はじめに
ONTAPおけるVolumeはデータを保存し、管理するための単位であり、容量やパフォーマンスの要件に応じて作成する必要があります。
例えば、ファイルサーバ用途の場合、部署毎にVolumeを作成する事でデータの整理やアクセス制御の管理が容易になります。
また、セキュリティ要件(UNIX, NTFS)によって分けて作成するような場合もありますし、パフォーマンス要件が異なる場合には、SSDベースのVolumeや容量重視のHDDベースのVolumeを作成することが有効な場合もあります。
但し、同一のDisk構成で特にセキュリティ的にも分ける必要が無い場合には、1つの大きなVolumeを作成して提供するのは仕様上最適であると言えるのでしょうか?
本記事では、ONTAP仕様に基づくVolume作成の最適個数について記載致します。

とりあえず結論
- Volumeは複数作成が推奨で、Aggregateあたり4 Volume
- Aggregateも複数作成が推奨
- 1 Volume環境の推奨は相当昔のONTAPの話(15年位前?)
Aggregateの複数作成については、障害時の影響をどうするかでも変わってきます。
障害時にコントローラへI/O集約してLatency上昇するのを抑えたいという点においては、通常時にはAggregateはコントローラあたり1つとする事で、影響度を下げる事はできます。

データ並列処理ついて
ONTAPは、最初はシングルCPU環境を想定して設計されていましたが、ハードウェアのクロック数競争が終わり、マルチコア化が進むにつれて、ONTAPもCSMP(Coarse Symmetric Multi Processing)モデルに移行しました。これにより、搭載されたCPUで負荷を分散するように設計されています。
また、CPUリソースは処理ごとに「ドメイン」という単位で管理されており、各ドメインは、シングルスレッドで動作するものとマルチスレッドで動作するものがあります。
ONTAPのファイルシステムであるWAFLのデータ処理(ユーザアクセス処理)については、過去のONTAPではシングルスレッドで動くKahunaドメインで処理されていましたが、WAFL Exemptドメインに下請けすることで分散処理が行われるように変わっています。
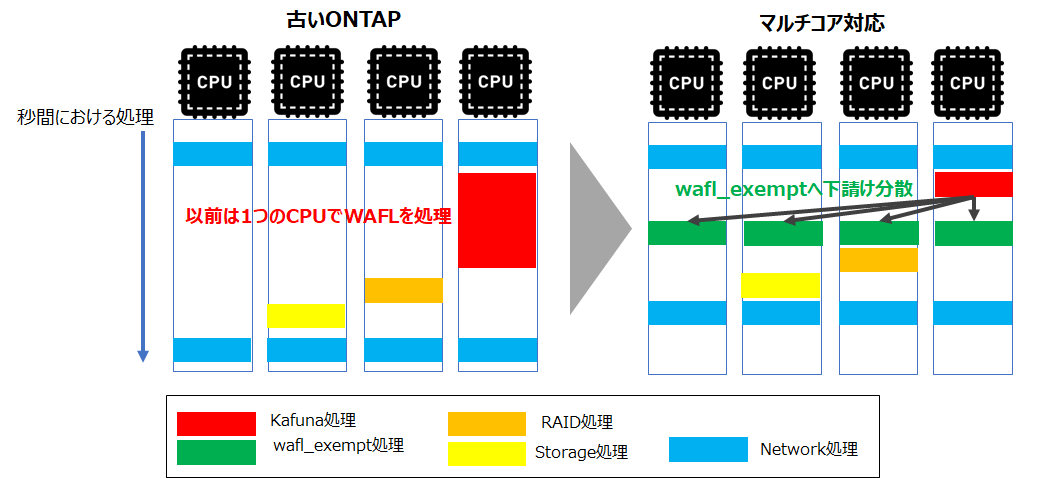
ドメインの処理については、CLIですとNode shellからDiag モードでsysstat -Mで確認するか、HarvestのNodeに関する項目からCPU Busy Domainグラフで利用状況を確認できます。
> node run -node コントローラ名 -command "priv set diag;sysstat -M 1"
Warning: These diagnostic commands are for use by NetApp
personnel only.
