はじめに
アウトプットのネタに困ったらこれ!?Ruby初心者向けのプログラミング問題を集めてみた(全10問)
の問題を解いてみました。(後編)
問題は以下の通りです。
この記事では6〜10まで解いています。
1〜5を解いた前編はこちら
- カレンダー作成問題
- カラオケマシン問題
- ビンゴカード作成問題
- ボーナスドリンク問題
- 電話帳作成問題
- 国民の祝日.csv パースプログラム
- 「Rubyで英語記事に含まれてる英単語を数えて出現数順にソートする」問題
- 行単位、列単位で合計値を求めるプログラム
- ガラケー文字入力問題
- 値札分割問題
6. 国民の祝日.csv パースプログラム
記事より引用。
その昔、「国民の祝日.csv」という扱いづらいCSVが話題になっていました。
具体的にはこんなCSVファイルです↓
平成28年(2016年),,平成29年(2017年),,平成30年(2018年),
名称,月日,名称,月日,名称,月日
元日,2016/1/1,元日,2017/1/1,元日,2018/1/1
成人の日,2016/1/11,成人の日,2017/1/9,成人の日,2018/1/8
建国記念の日,2016/2/11,建国記念の日,2017/2/11,建国記念の日,2018/2/11
春分の日,2016/3/20,春分の日,2017/3/20,春分の日,2018/3/21
昭和の日,2016/4/29,昭和の日,2017/4/29,昭和の日,2018/4/29
憲法記念日,2016/5/3,憲法記念日,2017/5/3,憲法記念日,2018/5/3
みどりの日,2016/5/4,みどりの日,2017/5/4,みどりの日,2018/5/4
こどもの日,2016/5/5,こどもの日,2017/5/5,こどもの日,2018/5/5
海の日,2016/7/18,海の日,2017/7/17,海の日,2018/7/16
山の日,2016/8/11,山の日,2017/8/11,山の日,2018/8/11
敬老の日,2016/9/19,敬老の日,2017/9/18,敬老の日,2018/9/17
秋分の日,2016/9/22,秋分の日,2017/9/23,秋分の日,2018/9/23
体育の日,2016/10/10,体育の日,2017/10/9,体育の日,2018/10/8
文化の日,2016/11/3,文化の日,2017/11/3,文化の日,2018/11/3
勤労感謝の日,2016/11/23,勤労感謝の日,2017/11/23,勤労感謝の日,2018/11/23
天皇誕生日,2016/12/23,天皇誕生日,2017/12/23,天皇誕生日,2018/12/23
,,,,,
月日は表示するアプリケーションによって形式が異なる場合があります。,,,,,
(中略)
> これをいい感じにパースして、以下のようなデータ構造(Rubyのハッシュオブジェクト)に変換しよう、というプログラミング問題です。
>
```ruby:
{
2016 => {
# 実際のキーは文字列ではなくDateオブジェクト
'2016/01/01' => '元日',
'2016/01/11' => '成人の日',
# ...
'2016/11/23' => '勤労感謝の日',
'2016/12/23' => '天皇誕生日',
},
2017 => {
'2017/01/01' => '元日',
'2017/01/09' => '成人の日',
# ...
'2017/11/23' => '勤労感謝の日',
'2017/12/23' => '天皇誕生日',
},
2018 => {
'2018/01/01' => '元日',
'2018/01/08' => '成人の日',
# ...
'2018/11/23' => '勤労感謝の日',
'2018/12/23' => '天皇誕生日',
},
}
作成したコード
class ParseSyukujitsu
def self.parse
syukujitsu = CSV.read("./syukujitsu.csv") # syukujitsu.csvを読み込んで配列に格納
parsed_syukujitsu = {} # パース後の祝日一覧を格納するハッシュ
syukujitsu[0].join.scan(/\d{4}/).map(&:to_i).each do |year| # キーが西暦のハッシュを作成しておく
parsed_syukujitsu[year]={}
end
2.upto(syukujitsu.size-1) do |line_count| # 3行目から末尾まで一行ずつ処理
break unless holiday=syukujitsu[line_count][0] # 祝日名を取得し、nilの場合は終了
syukujitsu[line_count].each_slice(2).map(&:last).each do |str_date| # 祝日の日付を取り出す
year=str_date[/\d{4}/].to_i
date=Date.parse(str_date)
parsed_syukujitsu[year][date]=holiday # 日付と祝日名の対応をハッシュに追加
end
end
return parsed_syukujitsu
end
end
CSV.read("./syukujitsu.csv")でCSVファイル全体を読み込んで、行ごとに配列に格納しています。
CSVの一行目の情報を基に、{2016=>{}, 2017=>{}, 2018=>{}}のようなキーが西暦のハッシュを作成しておき、行ごとに祝日名と日付を読み込んで、対応するハッシュに追加していっています。
7. 「Rubyで英語記事に含まれてる英単語を数えて出現数順にソートする」問題
問題:「Rubyで英語記事に含まれてる英単語を数えて出現数順にソートする」をカッコよく書いてみた
テストコード:[https://github.com/JunichiIto/extract-word-sandbox/tree/master/test]
(https://github.com/JunichiIto/extract-word-sandbox/tree/master/test)
テキストファイルの中から英熟語や英単語を抜き出してカウントする、という問題です。
入力に使うテキストファイルはこんな感じです。
Interior design and decorating resource Houzz is the overall best Android app of the year, according to Google, which this evening announced the results of the first-ever Google Play Awards at its developer conference, Google I/O.
(略)
出力結果はこんな感じになります。
単語数(熟語以外):331
英熟語?------------------------------------------------------------------
2 Google I/O
2 Google Play Awards
1 And Google
1 Best App
1 Best Game
1 Best of
1 Best Standout Startup
1 Best Use of Google Play Game Services
1 Best Use of Material Design
(略)
英単語------------------------------------------------------------------
22 the
11 and
11 of
8 a
6 apps
5 app
5 best
5 for
5 Google
5 to
4 that
4 this
(略)
作成したコード
class ExtractWord
def self.execute(input_file_path)
ew=ExtractWord.new
ew.execute(input_file_path)
end
def execute(input_file_path)
text = File.read(input_file_path) # テキストファイルを読み込んで、中身を格納
idioms_and_words = extract_iw(text) # 文字列内から英熟語と英単語を抽出する
idiom_count,word_count= count_iw(idioms_and_words) # 英熟語の数と英単語の数を数える
summarize_result(idiom_count,word_count) # 結果をまとめる
end
def extract_iw(text)
words = text.scan(/[A-Z][\w’\/]*(?:\s(?:[A-Z][\w’\/]*|of))+|[\w’-]+/) # 英熟語を優先して抽出
end
def count_iw(idioms_and_words)
idiom_count = Hash.new(0) # キーが英熟語で、値が出現回数のハッシュを作る
word_count = Hash.new(0) # キーが英単語で、値が出現回数のハッシュを作る
idioms_and_words.each do |iw|
if iw.include?(" ") # 文字列にスペースが含まれていたら、英熟語のカウントを増やす
idiom_count[iw]+=1
else
word_count[iw]+=1 # そうでなければ、英単語のカウントを増やす
end
end # カウントの多い順かつ辞書順にハッシュをソートして返す
return [idiom_count,word_count].map{|result| result.sort_by{|iw,count| [-count,iw.downcase]}}
end
