はじめに
SQL Serverの記事3つめです。
一旦これを最後しますが、最後に記事ではこれまでパフォーマンスチューニングをした際に実際に経験したことなどを書いていきます!
確認環境
今回は以下の環境で検証しています。
- Macbook上にDockerで起動しているSQL Server2022
- 5万件のデータがある簡単なテーブル
ポイント1:キャッシュを意識する。
キャッシュの機能により、同じSQLを複数回実施すると、応答時間が短くなります。
この為、本当の性能を測る際は、キャッシュが残っていない状態で実施する必要があります。
簡単に比較してみました。
キャッシュあり
select * from shain where Id = 4567; -- 複数回実施
総実行時間: 00:00:00.163
キャッシュなし
本番環境では、ワークロードの性能に影響でるので、DBCCコマンドを投入する場合は要注意です!
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
select * from shain where Id = 4567;
総実行時間: 00:00:00.556
2種類のキャッシュ
キャッシュは2種類あります。
プランキャッシュ
SQLを解析・最適化し、実行計画を生成する処理部分のキャッシュ。
DBCC FREEPROCCACHEで削除できます。
データキャッシュ
二次記憶装置(HDD/SSD)から一次記憶装置(メモリ)へキャッシュ。
DBCC DROPCLEANBUFFERSで削除できます。
RDS on SQLServerはDBCC DROPCLEANBUFFERSが利用できません。
https://repost.aws/ja/knowledge-center/rds-sql-server-clear-buffer-cache
大文字小文字のみの差異はキャッシュに影響するのか?
以下のような、大文字小文字のみの差異があるSQLでキャッシュがどうなるか確認してみました。
select * from SHAIN where ID = 4567; -- 全部大文字
select * from shain where id = 4567; -- 全部小文字
私の環境では実行時間の差異は見られませんでした。
ただし、下記のSQLでプランキャッシュを見ると、別々に作られているようです。
select
t.text,
cp.objtype,
qs.execution_count ,
p.query_plan,
qs.sql_handle,
qs.plan_handle
from
sys.dm_exec_query_stats AS qs
outer apply sys.dm_exec_sql_text(sql_handle) AS t
outer apply sys.dm_exec_query_plan(plan_handle) as p
left join sys.dm_exec_cached_plans AS cp
ON cp.plan_handle = qs.plan_handle
where
t.text LIKE'%shain%'
option (recompile)

大文字小文字の違いのみで、異なる実行計画が作成されるわけではないとは思いますが、統計情報が古くなっている等、他の要因と合わせて性能劣化になる原因となるかもしれません。
開発ルールとして、大文字小文字は統一しておく、などのルールを設けても良いかもしれません。