ANY1+ ANY2+ ANY3+ ANY4+ ANY5+ ANY6+ ANY7+ ANY8+ ANY9+ ANY10+ ANY11+ ANY12+ ANY13+ ANY14+ ANY15+ ANY16+ ANY17+ ANY18+ ANY19+ ANY20+ AVG CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7 CPU8 CPU9 CPU10 CPU11 CPU12 CPU13 CPU14 CPU15 CPU16 CPU17 CPU18 CPU19 Nwk_Lg Nwk_Exmpt Protocol Storage Raid Raid_Ex Xor_Ex Target Kahuna WAFL_Ex(Kahu) WAFL_MPClean SM_Exempt Exempt SSAN_Ex Intr Host Ops/s CP
32% 15% 10% 7% 4% 3% 2% 1% 1% 1% 0% 0% 0% 0% 0% 0% 0% 0% 0% 0% 4% 3% 3% 2% 2% 3% 3% 4% 2% 3% 3% 2% 1% 2% 1% 1% 10% 8% 18% 8% 10% 0% 10% 0% 1% 0% 0% 0% 0% 0% 13%( 0%) 0% 0% 19% 0% 12% 28% 1049 0%
50% 26% 15% 9% 5% 3% 2% 1% 1% 1% 0% 0% 0% 0% 0% 0% 0% 0% 0% 0% 6% 3% 3% 2% 2% 3% 3% 3% 2% 4% 4% 2% 0% 2% 1% 1% 24% 14% 19% 14% 19% 0% 18% 0% 1% 0% 0% 0% 0% 0% 22%( 1%) 0% 0% 29% 0% 13% 38% 2144 0%
31% 16% 10% 7% 5% 3% 2% 1% 1% 1% 0% 0% 0% 0% 0% 0% 0% 0% 0% 0% 4% 3% 3% 2% 2% 3% 3% 3% 2% 3% 3% 3% 1% 2% 1% 1% 13% 9% 12% 9% 12% 0% 13% 0% 1% 0% 1% 0% 0% 0% 18%( 0%) 0% 0% 19% 0% 13% 20% 1606 0%
45% 27% 17% 10% 6% 4% 3% 2% 1% 1% 0% 0% 0% 0% 0% 0% 0% 0% 0% 0% 6% 3% 3% 3% 3% 3% 3% 3% 3% 6% 3% 3% 1% 2% 1% 1% 20% 14% 19% 16% 20% 0% 35% 0% 1% 0% 1% 0% 0% 0% 30%( 1%) 0% 0% 22% 0% 14% 22% 5041 0%
76% 68% 62% 52% 39% 23% 13% 9% 6% 5% 3% 3% 2% 2% 1% 1% 1% 0% 0% 0% 19% 8% 10% 6% 8% 8% 7% 10% 7% 11% 8% 7% 5% 7% 6% 5% 54% 50% 54% 52% 55% 0% 21% 0% 4% 0% 18% 15% 0% 0% 88%( 4%) 159% 0% 34% 0% 12% 20% 2109 97%

Waffinityについて
一方で、ドメイン単位における処理は分割単位が大きいため、Networkに関する処理やWAFLのデータ処理(全Aggregateをまとめて)するといったような大きな単位でしか処理を分割できず、マルチスレッド対応には限界がありましたが、現在ではより細かな単位で並列処理を可能にするためにWaffinityが導入されています
WAFLの処理内容ごとに階層的にマルチスレッド化を行うことで、より細かいレベルでの並列処理が可能になっています。
ざっくりと言いますと、以下のような形です。
・ロック不要な範囲のユーザーファイルの読み書きを並列化
・データ構造やメタファイル変更操作(ファイル作成/削除など)を並列化
・別AggregateやVolume、ファイルブロック領域内の2つの操作などの分離データ操作を並列化
物理CPU単位で分けるということではないので、正確な表現では無いですが、以下の図のようにVolumeへ割り振られるWaffinity IDが異なると処理も分けてくれる(CPUを分ける)ようなイメージを持っていただくと分かりやすいと思います。

詳細を知りたい場合はアメリカのUSENIX協会へNetApp社のエンジニアが論文寄稿をしており、こちらに詳しく記載されております。
内容が難しいので、Bing Chat等を活用して翻訳や要約をしながら読んで頂くと良いかと思いますが、以下の簡易図ように細かく処理をわける事で、ロックのかかってないものは並列で処理することで効率化を図ってます。

1Volumeへのアクセスと4volumeへ分散した場合のパフォーマンスを比較してみる
以下のようなVolume数だけの違いでIOPSに差がでるか確認してみたいと思います。

実施条件
・検証とは別に既に負荷のかかっているFASで実施 (同じAggregateにVolume100個位)
・1Aggregateで1Volume作成か4 Volume作成かで同じアクセスパターンで差が出るか確認
・CIFS環境で確認
・同じNetworkセグメントで確認
・Serverは4つの物理サーバを使用
・Volumeパターンに関係なく同じLIFへアクセス
・重複排除や圧縮は有効化
・負荷をかけるツールはDISKSPDを使用
(Blockサイズ16Kで、60秒間Read/Writeの実施)
結果
以下のように、基本的には分散を図る事でIOPS等が増加しているのが確認できました。
1つめのVolumeは、既存環境の負荷影響なのか、リバランスの条件を満たしてない為なのか大きな増加はみられませんでした。
| Server#1 | Server#2 | Server#3 | Server#4 | |
|---|---|---|---|---|
| I/O per s(集約) | 4642 | 5081 | 4968 | 5017 |
| I/O per s(分散) | 4731 | 6501 | 6585 | 6505 |
| MiB/s(集約) | 72.54 | 79.4 | 77.63 | 78.4 |
| MiB/s(分散) | 73.92 | 101.58 | 102.89 | 101.65 |
| 平均latency[ms](集約) | 0.429 | 0.392 | 0.401 | 0.397 |
| 平均latency[ms](分散) | 0.421 | 0.307 | 0.303 | 0.306 |
実際のDISKSPD出力
Server#4のDISKSPDの出力になりますが、以下の通りです。
1volume集約時
