はじめに
先日のJAWS-UG札幌オンラインもくもく会で触ってみたS3 Tablesについてもう少し触ってみた記事です。
もくもく会では、単純にS3 Tables作ったテーブルをAthenaでクエリしてするだけでしたが、今回はREST API を経由し、Kinesis Firehoseを使って、S3Tablesに操作ログを記録する仕組みを作ってみようと思います。

なお、データ分析系は初心者なので、この記事を元に入門してみました!
S3 Tablesとは?
S3 Tablesは、Amazon Web Services (AWS) が提供するApache Icebergベースのストレージ最適化サービスです。去年のre:Inventにて発表されたサービスで、分析ワークロード向けに設計されています。
低コストかつ、マネージドサービスでとても使いやすいなと感じました。
Icebergの特徴でもある、スキーマ進化、パーティション進化(サービス断なく、スキーマやパーティションを変更でいる機能)等も運用後の変更に強くて良さそうです!
作ってみた!
簡単に順を追って記載していきます。
最終的な資材は以下に格納しています。
S3 Tablesの作成
S3Tablesの作成の前に、AWS分析サービスとの統合をしておく必要があるみたいなので、有効にしておきます。

その後に、テーブルバケットの作成、名前空間の作成と進めていき、AthenaからDDLを流し、テーブルを作ります。
今回は以下のDDLで作ってみました。
CREATE TABLE `my_s3_namespace`.app_activity_logs (
activity_id string,
created_at timestamp,
user_id string,
action_name string,
entity_type string,
entity_id string,
success boolean,
response_time_ms int,
metadata string
)
PARTITIONED BY (day(created_at))
TBLPROPERTIES ('table_type' = 'iceberg');
なお、テーブルを作ると、マネコンにも表示されるようになります。

'PARTITIONED BY'って?
PARTITIONED BYという見慣れない属性がありますが、パーティションはデータを保存する物理ファイルの分割単位で、S3のプレフィックスの作り方みたいな考え方で概ねあってそうです。
今回の場合は、create_atを日単位にまとめてパーティションを区切ることで、日付での範囲検索時に検索範囲を狭めることができ、コスト効率や検索速度の効率を上げることができるみたいです。
Claudeさんに頑張って解析してもらった結果、以下のような形でファイルが格納されているみたいです。
s3://e4236a86-dd2f-4818-zi3m7yiae7gdtjt8nmjm7r183tyrgapn1b--table-s3/
├── data/
│ └── created_at_day=2025-07-26/
│ ├── 00000-1-[UUID].parquet
│ ├── 00001-2-[UUID].parquet
│ └── ...
└── metadata/
├── 00017-54440fa3-2727-43f1-ae22-cefd5d410d52.metadata.json
├── snap-[snapshot-id]-1-[UUID].avro
└── ...
なお、パーティション進化(例えば日単位から月単位に変更した)をした場合は、メタデータを活用し、サービス継続が可能です。
その後自動でファイルが新しいパーティション単位でまとまっていくようです。
kinesiss Firehoseとの統合
以下で説明するリソースリンクの作成は現時点では不要になったみたいです。
参考:
https://dev.classmethod.jp/articles/data-firehose-s3-tables-without-resourcelink/
Firehoseとの統合は以下のページが本当に参考になりました。
複雑すぎて自力では解決できなかったかも。
手順は上記のページの通りですので、簡単に紹介程度ですが、以下の3つの手順を行います。
- Firehose用のサービスロールの作成(Glue,S3,Lake Formation,CloudwatchLogs等の認可付与)
- リソースリンクの作成
- Lake Formatationでリソースリンクへの権限付与
リソースリンクって何?
リソースリンクが複雑なのですが、まず、AWS GlueとLake Formationにおけるカタログ、データベース等のデータ階層は以下のような考え方みたいです。
AWSアカウント
└── カタログ(複数可)
└── データベース/名前空間(複数可)
└── テーブル(複数可)
└── パーティション(複数可)
下記の通り、S3Tablesで作成したデータベースは初期からあるデフォルトカタログとは別のカタログに作成されるため、デフォルトカタログ経由で参照できるためのリソースリンクが必要になるみたいです。
Firehose streams data to the tables in the database registered in the default catalog of the AWS Glue Data Catalog. To stream data to tables in S3 table buckets, create a resource link in the default catalog that points to the namespace in table bucket.
Firehoseは、AWS Glue Data Catalogのデフォルトカタログに登録されたデータベースのテーブルにデータをストリーム送信します。S3テーブルバケット内のテーブルにデータをストリーム送信するには、デフォルトカタログ内にリソースリンクを作成し、そのリンクをテーブルバケット内のネームスペースを指すように設定します。
具体的には以下のようなコマンドでリソースリンクを作成しました。
aws glue create-database --region ap-northeast-1 --catalog-id "<AccountID>" --database-input '{
"Name": "my_rsclink",
"TargetDatabase": {
"CatalogId": "<AccountID>:s3tablescatalog/mori-test-table",
"DatabaseName": "my_s3_namespace"
}
}'
アカウントIDがカタログIDになっているデフォルトカタログの中に、アカウントID:s3tablescatalog/<S3Table名>のカタログのデータベース(名前空間)へのリンクを作っているという内容です。
Lake Formationの権限付与
権限付与はFirehoseのサービスロールが先ほど作ったリソースリンクを参照できるような形で設定しますが、リソースリンク、データベース(名前空間)、テーブルとそれぞれの階層で権限が必要です。
最終的には以下ような権限となりました。

