はじめに
8/4,8/5の各イベントで触ったAgentCoreや、Strands Agents、S3 Vectorsについて、簡単にまとめてみた記事です。
AI周りの記事はたくさん検証記事があり、私の記事に有益な情報はないかもですが、アウトプットすることで自身が覚えたことを整理したいので、書いてみます!
何をしたか?
S3 Vectorsでベクトルデータベースを構築し、それをBedrock Knowledge Basesに利用することで安価で安全なRAGシステムのPoCをしてみようと思いました。
また、最近流行りのBedrock Agent Coreの一部だけ触ってみたかったので、一部取り入れてみました。
技術のキャッチアップは触ってみるのが一番良いですね!
やってみた!
ということで触ってみます。
ベクトルバケットの作成
作成そのものは名前を設定するだけでした。
料金については以下に記載あります。
どうやら日本語サイトにはまだS3 Vectorsの料金がありませんでした。
https://aws.amazon.com/s3/pricing/?nc1=h_ls
料金が安い分、機能制限があるみたいですがここらの違いはまだ私には分かりません。
社内ドキュメント検索とかに利用できたらと思いますが、実運用に耐えうるんでしょうか??
Bedrock Knowledge Basesと統合
ナレッジベースとして使うには、作成時のステップ3データストレージと処理を設定でAmazon S3 Vectorsを選択するだけです。
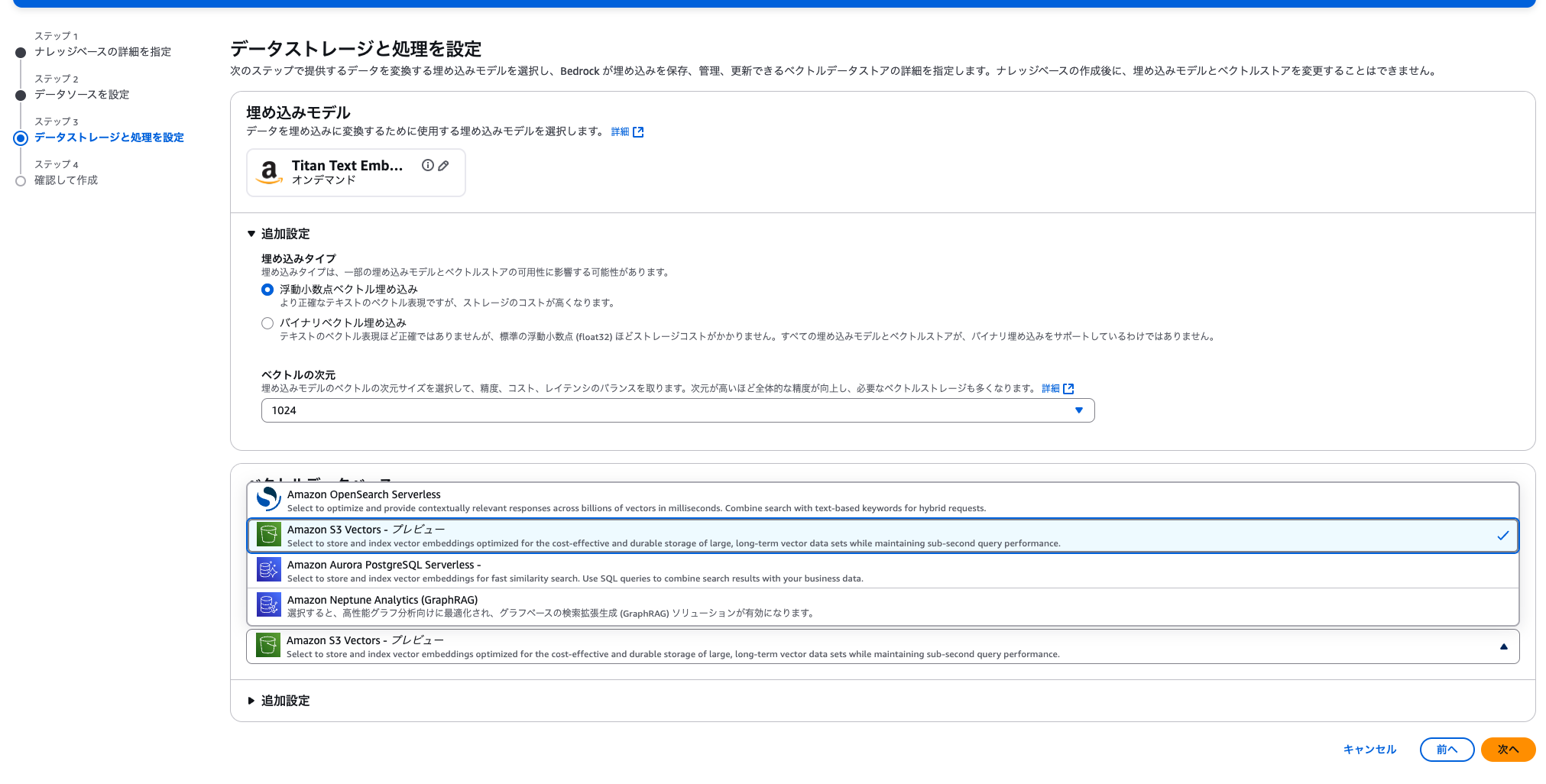
なお、追加設定の埋め込みタイプに関しては、S3 Vectorsを選択する場合、バイナリベクトル埋め込みは利用できない模様です。
なお、今回は以下のIPAの資料を使っています。
軽く動作確認!
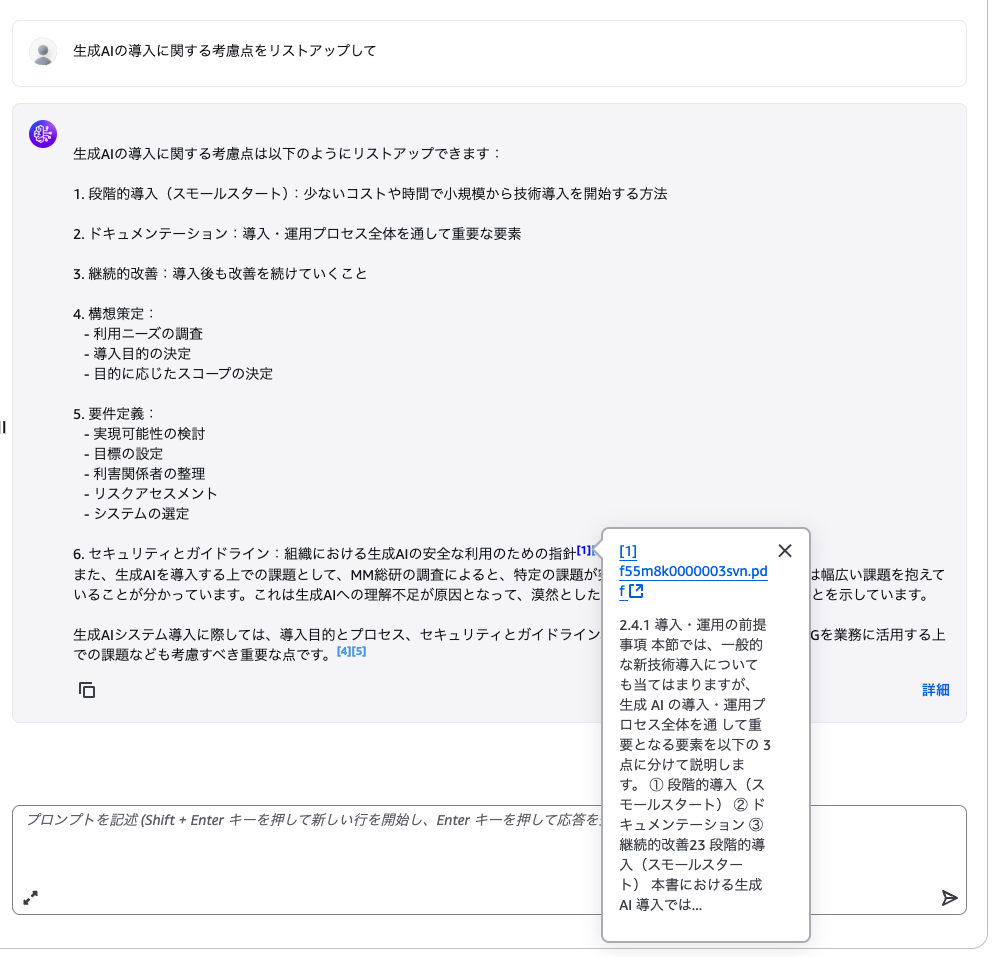
マネコンのナレッジベースのテストから動作確認ができるみたいなのでテストしてみます。
きちんと引用元も確認できたので問題なさそうです。
速度も全く気になりません。
Strands Agentで動作させてみる。
次にStrands Agentsを使ってRAGを使うエージェントを作ってみます。(Claude Codeで。)
@toolで簡単にエージェントが作れるみたいなので、以下みたいな感じにしてみました。
👤 ユーザー → 🤖 エージェント → 🛠️ ツール群 → 📚 Bedrock KB
以下のページが初心者の自分にはとても参考になったので、検索、検索+生成のツールを作ってみました。
Knowlege bases for Amazon Bedrock には RAG としての取り出しに 2 つの API があります。(大昔から触っている方は、耳タコだと思うのですっ飛ばしてもらって構いません。)
- Retrieve API
- RetrieveAndGenerate API
ソース全文はこちら!
# 必要なライブラリをインポート
from dotenv import load_dotenv
from strands import Agent, tool
import boto3
from typing import Dict, List, Optional, Any, Annotated
import json
# .envファイルから環境変数を読み込む
load_dotenv()
# グローバル設定(初期化時に設定)
BEDROCK_CLIENT = None
KNOWLEDGE_BASE_ID = None
MAX_RESULTS = 5
