はじめに
AidemyのAIアプリ開発口座の課題で、キノコ判定の画像アプリを作成しました。
去年から山登りを始めたのですが、山に行くようになって初めて
キノコや野草の毒を注意する看板に気づきました。
山登りする人が、毒と食べられるものを判定できたらいいな、とつくってみることにしました。
今回は、野草よりもキノコ狩りの人口の方が多そうなので、
キノコの判定にしました。
実行環境
Goole Coraboratory
Visual Studio Code
データ収集
まずはキノコの画像収集です。キノコのオープンデータセットも
公開されていたのですが、海外のものしか見当たらず、
日本のキノコに特化した方が実用度が高い(自分にとってですが)ので、Google画像検索から収集することにしました。
データを地域で絞る
でも、キノコといっても膨大な種類がありすぎてどの基準で選べばよいのか迷います・・
そこで、はじめに地域を絞ってみることにしました。
関東近辺の山々を想定し「関東 きのこ」で検索すると、
栃木の山登りサークルの方のブログがヒットするだけです。
関東と限定してもきのこの種類を特定することはできなさそうです。
データを種類で絞る
そこで、次に種類を絞ってみることにしました。
「毒きのこ」で検索すると、厚生労働省HPがヒットしますが
食べられるきのこの情報がありません。道のりは遠い…

毒きのこと食べられるきのこ、両方がわかるのは
図鑑しかない!ということできのこの図鑑を探しました。
今回使ったのは「日本のキノコ新訂275」というものです。

この本を選んだ決め手は、
①まず、きのこの発生場所や形状の種類などが体系的にガイドされているのです。柄の表面の観察、、この本を読まないと知ることなかったです。
②著者が写真家なので、ひだや柄まで部位ごとの写真があります。画像認識に最適!というということで決めました。
本を読むうち、きのこが生息する違いは、木の種類や環境によることがわかったので、地域で区切るのは難しそうです。
そこで、似た種類で見分けることを想定し、きのこの種類(科)で絞ってみることにしました。
選んだのは、食べられるきのこと毒きのこが両方あるキシメジ科という種類です。
対象
●毒きのこ カキシメジ、ドクササコ、ネズミシメジ、ヒョウモンクロシメジ(プラスして、キシメジ科ではありませんが猛毒のベニテングタケも含めました)
●食べられるきのこ オオイチョウタケ、カヤタケ、シモフリシメジ、マツタケ、ムラサキシメジ
データの抽出
ScrapingでWebページから必要な画像を抽出します。
htps://qiita.com/nkbk2525/items/9b6b254eedd311c1f932
まずは必要ライブラリのインポートをします。
import requests
from bs4 import BeautifulSoup
#Seleniumの準備
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
!pip install selenium
from selenium import webdriver
#WebブラウザをUIなしで扱うための設定
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver',options=options)
driver.implicitly_wait(10)
次に、きのこの名前でGoogle検索した時の画像を取得します。
#Google画像検索のURLを準備
query = "ムラサキシメジ"
#query = "Lepista nuda"
url = "https://www.google.com/search?q={}&hl=ja&tbm=isch".format(query)
url
#すべての要素が読み込まれるまで待つ
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# すべての要素が読み込まれるまで待つ。タイムアウトは15秒。
WebDriverWait(driver, 15).until(EC.presence_of_all_elements_located)
#BeautifulSoupでHTML解析
driver.get(url)
html = driver.page_source.encode("utf-8")
soup = BeautifulSoup(html, "html.parser")
soup
#imgタグを検索
