はじめに
自分でPythonのコードを書いてAIのモデル構築といった事は難しいけど、手軽にAI構築環境を利用したいといった場合にクラウド上のサービスを利用すると、機械学習モデルを作成、トレーニング、デプロイをGUI操作で利用する事ができます。
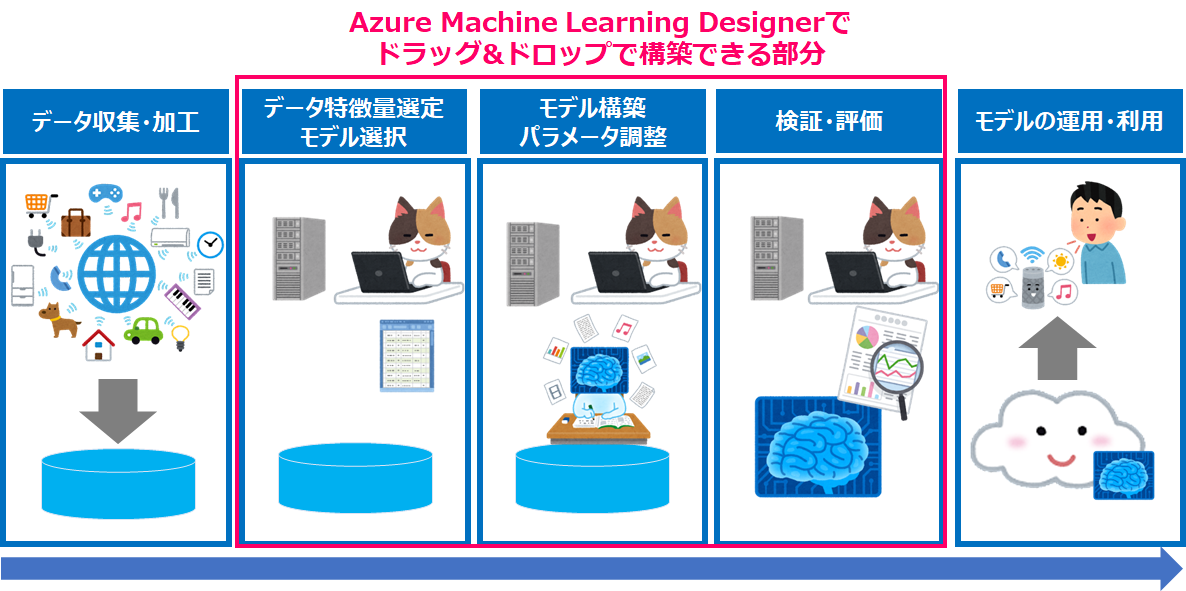
本記事では前回の記事に続いて、Azure Machine Learning Designerを使用して特徴量選択から検証・評価までの機械学習パイプラインの構築をドラッグ&ドロップで実施する方法について試してみたいと思います。
パイプライン作成を目的とした内容ですので、特徴量エンジニアリングについては割愛しています。
AutoMLとは異なり、処理の順番やどの機械学習モデルを利用するかについて事前に考える必要がありますので、AIやデータサイエンティストの知識があるのが望ましいですが、Azure Machine Learning Designerではパイプラインのサンプルがある為、どのように処理を接続するかについては確認することができます。
 |
|---|
何をしたい?できる?
- Azure上で、Azure Machine Learning Designerを使って学習パイプライン作成
- KaggleのHouse Pricesデータを使って試してみる
House Pricesデータについて
KaggleのHouse Pricesデータセットは、アイオワ州の住宅価格を予測するために使用され、住宅の広さや築年数、地理的な位置情報、材料品質といった多様な特徴量が含まれています。これらの特徴量を利用して、機械学習モデルを構築し、住宅価格の予測を行うことが目的となります。
(データのダウンロードにはKaggleへのアカウント作成が必要になりますが、ここでは割愛します。)