MODEL_ARN = "arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0"
def initialize_bedrock_kb_tool(
knowledge_base_id: str,
region_name: str = "us-west-2",
max_results: int = 5,
model_arn: str = None
):
"""
Bedrockナレッジベースツールを初期化
Args:
knowledge_base_id: BedrockナレッジベースのID
region_name: AWSリージョン
max_results: 検索結果の最大件数
model_arn: 生成に使用するモデルのARN
"""
global BEDROCK_CLIENT, KNOWLEDGE_BASE_ID, MAX_RESULTS, MODEL_ARN
BEDROCK_CLIENT = boto3.client(
'bedrock-agent-runtime',
region_name=region_name
)
KNOWLEDGE_BASE_ID = knowledge_base_id
MAX_RESULTS = max_results
if model_arn:
MODEL_ARN = model_arn
@tool
def search_knowledge_base(query: str, max_results: int = None) -> str:
"""
ナレッジベースから関連する文書を検索します
Args:
query: 検索したい内容のクエリ文字列
max_results: 取得する結果の最大数(デフォルト:5)
Returns:
検索結果のJSON文字列
"""
if not BEDROCK_CLIENT or not KNOWLEDGE_BASE_ID:
return json.dumps({
'success': False,
'error': 'Bedrockナレッジベースツールが初期化されていません。initialize_bedrock_kb_tool()を先に実行してください。',
'results': []
}, ensure_ascii=False)
try:
# Retrieve API を使用してナレッジベースから関連文書を取得
retrieve_params = {
'knowledgeBaseId': KNOWLEDGE_BASE_ID,
'retrievalQuery': {
'text': query
},
'retrievalConfiguration': {
'vectorSearchConfiguration': {
'numberOfResults': max_results or MAX_RESULTS,
'overrideSearchType': 'SEMANTIC'
}
}
}
response = BEDROCK_CLIENT.retrieve(**retrieve_params)
# 結果を整理
results = []
for result in response.get('retrievalResults', []):
results.append({
'content': result.get('content', {}).get('text', ''),
'score': result.get('score', 0),
'location': result.get('location', {}),
'metadata': result.get('metadata', {})
})
return json.dumps({
'success': True,
'query': query,