> diskspd.exe -b16K -c1G -r -o1 -t2 -Sh -n -L -D -W0 -d60 -w50 \\172.16.10.149\share100\testfile4.dat
Command Line: diskspd.exe -b16K -c1G -r -o1 -t2 -Sh -n -L -D -W0 -d60 -w50 \\172.16.10.149\share100\testfile4.dat
Input parameters:
timespan: 1
-------------
duration: 60s
warm up time: 0s
cool down time: 0s
affinity disabled
measuring latency
gathering IOPS at intervals of 1000ms
random seed: 0
path: '\\172.16.10.149\share100\testfile4.dat'
think time: 0ms
burst size: 0
software cache disabled
hardware write cache disabled, writethrough on
performing mix test (read/write ratio: 50/50)
block size: 16KiB
using random I/O (alignment: 16KiB)
number of outstanding I/O operations per thread: 1
threads per file: 2
IO priority: normal
System information:
computer name: PS-04
start time: 2023/06/05 02:58:51 UTC
Results for timespan 1:
*******************************************************************************
actual test time: 60.00s
thread count: 2
proc count: 20
CPU | Usage | User | Kernel | Idle
-------------------------------------------
0| 45.76%| 0.10%| 45.65%| 54.24%
1| 0.08%| 0.03%| 0.05%| 99.92%
2| 10.81%| 0.70%| 10.11%| 89.19%
3| 0.00%| 0.00%| 0.00%| 100.00%
4| 7.08%| 0.42%| 6.67%| 92.92%
5| 0.03%| 0.00%| 0.03%| 99.97%
6| 0.34%| 0.10%| 0.23%| 99.66%
7| 0.00%| 0.00%| 0.00%| 100.00%
8| 0.10%| 0.03%| 0.08%| 99.90%
9| 0.00%| 0.00%| 0.00%| 100.00%
10| 4.95%| 0.00%| 4.95%| 95.05%
11| 0.00%| 0.00%| 0.00%| 100.00%
12| 20.78%| 0.00%| 20.78%| 79.22%
13| 0.00%| 0.00%| 0.00%| 100.00%
14| 0.08%| 0.00%| 0.08%| 99.92%
15| 0.00%| 0.00%| 0.00%| 100.00%
16| 0.03%| 0.03%| 0.00%| 99.97%
17| 0.00%| 0.00%| 0.00%| 100.00%
18| 0.03%| 0.00%| 0.03%| 99.97%
19| 0.00%| 0.00%| 0.00%| 100.00%
-------------------------------------------
avg.| 4.50%| 0.07%| 4.43%| 95.50%
Total IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | IopsStdDev | LatStdDev | file
------------------------------------------------------------------------------------------------------------------
0 | 2453602304 | 149756 | 39.00 | 2495.88 | 0.399 | 179.32 | 0.142 | \\172.16.10.149\share100\testfile4.dat (1GiB)
1 | 2478817280 | 151295 | 39.40 | 2521.53 | 0.395 | 180.86 | 0.139 | \\172.16.10.149\share100\testfile4.dat (1GiB)
------------------------------------------------------------------------------------------------------------------
total: 4932419584 | 301051 | 78.40 | 5017.41 | 0.397 | 359.78 | 0.141
Read IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | IopsStdDev | LatStdDev | file
------------------------------------------------------------------------------------------------------------------
0 | 1231224832 | 75148 | 19.57 | 1252.44 | 0.375 | 92.95 | 0.141 | \\172.16.10.149\share100\testfile4.dat (1GiB)
1 | 1241235456 | 75759 | 19.73 | 1262.62 | 0.370 | 91.07 | 0.137 | \\172.16.10.149\share100\testfile4.dat (1GiB)
------------------------------------------------------------------------------------------------------------------
total: 2472460288 | 150907 | 39.30 | 2515.06 | 0.372 | 180.11 | 0.139