いったん動作確認!
一旦 CLIのaws firehose put-recordコマンドを使って、データを配信してみます。
送りたいデータは以下です。
{
"activity_id": "act_20250725_001",
"created_at": "2025-07-25T10:30:45.123Z",
"user_id": "user_12345",
"action_name": "user_login",
"entity_type": "authentication",
"entity_id": "auth_session_789",
"success": true,
"response_time_ms": 245,
"metadata": "{\"ip_address\":\"192.168.1.100\",\"user_agent\":\"Mozilla/5.0\",\"device\":\"desktop\"}"
}
これをBase64化します。
eyJhY3Rpdml0eV9pZCI6ImFjdF8yMDI1MDcyNV8wMDEiLCJjcmVhdGVkX2F0IjoiMjAyNS0wNy0yNVQxMDozMDo0NS4xMjNaIiwidXNlcl9pZCI6InVzZXJfMTIzNDUiLCJhY3Rpb25fbmFtZSI6InVzZXJfbG9naW4iLCJlbnRpdHlfdHlwZSI6ImF1dGhlbnRpY2F0aW9uIiwiZW50aXR5X2lkIjoiYXV0aF9zZXNzaW9uXzc4OSIsInN1Y2Nlc3MiOnRydWUsInJlc3BvbnNlX3RpbWVfbXMiOjI0NSwibWV0YWRhdGEiOiJ7XCJpcF9hZGRyZXNzXCI6XCIxOTIuMTY4LjEuMTAwXCIsXCJ1c2VyX2FnZW50XCI6XCJNb3ppbGxhLzUuMFwiLFwiZGV2aWNlXCI6XCJkZXNrdG9wXCJ9In0=
で、以下のコマンドで送信します。
aws firehose put-record \
--delivery-stream-name PUT-ICE-rviEd \
--record '{"Data":"eyJhY3Rpdml0eV9pZCI6ImFjdF8yMDI1MDcyNV8wMDEiLCJjcmVhdGVkX2F0IjoiMjAyNS0wNy0yNVQxMDozMDo0NS4xMjNaIiwidXNlcl9pZCI6InVzZXJfMTIzNDUiLCJhY3Rpb25fbmFtZSI6InVzZXJfbG9naW4iLCJlbnRpdHlfdHlwZSI6ImF1dGhlbnRpY2F0aW9uIiwiZW50aXR5X2lkIjoiYXV0aF9zZXNzaW9uXzc4OSIsInN1Y2Nlc3MiOnRydWUsInJlc3BvbnNlX3RpbWVfbXMiOjI0NSwibWV0YWRhdGEiOiJ7XCJpcF9hZGRyZXNzXCI6XCIxOTIuMTY4LjEuMTAwXCIsXCJ1c2VyX2FnZW50XCI6XCJNb3ppbGxhLzUuMFwiLFwiZGV2aWNlXCI6XCJkZXNrdG9wXCJ9In0="}'
しばらく待つと、Athena経由でデータが登録されていることが確認できました!
select * FROM "my_s3_namespace"."app_activity_logs" LIMIT 1

