はじめに
SnapMirrorは、NetApp社の提供するStorageであるONTAPのデータ保護技術の一部で、データのレプリケーション機能になります。SnapMirrorを使用すると、データセンター、リモートオフィス、およびラウド環境間でデータを効率的に移動および管理できます。
ONTAPのCluster間におけるSnapMirrorを実施する際には、Replication用のデータ転送に利用するInterCluster LIF作成が必要になりますが、本記事ではVolumeの配置によるSnapMirrorで利用されるLIFの違いについて記載致します。
なお、SnapMirror利用時のベストプラクティスはSnapMirror configuration and best practices guide for ONTAP 9を参照下さい。

何をしたい?できる?
- SnapMirrorの転送時における利用LIFの確認
- 一部のIntercluster LIF間の通信障害時における対応方法の確認
転送時はどんな動作?
- Destination(DR)側から、Source側のマスタDBのいるNodeのIntercluster LIFと通信
- Volumeを構成するAggregateを管理しているNodeのIntercluster LIFから転送

転送の成功する条件は2つという事?
-
Volumeを構成するAggregateを管理しているNodeのIntercluster LIFから転送で成功
(管理用のマスタDBのNode配置には依存しない)
記事における環境情報
本記事では、以下の環境で実施した内容となります。
- ONTAP : 9.13.1
本記事では、既にSnapMirrorが構築されている環境を前提としています。
環境のイメージとしては以下の通り
Source(本番) Cluster01側 => Destination(DR) Cluster02側という方向で転送します。
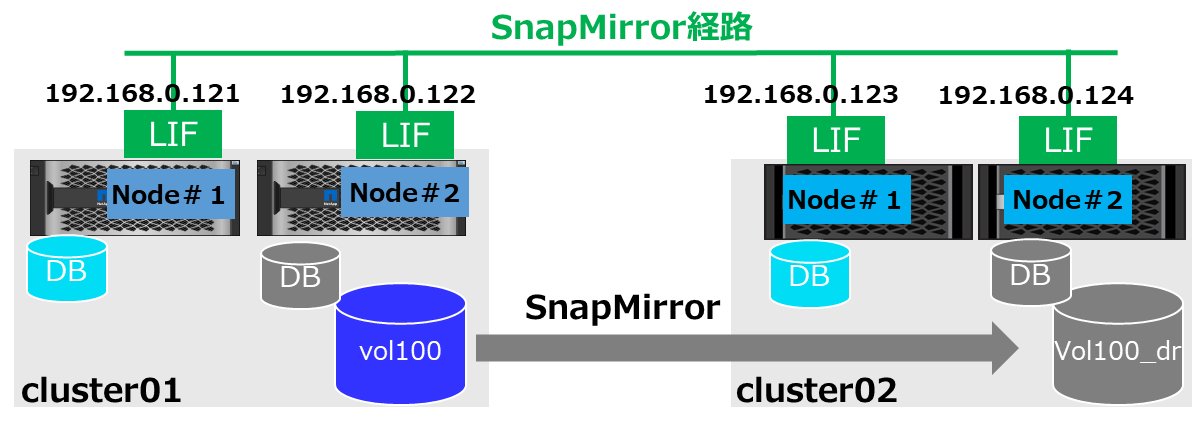
SnapMirrorの実行時の挙動確認
以下の環境おけるSnapMirror転送の実行時におけるパケットキャプチャを実施します。
SnapMirror環境は構築済の前提となります。
まず、設定されているIP、利用するPort、管理DBの状態、SnapMirrorの状態を確認します。
1. 環境の確認
# Cluster#1側の状態
> network interface show -service-policy default-intercluster
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- ------- ----
cluster1
intercluster_1
up/up 192.168.0.121/24 cluster1-01 e0e true
intercluster_2
up/up 192.168.0.122/24 cluster1-02 e0e true
2 entries were displayed.
> set advanced
Warning: These advanced commands are potentially dangerous; use them only when directed to do so by NetApp personnel.
