はじめに
最近流行りの生成AIの活用方法の一つに、「検索拡張生成」Retrieval-Augmented Generation(RAG)と呼ばれる技術があります。LLMを使って回答を作成する際に、最新の情報を出力に反映できなかったり、根拠がなく信頼性に欠ける回答が出力されるハルシネーションという現象が起こってしまうという課題があり、この課題を解決する方法としてRAGが期待されています。今回はそのRAGという技術に触れていきたいと思います。
ベクトル
まずRAGを理解する上でベクトルについて知る必要があります。ベクトルとは、向きと大きさを持つ量です。数学や物理学でよく使われています。具体的には、ベクトルは矢印で表され、矢印の長さが大きさ、矢印の指す方向が向きを示しています。この矢印はある始点から終点への移動を表していると考えることができ、x, yの成分を持つ矢印として、2次元空間に落とし込むことができます。
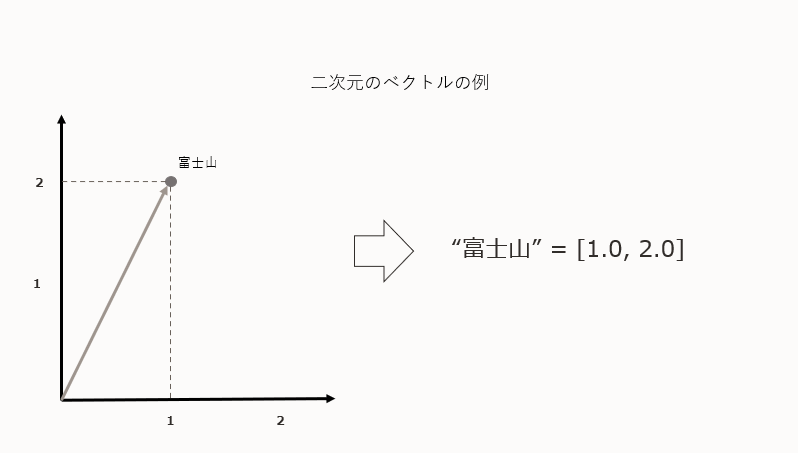
埋め込み (Embedding)
文章や単語をベクトル化することをEmbed(埋め込み)と言います。
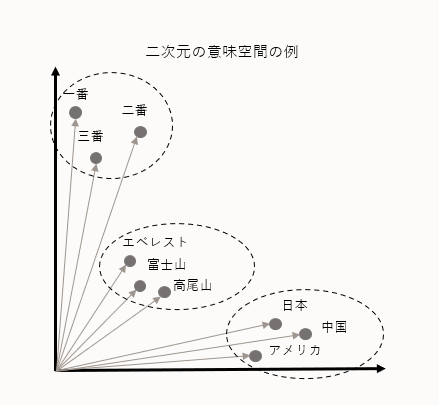
埋め込みとは、システムがテキストや文章などの現実世界のデータを理解するためにベクトル (数値列) で表現したものです。文章をベクトル化することで、文章の意味を計算できるようになります。意味の近い文章は近いベクトルを持ち、意味が反対の文章は遠いベクトルを持ちます。ベクトルを比較することで類似性や相違性を捉えることができます。近しいベクトルを検索することをベクトル検索 (類似度検索) と言います。
埋め込みはデータ内の関係性の発見、センチメント分析、言語翻訳、レコメンドシステムなどに使われます。
Retrieval-Augmented Generation(RAG)
RAGは、類似度検索を使ってテキスト生成に外部ソースの情報検索と組み合わせることで回答精度を高める方法です。
外部ソースとして最新のWeb文章やデータベースの情報を用意し、入力に応じて検索することで出力に反映させることができます。
この方法において、外部ソースを検索する際にテキストや画像などのデータを数値ベクトルで表現し、入力テキストの数値ベクトルとの類似性を計算して検索を行います。これをベクトル検索と言います。
ベクトル検索には、ベクトル化する生成AIとVector Storeと呼ばれるベクトル型のデータを格納できるデータベースを利用します。
今回は、ベクトル化する生成AIとしてOCI Generative AIのEmbedのモデルと、Vector StoreのPineconeを使ってみました。またどちらのサービスもLangChainでサポートされているので、LangChainを使った実装も試してみました。
Pinecone
Pineconeはベクトル型のデータを保存できるベクトルデータベースの1つです。Embedしたデータを保存し、ベクトル検索の結果を高速に出力することができます。
Pineconeのメリットは、フルマネージドなベクトルデータベースである点と大規模なデータセットに対するスケーラビリティが高い点です。フルマネージドサービスなので他のベクトルデータベースと比べてインフラの管理が必要なく運用を簡素化できます。またデータ増加時に自動でリソースをスケールしてくれます。
OCI Generative AI
OCI Generative AIはOracle Cloud Infrastructureのフルマネージドな生成AIのサービスです。2024年3月時点では、CohereとLlama2のモデルが利用できます。
こちらの記事に詳しく書かれています。
OCI Generative AIには3つの機能があります。今回はテキスト埋め込みのモデルを使います。
| 機能名 | モデル |
|---|---|
| テキスト生成 |
cohere.command, cohere.command-light, meta.llama-2-70b-chat
|
| テキスト要約 | cohere.command |
| テキスト埋め込み |
cohere.embed-english-v3.0, cohere.embed-multilingual-v3.0,cohere.embed-english-light-v3.0, cohere.embed-multilingual-light-v3.0
|
前提
Python環境
Oracle Cloud Infrastructureの環境
oci-sdkが利用できる環境
手順
OCI Generative AIとPineconeでVector Searchを試す
1. Pineconeへのログイン