なお、Firehoseはバッファリング機能があるので、put-recordしても即座に反映されません。
バッファ間隔を少し短くすると動作確認しやすいです。

配信が失敗している場合、S3バックアップバケット内のプレフィックスfirehose_fail_logiceberg-failed内にエラー内容がわかる情報が格納されてます。
{
"attemptsMade": 0,
"arrivalTimestamp": 1753388758000,
"errorCode": "S3.AccessDenied",
"errorMessage": "Access was denied. Ensure that the trust policy for the provided IAM role allows Firehose to assume the role, and the access policy allows access to the S3 bucket. Table: my_rsclink.app_activity_logs",
"attemptEndingTimestamp": 1753389227018,
"rawData": "exxxx"
}
この例はLake Formationでの権限設定が不足している場合に発生していたエラーです。
あとはAPI Gateway + LambdaでAPI化します!
Pythonで簡単にput-recourdするソースを書いて、RestAPI経由で呼び出せるようにしました!
import json
import boto3
import uuid
import os
from datetime import datetime
import logging
# ログ設定
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# 環境変数から設定を取得
FIREHOSE_DELIVERY_STREAM_NAME = os.environ.get('FIREHOSE_DELIVERY_STREAM_NAME', 'my-delivery-stream')
def lambda_handler(event, context):
"""
Kinesis Firehoseにログデータを送信するLambda関数
"""
try:
# Firehoseクライアントを初期化
firehose_client = boto3.client('firehose')
# デバッグ: 受信したeventをログ出力
logger.info(f"受信したevent: {json.dumps(event)}")
# 送信するログデータを準備
log_data = prepare_log_data(event)
logger.info(f"送信データ準備完了 - ActivityId: {log_data.get('activity_id')}, UserId: {log_data.get('user_id')}")
# Firehoseにデータを送信
record_id = send_to_firehose(firehose_client, log_data)
logger.info(f"データ送信完了 - Stream: {FIREHOSE_DELIVERY_STREAM_NAME}, RecordId: {record_id}")
return {
'statusCode': 200,
'body': json.dumps({
'message': 'ログデータが正常にFirehoseに送信されました',
'record_id': record_id
})
}
except Exception as e:
logger.error(f"エラーが発生しました: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps({
'error': str(e)
})
}
def prepare_log_data(event):
"""
イベントデータから操作ログデータを準備
"""
# イベントから必要な情報を抽出
current_time = datetime.utcnow()
# API Gatewayからのリクエストの場合、bodyを解析
if 'body' in event and event['body']:
try:
body_data = json.loads(event['body'])
logger.info(f"API Gateway body parsed: {body_data}")
except json.JSONDecodeError:
logger.warning("Failed to parse request body as JSON")
body_data = {}
else:
# 直接呼び出しの場合はeventをそのまま使用
body_data = event
logger.info(f"Direct invocation, using event as body_data")
log_record = {
'activity_id': body_data.get('activity_id', str(uuid.uuid4())),
'created_at': current_time.isoformat(),
'user_id': body_data.get('user_id', 'unknown'),
'action_name': body_data.get('action_name', 'lambda_execution'),
'entity_type': body_data.get('entity_type', 'system'),
'entity_id': body_data.get('entity_id', 'lambda'),
'success': body_data.get('success', True),
'response_time_ms': body_data.get('response_time_ms', 0),
'metadata': json.dumps(body_data.get('metadata', {}))
}
return log_record
def send_to_firehose(firehose_client, log_data):
"""
Kinesis FirehoseにデータをPUT
"""
if not log_data:
raise ValueError("送信するデータがありません")
# JSONデータを文字列に変換(Base64エンコードなし)
json_data = json.dumps(log_data)
# Firehoseにレコードを送信
response = firehose_client.put_record(
DeliveryStreamName=FIREHOSE_DELIVERY_STREAM_NAME,
Record={
'Data': json_data
}
)
return response['RecordId']
最後に動作確認!
最後のAPI経由で動作確認してみます。
{
"activity_id": "morimori",
"user_id": "user_12345",
"action_name": "user_login",
"entity_type": "authentication",
"entity_id": "auth_session_789",
"success": true,
"response_time_ms": 245,
"metadata": {
"ip_address": "192.168.1.100",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
"device": "desktop",
"login_method": "password",
"session_duration": 3600
}
}
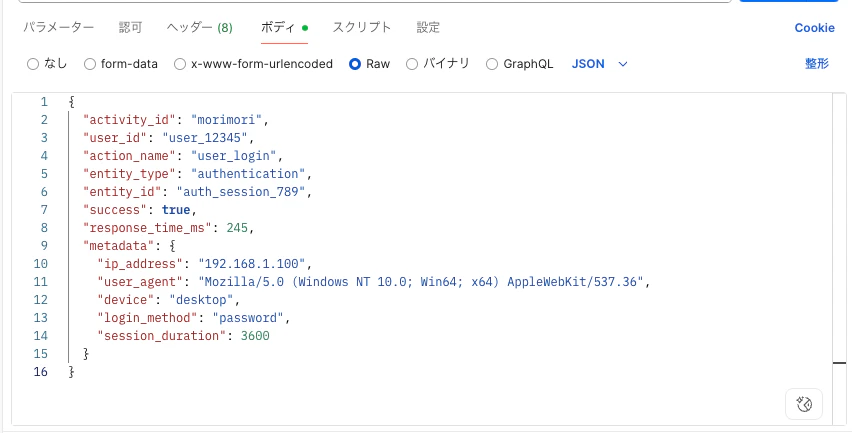

少し待って、Athenaで確認すると無事動いていることを確認できました!
select * FROM "my_s3_namespace"."app_activity_logs" LIMIT 1

最後に
ログを保存する方法として今まで、RDS or NoSQLのどちらかしか選択肢がなかった私ですが、今回初めてデータ分析系のサービスを触ることができ、良い経験になりました!
触ったことないサービスいっぱいあるので、今後積極的に触っていきたいなと改めて思う良い機会でした!