概要
普段MySQLを使用しているが、レスポンスが遅くなって調査することがある。
今回は70,000件のレコードから10件のレコードと結合テーブルを取得したい場合のSQLを調査して改修した内容を記載する。
基本的にはWorkBenchのVisual EXPALNを確認しながら解決していく。
WorkBenchのVisual EXPALN
添付画像の赤色の線を囲った虫眼鏡マークのボタンをクリックすることで確認できる。
通常のEXPLAINよりも図があって見やすいため使用している。

環境
■ MySQLのバージョン
5.7.37
■ Workbenchのバージョン
6.3
テーブル定義
- parents(親テーブル)
- id(主キー)
- index(indexを貼っているカラム)
- created_at
- children(子テーブル)
- id
- parent_id(外部キー)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
parentsテーブルとchildrenテーブルの関係性は「1対多」である。
parentsテーブルには70,000件のレコードが存在しており、その中から10件のレコードを取得する。
※テーブル名は今回の記事に合わせて元々ある名称を分かりやすく変更したものであり、今後出てくるVisual EXPALNの画像では一部テーブル名を書き換えている。
発行しているSQL
parentsテーブルとそれに紐づくchildrenテーブルを10件取得したい。
SELECT
`Parents`.`id`,
`Parents`.`index`,
`Parents`.`created_at`
FROM
`parents` AS `Parents`
LEFT OUTER JOIN `children` AS `Children` ON `Parents`.`id` = `Children`.`parent_id`
ORDER BY
created_at desc
LIMIT
0, 10;
EXPLAIN
上記のSQLでEXPLAINを確認すると、トータルのQuery costが106,317.60かかっている。
また、取得したいparentsテーブルのレコード数は10件であるが、FROM句内で75,000件ほど取得している。

Query costが多くかかっている原因としては以下が考えられる。
①parentsテーブルの取得時にフルテーブルスキャンを使用している。
②parentsテーブルを取得する際に全てのレコードを取得していてcostがかかっている。それに伴いテーブル結合したchildrenテーブルの取得にも90442.8のcostがかかっている。
③ORDER句を使用時にfilesortになっている。
フルテーブルスキャンの回避
フルテーブルスキャンとは
指定された票の全てのデータにアクセスするためデータの取得に時間がかかる。
https://dev.mysql.com/doc/refman/5.6/ja/how-to-avoid-table-scan.html
フルテーブルスキャンを回避する方法は上記サイトに複数記載されているが、今回はindexが設定されたカラムに対してWHERE句を指定して解決する。
本来WHERE句は指定したい条件がある場合に用いるが、今回は「indexが設定されたカラムに対してWHERE句を指定する」ことでフルテーブルスキャンが回避されることを記載したいと思い、上記の解決方法を選択している。
WHERE句を用いる必要がない場合は添付しているMySQL公式に記載されているいくつかの方法で解決していくことが望ましい。
なお、今回の最重要のボトルネックは後述する「取得コードが多すぎる」ことにあるため、必ずしもフルテーブルスキャンを回避する必要はない。
解決方法
parentsテーブルのindexカラムにindexを付与しているのでWHERE句で指定してみる。
SELECT
`Parents`.`id`,
`Parents`.`index`,
`Parents`.`created_at`
FROM
`parents` AS `Parents`
LEFT OUTER JOIN `children` AS `Children` ON `Parents`.`id` = `Children`.`parent_id`
-- 追加
WHERE
`Parents`.`index` = [任意の値]
ORDER BY
created_at desc
LIMIT
0, 10;
EXPLAIN
indexを貼っているindexカラムをWHERE句で指定することで、Query costが減少していることが分かる。(WHERE句で指定したため取得レコード数が減少したことも影響している)
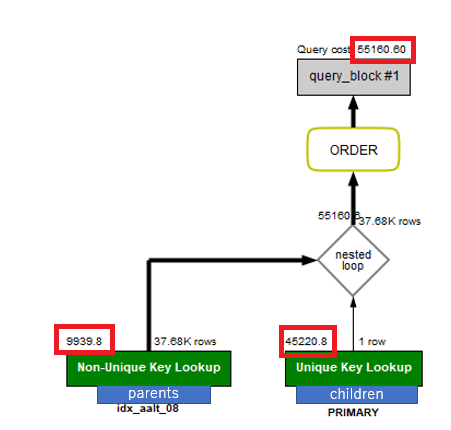
■ parentsテーブルの取得
15,874.8 → 99,939.8
■ childrenテーブルの取得
90,442.8 → 452,20.8
■ Query cost