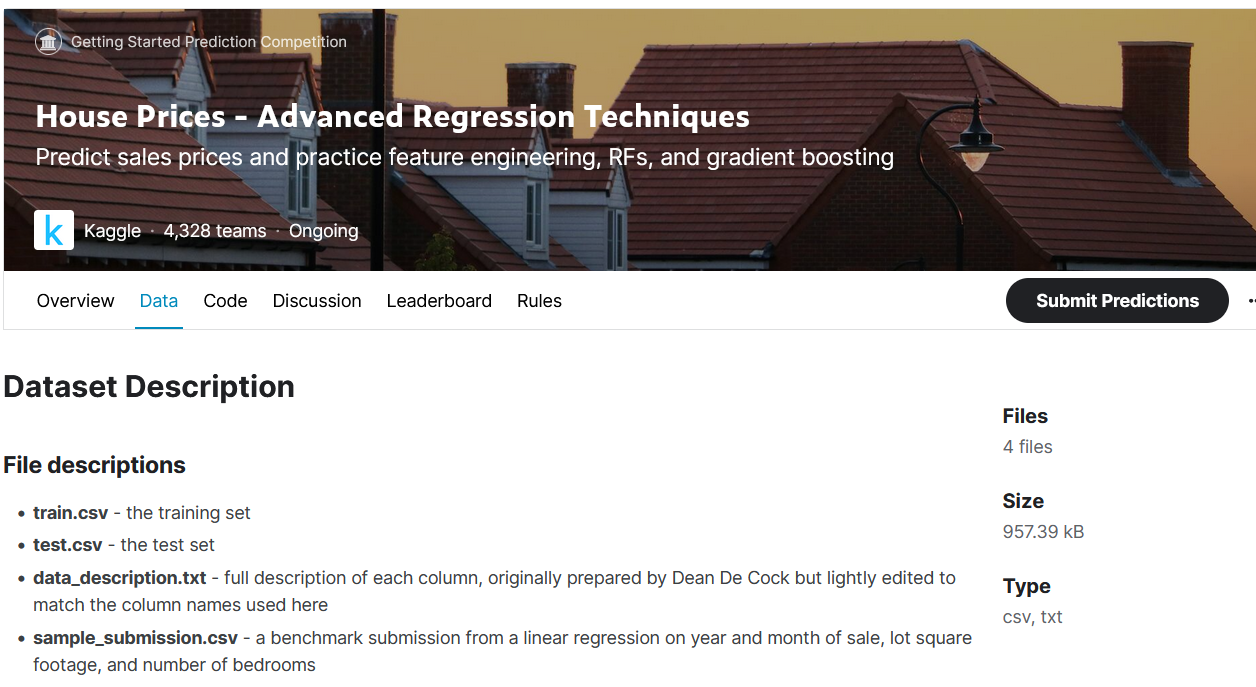
ダウンロードするデータは以下の4つになります。
- train.csv
=>機械学習の学習用データ(正解を含めて記載されているデータ) - test.csv
=>作成したモデルに渡して予測を行う為のデータ(正解はKaggle側が持っている) - data_description.txt
=>説明変数の詳細(特に質的変数の略字の意味等) - gender_submission.csv
=>Kaggleへの提出するファイルの例
学習用データであるtrain.csvは住宅の広さや築年数のデータがcsv形式で記載されており、
最終的に予測したいSalePriceという列に販売価格が記載されています。
学習データの説明は一部抜粋となりますが以下の通りで、SalePriceを予測する為に利用します。
| 列名 | 説明 |
|---|---|
| MSSubClass | 住宅の種類 |
| MSZoning | 売却先の一般的なゾーニング区分 |
| LotArea | 敷地面積 |
| YearBuilt | 建設時期 |
| OverallCond | 家全体の状態 |
| SalePrice | 住宅の価格<=この値を様々な説明変数を元に予測したい |
Azure Machine Learning Designerについて
本記事では、Azure Machine Learningのデザイナー機能を使い、モジュールを繋ぎ合わせて学習環境を構築する形となりますが、サンプルを事前に確認する事で、利用するモジュールや繋げ方を参考にする事ができます。
サンプルを改良して使う方が楽だとは思いますが、記事では逐次モジュール選択含めての構築例として記載してます。
上記のHouse Pricesデータ予測という回帰問題のモデルを作成したいという内容ですので、参考にするものとしてはRegression(回帰)に関するモデルとなります。