Write IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | IopsStdDev | LatStdDev | file
------------------------------------------------------------------------------------------------------------------
0 | 1222377472 | 74608 | 19.43 | 1243.44 | 0.423 | 92.98 | 0.138 | \\172.16.10.149\share100\testfile4.dat (1GiB)
1 | 1237581824 | 75536 | 19.67 | 1258.91 | 0.421 | 95.96 | 0.137 | \\172.16.10.149\share100\testfile4.dat (1GiB)
------------------------------------------------------------------------------------------------------------------
total: 2459959296 | 150144 | 39.10 | 2502.35 | 0.422 | 186.39 | 0.137
total:
%-ile | Read (ms) | Write (ms) | Total (ms)
----------------------------------------------
min | 0.217 | 0.249 | 0.217
25th | 0.300 | 0.364 | 0.333
50th | 0.354 | 0.404 | 0.382
75th | 0.409 | 0.450 | 0.434
90th | 0.477 | 0.504 | 0.493
95th | 0.527 | 0.551 | 0.540
99th | 0.729 | 0.760 | 0.745
3-nines | 2.232 | 2.275 | 2.246
4-nines | 3.548 | 3.881 | 3.765
5-nines | 4.775 | 4.988 | 4.775
6-nines | 5.664 | 5.955 | 5.955
7-nines | 5.664 | 5.955 | 5.955
8-nines | 5.664 | 5.955 | 5.955
9-nines | 5.664 | 5.955 | 5.955
max | 5.664 | 5.955 | 5.955
4volume分散時
> diskspd.exe -b16K -c1G -r -o1 -t2 -Sh -n -L -D -W0 -d60 -w50 \\172.16.10.149\share400\testfile4.dat
Command Line: diskspd.exe -b16K -c1G -r -o1 -t2 -Sh -n -L -D -W0 -d60 -w50 \\172.16.10.149\share400\testfile4.dat
Input parameters:
timespan: 1
-------------
duration: 60s
warm up time: 0s
cool down time: 0s
affinity disabled
measuring latency
gathering IOPS at intervals of 1000ms
random seed: 0
path: '\\172.16.10.149\share400\testfile4.dat'
think time: 0ms
burst size: 0
software cache disabled
hardware write cache disabled, writethrough on
performing mix test (read/write ratio: 50/50)
block size: 16KiB
using random I/O (alignment: 16KiB)
number of outstanding I/O operations per thread: 1
threads per file: 2
IO priority: normal
System information:
computer name: PS-04
start time: 2023/06/05 03:06:45 UTC
Results for timespan 1:
*******************************************************************************
actual test time: 60.00s
thread count: 2
proc count: 20
CPU | Usage | User | Kernel | Idle
-------------------------------------------
0| 44.87%| 0.00%| 44.87%| 55.13%
1| 0.00%| 0.00%| 0.00%| 100.00%
2| 0.03%| 0.00%| 0.03%| 99.97%
3| 0.00%| 0.00%| 0.00%| 100.00%
4| 0.16%| 0.05%| 0.10%| 99.84%
5| 0.00%| 0.00%| 0.00%| 100.00%
6| 0.03%| 0.00%| 0.03%| 99.97%
7| 0.00%| 0.00%| 0.00%| 100.00%
8| 0.05%| 0.03%| 0.03%| 99.95%
9| 0.00%| 0.00%| 0.00%| 100.00%
10| 1.80%| 0.03%| 1.77%| 98.20%
11| 0.00%| 0.00%| 0.00%| 100.00%
12| 25.23%| 0.13%| 25.10%| 74.77%
13| 0.03%| 0.00%| 0.03%| 99.97%
14| 11.09%| 0.29%| 10.81%| 88.91%
15| 0.03%| 0.00%| 0.03%| 99.97%
16| 7.32%| 0.29%| 7.03%| 92.68%
17| 0.00%| 0.00%| 0.00%| 100.00%
18| 0.49%| 0.00%| 0.49%| 99.51%
19| 0.08%| 0.03%| 0.05%| 99.92%
-------------------------------------------
avg.| 4.56%| 0.04%| 4.52%| 95.44%