'results_count': len(results),
'results': results
}, ensure_ascii=False)
except Exception as e:
return json.dumps({
'success': False,
'query': query,
'error': str(e),
'results': []
}, ensure_ascii=False)
@tool
def generate_with_knowledge(query: str, system_prompt: str = None) -> str:
"""
ナレッジベースの情報を使用して質問に対する回答を生成します
Args:
query: 回答を求める質問
system_prompt: システムプロンプト(回答の形式や観点を指定)
Returns:
生成された回答のJSON文字列
"""
if not BEDROCK_CLIENT or not KNOWLEDGE_BASE_ID:
return json.dumps({
'success': False,
'error': 'Bedrockナレッジベースツールが初期化されていません。initialize_bedrock_kb_tool()を先に実行してください。',
'answer': '',
'citations': []
}, ensure_ascii=False)
try:
retrieve_and_generate_params = {
'input': {
'text': query
},
'retrieveAndGenerateConfiguration': {
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': KNOWLEDGE_BASE_ID,
'modelArn': MODEL_ARN,
'retrievalConfiguration': {
'vectorSearchConfiguration': {
'numberOfResults': MAX_RESULTS,
'overrideSearchType': 'SEMANTIC'
}
}
}
}
}
# システムプロンプトがある場合は追加
if system_prompt:
retrieve_and_generate_params['retrieveAndGenerateConfiguration']['knowledgeBaseConfiguration']['generationConfiguration'] = {
'promptTemplate': {
'textPromptTemplate': system_prompt + "\n\nUser question: $query$\n\nContext: $search_results$"
}
}
response = BEDROCK_CLIENT.retrieve_and_generate(**retrieve_and_generate_params)
# 使用されたソース文書を整理
citations = []
if 'citations' in response:
for citation in response['citations']:
for reference in citation.get('retrievedReferences', []):
citations.append({
'content': reference.get('content', {}).get('text', ''),
'location': reference.get('location', {}),