今回はベクトルデータベースとして無料枠のPineconeを利用します。まず以下のURLのPineconeのHPからアカウントを登録します。
ガイドに従い登録すると、OrganizationとProjectが作成されます。
次に、API Keyを取得します。画面左のAPI KeysをクリックするとdefaultのAPI Keyが表示されるのでコピーしておきます。
ここまでがブラウザでの作業です。Python環境でPineconeを操作していきます。(Pineconeの操作はブラウザ画面からでも操作が可能です。)
2. pinecone-clientのインストール
pineconeをJupyter Notebookで使うために、pinecone-clientをインストールします。
!pip install pinecone-client
下記の結果が出力されたらpinecone-clientのインストールが完了しています。
...
Installing collected packages: pinecone-client
Successfully installed pinecone-client-3.1.0
今回使用するライブラリをインスト―ルします。
from pinecone import Pinecone, PodSpec
from dotenv import load_dotenv
import json
import oci
from os import getenv
from oci.generative_ai_inference import GenerativeAiInferenceClient
from oci.generative_ai_inference.models import (
OnDemandServingMode,
EmbedTextDetails,
)
先ほどコピーしたAPI Keyを.envファイルに記載して環境変数を設定します。
PINECONE_API_KEY = getenv('PINECONE_API_KEY')
index_name = "sample-index"
pineconeのclientを作成します。
pc = Pinecone(api_key=PINECONE_API_KEY)
3. Indexの作成
次にIndexを作成します。Indexはベクトルデータベースにおける効率的な検索を行えるようにするデータ構造のことです。Pineconeはデータ量と求めるパフォーマンスに合わせて独自のIndexを構築しています。
pc.create_index(
name=index_name,
dimension=1024,
metric="cosine",
spec=PodSpec(
environment="gcp-starter"
)
)
パラメータはそれぞれ以下のように設定しています。
| Parameters | Contents | Samples |
|---|---|---|
| name | Indexの名前 | "sample-index" |
| demension | 次元数 | 1024 |
| metric | 類似度検索方法 | cosine |
| spec | マネージドサービスのPod情報 | PodSpec |
demensionは、今回OCIのGenerative AI(Cohere社のEmbed用のマルチリンガルモデルembed-multilingual-v3.0)を使用するので、1024の次元数を指定しています。詳細は「生成AIでの事前トレーニング済基盤モデル」のドキュメントをご確認ください。
merticは、類似度検索を方法を指定します。今回はCosine類似度を指定しています。類似度検索についての詳細は「【ChatGPT】マルチモーダルAIのリファレンス実装 ~多様な情報源から一貫性のある結果を引き出す~」の記事を見てみてください。
specは、PodSpecを指定し、environmentとしてgcp-starterというGCP上に作成されるマネージド環境を指定します。無料枠で利用する場合はこの環境のみ利用可能です。
作成したIndexを確認します。
index = pc.Index(index_name)
index.describe_index_stats()
下記のようにIndexが作成されています。
{'dimension': 1024,
'index_fullness': 0.0,
'namespaces': {},
'total_vector_count': 0}
4. テキストのEmbed
次にテキストのEmbedを行います。
まずGenerative AIの環境変数を設定します。
GEN_AI_INFERENCE_ENDPOINT = getenv('GEN_AI_INFERENCE_ENDPOINT')