soup.find_all("img")
#imgタグのリストを変数に代入
img_tags = soup.find_all("img")
#imgタグの数を出力
len(img_tags)
#画像を抜き出す
img_urls = []
for img_tag in img_tags:
url = img_tag.get("src")
if url is None:
url = img_tag.get("data-src")
if url is not None:
img_urls.append(url)
print(url)
データの格納
取得した画像を、GoogleDrive上のフォルダに格納していきます。
#画像をダウンロード
def download_image(url, file_path):
r = requests.get(url, stream=True)
if r.status_code == 200:
with open(file_path, "wb") as f:
f.write(r.content)
#Base64をデコードして画像に戻す
import base64
def save_base64_image(data, file_path):
# base64の読み込みは4文字ごとに行う。4文字で区切れない部分は「=」で補う
data = data + '=' * (-len(data) % 4)
img = base64.b64decode(data.encode())
with open(file_path, "wb") as f:
f.write(img)
print(f)
#Google Driveに画像を保存
import os
import re
# 任意のディレクトリパスを指定(GoogleDrive上)
save_dir = "/content/drive/My Drive/Python/食きのこ/ムラサキシメジ"
os.makedirs(save_dir, exist_ok=True)
base64_string = "data:image/jpeg;base64,"
# png画像も対象にする
png_base64_string = "data:image/png;base64,"
for index, url in enumerate(img_urls):
# enumerateを使えばリストのindexを取得できます。このindexをそのままファイル名にします
# formatを使えば文字列内の指定した場所に変数の内容を入れることができます
file_name = "{}.jpg".format(index)
# os.path.joinを使えば引数に指定した文字列をパスの形に繋げる(joinする)ことができる
image_path = os.path.join(save_dir, file_name)
if len(re.findall(base64_string, url)) > 0 or len(re.findall(png_base64_string, url)) > 0:
url = url.replace(base64_string, "")
url = url.replace(png_base64_string, "")
save_base64_image(data=url, file_path=image_path)
else:
download_image(url=url, file_path=image_path)
大まかにですが、一種類のきのこあたり120枚程度の画像が取得できました。
工夫した点
次ステップの通り、データを間引くと1きのこあたり80枚程度まで
データ数が減ってしまいます。
そこで、検索キーワードで日本語だけでなくきのこの英文名を調べ、
英文でも画像収集をしています。
(ムラサキシメジの場合、Lepist nudaというそうです)
#query = "Lepista nuda"
画像の処理
Webから画像を取得すると、不要なデータが混ざってしまいます。
今回は、きのこのマスコットやイラストが入ってしまったので
一枚ずつ確認し、手作業で削除していきました。
処理した結果、データ数はそれぞれ500枚前後となりました。
食べられるキノコ471枚 毒きのこ517枚
画像の水増し
AIのデータは一般的には1000枚以上必要と言われます。
まだまだデータ数が少ないので、訓練データの画像の水増しを行いました。
#データを読み込み
import glob
