AirflowからDatabricksのjobを実行する
今回は、AirflowからDatabricksのJobを実行するやり方について、書いていきたいと思います。
AirflowにDatabricksのJobを組み込むことで、いろんな形でETLなり分析なり、ばっちなり回せると思うので結構便利かと思います。
手順の流れ
- Databricksにjobとtokenを準備しておく
- AirflowにDatabricksのproviderをセット
- dagファイルを配置
- DatabricksのJobを呼び出し
といった感じなります。
DatabricksにJobとTokenを用意する
すでに、jobとTokenを発行されてるのであれば、こちらの手順はskipでOKです。
Jobの作成
Notebookで単純なprintのみのnotebookを用意します。
submit(新規用のjob)とrunnow(既存job)で使う2つのnotebookを作成します。
print("this job is run now")
Job画面からCreate Jobを選択して、新しいJobをこんな感じで作成します。
Notebookはrunnowで作成したやつを指定します。
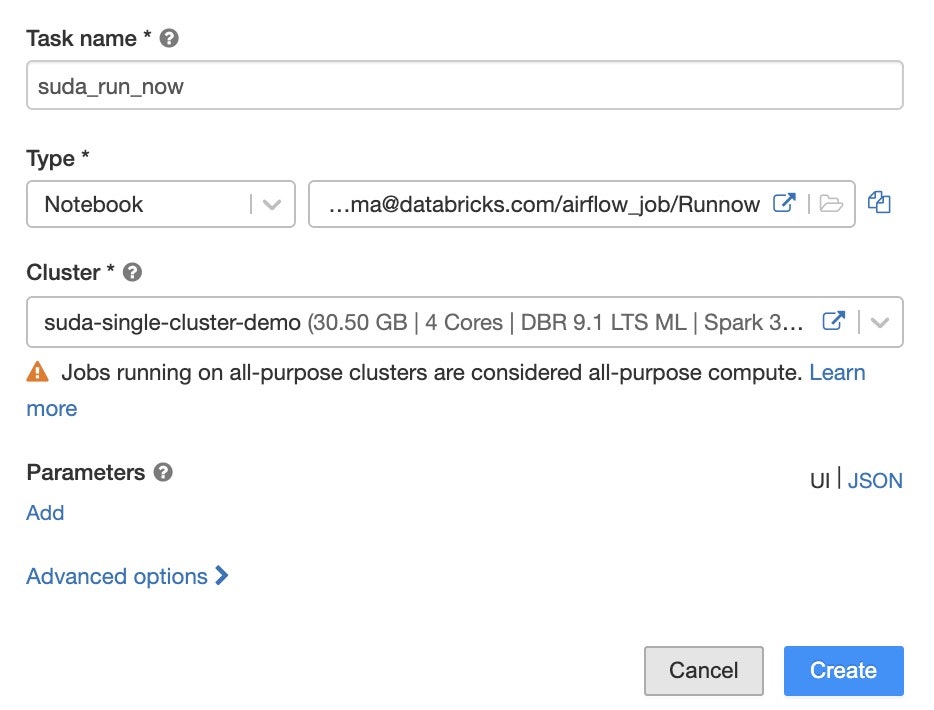
作成し終わったら、対象jobのIDだけメモしておきます。
tokenの発行
Databricksの左下にあるSetting -> User Settings -> Access Tokensから、Generate New Tokenをクリックして
Tokenを生成します。これもメモしておきます。