def summarize_result(idiom_count,word_count)
result="単語数(熟語以外):#{word_count.inject(0){|cnt,ar| cnt+ar[1]}}\n英熟語?------------------------------------------------------------------\n"
idiom_count.each do |idiom,count|
result += "#{"%3d" % count} #{idiom}\n"
end
result+="英単語------------------------------------------------------------------\n"
word_count.each do |word,count|
result += "#{"%3d" % count} #{word}\n"
end
return result.chomp
end
end
正規表現/[A-Z][\w’\/]*(?:\s(?:[A-Z][\w’\/]*|of))+|[\w’-]+/によって、テキスト内に現れる英熟語と英単語を、英熟語を優先して抽出しています。
抽出後に、英熟語と英単語に分けてハッシュを作成し、出現回数をカウントします。
最後に、カウントの多い順かつ辞書順にソートして出力しています。
8. 行単位、列単位で合計値を求めるプログラム
問題:「Ruby力向上のための基礎トレーニング」をテストコード付きで解いてみた
問題の参照先を見ると、元々はAizu Online Judgeのこの問題を参考に作られた問題のようだったので、そちらの仕様に合わせて解きました。
Aizu Online Judgeからの引用
以下の表のように、与えられた表の縦・横の値の合計を、それぞれの行・列で求め出力するプログラムを作成してください。ただし、縦・横のデータ数は 10 以下とし、それぞれの数字は 100 以下の整数とします。 出力は右詰め 5 桁で出力してください。
Input
複数のデータセットが与えられます。各データセットは以下の形式で与えられます。
$n$
$a_{1,1}\ a_{1,2}...\ a_{1,n}$
$a_{2,1}\ a_{2,2}...\ a_{2,n}$
:
$a_{n,1}\ a_{n,2}...\ a_{n,n}$
$n$ は縦・横のデータ数、$a_{i,j}$ は表の $i$ 行 $j$ 列目の値(整数)を表します。
$n$ が 0 のとき入力の終わりを示します。データセットの数は 50 を超えません。
Output
各データセットについて、入力データに縦と横の合計のデータを付加した表(半角右詰め 5 桁)を出力してください。
Sample Input
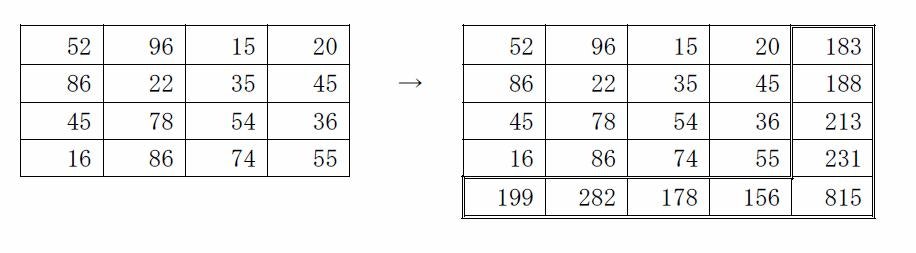
4
52 96 15 20
86 22 35 45
45 78 54 36
16 86 74 55
4
52 96 15 20
86 22 35 45
45 78 54 36
16 86 74 55
0
>**Output for the Sample Input**
>```
52 96 15 20 183
86 22 35 45 188
45 78 54 36 213
16 86 74 55 231
199 282 178 156 815
52 96 15 20 183
86 22 35 45 188
45 78 54 36 213
16 86 74 55 231
199 282 178 156 815
作成したコード
class MatrixLikeComputation
def execute
matrix=calculate_matrix_total(gets.to_i) # 答えの行列を表す文字列
end
def calculate_matrix_total(n)
return "" if n==0 # n=0のときは、空文字列を結合して終了する
ans_matrix= ""
rows = n.times.map{gets.split.map(&:to_i)} # 行ごとに数値を配列に格納
rows.each do |row|
ans_matrix += (row << row.sum).map{|i| "%5d" % i}.join + "\n" # 数値と合計値を結合した文字列を作成し、結合
end
column_sums = n.times.map{|i| rows.inject(0){|column_sum,row| column_sum+row[i]}} # 列ごとの合計を配列に格納
# 列ごとの合計値を行列の末尾に追加し、次の行列を結合
ans_matrix += (column_sums << column_sums.sum).map{|i| "%5d" % i}.join + "\n" + calculate_matrix_total(gets.to_i)
end
end
mlc = MatrixLikeComputation.new
puts mlc.execute
n=0を受け取るまで、再帰的に答えの文字列を結合させています。
各行では、その行の数値を入れた配列rowの末尾に合計値を追加し、rowの要素を結合して文字列にしました。
最終行については、まず列ごとの合計を格納した配列column_sumsを畳み込みで作成し、同様に結合して文字列にしています。
9. ガラケー文字入力問題
こちらもAOJの問題。
ガラケーでの文字入力では、2のボタンを押すごとにa→b→c→a→b...と文字が変化していきます。
数字列が与えられるので、その通りにボタンを押したときの文字列を出力するという問題です。
ただし以下の2つの制約があります。
① 0を確定ボタンとし、1文字の入力が終わったら必ず確定ボタンを押すこと
② 何もボタンが押されていないときに確定ボタンを押すことはできるが、その場合には何も文字は出力されないこと
数字ボタンと文字の対応は以下の通りです。
1: . , ! ? (スペース)
2: a b c
3: d e f
4: g h i
5: j k l
6: m n o
7: p q r s
8: t u v
9: w x y z
0: 確定ボタン
入力と出力、およびサンプルは以下の通りです(問題ページより引用)。
Input
最初の行にテストケースの数が与えられる。 続いて各テストケースについて、最大で長さ 1024 の数字列が1行で与えられる。
Output
Alice さんが作ったメッセージの文字列をそれぞれのテストケースについて 1 行ごとに出力せよ。 ただし、出力は 1 文字以上 76 文字未満であると仮定してよい。
Sample Input
5
20
220
222220
44033055505550666011011111090666077705550301110
000555555550000330000444000080000200004440000
Output for the Sample Input
a
b
b
hello, world!