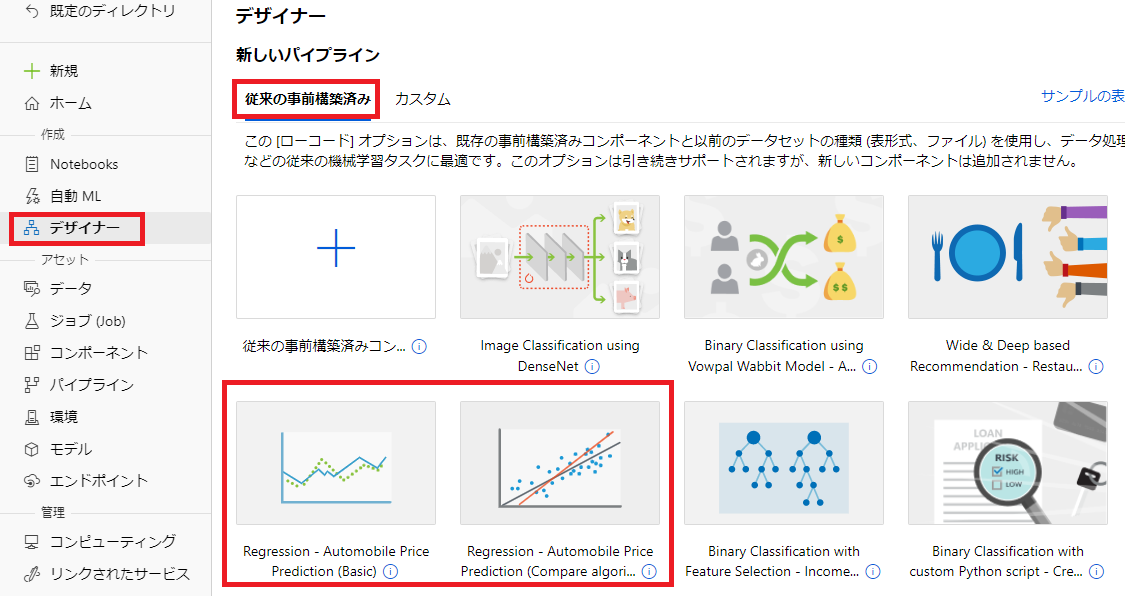
実際に[Regression - Automobile Price Prediction (Basic)]というサンプルを確認すると、
上の方から
- Azure側の用意しているデータ (Automobile price data)
- データで使う説明変数(列)の選択 (Select Columns in Dataset)
- 欠損値の多い説明変数の削除 (Clean Missing Data)
- データの分割 (Split Data)
- 学習アルゴリズムと接続して学習
- モデルの評価
というような形となっている事が確認できます。
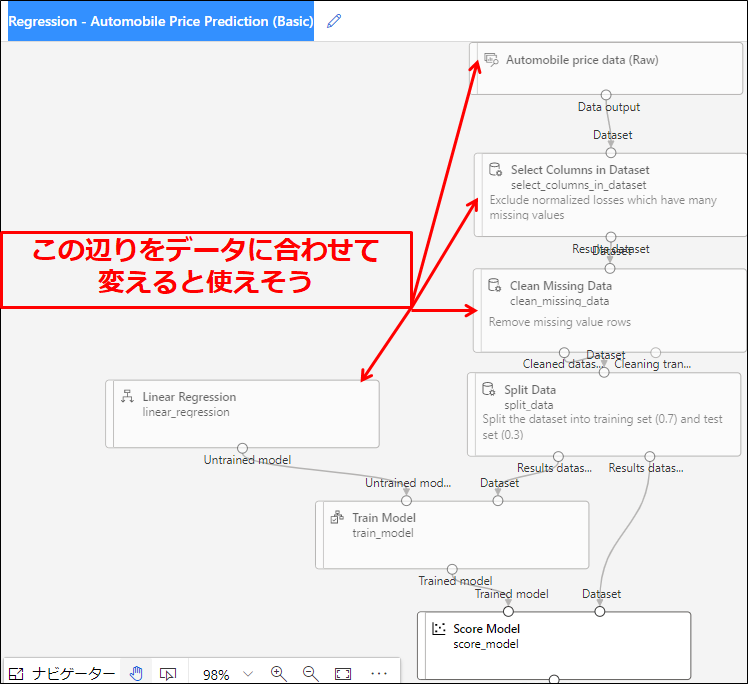
以下の点を修正する事で作成できそうな事が推測できます。
- Azureの用意しているデータをHouse Prices用のデータに置き換える
- データで使う説明変数(列)の選択をHouse Prices用のデータに合わせる
- 必要そうなコンポーネントを別途追加してみる
- 学習アルゴリズムを変えたい場合は変更
設定手順
画面例で指定されている以下のパラメータは、環境によって異なる内容なので適宜変更して下さい。
- リソースグループ名:ai_rg102
- Azure machine learning ワークスペース名:test-wkspace102
- リソースを作成するリージョン:Japan East(東日本)
- ドラフト名:House Prices
- データセット名:House Prices
- 実験名:house-prices-training
1. リソースグループ作成
サインインやAzureでリソースグループの作成については、