ポイント2:実際発行されているSQLをProfiler確認する。
アプリケーション経由の実施時はSQLの実行が遅いのに、SQLクライアントから手動実行の場合は特に問題なく実行されるというケースが何度かありました。
こういったケースはProfilerを利用し、実際にどのようなSQLが発行されているかを確認する必要があります。
ログイン時に指定するセッションパラメータ
まず、ログイン時に指定する下記パラメータの差異がないかを確認します。
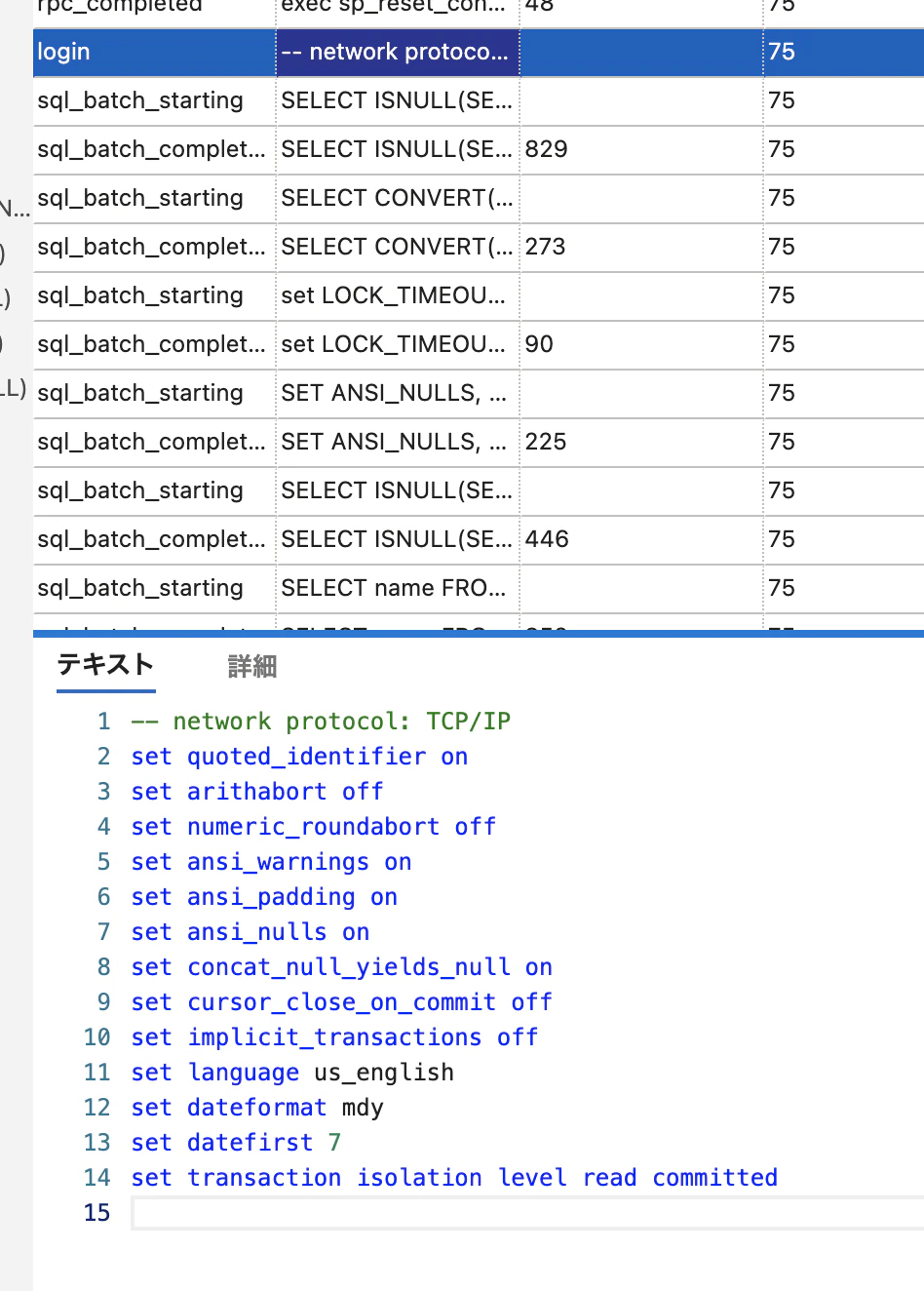
特に、arithabortの差異は要注意です!
下記ページにも注意がある通り、SSMSはこの設定がONになっています。
この差異もプランキャッシュを別々に作る要因となるため、特定の環境のみ再現といった事象の原因になります。
sp_executesql
.net frameworkを利用している場合、SQLはsp_executesqlのSP経由で実施される場合があります。
exec sp_executesql N'SELECT * FROM [SHAIN] WHERE [ID]=@1'
,N'@1 smallint',@1='4567'
これも大文字小文字問題と同様に、実行計画の差異が出る原因となり得ます。
また、その他O/Rマッパーにおいても、暗黙的にトランザクションを掛けたりしているので、Profilerで実際に投入されているSQLを確認することが大切です。
なお、全く同じクエリを投げても、プランキャッシュは別でした。
select * from SHAIN where ID = 4567
exec sp_executesql N'SELECT * FROM [SHAIN] WHERE [ID]=@1'
,N'@1 smallint',@1='4567'

ポイント3:暗黙の変換 (Implicit Conversion)
とても気付きにくい問題ですが、プレースホルダを利用する場合、カラムと値の型を一致させる必要があります。
型変換なし
-- SeiはVARCHAR(20)
DECLARE @Name VARCHAR(20) = 'ono789'
SELECT * FROM Shain WHERE Sei = @name
型変換あり
-- SeiはVARCHAR(20)
DECLARE @Name CHAR(50) = 'ono789'
SELECT * FROM Shain WHERE Sei = @name
型変換によるオーバヘッドや、適切なインデックスが選択されなくなるなどの問題が起き、性能劣化に繋がります。
意図的に変換することはないと思いますが、うっかり変換を行っていた経験かあります。(ソースのコピペ時に型の変更忘れていた、など)
ポイント4:ロックオプション
トランザクション分離レベルがデフォルトのREAD COMMITTEDの場合、以下のような単純なSQLは他のワークロードの更新処理をブロックします。
select * from SHAIN where ID = 4567
ロックする範囲は、Where句と必ず一致するわけではなく、SQLServer側で判別されるため、単純なSelect句の利用には注意が必要です。
WITH(NOLOCK)
この事象を避ける方法ひとつが、with(nolock)の指定です。
select * from SHAIN with(nolock) where ID = 4567
with(nolock)を付与することで、他の更新処理をブロックしないようになります。