Do you want to continue? {y|n}: y
*> cluster ring show
Node UnitName Epoch DB Epoch DB Trnxs Master Online
--------- -------- -------- -------- -------- --------- ---------
cluster1-01 mgmt 8 8 2115 cluster1-01 master
cluster1-01 vldb 8 8 16 cluster1-01 master
cluster1-01 vifmgr 8 8 39 cluster1-01 master
cluster1-01 bcomd 8 8 25 cluster1-01 master
cluster1-01 crs 8 8 1 cluster1-01 master
cluster1-02 mgmt 8 8 2115 cluster1-01 secondary
cluster1-02 vldb 8 8 16 cluster1-01 secondary
cluster1-02 vifmgr 8 8 39 cluster1-01 secondary
cluster1-02 bcomd 8 8 25 cluster1-01 secondary
cluster1-02 crs 8 8 1 cluster1-01 secondary
10 entries were displayed.
*> vol show -volume vol100
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
svm01 vol100 node2_aggr1 online RW 10GB 9.50GB 0%
# Cluster#2側の状態
> network interface show -service-policy default-intercluster
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- ------- ----
cluster2
intercluster_1
up/up 192.168.0.123/24 cluster2-01 e0d true
intercluster_2
up/up 192.168.0.124/24 cluster2-02 e0d true
2 entries were displayed.
> set advanced
Warning: These advanced commands are potentially dangerous; use them only when directed to do so by NetApp personnel.
Do you want to continue? {y|n}:
> cluster ring show
Node UnitName Epoch DB Epoch DB Trnxs Master Online
--------- -------- -------- -------- -------- --------- ---------
cluster2-01 mgmt 8 8 2516 cluster2-01 master
cluster2-01 vldb 8 8 27 cluster2-01 master
cluster2-01 vifmgr 8 8 49 cluster2-01 master
cluster2-01 bcomd 8 8 13 cluster2-01 master
cluster2-01 crs 8 8 1 cluster2-01 master
cluster2-02 mgmt 8 8 2516 cluster2-01 secondary
cluster2-02 vldb 8 8 27 cluster2-01 secondary
cluster2-02 vifmgr 8 8 49 cluster2-01 secondary
cluster2-02 bcomd 8 8 13 cluster2-01 secondary
cluster2-02 crs 8 8 1 cluster2-01 secondary
10 entries were displayed.
*> vol show -volume vol100_dr
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
svm01_dr vol100_dr node2_aggr1 online DP 10GB 10.00GB 0%
*> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
svm01:vol100 XDP svm01_dr:vol100_dr Snapmirrored Idle - true -
2. パケットキャプチャ取得
取得の流れとしては以下の順に実施します。
- Cluster2側でパケットキャプチャの開始
- Cluster2側でSnapMirrorのUpdate
- Cluster2側でパケットキャプチャの停止
2-1. パケットキャプチャ取得開始
ONTAP9.10以降からnetwork tcpdumpコマンドはDiagモードで利用可能です。
# キャプチャの取得
*> set diag
Warning: These diagnostic commands are for use by NetApp personnel only.
Do you want to continue? {y|n}: y
*> network trace start -node cluster2-02 -port e0d
Info: Started network trace on interface "e0d"
Warning: Snapshots should be temporarily disabled on the root volume while packet traces are occurring. Use the
"node run -node cluster2-02 vol options vol0 nosnap on" command to disable Snapshots on the root volume.
2-2. SnapMirrorの更新
*> snapmirror update -destination-path svm01_dr:vol100_dr
Operation is queued: snapmirror update of destination "svm01_dr:vol100_dr".
*> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
svm01:vol100 XDP svm01_dr:vol100_dr Snapmirrored Finalizing 21.09KB true 02/13 06:23:21
*> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
svm01:vol100 XDP svm01_dr:vol100_dr Snapmirrored Idle - true -
2-3. パケットキャプチャ取得停止
*> network trace stop -node cluster2-02 -port e0d
Info: Stopped network trace on interface "e0d"
3. パケットキャプチャFileのダウンロード
ONTAPではService Processor Infrastructure (spi) がデフォルトで有効化されているので
こちらを利用してFileを取得する事ができます。
Webブラウザを利用して、Nodeに格納されたパケットキャプチャFileをダウンロードする為、
https://Cluster管理LIFのIP/spi
へアクセスを行います。

対象Nodeのlogsをクリックし、packet_tracesディレクトリの中にあるファイルをダウンロードします。

4. パケットキャプチャFileの確認
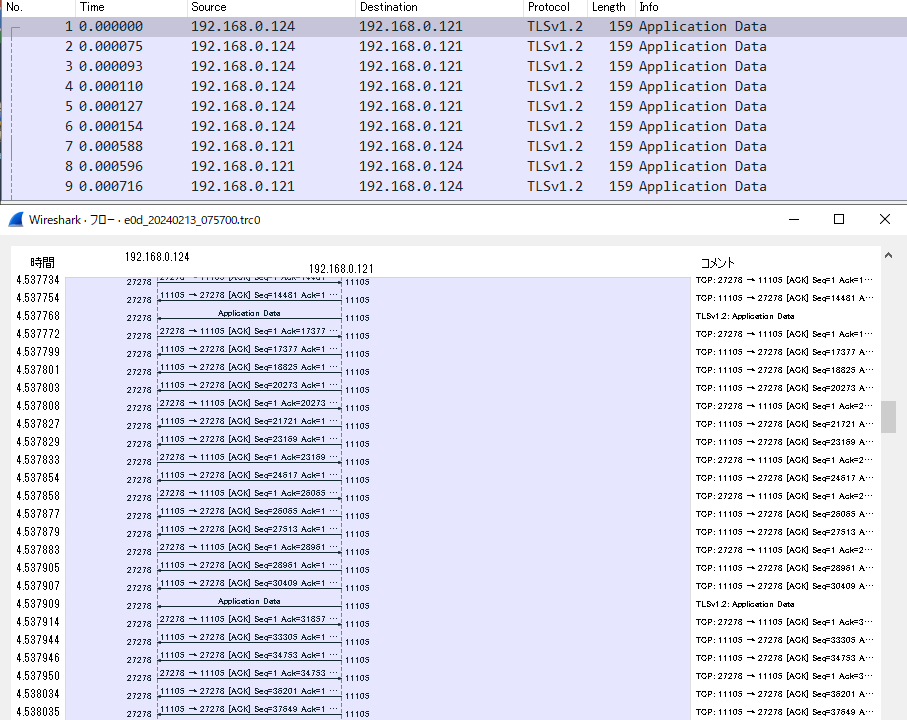
WireShark等で取得したパケットを確認すると、下図の赤いLIFの通信のみ発生している事が確認できます。

WireShark利用時は、[統計]->[フローグラフ]で確認すると見やすいかと思います。
(192.168.0.124から、192.168.0.121の通信の後に192.168.0.122との通信が確認できる)

5. Volumeの管理Nodeを変えての通信確認
さらに
- Volume moveで、Source volumeをのNode1の管理Aggreagteに移動
-
利用しないCluster1のNode2のLIFはDownさせる
といった状態でSnapMirrorを更新すると、経路は以下のような形で更新は成功します。
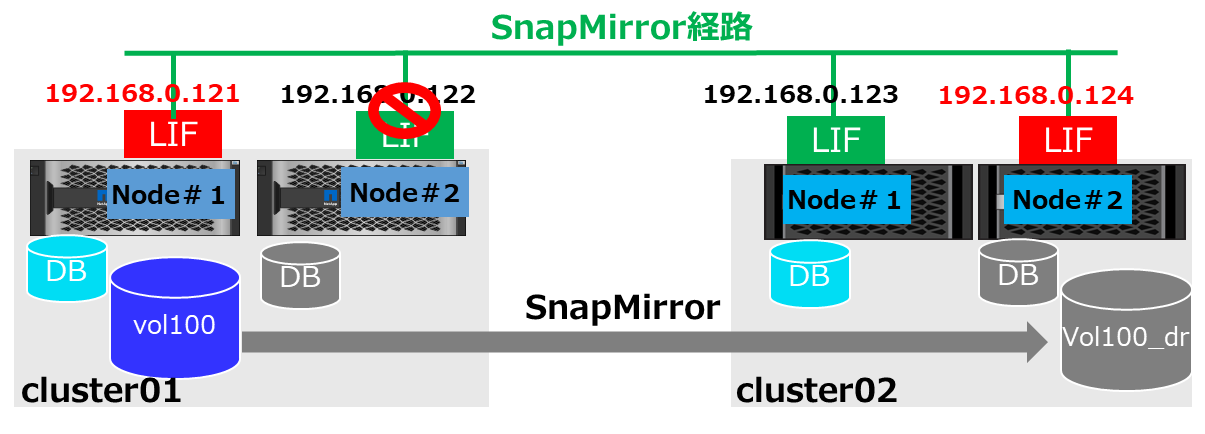
5-1. Cluster1側の状態確認
# Cluster1側の状態
*> net int show -service-policy default-intercluster
(network interface show)
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- ------- ----
cluster1
intercluster_1 up/up 192.168.0.121/24 cluster1-01 e0e true
intercluster_2 down/down 192.168.0.122/24 cluster1-02 e0e true
*> vol show -vserver svm01
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
svm01 svm1_root node2_aggr1 online RW 20MB 17.70MB 6%
svm01 vol100 node1_aggr1 online RW 10GB 9.50GB 0%
2 entries were displayed.