AzureのAIサービスを利用してみる1の記事と同じ内容となりますので割愛します。
(今回の記事用に名前はai_rg102に変えている)
2. Azure Machine Learningのワークスペース作成
Azure Machine Learningのワークスペース作成については、
AzureのAIサービスを利用してみる3の記事と同じ内容となりますので割愛します。
(今回の記事用に名前はtest-wkspace102に変えている)
3. Azure Machine Learning Studioへのアクセス
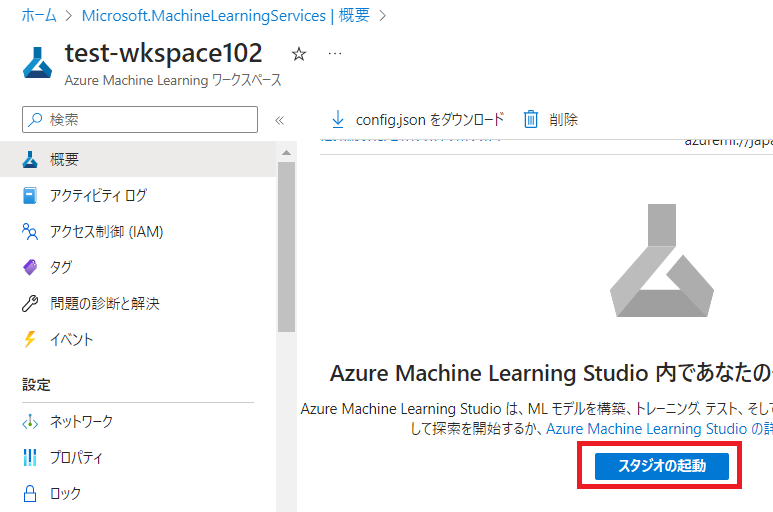
作成完了後に、リソースグループ上にあるワークスペース名のtest-wkspace102をクリックし、表示された画面にある、[スタジオの起動]をクリックします。
4. Azure Machine Learning上で使うコンピューティング作成
作成したワークスペース上で実行する処理の種類で必要となるコンピューティングが異なります。
コンピューティングの種類や実施される処理については以下の通りです。
| 種類 | 説明 |
|---|---|
| コンピューティングインスタンス | Notebook実行用の仮想マシン |
| コンピューティングクラスター | 学習や推論の実行環境 |
| Kubernetes クラスター | 独自のKubernetesクラスターを組み込んで利用 |
| アタッチされたコンピューティング | 仮想マシン、Databricksクラスター等の独自コンピューティングをアタッチ |
Azure Machine Learning Studioの画面左側にある[コンピューティング]をクリックし、表示された画面で[コンピューティングクラスター]タブから[+新規]をクリックします。

