今年3月頃から機械学習(主にDeepLearning)とKaggleを始め、賞金のあるコンペ「Freesound Audio Tagging 2019(以下FAT2019)」に初めて挑戦しました。やるならばと金メダルを目指していましたが、結果はPrivateLB 89位で銅メダルに落ち着きました。苦労・工夫した点や、参考にした論文、記事、カーネルなども交えてここに記録したいと思います。
ちなみに以下が最終提出カーネルです。
定数で学習モードと推論モードを切り替えていたので、少し読みづらいですが…。なお、MixMatchなど一部の実装は実験的なもので、最終提出には使っていません。
コンペの内容
FAT2019は、環境音データに対して「エンジン音」や「男性の歌声」などのタグを付ける認識モデルを開発して精度を競うコンペです。タグは80種類あり、1つの環境音に対して複数のタグが付く場合もあるので、今回の問題は「マルチラベル分類」に相当します。MNISTなどのマルチクラス分類に比べて出力のパターン数が非常に多いため、難しめの問題設定かと思われます。具体的には、例えば10クラス分類なら10パターンで済みますが、10ラベル分類となると組み合わせがあるため $2^{10}=1024$ パターンもあります。
下図はコンペ概要ページで示されていた図を日本語に置き換えたものです。(出力タグのニュアンスが怪しい…)
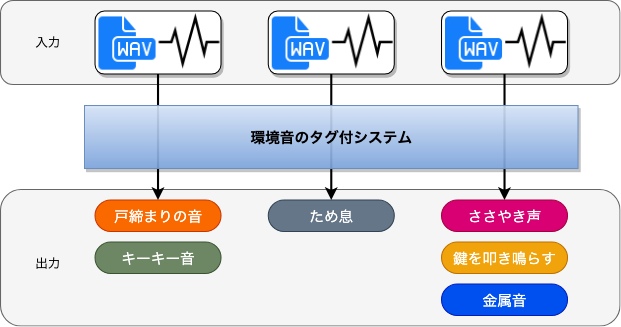
モデルの評価指標はLwLRAPというLRAPにラベル重み付けがされたものになっています。LRAPについてはコチラの記事が分かりやすいです。
また、本コンペはKaggleカーネル上で制限時間1時間以内に推論しなければいけないルールを採用しており、長時間の推論でゴリ押しみたいなことはできません。
手法について
最初はCNN、RNN、XGBoostなど試しましたが、初心者がアレコレ手を付けるのも問題なので他チームが公開してくれたカーネルをベースに勉強&試行錯誤しました。本記事では最終的に使った手法を説明します。
基本的な流れは、環境音データをスペクトログラム画像に変換して、CNN+Pooling+全結合のニューラルネットワークを通して、最後にシグモイド関数を通した結果を出力するものです。スペクトログラムの変換はLibROSA、深層学習部分はfast.aiのvisionモジュールを中心に使用しています。
音データの前処理
FAT2019から提供される環境音データはWAV形式(PCM音源)となっていますが、本手法では画像認識で高い成果が出ている2次のCNNを使った認識モデルを構築するため、事前にスペクトログラムに変換します。
スペクトログラムは周波数軸に対してメルスケール、パワーに対して対数スケールで変換します。これは人間の感覚に寄せる手法で、音声認識の分野で一般的に使われています。(ただし、環境音の認識に適しているかどうかは何とも言えない…)一般的にメルスケールのスペクトログラムを「メルスペクトログラム」と呼びます。
下図に「Bark」タグが付けられたサンプルのメルスペクトログラムを示します。(軸ラベルが抜けてしまいましたが、縦軸はメル単位の周波数、横軸はフレーム単位の時間です。)
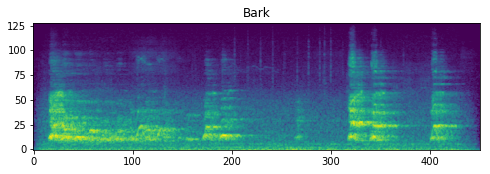
Data Augmentation
提供された環境音のデータセットは2種類あり、研究者らによって綿密にタグ付けされたcuratedデータセットと、オンラインサービスから収集したnoisyデータセットがあります。curatedは高音質かつタグ付けも正確で、4970サンプルあります。対してnoisyは音質にバラツキがあり、タグ付けも不正確なものを多分に含みますが、19815サンプルとcuratedに比べて4倍近く提供されます。
noisyの扱いが上位を狙う重要ポイントと思われますが、本節はcuratedを中心に解説します。noisyの扱いについては後述の転移学習で解説します。
Data Augmentationは日本語ではデータ水増しとも呼ばれ、学習用のサンプル数をデータ処理で増やすテクニックのことです。本手法ではcuratedのサンプルをデータ加工で増やし、MixUpで複合的に学習量を増やしています。
curatedのデータ水増し
curatedのサンプル数がnoisyに比べて少ないため、複数の加工方法を使ってサンプル数を増やします。Kaggleカーネル上で学習させたかったため、処理が重い加工と軽い加工で分けて、前者を前処理済みデータとしてnpyファイルに保存して、後者を学習時のファイルロードに含める形(オンライン)で前処理しています。
事前の前処理として、次の加工を入れた音データを生成して、メルスペクトログラムに変換1しました。各パラメーターは感と試行錯誤で定めています。