import cv2
#データ水増し
import os
import cv2
import numpy as np
def scratch_image(img, flip=True, blur=True, rotate=True):
methods = [flip, blur, rotate]
# filp は画像上下反転
# blur はぼかし
# rotate は画像回転
#画像のサイズ(x, y)
size = np.array([img.shape[1], img.shape[0]])
# 画像の中心位置(x, y)
center = tuple([int(size[0]/2), int(size[1]/2)])
# 回転させる角度
angle = 30
# 拡大倍率
scale = 1.0
mat = cv2.getRotationMatrix2D(center, angle, scale)
# 画像処理をする手法をNumpy配列に格納
scratch = np.array([
lambda x: cv2.flip(x, 0), # flip
lambda x: cv2.GaussianBlur(x, (15, 15), 0), # blur
lambda x: cv2.warpAffine(x, mat, img.shape[::-1][1:3]) # rotate
])
# imagesにオリジナルの画像を配列として格納
images = [img]
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
def doubling_images(func, images):
return images + [func(i) for i in images]
for func in scratch[methods]:
images = doubling_images(func, images)
return images
画像を訓練データとテストデータに分割
水増ししたデータを、教師データとテストデータに分けて
Google Drive上のフォルダに保存していきます。
先にGoogle Drive上にフォルダを作成しておきます。

#train_imagesディレクトリに保存
# faceディレクトリにあるキノコの画像を拡張する
IMAGE_DIR = '/content/drive/MyDrive/Python'
mushrooms = ["data_eatablemushroom", "data_poisonmushroom"]
# for m in mushrooms:
# files = glob.glob(os.path.join(IMAGE_DIR, m + "/*.jpg"))
# file_number = len(files) #画像の枚数
# train = int(0.8*file_number)
# test = file_number-train
# #拡張した画像を出力するディレクトリを作成
# os.makedirs("/content/drive/MyDrive/Python/train_images/{}".format(m), exist_ok=True)
# train_dir = "/content/drive/MyDrive/Python/train_images/{}".format(m)
# os.makedirs("/content/drive/MyDrive/Python/test_images/{}".format(m), exist_ok=True)
# test_dir = "/content/drive/MyDrive/Python/test_images/{}".format(m)
# for index, file in enumerate(files):
# mushroom_image = cv2.imread(file)
# if index <= train:
# data_aug_list = scratch_image(mushroom_image) #データ水増し
# #保存
# for j, img in enumerate(data_aug_list):
# cv2.imwrite("{}/{}_{}.jpg".format(train_dir, str(index).zfill(3), str(j).zfill(2)), img)
# else:
# cv2.imwrite("{}/{}.jpg".format(test_dir, str(index).zfill(3)), mushroom_image)
モデル学習