作成する仮想マシンの場所や種類を選択します。
重い処理を実施はしないのでStundard_DS11_v2を指定して進めます。

コンピューティング名やクラスタを構成するノードの最大数を指定します。
(ここでは最大2台構成にしています)

5. MLパイプライン作成
本記事では、データをHouse Prices用のデータに置き換えると共に、学習アルゴリズムについてはBoosted Decision Tree Regressionを利用してMLパイプライン作成を実施します。
詳細はリンクに記載されてますが、LightGBMアルゴリズムに基づいており、スケーリングする必要がなく,欠損値をそのまま扱うことができるといった特徴があります。
5-1. ドラフト作成開始と設定
Azure Machine Learning Studioの画面左側にある[デザイナー]をクリックし、表示された画面で[+]をクリックします。

表示された鉛筆マークをクリックしてドラフト名(パイプライン名)を変更します。


画面右上の[設定]をクリックし、作成したコンピューティングの種類とクラスタ名を選択します。

5-2. House Prices用のデータ登録
House Prices用のデータを利用する為、[データ]タブの[+]をクリックします。
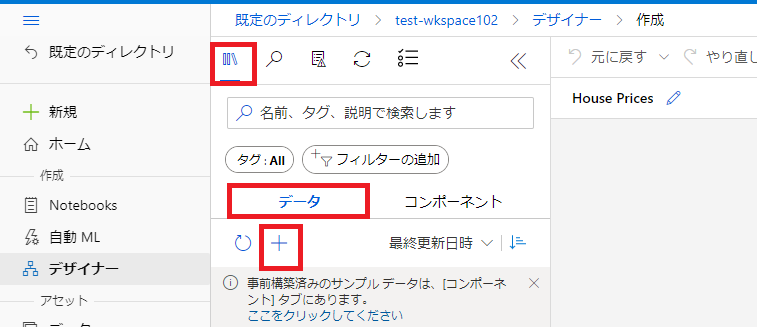
データセット名を入力し、種類を表形式にして[次へ]をクリックします。

Kaggleからダウンロードしたデータを使うので、[ローカルファイルから]をクリックして[次へ]をクリックします。

データを保存先となるデータストア(クラウド上のデータ置き場)を指定します。
ここではワークスペース作成時に、併せて作成されたAzure Blob Storageを選択しています。

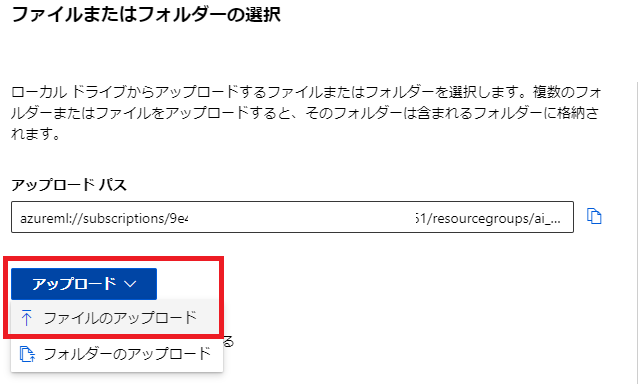
[アップロード]から[ファイルのアップロード]を選択し、House Prices用のtrain.csvを選択します。

設定で項目が正しく選択されている事を確認します。
- ファイル形式 :区切り
- 区切り記号 :コンマ
- エンコード :UTF-8
- 列見出し :すべてのファイルで同じヘッダーを利用
- 行のスキップ :なし

スキーマでは利用する変数の選択を実施します。
ここでは、後のパイプライン作成時に変数を選択するので除外は実施しません。
また、質的変数を[文字列]に変更し、広さのような量的変数を[小数点(ドット'.')]にします。
「次へ」を指定後に、レビューで登録内容に問題が無い事を確認し[作成]をクリックします。