AirflowにDatabricksのprovideをセット
Airflowにsshでログインして、pipでdatabricks providerをinstallします。
https://airflow.apache.org/docs/apache-airflow-providers-databricks/stable/index.html
pip install apache-airflow-providers-databricks
installが終わったら、Admin -> provider にdatabricksがあることを確認します。
Admin -> Connectionsから+ボタンをクリックして、Databricks用のConnectionを作成します。
Connection id : 任意の名前
Host : DatabricksのWorkspace URL
Extra : {"token":"さっき発行したtoken"}
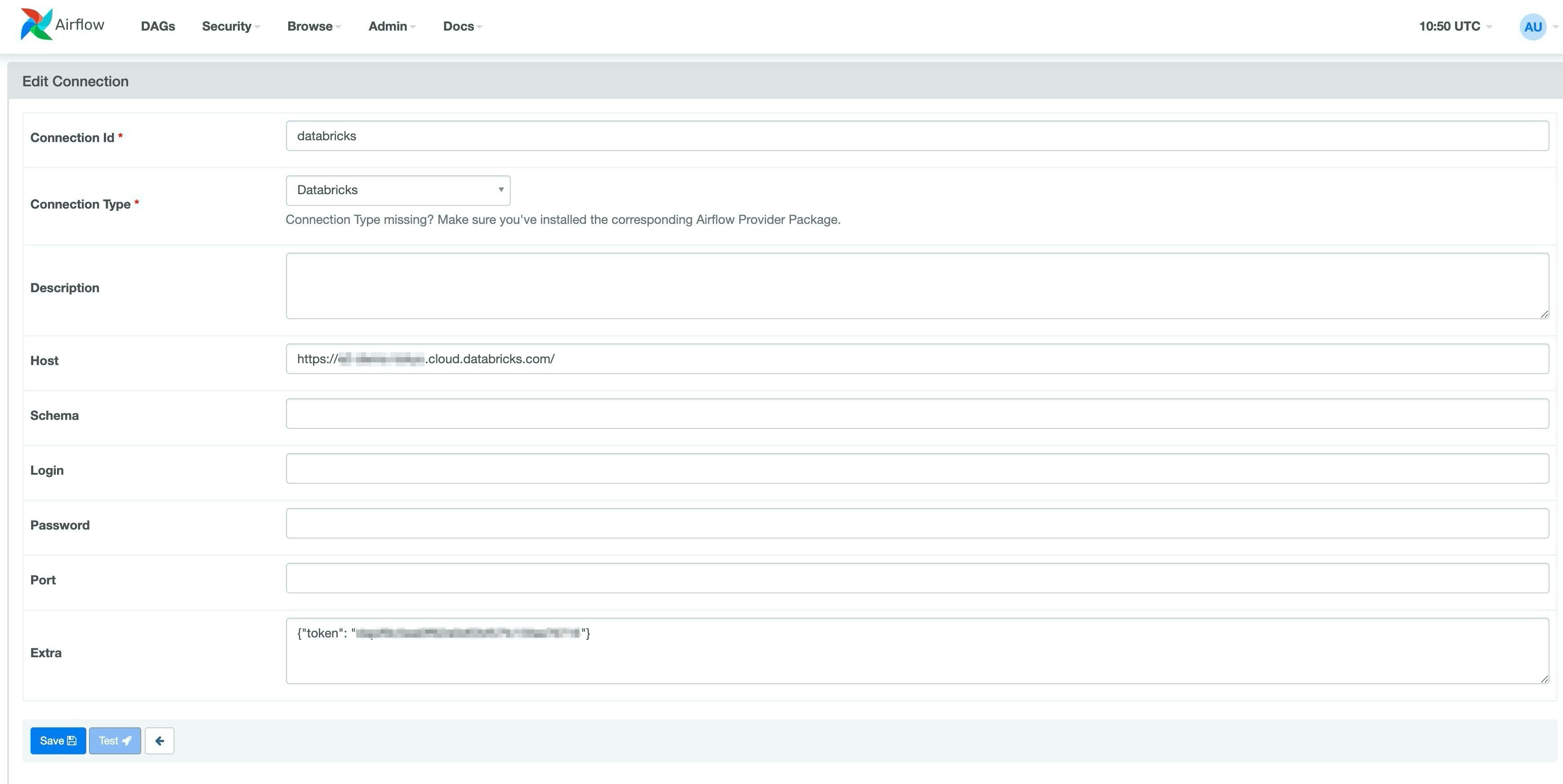
これで、Databricksの接続はいけるかと思います。
dagファイル配置
databricksのjobを実行するためのdagを配置します。
airflowのproviderで用意されてるClassesは2種類あって
| DatabricksSubmitRunOperator | 新規のjob実行 |
|---|---|
| DatabricksRunNowOperator | 既存のjobを実行 |
の2種類用意されているようです。なので今回は
- clusterを立ち上げて実行
- 既存Jobを実行