5-2. パケットキャプチャの取得とSnapMirrorの更新
*> network trace start -node cluster2-02 -port e0d
Info: Started network trace on interface "e0d"
Warning: Snapshots should be temporarily disabled on the root volume while packet traces are occurring. Use the
"node run -node cluster2-02 vol options vol0 nosnap on" command to disable Snapshots on the root volume.
*> snapmirror update -destination-path svm01_dr:vol100_dr
Operation is queued: snapmirror update of destination "svm01_dr:vol100_dr".
*> network trace stop -node cluster2-02 -port e0d
Info: Stopped network trace on interface "e0d"
5-3. パケットキャプチャの確認
パケットキャプチャの確認を行うと、図で記載していたような192.168.0.124と192.168.0.121の通信のみ確認することができます。
Volumeを保持しているNodeのLIFが疎通できない場合
上記と殆ど同じ構成で、Node1のLIFで通信ができないとSnapMirrorのUpdateは失敗します。

# Cluster1の確認
*> cluster ring show
Node UnitName Epoch DB Epoch DB Trnxs Master Online
--------- -------- -------- -------- -------- --------- ---------
cluster1-01 mgmt 9 9 422 cluster1-02 secondary
cluster1-01 vldb 9 9 25 cluster1-02 secondary
cluster1-01 vifmgr 9 9 38 cluster1-02 secondary
cluster1-01 bcomd 9 9 12 cluster1-02 secondary
cluster1-01 crs 9 9 1 cluster1-02 secondary
cluster1-02 mgmt 9 9 422 cluster1-02 master
cluster1-02 vldb 9 9 25 cluster1-02 master
cluster1-02 vifmgr 9 9 38 cluster1-02 master
cluster1-02 bcomd 9 9 12 cluster1-02 master
cluster1-02 crs 9 9 1 cluster1-02 master
*> network interface show -service-policy default-intercluster
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- ------- ----
cluster1
intercluster_1 down/down 192.168.0.121/24 cluster1-01 e0e true
intercluster_2 up/up 192.168.0.122/24 cluster1-02 e0e true
2 entries were displayed.
*> volume show -vserver svm01
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
svm01 svm1_root node2_aggr1 online RW 20MB 17.50MB 7%
svm01 vol100 node1_aggr1 online RW 10GB 9.50GB 0%
2 entries were displayed.
# Cluster2の確認
> volume show -vserver svm01_dr
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
svm01_dr svm01_dr_root
node2_aggr1 online RW 20MB 18.37MB 3%
svm01_dr vol100_dr node2_aggr1 online DP 10GB 9.92GB 0%
2 entries were displayed.
SnapMirrorのUpdateを実行しても、Transferring状態まま暫く固まり、その後falseとなります。
# Cluster2の操作
> snapmirror update -destination-path svm01_dr:vol100_dr
Operation is queued: snapmirror update of destination "svm01_dr:vol100_dr".
> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
svm01:vol100
XDP svm01_dr:vol100_dr
Snapmirrored
Transferring 0B true 02/14 03:22:14
> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
svm01:vol100
XDP svm01_dr:vol100_dr
Snapmirrored
Idle - false -
MasterDB側のNodeのLIFが疎通できない場合
上記と殆ど同じ構成で、Takeover等が発生してMaster DBのNodeがNode2になっている場合は、Node2のLIFで通信ができなくてもSnapMirrorのUpdateは成功します。

# Cluster1の確認
*> cluster ring show
Node UnitName Epoch DB Epoch DB Trnxs Master Online
--------- -------- -------- -------- -------- --------- ---------
cluster1-01 mgmt 9 9 422 cluster1-02 secondary
cluster1-01 vldb 9 9 25 cluster1-02 secondary
cluster1-01 vifmgr 9 9 38 cluster1-02 secondary
cluster1-01 bcomd 9 9 12 cluster1-02 secondary
cluster1-01 crs 9 9 1 cluster1-02 secondary
cluster1-02 mgmt 9 9 422 cluster1-02 master
cluster1-02 vldb 9 9 25 cluster1-02 master
cluster1-02 vifmgr 9 9 38 cluster1-02 master
cluster1-02 bcomd 9 9 12 cluster1-02 master
cluster1-02 crs 9 9 1 cluster1-02 master
*> net int modify -vserver cluster1 -lif intercluster_2 -status-admin down
(network interface modify)
Warning: Disabling LIF "intercluster_2" on system Vserver "cluster1" could
interrupt services required for proper cluster operation. Are you sure
you want to continue? {y|n}: y
*> network interface show -service-policy default-intercluster
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- ------- ----
cluster1
intercluster_1 up/up 192.168.0.121/24 cluster1-01 e0e true
intercluster_2 down/down 192.168.0.122/24 cluster1-02 e0e true
2 entries were displayed.
# Cluster2の操作
> snapmirror update -destination-path svm01_dr:vol100_dr
Operation is queued: snapmirror update of destination "svm01_dr:vol100_dr".
> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
svm01:vol100
XDP svm01_dr:vol100_dr
Snapmirrored
Finalizing 0B true 02/14 03:50:48
> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
svm01:vol100
XDP svm01_dr:vol100_dr
Snapmirrored
Idle - true -
パケットキャプチャでも疎通できないLIFは使わずにデータ転送している事が確認できます。

1NodeにIntercluster LIFが複数ある場合の転送
次に、1Nodeに複数のIntercluster LIFがある場合のパケットキャプチャになりますが
Volumeの管理しているNode上で設定されているLIFを全て利用して転送を実施します。

# Cluster1の確認
*> net int show -service-policy default-intercluster (network interface show)
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- ------- ----
cluster1
intercluster_1 up/up 192.168.0.121/24 cluster1-01 e0e true
intercluster_2 up/up 192.168.0.122/24 cluster1-02 e0e true