106,317.60 → 55,160.60
取得コードを絞る
indexを貼ることでコストを現象させることができたが、依然として取得するレコード数も多くQuery costがかかっている。
現状だと、parentsテーブルを全て取得し、childrenテーブルを結合させた上でORDER句を使用しているので時間がかかっている。
サブクエリを発行し、parentsテーブルを必要なレコード数(今回だと10件)取得してから次の処理を実施するようにする。
SELECT
`Parents`.`id`,
`Parents`.`index`,
`Parents`.`created_at`
FROM
(
SELECT
`Parents`.*
FROM
`parents` AS `Parents`
WHERE
`Parents`.`index` = [任意の値]
ORDER BY
created_at desc
LIMIT
0, 10
) AS `Parents`
LEFT OUTER JOIN `children` AS `Children` ON `Parents`.`id` = `Children`.`parent_id`
WHERE
`Parents`.`index` = [任意の値]
ORDER BY
created_at desc;
サブクエリ内でparentsテーブルを10件取得するように変更した。
EXPLAIN
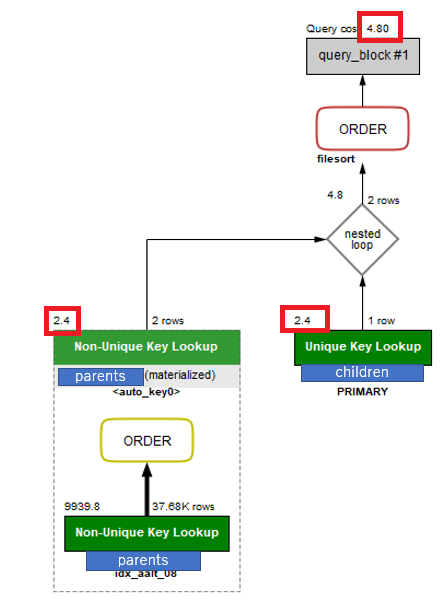
■ parentsテーブルの取得
15,874.8 → 99,939.8 → 2.4
■ childrenテーブルの取得
90,442.8 → 452,20.8 → 2
■ Query cost
106,317.60 → 55,160.60 → 4.80
取得するテーブル数を限定することで大幅にQuery costの削減が可能になった。
メインクエリの以下の構文はサブクエリでも記載しているため不要の様に思われるが、今回のテーブル構成だとサブクエリで取得した表をメインクエリで取得する際に、インデックスが付与されているカラムを指定しないので再度フルテーブルスキャンを使用する。
そのため、メインクエリでもWHERE句を使用している。
WHERE
`Parents`.`index` = [任意の値]
ORDER句のカラムにindexを貼る
filesortとは
ソートにsort_buffer_size以上のメモリ量が必要な場合に実行される。
メモリに入る単位でデータを切り出してクイックソートを行う。
その際にテンポラリファイルを使用する。
MySQL公式にソート時にテンポラリファイルを使用することが記載されている。(以下を参照)
When sorting (ORDER BY or GROUP BY), MySQL normally uses one or two temporary files. The maximum disk space required is determined by the following expression:
私の環境のsort_buffer_sizeは以下である。
SELECT @@GLOBAL.sort_buffer_size;
-- 結果
262144
解決方法
ORDER句で指定したいカラムにindexを貼る。
今回の場合はorder句で指定するカラムをindexカラムをに変更して解消を行った。
EXPLAIN
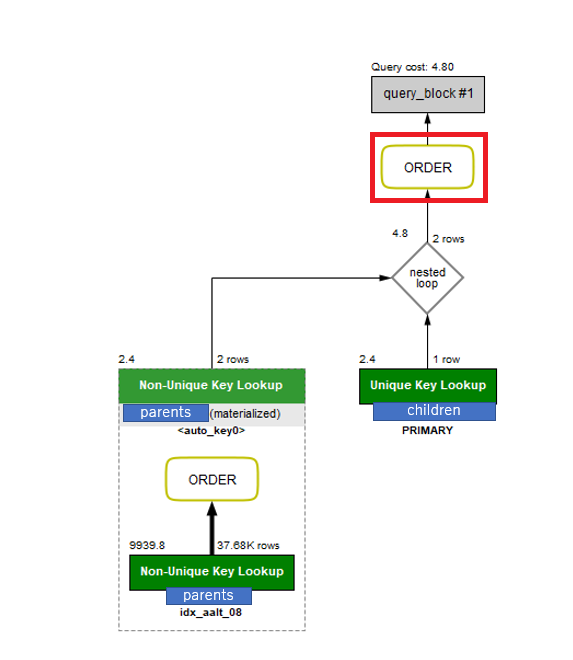
Query costは変わっていないが、filesortがEXPLAINからなくなっていることが確認できる。
Nested Loop Join
3つほど解決方法を記載したが、最重要のボトルネックは取得レコードが多すぎたことである。
今回はNested Loopという結合アルゴリズムが採用されている。
MySQL公式にて、以下のNested Loop Joinのアルゴリズムに関して記載がある。
単純な Nested Loop Join (NLJ) アルゴリズムは、ループ内の最初のテーブルから行を一度に 1 つずつ読み取り、各行を、結合の次のテーブルを処理するネストしたループに渡します。このプロセスは、結合するテーブルが残っている回数だけ繰り返されます。
上記により、駆動表もしくは内部表のレコード数が多ければ多いほどテーブルの結合にコストがかかってしまう。
今回の場合だと、70,000件以上のレコードが駆動表にあったためテーブルの結合にコストがかかりレスポンスが遅くなっていた。
また、Nested Loop Joinのアルゴリズムは以下である。
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions,
send to client
}
}
}
上記を見ると、テーブル結合順番は大きくコストに関わることが分かる。
今回の結合テーブルは1つであったが、複数のテーブルを結合する際はレコード数の多いテーブルは後ろ(上記アルゴリズムの内側)に格納することも効率化につながる。