- ピッチシフト:周波数を±200centsの範囲でランダム量シフトする
- ホワイトノイズ:正規化した信号に最大 $1e{-3}\approx-60,\mathrm{db}$ のノイズを加える
オンラインの前処理では、メルスペクトログラムに対して次の加工を入れてサンプル数を更に増やしています。この内、マスク処理は音声認識の水増しとして成果が出たSpecAugmentの一部です。
- 周波数マスク:最大8px(mels)範囲の周波数帯を0〜3箇所ゼロ埋めする
- タイムマスク:最大8px(frames)範囲の時間帯を0〜3箇所ゼロ埋めする
- タイムシフト:時間方向にランダム位置で2秒分を切り取る2
- 水平反転:時間軸を反転する(有効性は微妙…)
最終的に次のような画像データが得られます。

MixUp
MixUpは学習時にサンプルをそのまま入力せずに、2つ以上の同一クラス(ラベル)のサンプルを合成したデータを使うことで正則化効果が得られ、モデルの汎化性能を向上させられる手法です。特に画像認識で高い成果が出ていたため、Kaggleコンペでは常套手段となっているようです。
詳しい理論については元論文や他の記事などをご参考下さい。
なお、fast.ai標準でMixUpが実装されていますが、マルチラベルに対応していない(と思われる)ため、改変が必要でした。有り難いことに、Vinayak氏によって公開されたカーネルに実装されていたため、そのまま拝借させて頂いています。
認識モデル
前処理で得られた2秒間のメルスペクトログラムを下図のようなCNNモデルを使い、学習・推論させます。このモデルは、FAT2019に参加していたkaggler-jaチームの公開カーネルを元にしており、Poolingのパラメータなどを独自に微調整したものです。
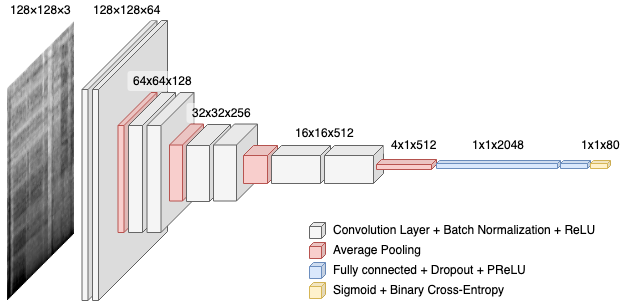
学習
学習フェーズはほぼ fast.ai vision (画像認識)で提供されている手法をそのまま使っています。大雑把に手法や使用関数を以下に示します。
- 学習単位:ミニバッチ学習
- バッチサイズ:48
- 損失関数:torch.nn.MultiLabelSoftMarginLoss
- 最適化アルゴリズム:Adam
- 学習率:One Cycle Policy
損失関数が少々ややこしいですが、理論上はSigmoid層+Binary Cross Entropy関数の認識で構いません。MultiLabelSoftMarginLossを使っているのは2つ理由があります。
- Sigmoid層を通すことで数値的に不安定になる問題を解消するため 参考(en)
- マルチラベル用の損失重みを引数指定できるため
なお、二値分類問題を対象にする場合はtorch.nn.BCEWithLogitsLossが良いようです。どちらも同じ結果を返しますが、損失重みの仕様だけ異なります。
One Cycle Policy は fast.ai course v3 の Lesson 1 でも使われており、1度のサイクル(Cyclic Learning Rateにおける単位)で高性能なモデルになるように学習率をイテレーションごとに更新する手法です。詳細は以下の論文や参考文献へ。
論文: https://arxiv.org/pdf/1803.09820.pdf
参考(英語): https://towardsdatascience.com/finding-good-learning-rate-and-the-one-cycle-policy-7159fe1db5d6
転移学習(noisy→curated)
本コンペで差を付ける1つの要因に、noisyデータをどう扱うか、という問題があります。純粋にcurated+noisyでまとめて学習させても精度的には上がりましたが、そのモデルを更にcuratedだけで学習させることでそれなりに性能が上がったため、これを採用しました。
後段の重みだけを更新(ファインチューニング)するか、全体で再学習(転移学習)させるかに悩みましたが最終的には後者を採用しています。
転移学習時は損失関数に重みを与えてスコアの低いラベルを優先的に学習させています。
Test Time Augmentation
推論時にもデータ水増しすると精度が向上することが知られています。これを Test Time Augmentation(以下TTA)と呼び、コンペ上位を狙うなら必須のようです。
実装に関しては fast.ai のTTAメソッドを使用しますが、水増し処理が fast.ai 標準(transform)のものとは異なるため、そのままでは使用できませんでした。MixUp同様にVinayak氏によって公開された実装を使用させて頂いています。
