はじめに
最近自然言語処理はじめました ![]()
HuggingFaceのチュートリアルをやってたのですが、モデルのトークナイザーにis_fast属性(高速トークナイザー)がなかったので作ることになりました。
※引用ばかりですみません
word_idsとは?
自然言語処理でモデルにデータを渡す際、文毎の位置を0から割り当てたID
サブワードの分割では一つの単語として同じ数字が割り当てられる
input_idsとの違い
Claude.ai
input_idsとword_idsの主な違いは以下の点です。
■input_ids
・Transformerベースのモデルへ入力するための入力単語のIDです。
・単語に加えて、特別トークン(CLS、SEPなど)も含まれます。
■word_ids
・単語列の各単語に対して割り当てられたIDです。
・特別トークンは含まれず、単語のみに対するIDです。
word_idsの代わり
■HuggingFaceだとできないこと
Tokenizerにis_fast要素がないとword_idsを作れない
チュートリアル(HuggingFace)のコード
def tokenize_function(examples):
result = tokenizer(examples["text"])
if tokenizer.is_fast:
result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
return result
# Use batched=True to activate fast multithreading!
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
tokenized_datasets
■今回の主題
Tokenizerにis_fast要素がなくてもword_idsを再現する方法の作成
def tokenize_function(examples) :
result = tokenizer(examples["text"])
if tokenizer.is_fast :
result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
else :
tokens = result["input_ids"]
word_idsList = []
for e, token in enumerate(tokens) :
word_ids = []
tmp_word_id = -1
tmp_token = ""
for word in token :
word = tokenizer.decode(word)
if word.startswith("##"):
# 直前のトークンの連結
tmp_token += word[2:]
word_ids.append(tmp_word_id)
elif word == "[CLS]" or word == "[SEP]" :
word_ids.append(None)
else :
tmp_word_id += 1
word_ids.append(tmp_word_id)
tmp_token = word
word_idsList.append(word_ids)
result["word_ids"] = word_idsList
return result
# Use batched=True to activate fast multithreading!
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
tokenized_datasets
単純に##で続いたらサブワードとして認識するようにした
num_proc=4の値を.map関数内にすると早くなるけど、エラーが出る...
Token indices sequence length is longer than the specified maximum sequence length for this model (759 > 512). Running this sequence through the model will result in indexing errors
時間の比較
mapが完了するまでにどのくらいの時間がかかったのか
環境
OS:Ubuntu 22.04.3 LTS (Jammy Jellyfish)
CPU:12 x Intel(R) Core(TM) i7-3930K CPU @ 3.20GHz (1 Socket)
GPU:なし
メモリ:20 GiB
データセット:imdb
■is_fast属性あり
01秒
■is_fast属性なし(自作した関数)
04分37秒
Map: 100%|█████████████████████████████████████| 25000/25000 [01:09<00:00, 357.88 examples/s]
Map: 100%|█████████████████████████████████████| 25000/25000 [01:08<00:00, 363.72 examples/s]
Map: 100%|█████████████████████████████████████| 25000/25000 [02:20<00:00, 355.73 examples/s]
以下map中のモニタリング状況(実行中ほぼ不変)
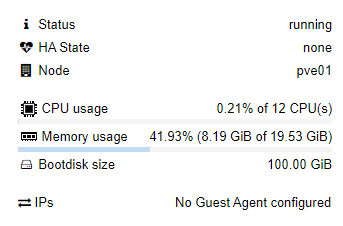
⇒つまるところ全然CPUを使ってくれない
課題
とにかく遅い。