この記事で紹介するのは高スループットなBase64エンコードの実装方法です。
Base64は、Webの世界を始めとして、世界中さまざまな箇所で使われているエンコード方式です。とてもよく使われるので、高速化についてもしばしば研究されてきたようです。
高速化の最新成果として、2019年10月に、Wojciech Muła, Daniel Lemireによる新しい論文がarxivに投稿されました。なかなか強烈なタイトルが付いています。
Base64 encoding and decoding at almost the speed of a memory copy
論文の主張としては、x86 CPUの持つ最新の命令群を駆使することで、非常に高効率なBase64エンコード・デコードが実現できたというものです。このQiita記事では論文の内容の一部を紹介します。
- Base64は問題としては単純に見えるが、簡単に解けるというほど単純でもない
- Qiitaで紹介しやすい程度の複雑さだと感じました
- AVX-512を非常にうまく使った事例になっている
- 得られる実装は簡潔かつ美しいものです
という辺りがとても気に入っています。
前提知識
Base64
Base64そのものについてはWikipediaの記事などを参照してください。要するに入力を6ビット単位で分割し、( $2^6=$ )64文字の変換テーブルにしたがって変換したものです。
https://ja.wikipedia.org/wiki/Base64
6ビットで1文字を表す表現なので、入力3バイトが出力4バイトになります。以降、しばしば3バイトの入力を例として使います。
6ビットずつ切り出して変換するだけなら単純そうですが、微妙な問題があります。6ビットの塊は、各バイトからビットオーダーとして最上位ビット(MSB)から順に6ビットずつ取るアルゴリズムなのです。
x86 CPUは最下位ビットがメモリアドレス最下位に来るアーキテクチャです。どういうことかというと、0バイト目の最下位ビットがメモリアドレスの最下位に来て、その次の1ビット目、2ビット目……7ビット目(MSB)そして1バイト目の最下位ビットと続きます。このことをIntelのマニュアルでは次のように表現しています
In illustrations of data structures in memory, smaller addresses appear toward the bottom of the figure; addresses increase toward the top. Bit positions are numbered from right to left. The numerical value of a set bit is equal to two raised to the power of the bit position. Intel 64 and IA-32 processors are “little endian” machines; this means the bytes of a word are numbered starting from the least significant byte. See Figure 1-1.
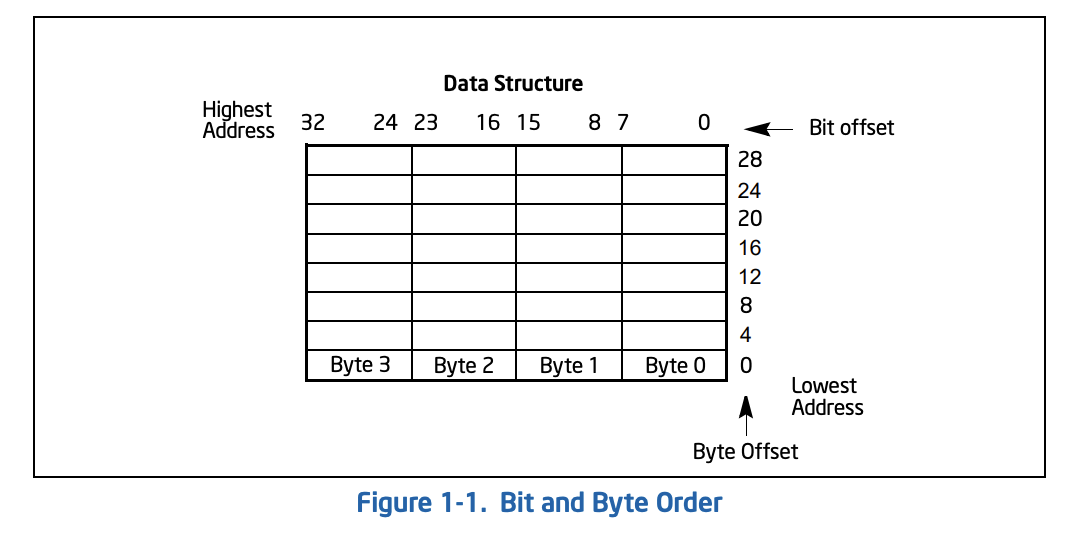 出典: [Intel® 64 and IA-32 Architectures Software Developer's Manual Volume 1: Basic Architecture](https://software.intel.com/en-us/download/intel-64-and-ia-32-architectures-software-developers-manual-volume-1-basic-architecture)
出典: [Intel® 64 and IA-32 Architectures Software Developer's Manual Volume 1: Basic Architecture](https://software.intel.com/en-us/download/intel-64-and-ia-32-architectures-software-developers-manual-volume-1-basic-architecture)
例えばASCII文字列 ABC は16進数で書くと 0x41, 0x42, 0x43 ですが、 メモリアドレス下位から順に左から右へと 1ビットずつ書くと
\overbrace{1 0 0 1 0 1 0 0}^{\verb|A|} | \overbrace{0 1 0 1 0 1 0 0}^{\verb|B|} | \overbrace{1 1 0 1 0 1 0 0}^{\verb|C|}
これがx86 CPU上のビットの並びです。見やすさのためバイト境界には $|$ を書きました。
Base64の6ビット分割は、各バイトの最上位ビットから順に6ビットずつ取ります。つまり0バイト目の最上位ビット、1ビット目、2ビット目……7ビット目(最下位ビット)、そして1バイト目の最上位ビットというビット列から6ビットずつ切り出していきます。
つまり、先の例でいうと、最初の6ビットは