データの準備ができたので、機械学習モデルを定義し、学習します。
今回はAidemyのAIアプリ開発講座で学んだVGG16というCNNモデルを用います。
全16の畳み込み層から1000クラスを学習したCNNモデルです。
ライブラリのインポート
まずは必要なライブラリをインポートします。
#モデルの定義と学習
#CNNモデル ライブラリインポート
import os, glob
import random
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import Input, Sequential, Model
from tensorflow.keras.models import load_model, save_model
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.optimizers import SGD, Adam
IMAGE_DIR_TRAIN = "/content/drive/MyDrive/Python/train_images/"
IMAGE_DIR_TEST = "/content/drive/MyDrive/Python/test_images"
訓練データとテストデータへ分ける
次に訓練データとテストデータとにデータを
分けていきます。
# 訓練データとテストデータをわける
X_train = []
X_test = []
y_train = []
y_test = []
image_size = 224
# 訓練データをリストに代入
for index, m in enumerate(mushrooms):
files = glob.glob(os.path.join(IMAGE_DIR_TRAIN, m + "/*.jpg"))
for file in files:
image = load_img(file)
image = image.resize((image_size, image_size))
image = img_to_array(image)
X_train.append(image)
y_train.append(index)
# テストデータをリストに代入
#mushrooms = ["data_eatablemushroom", "data_poisonmushroom"]
for index, m in enumerate(mushrooms):
files = glob.glob(os.path.join(IMAGE_DIR_TEST, m + "/*.jpg"))
for file in files:
image = load_img(file)
image = image.resize((image_size, image_size))
image = img_to_array(image)
X_test.append(image)
y_test.append(index)
# テストデータと訓練データをシャッフル
#p = list(zip(X_train, y_train))
#random.shuffle(p)
#X_train, y_train = zip(*p)
#q = list(zip(X_test, y_test))
#random.shuffle(q)
#X_test, y_test = zip(*q)
# Numpy配列に変換
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
# データの正規化
X_train = X_train / 255.0
X_test = X_test / 255.0
# One-hot表現
y_train = to_categorical(y_train, 2)
y_test = to_categorical(y_test, 2)
画像サイズはVGG16で用いる224です。
データの確認
実際にデータが格納されたか確認します。
訓練データに6320枚、テストデータに197枚が格納されていました。
AIでは訓練データ8割、テストデータ2割で
データを分けることが一般的ですが、
今回は訓練データのみ水増ししているので大幅に訓練データが多くなっています。

モデルの定義