'metadata': reference.get('metadata', {})
})
return json.dumps({
'success': True,
'query': query,
'answer': response.get('output', {}).get('text', ''),
'session_id': response.get('sessionId', ''),
'citations': citations
}, ensure_ascii=False)
except Exception as e:
return json.dumps({
'success': False,
'query': query,
'error': str(e),
'answer': '',
'citations': []
}, ensure_ascii=False)
agent = Agent(
model="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
tools=[
search_knowledge_base,
generate_with_knowledge
]
)
app = BedrockAgentCoreApp()
# エージェント呼び出し関数を、AgentCoreの開始点に設定
@app.entrypoint
def invoke_agent(payload, context):
initialize_bedrock_kb_tool("UQMWFZB6RU")
# リクエストのペイロード(中身)からプロンプトを取得
prompt = payload.get("prompt")
# エージェントを呼び出してレスポンスを返却
return {"result": agent(prompt).message}
# AgentCoreサーバーを起動
app.run()
# initialize_bedrock_kb_tool("UQMWFZB6RU")
# agent("生成AI導入に関する考慮内容を考えて。")
ツール1: search_knowledge_base
指定されたクエリに基づいてナレッジベース内を検索(Retrieve)し、関連性の高い箇所を返してくれるだけのツール。
LLMによる回答生成は行わず、検索結果そのものを返すだけです。
@tool
def search_knowledge_base(query: str, max_results: int = None) -> str:
"""ナレッジベースから関連する文書を検索します"""
try:
# BedrockのRetrieve APIを呼び出し
response = BEDROCK_CLIENT.retrieve(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
retrievalQuery={'text': query},
retrievalConfiguration={
'vectorSearchConfiguration': {
'numberOfResults': max_results or MAX_RESULTS
}
}
)
# 結果をJSON形式で返す
return json.dumps({'success': True, 'results': results}, ensure_ascii=False)
except Exception as e:
# エラー処理
return json.dumps({'success': False, 'error': str(e)}, ensure_ascii=False)