1 0 \underbrace{0 1 0 1 0 0}_{1つ目の6ビット} | \overbrace{0 1 0 1 0 1 0 0}^{\verb|B|} | \overbrace{1 1 0 1 0 1 0 0}^{\verb|C|}
ここになります。2つ目以降の6ビットも表記してみます。
\underbrace{1 0}_{2つ目} \underbrace{0 1 0 1 0 0}_{1つ目} | \underbrace{0 1 0 1}_{3つ目} \underbrace{0 1 0 0}_{2つ目} | \underbrace{1 1 0 1 0 1}_{4つ目} \underbrace{0 0}_{3つ目}
問題のややこしさが見えてきたでしょうか。x86 CPUのメモリ上では、Base64の処理単位である6ビットの塊が不連続に配置されてしまっているのです。ビットオーダーが逆であれば単純だったのですが……。
節のまとめとして、以上の説明までを含んだ簡易エンコーダのRuby実装を示します。この実装はBase64仕様全てを満たしているわけではない点に注意してください(パディングを含む入力の切れ端部分の処理が入っていません)。
def base64_encode(str)
enum = Enumerator.new do |y|
str.bytes.each do |b|
7.downto(0).each do |idx|
y << ((b >> idx) & 1)
end
end
end
table = [*('A'..'Z'), *('a'..'z'), *('0'..'9'), '+', '/']
enum
.each_slice(6)
.map { |chunk| chunk.inject { |a, b| (a << 1) | b } }
.map { |x| table[x] }
.join('')
end
AVX-512
AVX-512そのものについては、以前に書いた記事などを参照してください。
SIMDプログラミング入門(AVX-512から始める編)
今回の実装で特徴的なのは、AVX-512VBMIをフル活用する点です。2つの命令が活躍します。
- VPERMB
- VPMULTISHIFTQB
VPERMBは、オペランドの各バイトについてテーブル参照を行う命令です。64バイトあるzmmレジスタの参照先要素を各バイトの下位6ビットで指定します(上位2ビットは無視されます)。
VPMULTISHIFTQBは、オペランドの各バイトについて、任意の位置から1バイトを切り出すという操作を行う命令です。ただし、8バイト境界は超えられません。Intelの提示する図が見やすいと思います。
出典: [Intel® 64 and IA-32 Architectures Optimization Reference Manual](https://software.intel.com/en-us/download/intel-64-and-ia-32-architectures-optimization-reference-manual)
ちなみに、残念なことに、2019年11月現在、今回の実装を実機動作させられる市販CPUはそれほど多く出回っていません1。Cannon LakeもしくはIce LakeのCPU世代のCPUが必要です。 バイト単位シャッフルはものすごく汎用性があるので、Skylake-SP世代から導入しておいてほしかった……。
アルゴリズム・実装
さて、とうとうここから、AVX-512でBase64エンコードをする手法について説明します。
メモリから入力48バイトを受け取り、64バイトにエンコードして書き出すのがプログラム全体の流れです。言い方を変えると、3バイトをBase64エンコードで4バイトにする処理を同時に16並列で行います。以降では3バイト → 4バイトへの変換に注目します。
アルゴリズム
Base64の処理単位である6ビットの塊4つをそれぞれ$a, b, c, d$と書くことにします。そして、その添字で何ビット目かを表すことにします。例えば$a$は$a_0, a_1, a_2, a_3, a_4, a_5$の6ビットからなります。
これまで説明したように、$a, b, c, d$は入力として不連続に配置されています。
b_4\ b_5\ a_0\ a_1\ a_2\ a_3\ a_4\ a_5\ |\ c_2\ c_3\ c_4\ c_5\ b_0\ b_1\ b_2\ b_3\ |\ d_0\ d_1\ d_2\ d_3\ d_4\ d_5\ c_0\ c_1
最初にこのビット列を加工して、$a, b, c, d$がバイト単位で固まっている状況を作ることを考えます。
b_4\ b_5\ a_0\ a_1\ a_2\ a_3\ a_4\ a_5\ |\ c_2\ c_3\ c_4\ c_5\ b_0\ b_1\ b_2\ b_3\ |\ d_0\ d_1\ d_2\ d_3\ d_4\ d_5\ c_0\ c_1 \\
\Downarrow\\
a_0\ a_1\ a_2\ a_3\ a_4\ a_5\ x\ x\ |\ b_0\ b_1\ b_2\ b_3\ b_4\ b_5\ x\ x\ |\ c_0\ c_1\ c_2\ c_3\ c_4\ c_5\ x\ x\ |\ d_0\ d_1\ d_2\ d_3\ d_4\ d_5\ x\ x