画面左側に、データが登録されている事を確認します。

5-3. モジュールを利用した学習パイプライン構築
登録されたデータを選択し、ドラッグ&ドロップで画面の中央に移動させます。

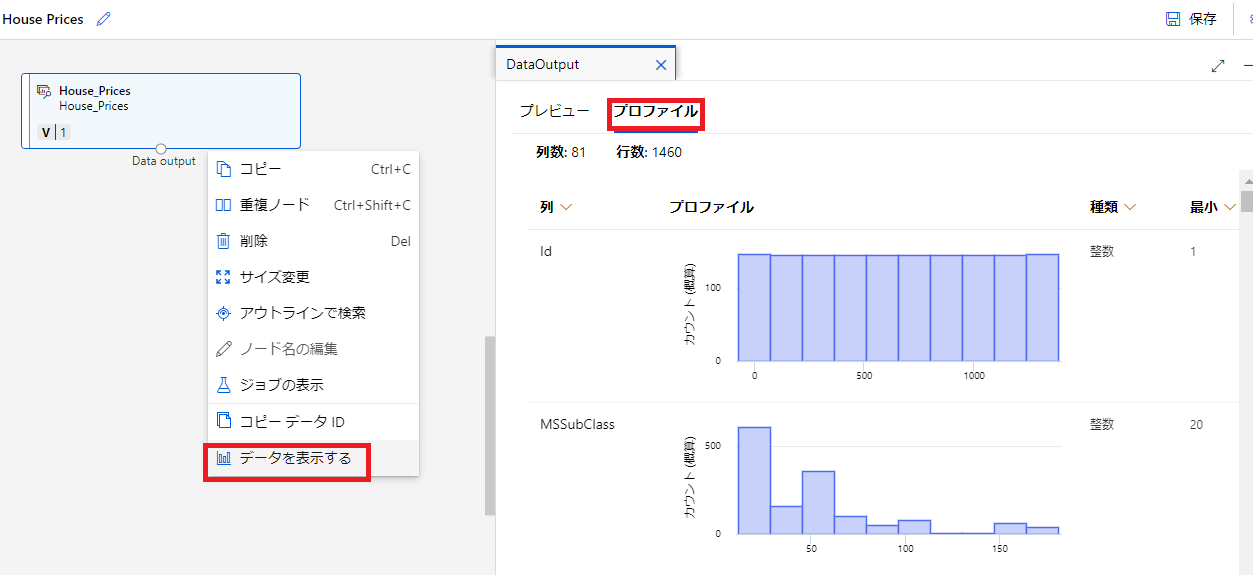
配置した[House_Prices]で右クリックし、[データを表示する]を選択する事で、データの参照や各説明変数の度数をグラフ化したものや最大値、最小値、平均値等を確認する事ができます。
使う説明変数を選択する為、[コンポーネント]タブをクリックし、検索部分から"Select"と入力し、表示されたコンポーネントから[Select Columns in Dataset]をドラッグ&ドロップで画面の中央に移動させます。
移動後、[House_Prices]の〇から[Select Columns in Dataset]の上部の〇へドラッグを行い矢印を連結させます。

[Select Columns in Dataset]をダブルクリックして、右側に表示された項目から[列の編集]をクリックします。
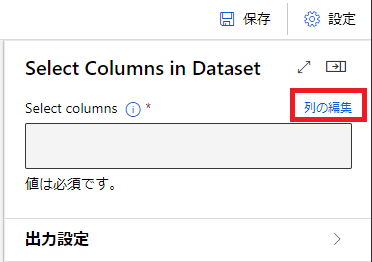
[名前別]を選択し、使用する変数を選択します。
本来は、相関を調べたりする特徴量エンジニアリングで決めていく内容ですが、参考までにChatGPTで使うべき変数の内容を聞いてみます。

とりあえず、以下の変数を使ってみることにしました。
LotArea, Neighborhood, OverallQual, YearBuilt, ExterQual, BsmtQual, 1stFlrSF, GrLivArea, BedroomAbvGr, KitchenQual, GarageCars, GarageQual, SalePrice
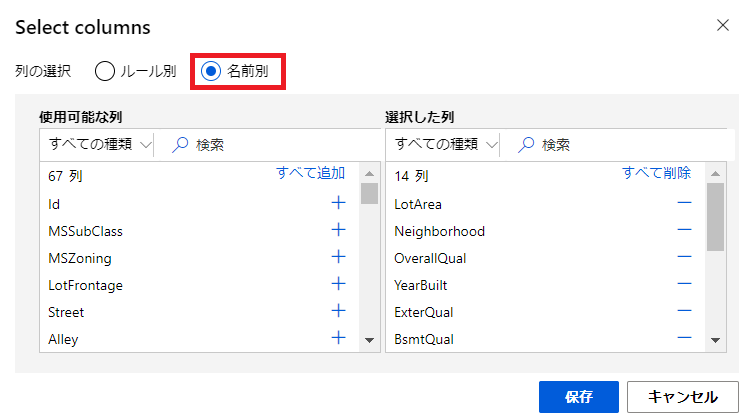
数値データを対数変換する為に[Normalize Data]を利用します。
検索部分から"Normalize"と入力し、表示されたコンポーネントから[Normalize Data]をドラッグ&ドロップで画面の中央に移動させます。
[Select Columns in Dataset]の〇から上部の〇へドラッグを行い矢印を連結させます。