- DatabricksRunNowOperatorのjobidに先ほどメモした既存のjobidをセットしてください。
の2パターンをやってみます。
from airflow import DAG
from airflow.providers.databricks.operators.databricks import DatabricksSubmitRunOperator, DatabricksRunNowOperator
from datetime import datetime, timedelta
# Define params for Submit Run Operator
new_cluster = {
'spark_version': '9.1.x-scala2.12',
'num_workers': 2,
'node_type_id': 'i3.xlarge',
}
notebook_task = {
'notebook_path': '/Users/ユーザ名/airflow_job/Submitrun',
}
# Define params for Run Now Operator
notebook_params = {
"Variable":5
}
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=2)
}
with DAG('databricks_dag',
start_date=datetime(2021, 1, 1),
schedule_interval='@daily',
catchup=False,
default_args=default_args
) as dag:
opr_submit_run = DatabricksSubmitRunOperator(
task_id='submit_run',
databricks_conn_id='databricks',
new_cluster=new_cluster,
notebook_task=notebook_task
)
opr_run_now = DatabricksRunNowOperator(
task_id='run_now',
databricks_conn_id='databricks',
job_id=11257,
notebook_params=notebook_params
)
opr_submit_run >> opr_run_now
DatabricksのJobを呼び出し
ここまできたら、あとは実行のみです。
AirflowのJobから実行すると、こんな感じで完了します。
分かりづらいですが、一番右のJobです。
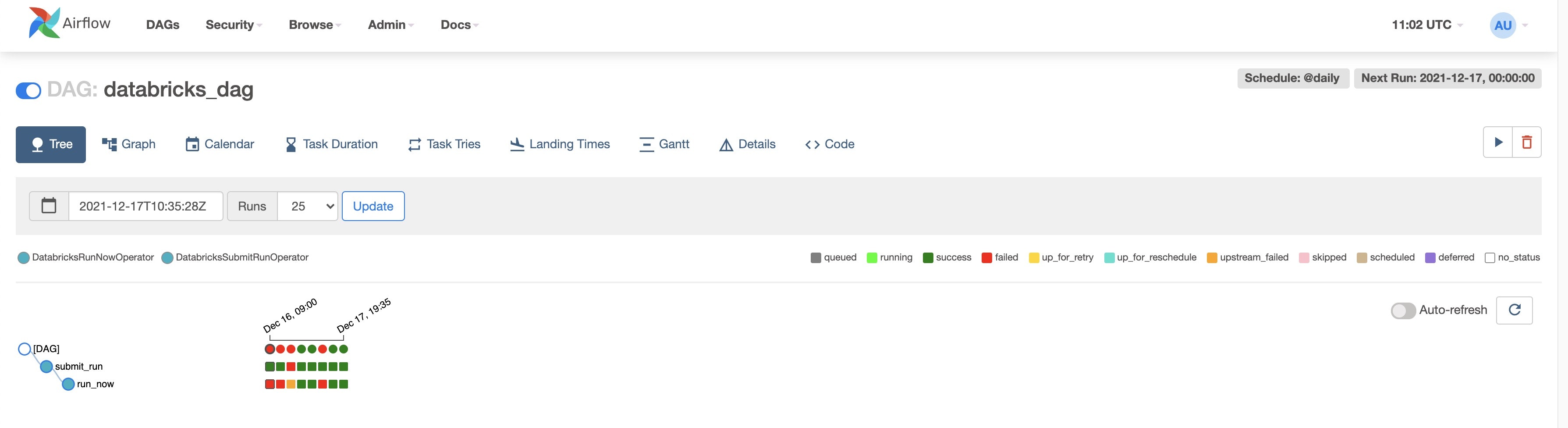
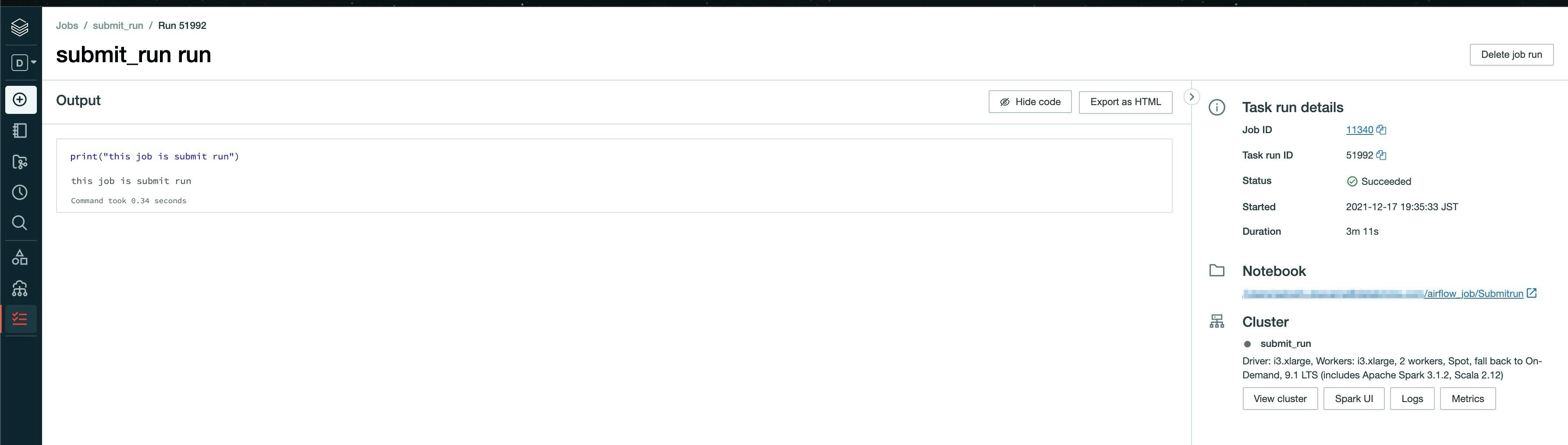
DatabricksSubmitRunOperatorで実行したしたJobはこんな感じで実行されています。
新規でclusterが作成されて、Jobが実行されてます。
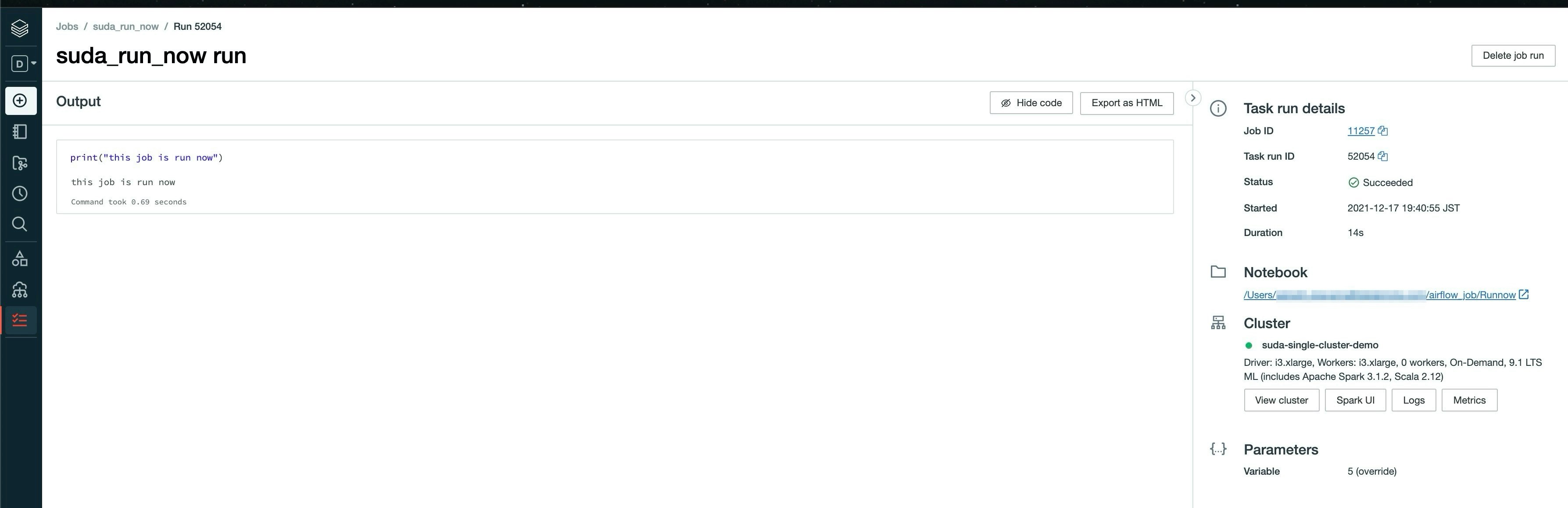
DatabricksRunNowOperatorで実行したJobはこんな感じです。
既存のJobで指定したclusterで実行されてます。
こんな感じで簡単にjobを実行できるので、databrickとairflowをお使いの方はためしてみてください!