COMPARTMENT_ID = getenv('COMPARTMENT_ID')
EMBED_MODEL_OCID = getenv('EMBED_MODEL_OCID')
CONFIG_PROFILE = "CHICAGO"
Generative AIのClientなどを作成します。
config = oci.config.from_file('~/.oci/config', CONFIG_PROFILE)
genai = GenerativeAiInferenceClient(
config=config,
service_endpoint=GEN_AI_INFERENCE_ENDPOINT,
retry_strategy=oci.retry.NoneRetryStrategy(),
timeout=(10,240)
)
次に、Embedを行う関数を作成します。
def embed_text(query: list[str]):
response = genai.embed_text(
embed_text_details=EmbedTextDetails(
serving_mode=OnDemandServingMode(
model_id="cohere.embed-multilingual-v3.0"
),
inputs=query,
truncate="NONE",
compartment_id=COMPARTMENT_ID,
is_echo=True
)
)
if not response.status == 200:
raise Exception("Failed to obtain query response.")
return response
| Parameters | Contents | Samples |
|---|---|---|
| serving_mode | オンデマンドか専用クラスターかの提供形態を指定 | OnDemandServingMode |
| inputs | 入力文章 | "text" |
| compartment_id | コンパートメントOCID | ocid1.compartment.oc1..aaaxxx |
| is_echo | Responseに入力文章を含めるか | True/False |
OCI Generative AIのcohere.embed-multilingual-v3.0というモデルを指定します。
次に、sample_data.jsonからデータを読み込みます。今回はサンプルとして10単語を読み込みます。
file_path = './sample_data.json'
with open(file_path, 'r') as file:
data_json = json.load(file)
data = data_json[0]['data']
print(data)
読み込めると以下のような結果が出力されます。
['人工知能は未来の仕事にどのような影響を与えるのでしょうか?', '気候変動は地球上の生態系に深刻な影響を及ぼしています。', ...]
embed_text関数を使用して、ベクトルデータを作成します。10単語をEmbedしてベクトルデータを作成しました。
vector_data = embed_text(data).data
print(vector_data.inputs[0])
print(vector_data.embeddings[0])
以下のようなベクトルデータが出力されます。
人工知能は未来の仕事にどのような影響を与えるのでしょうか?
[-0.008178711, 0.035980225, -0.0004684925, -0.010627747,...]
これでベクトルデータベースに入れるベクトルデータを作成できました。
5. データのUpsert
作成したベクトルデータを、ベクトルデータベースにUpsertします。
for i in range(len(vector_data.inputs)):
index.upsert(
vectors=[
{"id":"vec" + str(i),
"values": vector_data.embeddings[i],
"metadata": {"text": vector_data.inputs[i]}
}],
namespace='sample-namespace'
)
Upsertされるデータは、以下のようなデータです。
{
"id":"vec0",
"values": [-0.008178711, 0.035980225, -0.0004684925, ...],
"metadata": {
"text": "人工知能は未来の仕事にどのような影響を与えるのでしょうか?"
