この記事は Microsoft Power BI Advent Calendar 2020 22 日目の記事です。
株式会社EBILAB のエンジニアのさぼ(@saboyutaka)です。EBILABでは提供するサービスの一部としてPowerBIを活用しています。今回はPowerBIを大規模に使うときに必要になってくるデータのチューニングについてまとめたので共有したいと思います。
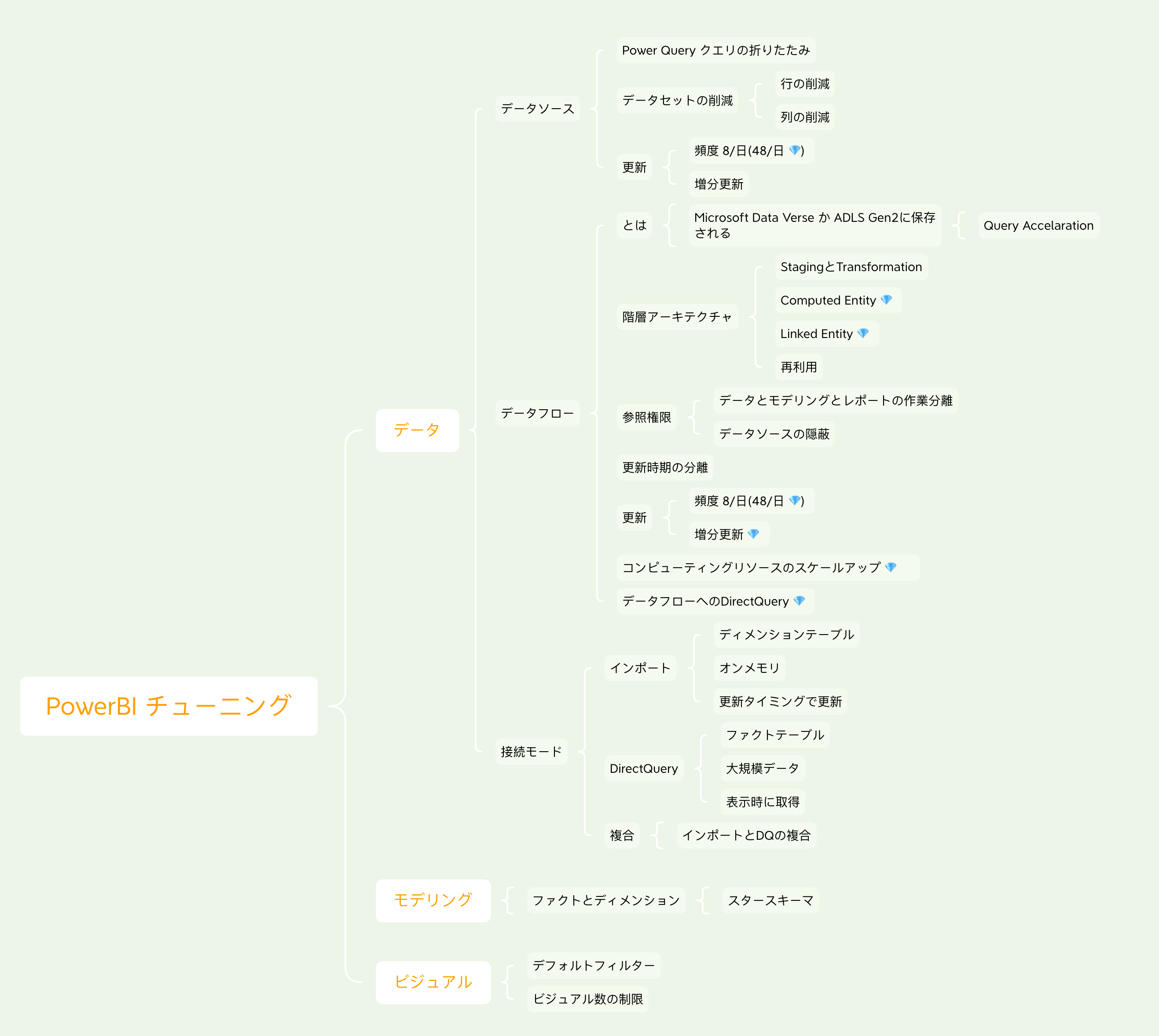
PowerBIを大規模で扱うときに出てくる課題
PowerBIをヘビーに使っていくことで時間経過とともに
- レポート数
- データ量
- テナント数
などが増加していきます。その結果、
- データソースへのアクセスの急増, I/Oの急増
- 似たようなデータへのアクセスによる無駄
- データセットの更新数が急増え, データ更新に時間がかかる
- PowerBI Serviceのコンピューティングリソースの利用が増える
などの問題が浮上してきます。
今回はそれらの問題に対し、PowerBIが用意している技術を調査した内容をまとめました。
前置き
PowerBI とは
Power BI はソフトウェア サービス、アプリ、コネクタのコレクションで、これらを組み合わせることで、関連性のないデータ ソースから、まとまりがあり、実体験的な対話型洞察を得ることができます。 Excel スプレッドシートや、クラウド ベースとオンプレミスのハイブリッド データ ウェアハウスのコレクションなど、さまざまなデータを使えます。 Power BI を使うと、ご利用のデータ ソースへの接続、重要事項の視覚化と検出、必要に応じた任意のユーザーまたはすべてのユーザーとの共有を、簡単に実行できます。
端的に言うと、PowerBIはMicrosoftが提供するBI(Business Inteligence)ツールです。様々なデータソース(エクセルやCSV, データベース)などからデータを収集し、加工し、レポートを作成することが出来ます。PowerBIは主に、PowerBI DesktopとPowerBI Serviceがあります。簡易的に説明すると、PowerBI Desktopを使ってデスクトップ上でレポート作成し、PowerBI Service(SaaS)に公開することでレポートを共有します。
PowerBI レポート
PowerBIで作成するレポートには主に3つの機能があります。
- データセット: 様々なデータソースからデータを取得し加工し、最終的に複数の2次元テーブルを作成する。ETL機能。
- モデリング: データセットで作成したテーブルのリレーション(関連)を作成する
- ビジュアル: レポートを描画するための機能、モデリングされたテーブルを利用する
PowerBI Premium
今回は大規模PowerBIを見ていこうと思うので、前提としてはPowerBI Premiumにある機能を含めて解説していきます。(記事内でPremiumは💎として記述します。)
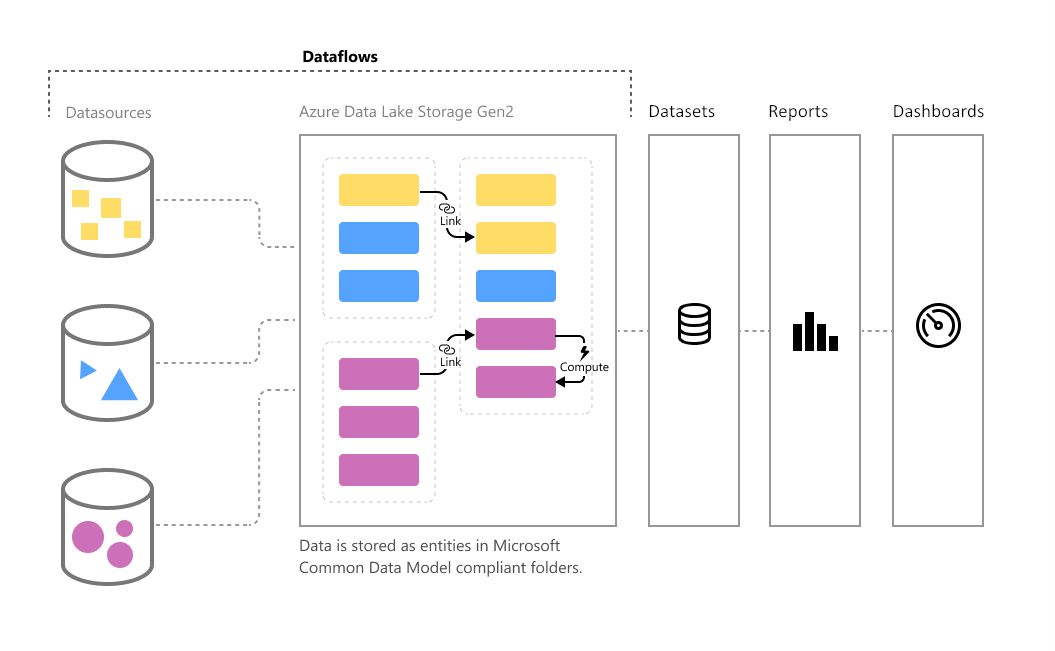
データセットとデータフロー