ツール2: generate_with_knowledge
こちらのツールは、検索と生成(Retrieve and Generate)を一度に行うツール。
ナレッジベースから関連情報を検索し、その情報をコンテキストとしてLLMに渡し、質問に対する回答も生成してくれます。
@tool
def generate_with_knowledge(query: str, system_prompt: str = None) -> str:
"""ナレッジベースの情報を使用して質問に対する回答を生成します"""
try:
# BedrockのRetrieveAndGenerate APIを呼び出し
response = BEDROCK_CLIENT.retrieve_and_generate(
input={'text': query},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': KNOWLEDGE_BASE_ID,
'modelArn': MODEL_ARN,
}
}
)
# 生成された回答と引用情報をJSON形式で返す
return json.dumps({'success': True, 'answer': response.get('output', {}).get('text', '')}, ensure_ascii=False)
except Exception as e:
# エラー処理
return json.dumps({'success': False, 'error': str(e)}, ensure_ascii=False)
あとはエージェントにこの2つのツールを使えるように設定してあげるだけですね。
全く初心者でも分かりやすくて良いです!
agent = Agent(
model="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
tools=[
search_knowledge_base,
generate_with_knowledge
]
)
ローカルで動かすとこんな感じです!
きちんと2つのツールを使ってくれてそうです。
@SatoshiMoriyama ➜ /workspaces/strands-agentcore/4_s3vectors (main) $ python agent.py
生成AI導入に関する考慮内容についての情報を検索し、まとめたいと思います。ナレッジベースから関連情報を探してみましょう。
+Tool #1: search_knowledge_base
より詳細な情報を取得するために、生成AIの導入プロセスや考慮すべきリスクについても検索してみましょう。
+Tool #2: search_knowledge_base
生成AIの導入プロセスについても具体的に調べてみましょう。
+Tool #3: search_knowledge_base
収集した情報を元に、生成AI導入に関する考慮内容について包括的な回答を作成しましょう。
+Tool #4: generate_with_knowledge
# 生成AI導入に関する考慮内容
企業が生成AIを導入する際には、様々な側面を考慮する必要があります。以下では、導入プロセス、メリット、リスクとセキュリティの観点から体系的に整理しました。
## 1. 導入プロセス
生成AIの導入は、計画的かつ段階的に進めることが重要です。一般的な導入プロセスは次のステップに分けられます。
・・・略
Bedrock AgentCore Runtimeで動作させてみる。
AgentCoreの説明やデプロイの方法は私も体験させていただいた、みのるんさんのページが最高に分かりやすいです!