}
}
ベクトルデータをベクトルデータベースにUpsertできました。
6. Vector Search
次に、Upsertしたデータをベクトル検索します。今回は、10個の文章の中から「機械学習」という単語に意味が近しい文章を3つ抽出したいと思います。(「機械学習」に対して類似度検索をします。) まず「機械学習」という単語をベクトル化します。
prompt = ["機械学習"]
embed_response = embed_text(prompt)
print(embed_response.data.embeddings[0])
「機械学習」という単語は以下のようなベクトルで表されます。
[-0.007896423, 0.034332275, -0.019927979, ...]
類似度検索では「機械学習」のベクトルに近しい意味を持つ文章を検索します。今回は近しい意味を判断する手法として、3. Indexの作成で指定した、Cosine類似度を使った検索が行われます。
最も近しい文章を3つ出力させます。
response = index.query(
vector=embed_response.data.embeddings[0],
top_k=3,
include_metadata=True,
# include_values=True,
namespace="sample-namespace"
)
print(response)
以下のような結果が出力されます。
{'matches': [{'id': 'vec0',
'metadata': {'text': '人工知能は未来の仕事にどのような影響を与えるのでしょうか?'},
'score': 0.748560607,
'values': []},
{'id': 'vec7',
'metadata': {'text': 'ディープラーニングは画像認識技術の進化に大きく貢献しています。'},
'score': 0.674403369,
'values': []},
{'id': 'vec4',
'metadata': {'text': '自動運転車の実用化は交通システムにどのような変化をもたらすでしょうか?'},
'score': 0.620764554,
'values': []}],
'namespace': 'sample-namespace',
'usage': {'read_units': 6}}
「機械学習」に対してベクトル検索が行われ、最も関連した文章が3つ出力されています。順番はcosine類似度の結果に基づいて算出されたscore順になっています。
7. LangChainを使った実装
ここまでのVector SearchをLangChainを使って簡単に実装することができます。OCI Generative AIもPineconeもLangChainにサポートされているので、比較的簡単に実装することができます。
まず必要なライブラリをインポートします。
# langchain
from langchain_community.embeddings import OCIGenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
次にEmbedに使うLLMとしてOCI Generative AIを指定する。
# embedding llm
embeddings = OCIGenAIEmbeddings(
model_id=EMBED_MODEL_OCID,
service_endpoint=GEN_AI_INFERENCE_ENDPOINT,
compartment_id=COMPARTMENT_ID,
auth_profile=CONFIG_PROFILE,
)
VectorStoreとしてPineconeを指定する。
# vectorstore
vectorstore = PineconeVectorStore(
index_name=index_name,
embedding=embeddings,
namespace=namespace,
)
ベクトル検索を行い、結果を出力する。
# vectorsearch
query = "機械学習"
vector_search = vectorstore.similarity_search(
query=query,
k=3
)
for i in range(len(vector_search)):
print(vector_search[i].page_content)
以下のような結果が出力されます。
人工知能は未来の仕事にどのような影響を与えるのでしょうか?
ディープラーニングは画像認識技術の進化に大きく貢献しています。
自動運転車の実用化は交通システムにどのような変化をもたらすでしょうか?
先ほどのベクトル検索と同様に「機械学習」と類似度が高い文章が順番に表示されています。LangChainを使うことで少ないコード量でVector Searchを実装できました。
まとめ
OCI Generative AIを使ってEmbedしたデータをPineconeに追加することができました。また入力したデータに対してベクトル検索を行い類似性の高い文章を出力できました。VectorStoreの1つであるPineconeとOCI Generative AIを連携させることができます。またLangChainを使う場合は、どちらもサポートされているので非常に簡単に実装ができました。