ここで$x$はdon't careです(加工後ここに何が入っていようと構わない)。この並びを実現するには、まず元入力の0, 1, 2バイト目を、VPERMBで1, 0, 2, 1バイト目の並びにします。
b_4\ b_5\ a_0\ a_1\ a_2\ a_3\ a_4\ a_5\ |\ c_2\ c_3\ c_4\ c_5\ b_0\ b_1\ b_2\ b_3\ |\ d_0\ d_1\ d_2\ d_3\ d_4\ d_5\ c_0\ c_1 \\
\Downarrow \mathtt{VPERMB}\\
c_2\ c_3\ c_4\ c_5\ b_0\ b_1\ b_2\ b_3\ |\ b_4\ b_5\ a_0\ a_1\ a_2\ a_3\ a_4\ a_5\ |\ d_0\ d_1\ d_2\ d_3\ d_4\ d_5\ c_0\ c_1\ |\ c_2\ c_3\ c_4\ c_5\ b_0\ b_1\ b_2\ b_3
こうすることで、分断されていた $b_3, b_4$と$c_1, c_2$が連続したビット並びになりました。
並びとしてくっついたので、VPMULTISHIFTQBでシフト量10, 4, 22, 16で切り出します。
c_2\ c_3\ c_4\ c_5\ b_0\ b_1\ b_2\ b_3\ |\ b_4\ b_5\ a_0\ a_1\ a_2\ a_3\ a_4\ a_5\ |\ d_0\ d_1\ d_2\ d_3\ d_4\ d_5\ c_0\ c_1\ |\ c_2\ c_3\ c_4\ c_5\ b_0\ b_1\ b_2\ b_3 \\
\Downarrow \mathtt{VPMULTISHIFTQB} \\
a_0\ a_1\ a_2\ a_3\ a_4\ a_5\ d_0\ d_1\ |\ b_0\ b_1\ b_2\ b_3\ b_4\ b_5\ a_0\ a_1\ |\ c_0\ c_1\ c_2\ c_3\ c_4\ c_5\ b_0\ b_1\ |\ d_0\ d_1\ d_2\ d_3\ d_4\ d_5\ c_0\ c_1
ようやく$a, b, c, d$がバイト単位で固まっている状況が作れたので、あとはVPERMBによるテーブル変換をするだけです。
とても都合がいいことに、zmmレジスタには64バイトのBase64変換テーブルがピッタリ入ります。Base64の変換テーブルであるASCII文字列 ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/ をそのままzmmレジスタにロードし、先程の結果をインデックスとしてVPERMBを適用することで、変換が完了します。
以上の手続きは3バイトを例にしましたが、zmmレジスタ上で入力48バイト全体に関して同じように処理できます。
実装例
SIMD部分に限った実装をすると、以下のようになります。
# include <cstdint>
# include <immintrin.h>
//
// srcからsizeバイト読み込み、Base64エンコードした結果をdstに書き出す。
//
void base64_encode(uint8_t *src, size_t size, uint8_t *dst)
{
const __m512i table = *reinterpret_cast<const __m512i*>("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/");
constexpr __mmask64 loadmask = 0xffffffffffff; // 48bit
for (size_t i = 0; i + 47 < size; i += 48) {
__m512i input = _mm512_maskz_loadu_epi8(loadmask, src + i);
const __m512i idx = _mm512_set_epi8(46, 47, 45, 46, 43, 44, 42, 43, 40, 41, 39, 40, 37, 38, 36, 37, 34, 35, 33, 34, 31, 32, 30, 31, 28, 29, 27, 28, 25, 26, 24, 25, 22, 23, 21, 22, 19, 20, 18, 19, 16, 17, 15, 16, 13, 14, 12, 13, 10, 11, 9, 10, 7, 8, 6, 7, 4, 5, 3, 4, 1, 2, 0, 1);
input = _mm512_permutexvar_epi8(idx, input);
const __m512i ctl = _mm512_set_epi8(48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10);
input = _mm512_multishift_epi64_epi8(ctl, input);
input = _mm512_permutexvar_epi8(input, table);
_mm512_storeu_si512(dst, input);
dst += 64;
}
// 余り部分はスカラ処理する(省略)
}
もちろん _mm512_set_epi8 の引数は機械的に生成できるものです。