keitai
作成したコード
class KeitaiMessage
@@button = { # 数字と文字の対応をハッシュで持っておく
'1' => ['.',',','!','?',' '],
'2' => [*'a'..'c'],
'3' => [*'d'..'f'],
'4' => [*'g'..'i'],
'5' => [*'j'..'l'],
'6' => [*'m'..'o'],
'7' => [*'p'..'s'],
'8' => [*'t'..'v'],
'9' => [*'w'..'z'],
'0' => ['']
}
def execute
output=number2string(gets.to_i) # 数字列を文字列に変換し、結合して返す
end
def number2string(n)
output='' # n行分の文字列を格納
n.times do
input_numbers=gets.chomp.chars # 数字列を受け取って配列に格納
line='' # 1行分の文字列を格納
push_count=0 # ボタンを押した回数をカウント
prev_number='0' # 一つ前に押された数字を持っておく
input_numbers.each do |input_number|
if input_number=='0' # 0が押されたら文字を確定
array_size = @@button[prev_number].size
line+=@@button[prev_number][(push_count-1)%array_size] # 数字列を文字に変換して末尾に追加
push_count=0
else
push_count+=1 # 0以外が押されたときは、押した回数を数える
end
prev_number=input_number # 一つ前に押された数字を更新
end
output+=line+"\n" # 1行ずつoutputに追加
end
return output
end
end
km=KeitaiMessage.new
puts km.execute
一つ前に押された数字をprev_numberで持っておき、0が押されるまで、その数字を押した回数をpush_countで数えておきます。
0が押されたときは、prev_numberと、push_countから文字に変換します。
変換の際には、push_countを配列の長さで割った余りを計算することで、"222220"→"b"のように循環するものも正しく変換できるようにしています。
10. 値札分割問題
問題:【Rubyプログラミング問題】値札分割メソッド(split_price)を作成してください
ユーザーが自由に入力できる値札データがある。
このデータ(文字列)を以下のようなルールで分割するメソッド、 split_price を作成せよ。
'110.0万円' => ['110.0', '万円']
'2015円' => ['2015', '円']
'1,123,456円' => ['1,123,456', '円']
'110 - 120万円' => ['110 - 120', '万円']
'2015円' => ['2015', '円']
'価格未定' => ['価格未定', '']
nil => ['', '']
作成したコード
def split_price(price_text)
s = /^(.*?)(万?円|)$/.match(price_text.to_s)
[s[1],s[2]]
end
^(.*?)(万?円|)$という正規表現とマッチさせています。
1番目のキャプチャは任意の文字列との最短マッチ、2番目のキャプチャは(万)円もしくは空文字列とのマッチです。
入力に(万)円が含まれる際には、(万)円が2番目にキャプチャされ、(万)円より前方が、1番目にキャプチャされます。
入力に(万)円が含まれない場合は、空文字列が2番目にキャプチャされ、文字列全体は、1番目にキャプチャされます。
nilについては、マッチする前に入力をto_sで空文字列に変換しておくことによって、マッチした結果がnilになることを防いでいます。
おわりに
Ruby初心者向けのプログラミング問題10問のうち、後半の5問を解いてみました。リファクタリングできる場所やアドバイス等ございましたら、コメントをいただければ幸いです。
綺麗なコードを書いてる人はmapやinjectを上手く使ってるイメージがあるので、習得したいですね。
また、正規表現で思い通りにマッチさせることができず苦労したので、こちらも精進します。