配置した[Normalize Data]をダブルクリックして、右側に表示された項目から以下の内容に変更します。
- Transformation method :LogNormal
- Use 0 for constant columns when checked :True
- 列の編集で、1stFlrSF,GrLivArea,LotAreaを指定
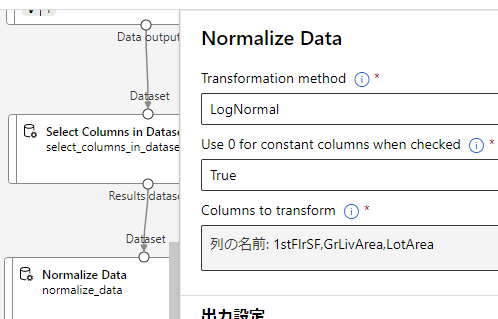
学習と検証用にデータ分割する為に[Split Data]を利用します。
検索部分から"Split"と入力し、表示されたコンポーネントから[Split Data]をドラッグ&ドロップで画面の中央に移動させます。
[Normalize Data]の〇から上部の〇へドラッグを行い矢印を連結させます。

画面中央の[Split Data]をクリックして、データ分割の為の設定を入力します。
以下の値を使用します。
- Splitting mode :Split Rows
- Fraction of rows.:0.7
- Randomized split :True
- Random seed :123
- Stratified split :False
次に[Train Model]モジュールをドラッグ&ドロップで画面の中央に移動させ、[Split Data]の左側と[Train Model]の右側を連結します。
連結後、[Train Model]モジュールをクリックし、[列の編集]から予測したい列である[SalePrice]を指定します。
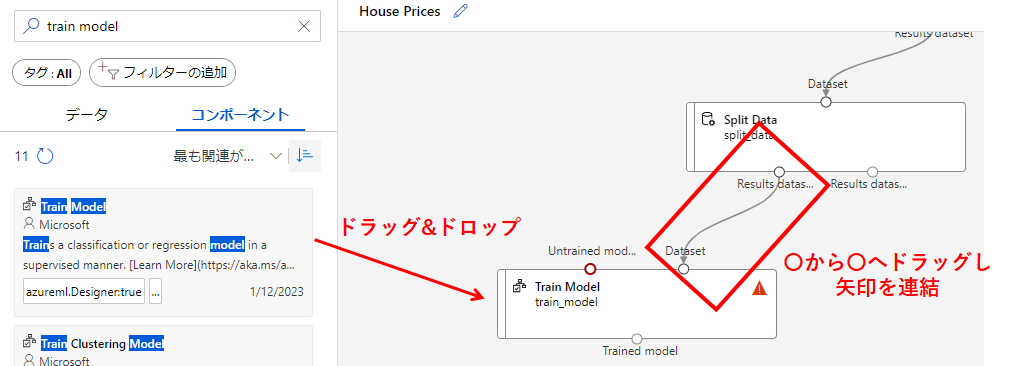