$ ruby -e'a=[]; 16.times{|x| a << [1, 0, 2, 1].map{|e| e + 3*x } }; puts a.flatten.reverse.join(", ")'
46, 47, 45, 46, 43, 44, 42, 43, 40, 41, 39, 40, 37, 38, 36, 37, 34, 35, 33, 34, 31, 32, 30, 31, 28, 29, 27, 28, 25, 26, 24, 25, 22, 23, 21, 22, 19, 20, 18, 19, 16, 17, 15, 16, 13, 14, 12, 13, 10, 11, 9, 10, 7, 8, 6, 7, 4, 5, 3, 4, 1, 2, 0, 1
$ ruby -e'puts ([10,4,22,16, 42,36,54,48] * 8).reverse.join(", ")'
48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10, 48, 54, 36, 42, 16, 22, 4, 10
Clang10にて生成される命令列を確認します(定数表は巨大だったので省略します)。
コンパイルオプション: -S -O3 --std=c++17 -mavx512f -mavx512bw -mavx512vbmi -masm=intel
__Z13base64_encodePhmS_: ## @_Z13base64_encodePhmS_
.cfi_startproc
## %bb.0:
push rbp
.cfi_def_cfa_offset 16
.cfi_offset rbp, -16
mov rbp, rsp
.cfi_def_cfa_register rbp
cmp rsi, 48
jb LBB0_3
## %bb.1:
vmovdqa64 zmm0, zmmword ptr [rip + l_.str]
mov eax, 47
movabs rcx, 281474976710655
vmovdqa64 zmm1, zmmword ptr [rip + LCPI0_0] ## zmm1 = [1,0,2,1,4,3,5,4,7,6,8,7,10,9,11,10,13,12,14,13,16,15,17,16,19,18,20,19,22,21,23,22,25,24,26,25,28,27,29,28,31,30,32,31,34,33,35,34,37,36,38,37,40,39,41,40,43,42,44,43,46,45,47,46]
vmovdqa64 zmm2, zmmword ptr [rip + LCPI0_1] ## zmm2 = [10,4,22,16,42,36,54,48,10,4,22,16,42,36,54,48,10,4,22,16,42,36,54,48,10,4,22,16,42,36,54,48,10,4,22,16,42,36,54,48,10,4,22,16,42,36,54,48,10,4,22,16,42,36,54,48,10,4,22,16,42,36,54,48]
.p2align 4, 0x90
LBB0_2: ## =>This Inner Loop Header: Depth=1
kmovq k1, rcx
vmovdqu8 zmm3 {k1} {z}, zmmword ptr [rdi + rax - 47]
vpermb zmm3, zmm1, zmm3
vpmultishiftqb zmm3, zmm2, zmm3
vpermb zmm3, zmm3, zmm0
vmovdqu64 zmmword ptr [rdx], zmm3
add rdx, 64
add rax, 48
cmp rax, rsi
jb LBB0_2
LBB0_3:
pop rbp
vzeroupper
ret
Clangはなぜかkmovをループ外に巻き上げてくれない2のが気になりますが、とはいえ基本的に非常にきれいなコードが出ているように見えます。
この記事で触れなかったこと
執筆時間の関係でデコードについては省略します ![]()
デコード(Base64文字列を元のバイナリ列に戻す)はエンコードの処理を逆にやればいいのかというと、そうではありません。それなりに差異があります。
- エラー処理をしなければならない
- VPMULTISHIFTQBの逆に相当する命令がない
バイト境界に整列した6ビット値を詰め直すのは難しそうな問題ですが、論文ではVPMADDUBSWなどを駆使した巧妙な実装を提案しています。興味のある方は読んでみてください。
まとめ
この記事では最新の拡張命令を用いた高速なBase64エンコード実装について紹介しました。48バイト入力に対してわずか3命令でエンコード結果が得られる簡潔なSIMD実装です。
2019年現在まだまだVBMIを使えるプラットフォームは多くないのですが、時間とともに今回紹介したようなアルゴリズムが広まっていくのかもしれません。
関連リンク
- Base64 encoding and decoding at almost the speed of a memory copy
- http://0x80.pl/articles/index.html#base64-algorithm-update