Aidemyの講座で学んだコードを用いて、モデルを生成します。
# VGG16のインスタンスの生成
input_tensor = Input(shape=(224, 224, 3))
vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=input_tensor)
# モデルの定義
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation="relu"))
top_model.add(Dropout(0.5))
top_model.add(Dense(128, activation="relu"))
# top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation="softmax"))
# モデルの結合
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# model.summary()
# 15層目までのパラメータを固定
for layer in model.layers[:15]:
layer.trainable = False
# モデルのコンパイル
optimizer = SGD(lr=1e-4, momentum=0.9)
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"])
無事にモデルが生成できました。
CNN(畳み込みニューラルネットワーク)では、畳み込み層で画像の特徴を調べ、ブーリング層で畳み込み層から得た特徴を要約して分類します。

モデル学習
いよいよ、モデルを学習していきます。
画像判定アプリとして実装する為に、モデルを保存するコードも記入します。
# モデルの学習
batch_size = 32
epochs = 100
history = model.fit(X_train,
y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(X_test, y_test)
# callbacks=[early_stopping]
)
scores = model.evaluate(X_test, y_test, verbose=1)
# モデルの保存
model.save("./content/drive/MyDrive/Python/model.h5")
エポック数が100なので、モデルが収束するのに時間がかかります。
GPUモードでも1時間近くの時間がかかりました。
参考
ランタイムのタイプは、Goole ColaboratoryでGPUに変更しておくと処理時間が短縮できます。
ランタイム>ランタイムのタイプを変更>ハードウェアアクセラレータ>GPU

モデルの結果をグラフで可視化します。
可視化
fig = plt.figure(figsize=(15,5))
plt.subplots_adjust(wspace=0.4, hspace=0.6)
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(history.history["accuracy"], c="b", label="acc")
ax1.plot(history.history["val_accuracy"], c="r", label="val_acc")
ax1.set_xlabel("epochs")
ax1.set_ylabel("accuracy")
plt.legend(loc="best")
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(history.history["loss"], c="b", label="loss")
ax2.plot(history.history["val_loss"], c="r", label="val_loss")
ax2.set_xlabel("epochs")
ax2.set_ylabel("loss")
plt.legend(loc="best")
fig.show()
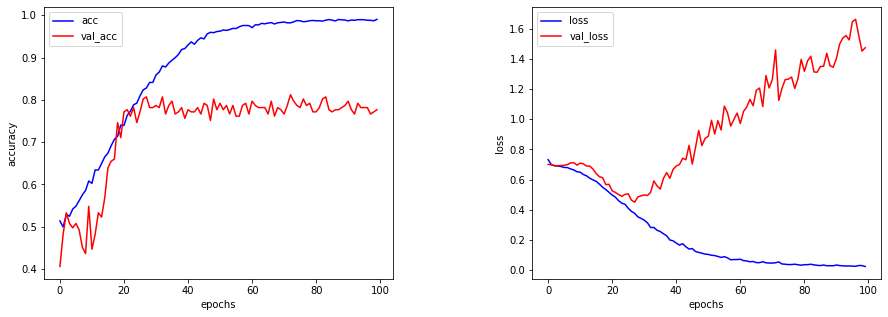
結果
モデル精度が0.77であまりよくありません。
また、エポック数30付近でLossが右肩上がりとなっている為、過学習が起きていることが
わかります。
lossは、損失化関数(交差エントロピー誤差)と呼ばれ、目標に対する実際の誤差なので