PowerBIデスクトップで作成するレポート内のデータセットで様々なデータソースへのアクセスすることでレポートを作成する事を上記で説明しました。PowerBI Serviceの1機能であるデータフローを利用することでデータの前処理を分離・階層化することが出来ます。レポートで扱うものをデータセット、PowerBI Serviceで扱うものをデータフローと呼びます。
PowerBIを小規模で使っている場合はレポート毎にデータセットを作成していきますが、それぞれのデータセットがデータソースへ直接アクセスする必要があるため、大規模になると次第にデータソースへのデータフェッチの量が多くなったり、データセットが大量に増えることでオペレーションが煩雑になります。データフローを扱うことで構造的に再利用, チューニングしやすくすることが出来ます。データフローを使う場合は、データセットからデータフローへアクセスします。
データセット、データフローのインポートモードではそれぞれ更新が必要です。自動更新は8回/日(💎の場合は48回/日)まで設定出来ます。
データの保存先として、データセットはPowerBI Serivce内に格納されるのに対し、データフローはAzure Data Lake Storage Gen2の中に格納されます。
データセットモード
データセットでの接続にはインポートモード、Direct Queryモード, 複合モードがあります。複合モードは前者2つの複合です。主に利用する2つを見ていきます。
インポートモード
インポート モードは、モデルの開発に使用される最も一般的なモードです。 このモードは、インメモリ クエリのおかげでパフォーマンスが非常に高速です。 また、モデラーにとって柔軟な設計が提供され、特定の Power BI サービス機能 (Q&A、クイック分析情報など) がサポートされます。 このような長所があるため、これは新しい Power BI Desktop ソリューションを作成するときの既定モードです。
レポートの描画時にオンメモリにロードされるため描画が高速に行うことが出来ます。基本的にはリアルタイムの必要性がない場合はインポートモードを使うことが多いです。しかし、大規模なデータセットの場合、オンメモリでロードする事が不都合になってしまうためインポートモードではなくDirectQueryを利用することが推奨されています。
特徴
- レンダリング時に速い
- 更新が必要
- オンメモリ
- ディメンションテーブル向き
- データが小さい場合はインポートモードで十分
DirectQuery
DirectQuery モードは、インポート モードの代わりになります。 DirectQuery モードで開発されたモデルでは、データがインポートされません。 代わりに、モデル構造を定義するメタデータのみで構成されます。 モデルに対してクエリを実行すると、基のデータ ソースからのデータの取得にネイティブ クエリが使用されます。
描画のたびに毎回データソースへ直接データフェッチを行います。リアルタイム性が高いデータにはこちらを使います。前述の通り、大規模データセットの場合もこちらを使います。DirectQueryは接続数に制限があるため, インポートモードとバランスよく使う必要があります。
特徴
- リアルタイム性
- データ更新が不要
- 描画毎にデータソースへの通信が発生する
- 大規模なファクトテーブル
データのチューニング
今回はデータ、モデリング、ビジュアルで分けたときのデータのチューニングを見ていきます。以下のベストプラクティスにはモデリングやビジュアルに関してのベストプラクティスも記述されているので興味ある方は以下のリンクから見てください。