ざっくり書くと、BedrockAgentCoreAppの作成と@app.entrypointでエントリポイント指定するだけです。
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
# エージェント呼び出し関数を、AgentCoreの開始点に設定
@app.entrypoint
def invoke_agent(payload, context):
initialize_bedrock_kb_tool("UQMWFZB6RU")
# リクエストのペイロード(中身)からプロンプトを取得
prompt = payload.get("prompt")
# エージェントを呼び出してレスポンスを返却
return {"result": agent(prompt).message}
# AgentCoreサーバーを起動
app.run()
手順はここでは省略しますが、動作確認はローカルで確認後、AWSにデプロイっていう形で確認しました。
デプロイも2つくらいのコマンドで完結します。
ローカルで確認。

マネコン上で確認。
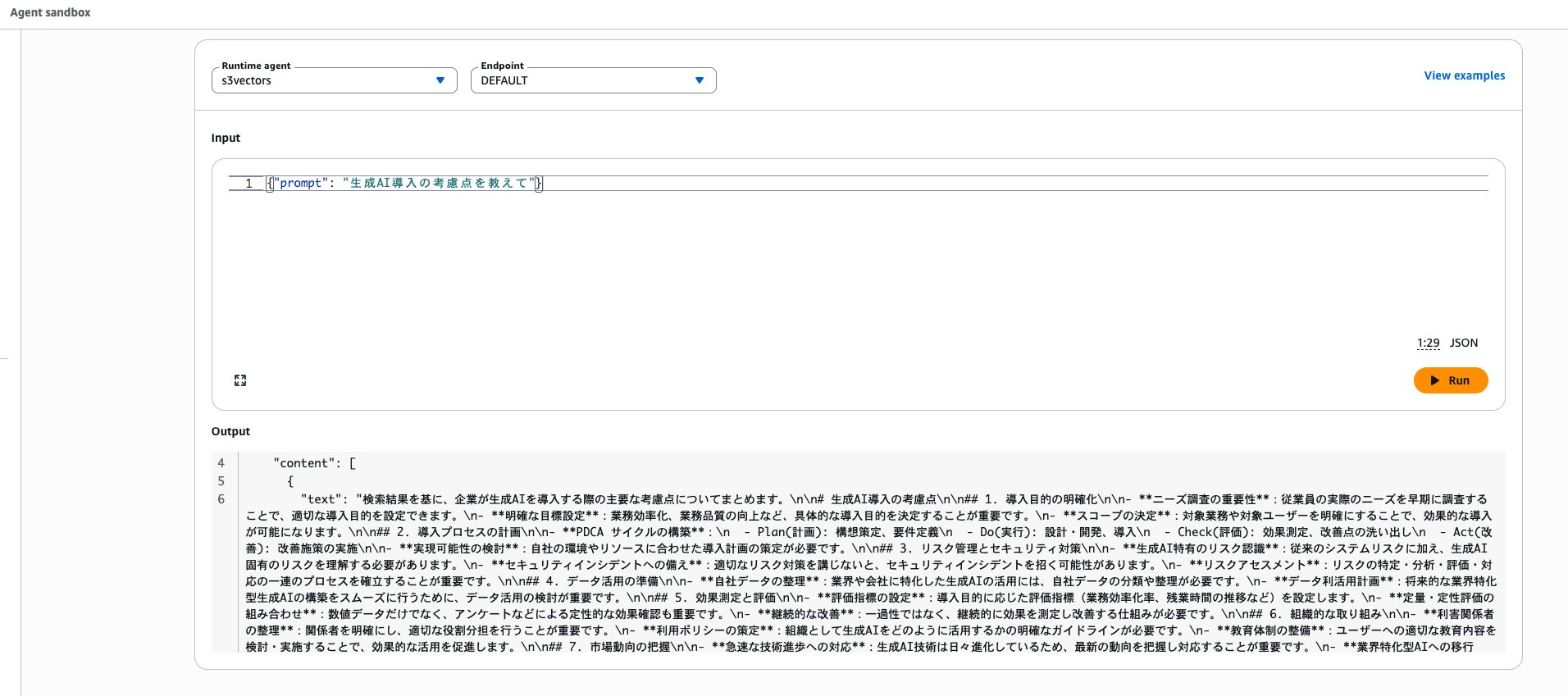
なお、AWS上で動く場合は、AgentCore Runtime側のサービスロールに必要なポリシーを付与する必要がありました。
bedrock-agentcore.amazonaws.comがプリンシパルなんですね。
最後はStreamlitでGUIにしてみる。
これもソースはみのるんさんのページのものをそのまま流用したもので、簡単に動きました。

boto3がすでにAgentCoreに対応しているので、invoke_agent_runtimeを呼び出すだけですね。
最後に
ちょっと長くなりそうなのでだいぶ省きましたが、とても良い経験ができました!
AgentCoreはまだRuntimeを触ったくらいなので、Gateways,Auth(Identity)などの他のビルディングブロックも触ってみたいと思いました。