test up/up 192.168.0.190/24 cluster1-01 e0f true
3 entries were displayed.
*> vol show -volume vol100 Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
svm01 vol100 node1_aggr1 online RW 10GB 9.50GB 0%
# Cluster2の確認
*> cluster peer show -fields ip-addrs
cluster ip-addrs
-------- -----------------------------------------
cluster1 192.168.0.121,192.168.0.190,192.168.0.122
SnapMirror Update時のパケットは以下の通りです。
疎通確認の為、192.168.0.122も混在していますが、大きいサイズのデータは以下の2経路を利用しているのが確認できます。
- 192.168.0.190==>192.168.0.123
- 192.168.0.121==>192.168.0.123

SnapMirror転送中のNetwork障害時の挙動について
今までの挙動から、SnapMirror転送中にNetwork障害でAbortした場合に、Volume Moveで生きているLIFのあるNodeに移動すると転送が途中から再開されるのか? という疑問が出てくるかと思いますが、Volume Moveの制約で障害箇所によって対応が異なります。
Vol MoveはSnapMirror転送がAbort中でもsource側Volumeであれば特に問題無く動きますが、Destination側関しては、vol moveを実行してもMirrorの転送完了後にvol moveが動き出す形になります。(マニュアルにも記載があります)
以下のような想定で実際に動作を確認してみます。
- Source VolumeはNode2で管理
- Destination VolumeはNode1で管理
- 転送途中でSnapMirrorのAbort
- Source側のNode2のIPを通信できないIPに変更
- Source側のVolume Moveを実施後に転送の再開
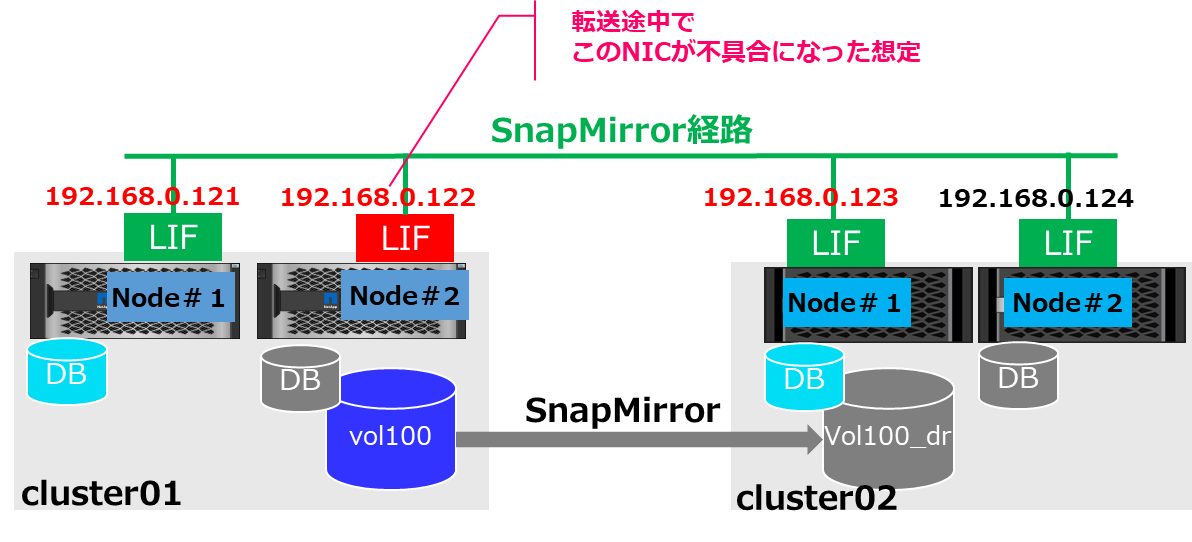
環境の確認
Sourceの約80MBの更新を転送する形になります。
# Cluster1の確認
*> df -h vol100
Filesystem total used avail capacity Mounted on Vserver
/vol/vol100/ 9728MB 83MB 9644MB 0% /vol100 svm01
/vol/vol100/.snapshot 512MB 1896KB 510MB 0% /vol100/.snapshot svm01
2 entries were displayed.
SnapMirrorの更新転送中にAbort
データが全部転送されていない事を確認します。
# Cluster2側で操作
*> snapmirror update -destination-path svm01_dr:vol100_dr
Operation is queued: snapmirror update of destination "svm01_dr:vol100_dr".
::*> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
svm01:vol100 XDP svm01_dr:vol100_dr Snapmirrored Transferring 12.66MB true 02/13 10:16:14
# 転送途中でAbort操作
::*> snapmirror abort -destination-path svm01_dr:vol100_dr
Operation is queued: snapmirror abort for the relationship with destination "svm01_dr:vol100_dr".
:*> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
svm01:vol100 XDP svm01_dr:vol100_dr Snapmirrored Idle - false -
*> snapmirror show -fields total-transfer-bytes
source-path destination-path total-transfer-bytes
------------ ------------------ --------------------
svm01:vol100 svm01_dr:vol100_dr 537700
# Volumeサイズも同じになっていない事の確認
*> df -h -volume vol100_dr
Filesystem total used avail capacity Mounted on Vserver
/vol/vol100_dr/ 10GB 18MB 10221MB 0% --- svm01_dr
/vol/vol100_dr/.snapshot 0B 268KB 0B 0% --- svm01_dr
2 entries were displayed.