ベストプラクティス
ちなみに今回まとめる内容はすでにPowerBIのドキュメントに公開されている手法ばかりです。しかし体系的に理解するためにはある程度の時間がかかるため、まとめて体系化することで調べやすくするのが今回の狙いです。主に以下のリンクから探っていく事で調べたい内容に到達出来ると思うので記述しておきます。
- Power BI の最適化ガイド
- データフローのベスト プラクティス
- Power Query を使用する場合のベストプラクティス
- データフローを使用してデータウェアハウスを作成するためのベストプラクティス
データソースのチューニング
データセットでもデータフローでも共通している事を先に書きます。
Power Query クエリの折りたたみ(Query Folding)
PowerBIでは様々なデータソースにデータを取得するためにPower Queryを利用し、取得したデータを加工するためにPower Queryを使いステップを記述していきます。SQLなどで接続するデータソースの場合に、記述したステップをSQLなどのクエリに暗黙的に折りたたむ機能をクエリの折りたたみといいます。Power Queryでクエリの折りたたみが行われるようにステップを記述していくことで、データのフェッチ段階でフィルタリングや加工を行うことが出来ます。また後述しますが、増分更新などの技術もクエリの折りたたみを利用することで実現されているのでそれらを利用する際にも気をつける必要があります。
インポート モデリングのデータ削減手法
データソースへの不要なデータフェッチは減らすべきなので、不要な行、不要な列は取得しないようにしましょう。
増分更新
PowerBIで用意された増分更新の機能を使って、データソースへのアクセスの期間を限定することが出来ます。前述したQuery Foldingを利用しているのでPower Query側の対応が必要な場合があります。これを利用することでデータソースへのデータフェッチを最適化でき、データセットの更新が高速になります。
データソース元での最適化
PowerBIではPowerQueryを利用して柔軟にデータの加工が出来ますが、データソース側で加工が可能なのであればそれに越したことはありません。データの型変換や列の結合など、データソース元で行うことが出来るのであればその加工フェーズをスキップすることが出来るためデータセットの更新を短くすることが出来ます。
データフローのチューニング
ここからはデータフローを使ったチューニングを見ていきます。
計算されたエンティティ, リンクされたエンティティ 💎
データセットでPower Queryを実行する場合、Power Query クエリの参照にもある通り、参照することで他のPower Queryを利用することが出来ますが、それはステップを引き継ぎ内包する形で実現されます。Query1を参照したQuery2, Query3, Query4がある場合, Query1は合計で4回実行されます。データソースへのアクセスの場合でも4回実行されます。つまりステップを参照しているだけで、データを参照しているわけではありません。