Total IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | IopsStdDev | LatStdDev | file
------------------------------------------------------------------------------------------------------------------
0 | 3175841792 | 193838 | 50.48 | 3230.83 | 0.308 | 139.55 | 0.116 | \\172.16.10.149\share400\testfile4.dat (1GiB)
1 | 3218964480 | 196470 | 51.17 | 3274.70 | 0.304 | 134.66 | 0.112 | \\172.16.10.149\share400\testfile4.dat (1GiB)
------------------------------------------------------------------------------------------------------------------
total: 6394806272 | 390308 | 101.65 | 6505.53 | 0.306 | 273.21 | 0.114
Read IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | IopsStdDev | LatStdDev | file
------------------------------------------------------------------------------------------------------------------
0 | 1591001088 | 97107 | 25.29 | 1618.55 | 0.281 | 76.18 | 0.114 | \\172.16.10.149\share400\testfile4.dat (1GiB)
1 | 1609056256 | 98209 | 25.58 | 1636.92 | 0.275 | 71.87 | 0.110 | \\172.16.10.149\share400\testfile4.dat (1GiB)
------------------------------------------------------------------------------------------------------------------
total: 3200057344 | 195316 | 50.87 | 3255.47 | 0.278 | 139.21 | 0.112
Write IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | IopsStdDev | LatStdDev | file
------------------------------------------------------------------------------------------------------------------
0 | 1584840704 | 96731 | 25.19 | 1612.28 | 0.336 | 75.66 | 0.111 | \\172.16.10.149\share400\testfile4.dat (1GiB)
1 | 1609908224 | 98261 | 25.59 | 1637.78 | 0.333 | 74.34 | 0.107 | \\172.16.10.149\share400\testfile4.dat (1GiB)
------------------------------------------------------------------------------------------------------------------
total: 3194748928 | 194992 | 50.78 | 3250.07 | 0.335 | 145.34 | 0.109
total:
%-ile | Read (ms) | Write (ms) | Total (ms)
----------------------------------------------
min | 0.136 | 0.187 | 0.136
25th | 0.211 | 0.280 | 0.242
50th | 0.253 | 0.319 | 0.293
75th | 0.316 | 0.367 | 0.348
90th | 0.383 | 0.415 | 0.404
95th | 0.439 | 0.450 | 0.446
99th | 0.634 | 0.671 | 0.652
3-nines | 1.550 | 1.792 | 1.675
4-nines | 2.807 | 3.012 | 2.920
5-nines | 4.102 | 5.863 | 4.506
6-nines | 4.506 | 6.331 | 6.331
7-nines | 4.506 | 6.331 | 6.331
8-nines | 4.506 | 6.331 | 6.331
9-nines | 4.506 | 6.331 | 6.331
max | 4.506 | 6.331 | 6.331
FAQ
・Volumeは必ず4つじゃないとNG?
=> コントローラーのCPU搭載数で分散数(Waffinity ID)が変わってくるので、最小2個からと考えても良いと思います。(高スペックだと8個等でA90だと16個とか)
・Volumeを複数作成しても負荷が偏ったらどうするの?
=> Affinity使用率に大きな偏りがあれば、自動的にVolumeのAffinity IDの割り当てを変更。
(時間単位でチェックしているので、数分の検証では確認できないです)
参考及びリンク
High latency from CPU even the CPU average utilization is not high
Lower than expected performance while utilizing a single volume
CPU as a compute resource and the CPU domains explained in ONTAP 9
DISKSPD を使用してワークロード ストレージのパフォーマンスをテストする
To Waffinity and Beyond: A Scalable Architecture for Incremental Parallelization of File System Code