一方でダーティーリードになってしまうため、ファントムリード等の問題が顕著化する場合は、下記のSNAPSHOT分離を検討する必要があります。
SNAPSHOT分離
更新処理をブロックしたくない、でもダーティリードもできないといったケースでは、トランザクション分離レベルにSNAPSHOT分離を利用するのが良いです。
SET TRANSACTION ISOLATION LEVEL SNAPSHOT
この分離レベルでは、一時的なデータを保存するtempdbを使い、バージョン管理を行います。
このtempdbを利用することで、トランザクション開始時時点でコミット済みのデータが取得可能になります。
ただし、この方法ではtempdbを利用することによるオーバヘッドが発生するため、注意が必要です。
業務では使ったことがないのですが、ZOZOさんが体験談を書いてくれていたので、紹介します。
ポイント5:統計情報、インデックスのメンテナンス
インデックスの作成は最小限に
インデックスは検索処理を高速にする反面、更新処理ではインデックスの更新が必要となる為、処理劣化します。
特に大量のデータを挿入するようなバッチ処理では、一つのインデックスの追加が大きな性能劣化につながります。
インデックスを追加する必要がでてきた際には、極力既存のインデックスを変更するなど、むやみに増やさないことが大切です。
インデックスの再構築・再編成
データの更新を繰り返し実施すると、インデックスを格納しているディスク領域が断片化し、検索効率が徐々に低下します。
再構築・再構成ともにオンラインで実施可能ですが、一定の負荷はかかります。
パフォーマンスモニタで監視しつつ、影響の少ない時間帯で、定期的に実施するのが良いと思います。
再構築(REBUILD)
インデックス全体を再構築します。
ALTER INDEX [index_name] ON [table_name]
REBUILD WITH (ONLINE = ON);
高負荷かつ、インデックス全体にロックがかかりますが、断片化の割合にかかわらず、一定速度で完了します。
再構成(REORGANIZE)
インデックスのリーフレベルのみを処理対象とします。
ALTER INDEX [index_name] ON [table_name] REORGANIZE;
低負荷で、ロック範囲も限定的ですが、断片化の具合が大きいほど処理が長くなります。
ポイント6:統計情報の更新
統計情報はデータベース内のデータ分布を表す情報で、どのインデックスを利用するかなどの実行計画を作成するために利用されます。
統計情報は最新データを常時反映しているわけではないので、実データの分布と、統計情報に差異がある場合、適切な実行計画が作成されない場合があります。
結果、普段は問題なく動いているSQLが急激に低速になったりします。
統計情報はデータ総数の20%+500レコードが更新されたなどの閾値を超えた段階で自動更新されますが、すべてのデータをサンプリングするのではなく、一部のデータのみでサンプリングされるため、更新はされたけど、以前実データとはかけ離れていることがあるようです。
そのため、インデックスと同様に日次などの周期的なタイミングで、サンプリング率を指定した更新を行うことや、大量のデータを更新するようなバッチ処理の後では手動で統計情報の更新を行うような対応が必要です。
最後に
登壇するために必要な情報整理はいったん終了です!
記載していく中で、曖昧だった部分も理解できたし、勉強になりました。
あとは登壇資料作るのみ!