モデル評価
最終提出したモデルでは、学習済みデータでLwLRAP=0.95909、コンペのPrivateLBで0.69547となりました。
GradCAMによる評価
スコア以外に、モデルが画像のどの部分に着目して推論したかを可視化する手法の一つ、GradCAMも見ていきます。
次の画像は「Hi-hat(ハイハット)」を正しく認識できたときのメルスペクトログラムとGradCAMになります。縦軸は上が低周波、下が高周波で一般的なスペクトログラムとは逆になっているので注意してください。横軸も水増し処理で左右反転されています。

ハイハットの音は一般的に高周波にアタックの音が強く出ますが、GradCAMで下の方のエネルギーに着目しているため、正しく認識できていると考えられます。
次の画像は「Bass_drum(バスドラム)」になります。

バスドラムは低周波にアタックが出ますが、GradCAMも上部に着目しているため、ほぼパーフェクトです。
誤認したサンプルの評価
次の画像は「Mechanical_fan(電動ファン)」を誤って「Bus(風呂場)」と認識したサンプルです。左から入力データ、Busの例1(参考用)、例2(参考用)と並びます。
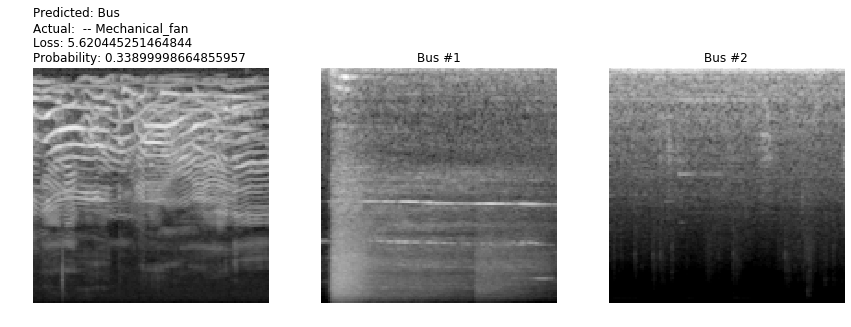
電動ファンもバス(自動車)もピンクノイズ(上の方が白っぽいグラデーション)の傾向があります。このサンプルは可変的なピッチを含む音の特徴があるため、それを含まないバス3と認識するのは違和感があります。バスに間違えたというより電動ファンとして認識できず迷った感じでしょうか。
恐らく、電動ファンの学習データにノイズ特性が強かった、もしくはピッチが可変的(ファンを稼働させる瞬間など)な学習データが少なかったことが考えられます。
他のGradCAMや誤認サンプルも転移学習段階のカーネルの最後尾にあるので、興味があれば見てみてください。
精度向上に繋がらなかった手法
ここまで最終的に使用した手法を取り上げましたが、それに対して精度向上が得られなかった手法も一部紹介します。
MixMatch
半教師あり学習(SSL)の色々な手法を織り交ぜた、最近出たばかりの手法です。論文ではマルチクラス問題を対象にした手法なのでマルチラベル用に再解釈して実装してみましたが、どうにも上手く成果が出なかったため、諦めて転移学習のアプローチに切り替えました。
コンペのディスカッションによれば、同じく精度が出ないという話が出ていました。なぜ精度が出ないのかは今後の課題です…。
位相スペクトログラム
スペクトログラムを出す際に位相情報は破棄されるため、フレーム間の音の繋がりが曖昧になってしまいます。そこで位相情報をスペクトログラムにしたらどうか、ということでいくつかの計算方法で位相スペクトログラムを出しました。
しかし、有ピッチな音(ギター、人の声など)には有効でしたが、そうでない音(打楽器、拍手など)に対しては大きく精度が落ちてしまいました。
最終的には組み合わせる案もあったものの、使わずじまいに…。
MFCC+XGBoost
深層学習以外にもツリー系のモデルも試そうと、MFCCで特徴量を圧縮してXGBoostで色々試しましたが、精度があまり出ず早々に断念しました。指標系のデータではないので厳しい…?
全体を通しての反省
上位を狙うため、とにかく学習データの調整(水増しなど)と単体モデルで性能を出すことを優先していましたが、k-Foldやアンサンブルが終盤で間に合わず…これが大失敗でした。
k-Foldを使ったローカル評価はモデル評価で重要だったため、むしろこれこそ序盤にやるべきでした。また、色々試すうちにモデルごとに得意不得意なラベルや特徴を持っていたため、この特性を活かすようにアンサンブルできればまた結果は違かったのかな、と反省です。
次の挑戦時は、評価基盤とカーネルやモデルの管理方法を工夫できればと思案しています。
参考文献など
-
https://course.fast.ai
- メインの深層学習教材として使用した
- 深層学習関連では珍しいトップダウン式に学べる
-
https://www.kaggle.com/vinayaks/2d-cnn-high-score-fast-ai
- 最終実装でベース&参考にしたカーネル
- 特にMixUpとTTAの実装を使用した
-
https://github.com/zcaceres/spec_augment
- SpecAugment(周波数マスクとタイムマスク)の実装で参考にした
その他
こういった記事は初めてですので、適時加筆修正すると思います。指摘や質問は大歓迎です。
また、手法解説を主にしたためプログラムコードは載せていません。時間的余裕があれば別記事で書くかもしれませんが、基本的にはカーネルの方見てください…。