ではないということです。
結局、次のような構成をとることにしました。
- スタンドアロンモードで動作させる
- ホスト障害はプライベートクラウドの機能であるvSphere HAで対処することとし、停止時間を最小化する
- アップデート時などは停止メンテナンスとする
- 利用が少ない深夜や早朝に停止計画を立てて実施しています
GHEメンテナンス時に緊急の利用(利用システムでの障害対応が発生した等)があった場合にどうするか? は、GHE単独で解決させることができず、難しい問題として残っています。
バックアップは悩ましい
公式ドキュメントで提示されているバックアップ手段は、backup-utilsを使うものです。
このツールはバックアップ用のストレージを持つインスタンスから実行するものです。ツールはGHE本体にSSHアクセスし、そこからrsyncなどを駆使してバックアップデータを差分バックアップする、という挙動をします。これをsystemdのtimer(や、その他のcron的な機構)で定期実行せよというわけです。
ツールは実装としてかなり素朴なようで、確かにちゃんと動くのですが、これまでにいくつか問題を踏んでしまいました。
- バックアップ先のストレージへの負荷がそれなりに高い
- GHE内部のGitディレクトリをそのままrsyncしているらしく、大量のファイルにアクセスするという負荷の高い挙動を示します
- 極めて稀だが、バックアップが刺さる(スクリプトの実行が終わらなくなる)ことがあった
そんなわけで、(たぶん)素朴なツールではあるのですが、しばらくの試行錯誤が必要でした。
- ブロックストレージチームと相談しながら、ストレージの調整
- バックアップスクリプトの定期実行を監視して、異常時にはアラートを飛ばすようにした
- 具体的にはDataDogへのEvent通知スクリプトを書き、バックアップイベントを監視するようにしています
おそらくですが、他の環境であれば別のバックアップ手段を取ることも考えられるのでは、と思っています。例えば、ブロックデバイスレベルのスナップショットです(e.g. AWSのEBS Snapshot)。
メンテナンス予告機能は……誰も使ってない?
前述のように、GHEではどうしても停止メンテが発生するのですが、メンテナンスを事前設定し、利用者に予告する機能(schedule a maintenance window)があります。
「スケジュールを入れると、全てのページにメンテ時間の予告が出る」「予告時間になると自動的にメンテ画面に移行してくれる」などなど、それなりに便利です。
さて、これいいじゃん!! と思って使おうとすると、機能的にかなり微妙な点があることに気付きました。
- UIからの時間指定が、「2時間後メンテ」「1時間後メンテ」「30分後メンテ」しかできない
- いざ有効化すると、 全てのページが 500 Internal Server Errorを返す バグがあった
というわけで、あまり活用できていません。どれぐらいのGHE運用者がこの機能を使っているのか若干疑問に思っています。
記事の執筆時点ではmanagement consoleのmaintenance APIを使うと任意時間にメンテナンス設定ができるようになるので、今後はこれを試してみようとしている所です。
ちなみに…… スクリプトを書き軽く動作させてみたところ、入力時間がUTCで解釈されるらしく、日本時間と9時間ずれました。こいつ大丈夫か感は相変わらずです。
サポート連絡は日本語でもOK
GHEのサポートを受ける場合、専用のポータルから質問文を投げることになると思います。
サイトが英語なので、頑張って英作文することに……? と考えるわけですが、日本語でも実は問題ないっぽいです。よく考えたら日本法人があるわけですし、日本向けサポート体制もあるようでした。
新バージョンのリリースは火曜日(日本時間の水曜日)
GHEのリリース日は、リリース一覧を見ると気づくのですが、必ず火曜日というルールになっているようです。
日本時間でいうと、水曜の0時〜2時(火曜の24〜26時)ぐらいにリリースがあります。時差を踏まえるに、リリース作業はアメリカ東海岸でやってるんでしょうか?
リリース間隔は不定期で、1週間後にすぐ次のバージョンが出ることもあれば、数週間ほど間が空くこともあります。
-
リリースのRSSフィードを見ておく
- 会社ではSlackに通知するようにしてあります
- 火曜深夜(水曜未明)のアップグレード作業を避ける
- アップグレードが終わった 😎 → 3分後に新バージョンが来る → 😭 という流れは精神衛生上よくないです(実話)
これらのプラクティスの導入で、運用がちょっとだけ楽になりました。
その他
いまどきEnterprise版である価値はある?
例えば、パブリックなサービスとの連携などを考えると、github.com版(TeamやBusiness Cloud)の方がシームレスに行く場合が少なくないと思っています。実際、会社のプロダクトのSCMは全てGHEかというとそうではなく、github.com版を併用していることもあります。
また、オープンソース化されたプロダクトの成果物はgithub.comに置かれています。
とはいえ、会社では長年GHEを運用してきた経緯があるため
- イントラネットにある社内システムとの連携が作り込まれている箇所がある
- 色々な成果物(ソースコードや社内ドキュメントなど)にURLが埋め込まれている
などなど、GHEは資産の一部になっているという側面もあります。少なくとも当面はGHEを使い続けることになりそうだと思っています。
まとめ
GitHub Enterpriseの運用をしばらくやってみたので、経験したことをまとめました。
売られている製品だけあって基本的に完成度は高く運用は楽なのですが、快適なGHEを保つには多少工夫をしてやる必要があることがわかりました。