Cluster1側のNode2のInstercluster LIFのIP変更
疑似障害を起こす為に、通信できないセグメントのIPに変更します。
(Link UPしているけど通信できない状態を作る)
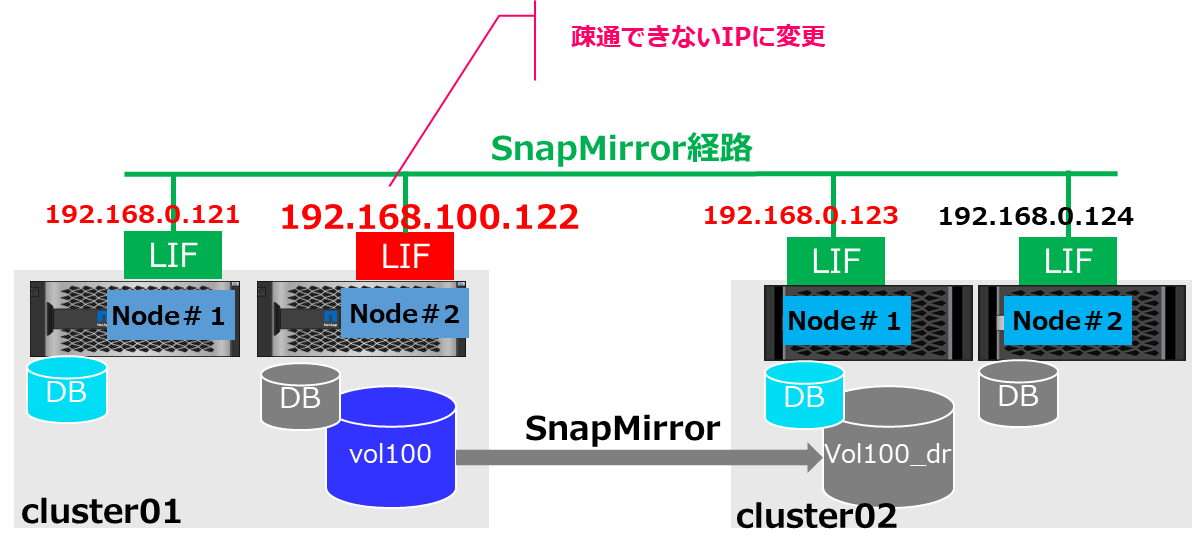
# Cluster1の操作
*> net int show -service-policy default-intercluster
(network interface show)
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- ------- ----
cluster1
intercluster_1 up/up 192.168.0.121/24 cluster1-01 e0e true
intercluster_2 up/up 192.168.0.122/24 cluster1-02 e0e true
2 entries were displayed.
*> net int modify -vserver cluster1 -lif intercluster_2 -address 192.168.100.122
(network interface modify)
::*> net int show -service-policy default-intercluster
(network interface show)
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- ------- ----
cluster1
intercluster_1 up/up 192.168.0.121/24 cluster1-01 e0e true
intercluster_2 up/up 192.168.100.122/24 cluster1-02 e0e true
2 entries were displayed.
クラスタの状態もAvailableからPartialに変更されているのが確認できます。
# Cluster1側の確認
> cluster peer show
Peer Cluster Name Cluster Serial Number Availability Authentication
------------------------- --------------------- -------------- --------------
cluster2 1-80-000011 Partial ok
# Cluster2側の確認
*> cluster peer show
Peer Cluster Name Cluster Serial Number Availability Authentication
------------------------- --------------------- -------------- --------------
cluster1 1-80-000011 Partial ok
Source側のVolume Moveの実行
Source側VolumeをNode1に移動します。

# Cluster1でVolume Moveの実行
*> vol show -volume vol100
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
svm01 vol100 node2_aggr1 online RW 10GB 9.42GB 0%
*> volume move start -vserver svm01 -volume vol100 -destination-aggregate node1_aggr1
Warning: Volume move of the volume "vol100" on Vserver "svm01" will lose cross-volume deduplication savings, if any,
because the destination is a newly-moved volume. Cross-volume deduplication will resume when the volume has
been moved to the destination aggregate.
Do you want to continue? {y|n}: y
[Job 130] Job is queued: Move "vol100" in Vserver "svm01" to aggregate "node1_aggr1". Use the "volume move show -vserver svm01 -volume vol100" command to view the status of this operation.
*> vol show -volume vol100
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
svm01 vol100 node1_aggr1 online RW 10GB 9.42GB 0%
SnapMirrorの更新
転送が再開され、SnapMirror showの状態もHealthyがTrueになっている事が確認できます。
# Cluster2でSnapMirrorのUpdate実行
*> snapmirror update -destination-path svm01_dr:vol100_dr
Operation is queued: snapmirror update of destination "svm01_dr:vol100_dr".
*> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
svm01:vol100 XDP svm01_dr:vol100_dr Snapmirrored Idle - true -
*> snapmirror show -fields total-transfer-bytes
source-path destination-path total-transfer-bytes
------------ ------------------ --------------------
svm01:vol100 svm01_dr:vol100_dr 89001033
*> df -h -volume vol100_dr
Filesystem total used avail capacity Mounted on Vserver
/vol/vol100_dr/ 10GB 84MB 10155MB 0% --- svm01_dr
/vol/vol100_dr/.snapshot 0B 324KB 0B 0% --- svm01_dr
2 entries were displayed.
参考及びリンク
SnapMirror configuration and best practices guide for ONTAP 9
Web ブラウザを使用して、ノードのログファイル、コアダンプファイル、 MIB ファイルにアクセスします