[Train Model]モジュールの上側の左へ[Boosted Decision Tree Regression]モジュールを連結します

データ学習後に[Split Data]で分割された検証用データでモデルの精度を確認する為、
[Score Model]コンポーネントをドラッグ&ドロップで画面の中央に移動させ、左側と[Train Model]を連結さて、右側に[Split Data]を連結します。
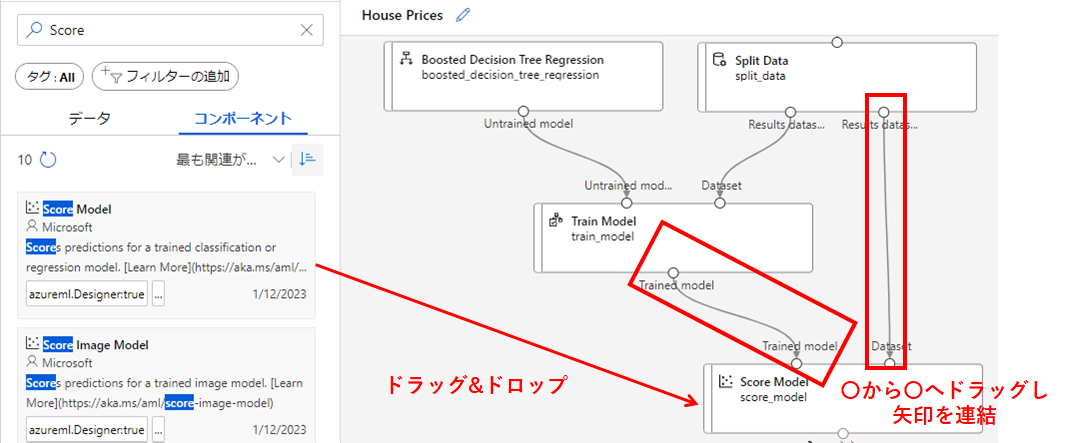
5-4. モデルの評価部分の構築
[Evaluate Model]コンポーネントをドラッグ&ドロップで画面の中央に移動させ、左側と[Score Model]を連結させます。
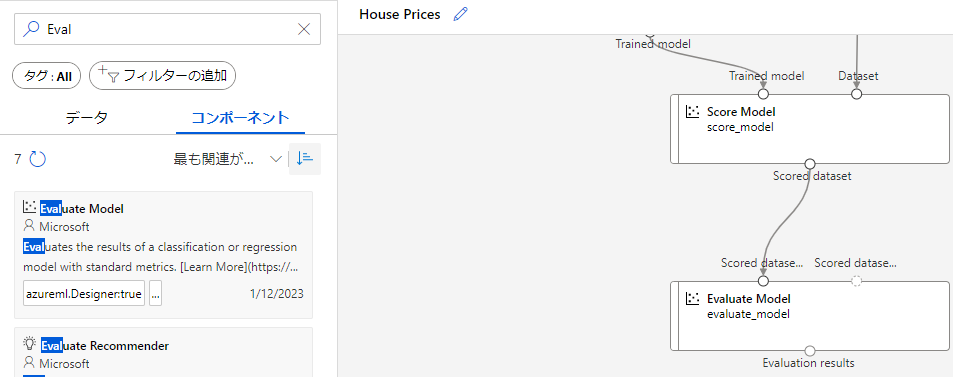
6. MLパイプラインの実行
画面右上の[▷送信]をクリックします。

表示された画面で[新規作成]を選択し、実験名を入力して[送信]をクリックします。

画面左側に[ジョブの詳細]というリンクが表示されるので、クリックします。
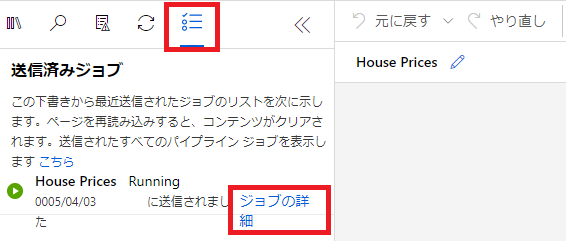
完了したコンポーネントは緑色のチェックが表示されます。

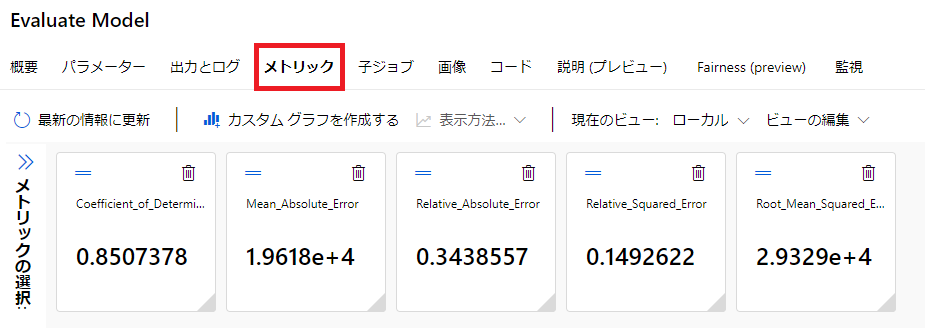
[Evaluate Model]コンポーネントダブルクリックし、画面右側で[出力とログ]タブのグラフボタンを選択することで、評価指標を確認する事ができます。


[メトリック]タブからも決定係数(Coefficient_of_Determination)の値等が確認できます。
ここまでエラー無く完了すると、学習パイプラインの作成は完了となります。
参考及びリンク
Azure Machine Learning デザイナーのアルゴリズムとコンポーネントのリファレンス
チュートリアル: デザイナー - コードなし回帰モデルをトレーニングする