データフローでは計算されたエンティティ, リンクされたエンティティ Linked Entityを利用することでデータへの参照を行うことが出来ます。つまりデータソースへのアクセスを1本化することでデータソースへの負担を減らし、再利用可能にします。
リンクされたエンティティは単純に参照してコピーとして作成されたテーブルを指します。計算されたエンティティは参照したテーブルを元に更にステップを追加したテーブルを指します。
階層アーキテクチャ
計算されたエンティティ, リンクされたエンティティ を利用し、更に再利用性を高めるためにデータフローを分けて作成していきます。こちらは機能というより設計手法です。データフロー毎に役割を持たせたり、データフローごとに更新頻度を変更出来るため用途によってデータフローを分けて行きます。
データフローでの増分更新 💎
データフローでも増分更新することが出来ます。
データセットからデータフローへのDirectQuery 💎
データセットからデータフローへはインポートモードの他にDirectQueryを使うことが出来ます(Premium必要)。インポートモードの場合、データフローとデータセット双方でデータ更新が必要なためスケジュールを上手く設定する必要があります。DirectQueryは大規模なデータに向く、という話を前述しましたが、データフローで作成した大規模データへのアクセスをDirectQueryで実現することでインポートとDirectQueryのいいとこ取りが出来ます。
参照権限
アナリストが基になるデータ ソースに直接アクセスするのを防ぎます。 レポート作成者はデータフローに基づいて作成できるため、基になるデータソースへのアクセスを少数の個人にのみ許可し、アナリストがデータフローにアクセスし、それに基づいて作成できるようにする方が便利な場合があります。 このアプローチを使用すると、基になるシステムへの負荷が削減され、管理者は、システムが更新から読み込まれるタイミングをより細かく制御できます。
データフローでデータソースへのアクセスを隠蔽することが出来るため、レポートのデータセットを薄く実装出来ます。そのためアナリストやレポート作成者にデータソースへのアクセス権限を渡すことなく作業分担することが出来ます。
コンピューティングリソースのスケールアップ 💎
Premium Capacity のSKUを上げることで対応。金で解決💰💰💰
って出来たらいいのですが、そう簡単にはいかないのでチューニングしましょうという話ですね。
マッピングしてみる

まとめ
PowerBIや他のMicrosoft製品はあらゆるケースに対応していて便利でさらにほとんどがドキュメントとして用意されてるのですごい便利な反面、ドキュメント多すぎて概要を理解することやピンポイントで知りたい事を探すのが大変というのがあります。今回まとめた内容が、同じ問題に行き当たった人の手がかりになると嬉しいです。
所属会社
所属している株式会社EBILABではサービス業・飲食業向けのデータ統合・BI・機械学習を提供するサービス, TOUCHPOINTBI, を開発しています。EBILABではデータ基盤とデータ分析部分でAzure Serverless, WebアプリケーションはGraphQL, Nuxt.js, Laravelで構築しています。EBILABのシステムの一部としてPowerBIを、サービス業・飲食業向けにおけるデータ分析をお客様へ素早く届ける事に利用しています。