エポック数が多ければ多いほど乖離が出てしまっていることになります。
7/7 [==============================] - 1s 146ms/step - loss: 1.4735 - accuracy: 0.7766
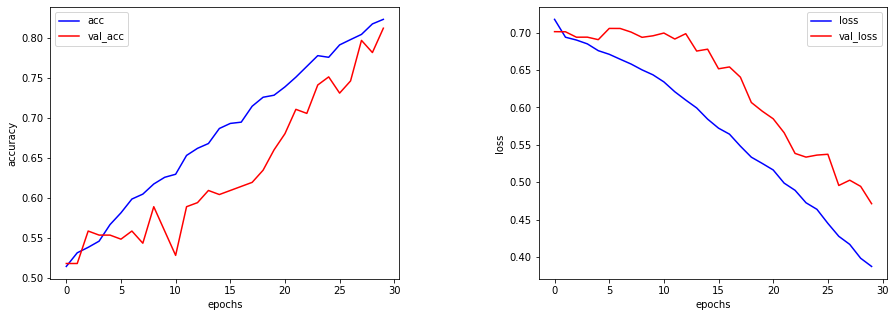
モデルの改善
モデルの精度を改良する為に、バッチ数を64に増やし、エポック数を30に減らしてみます。
モデル精度が0.81まで向上し、lossも改善しました。
# モデルの学習
batch_size = 64
epochs = 30
7/7 [==============================] - 4s 147ms/step - loss: 0.4712 - accuracy: 0.8122
きのこの判定
モデルが完成したので、いよいよテストデータできのこの判定をしてみます。
コードは、Aidemyの男女識別で学んだ分類に用いるものを参考にしました。
今回は、毒なし・毒ありの2分類なので、
「0:毒なし」「1:毒あり」としています。
GoogleDrive上のTestデータフォルダから5枚のデータを判定します。
# 画像を一枚受け取り、毒なしかありかを判定して返す関数
def pred_mushroom(img):
img = cv2.resize(img, (224,224))
pred = np.argmax(model.predict(img.reshape(1,224,224,3)))
if pred ==0:
return "毒なし"
else:
return "毒あり"
# 精度の評価(適切なモデル名に変えて、コメントアウトを外してください)
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
files = glob.glob("/content/drive/MyDrive/Python/trial_images/*.jpg")
for file in files[:5]:
img = cv2.imread(file)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
print(pred_mushroom(img))
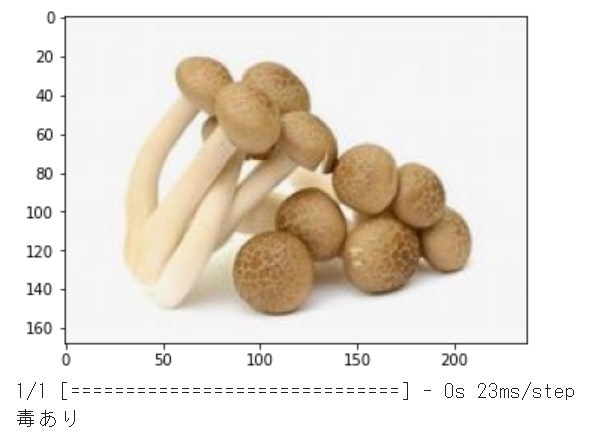
結果は、5枚中4枚正解ということで、まずまずとなりました。
まつたけ ○食べられるきのこです。

ムラサキシメジ ○食べられるきのこです。

ネズミシメジ ○毒きのこです。

カキシメジ ○毒きのこです。

しめじ ×しめじも試してみましたが、残念ながら毒きのこに判定されてしまいました。カキシメジと似ているせいかもしれません。
Webアプリの作成
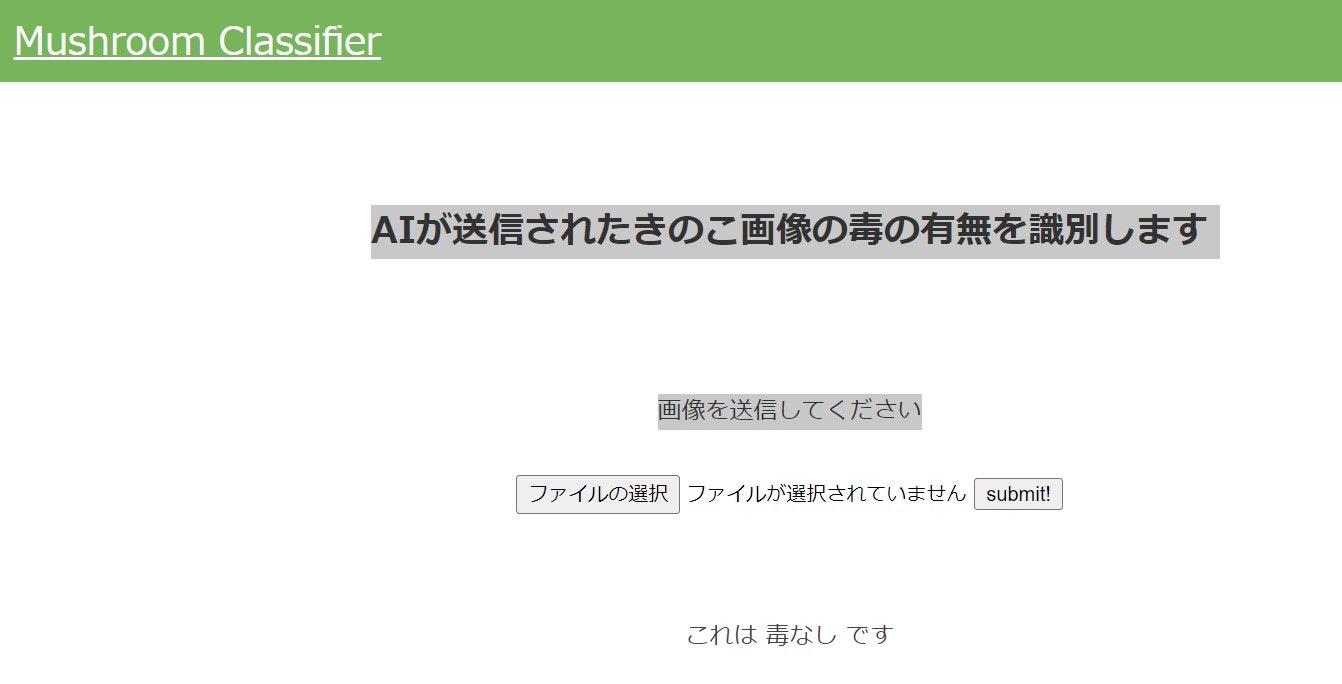
では、実際にWebアプリ画面上で画像判定をみてみます。
FlaskというPython上で動くウェブアプリケーションフレームワークで、実装していきます。アイデミーで習ったHTMLとCSSの設定を反映します。
「ファイルを選択」で、カキシメジの画像を設定し
「submit」を押すと…無事に毒なしと判定されました!
振り返り
今回精度が9割に満たなかったのは、
まず、データ数が少ないことです。どうしてもWeb検索から画像を検索すると元データの数が限られてしまいます。
また、今回は毒の有無で閾値が50%という前提でしたが、一概に毒きのこといっても見た目の特徴がばらばらで、
毒のありなしの中間に位置するきのこがあると考えられます。
今後の改善点としては、以下の工夫をしてみようと思います。
①VGG16以外の、他の様々な転移学習モデルも試してみる
②画像の水増しを色や形などきのこの特徴を捉えて試してみる
③画像編集(切り取り)できのこの背景を消すなど工夫する
④過学習を防ぐ為のコードを追記する
⑤閾値を見直す(例えば、毒キノコの閾値を80%とし閾値を超えない限り毒キノコとはしないなど)
おわりに
初めはきのこの種類が分かれば判定できると簡単に考えていましたが、
毒の有無は外見からは区別できなかったりと、画像認識の奥深さを知ることができました。
きのこの特徴を捉えるには専門家の知見が必要で、個人でトライするのは難しいですが、
実現できれば山登り愛好家のお役立ちになれるかも…!
初心者ですが、実用的なアプリ開発にこれからもトライします。