はじめに
現在、人文学データセンターがホストとなりkaggleにて、くずし字の認識コンペが開催されています。今回は、センターから公開されているくずし字のデータセットを使って、まっちゃんを描画します。
 まっちゃん
まっちゃん
本記事は、同じくkaggleに公開されている下記カーネルを参考にさせていただきました。
・Kuzushiji-MNIST Cat
データセット
データは、こちらからダウンロードできます。
『KMNISTデータセット』(CODH作成) 『日本古典籍くずし字データセット』(国文研ほか所蔵)を翻案 doi:10.20676/00000341
今回は、Kuzushiji-49内のk49-train-imgs.npzを使用します。

環境
ローカルにデータをダウンロードして、jupyter notebook にて実行します。
カレントフォルダに、上記の "k49-train-img.npz" および、まっちゃん画像 "matchan.jpg" を用意します。
macOS Mojave
・python 3.6.5
・numpy 1.16.3
・pandas 0.24.2
・mlcrate 0.2.0
・skimage 0.15.0
・matplotlib 3.0.3
実装
ライブラリのインポート
import numpy as np
import pandas as pd
import mlcrate as mlc
from skimage.io import imread, imsave
from skimage.transform import resize
import matplotlib.pyplot as plt
%matplotlib inline
元画像の読み込み
次に、元画像を読み込み、白黒画像(グレースケール化)します。
image = imread('matchan.jpg') # => image.shape = (252, 200, 3)
# グレースケール化
image = image[:,:,0]
plt.imshow(img, cmap='gray')

データセット読み込み
くずし字データセットを読み込み、各文字の画像におけるグレーレベル(白黒の比率)を見てみる。また、各文字とそのグレーレベルを辞書化。
imgs_train = np.load('k49-train-img.npz')['arr_0']
means = (255 - imgs_train).mean(axis=1).mean(axis=1)
plt.hist(means, bins=50, log=True)
# 辞書化
from collections import defaultdict
character_bins = defaultdict(list)
for char, mean in zip(imgs_train, means):
character_bins[int(mean)].append(char)
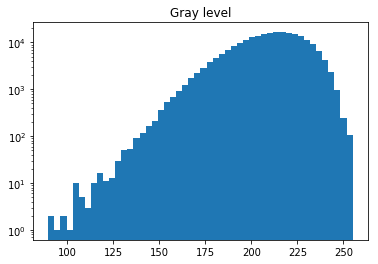
このグラフから、このデータセットには、グレーレベルが低い(約90以下)画像は無いことがわかる。
元画像をリスケール
# 各ピクセルが文字に置き換えられるので、これに28x28が乗算される。
OUTPUT_RESOLUTION = (96, 75)
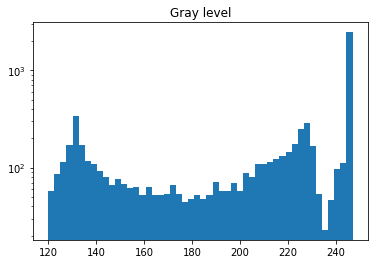
# データセットには、グレーレベルが低い画像が無いため、各ピクセルを(120, 245)にリスケールする。
img_small = (resize(img, OUTPUT_RESOLUTION, preserve_range=True) / 2) + 120
plt.hist(img_small.flatten(), bins=50, log=True)
plt.title('Gray level')
plt.show()
plt.imshow(img_small, cmap='gray')

新しい画像を作成
上記、まっちゃん画像の全てのピクセルをループして、くずし字画像から同じグレーレベルのものをランダムに選択し、新しい画像の同じ位置に配置していく。
# 新しい空の画像
new_img = np.zeros((img_small.shape[0]*28,
img_small.shape[1]*28),
dtype=np.unit8)
# ループ
ix = 0
iy = 0
for iy in range(img_small.shape[0]):
for ix in range(img_small.shape[1]):
level = int(img_small[iy, ix])
charbin = character_bins[level]
if len(charbin) == 0:
charbin = character_bins[level + 1]
if len(charbin) == 0:
charbin = character_bins[level - 1]
char = 255 - charbin[np.random.choice(np.arange(len(charbin)))]
new_img[iy*28:(iy+1)*28, ix*28:(ix+1)*28] = char
# カレントディレクトリに画像の保存
imsave('kuzushiji_matchan.jpg', new_img)
くずし字まっちゃん
上記、設定だと解像度も高いので、拡大するとくずし字がはっきりわかる。
