目次
- はじめに
- ロジスティック回帰分析について
- 実装
- おわりに
はじめに
前回の記事にて重回帰分析を行ったが今回はロジスティック回帰分析を実行してみる。
ロジスティック回帰分析について
そもそも回帰分析とは相関・因果関係があると思われる2つの変数のうち、一方の変数から将来的な値を予測するために用いられる手法。
その中でもロジスティック回帰分析は二値分類で複数の説明変数をもとに確率を計算して予測を行う。
- 目的変数:1つ(0 or 1の2値)
- 説明変数:2つ以上の複数
- 出力:検証値となりうる確率(%)
実装
事前準備
今回はscikit-learnのiris(アヤメ)問題のデータセットを利用する。
元データは下記のようにがく片(Sepal)、花弁(Petal)の幅及び長さと種別(species)が0, 1, 2となっていてデータ数は種別ごとに各50の計150データである。

ここからデータを学習用と予測検証用で分ける必要があるが、上述したようにロジスティック回帰分析は二値分類を行うという性質上3分類で確立計算を行う場合は各分類同士を比較して多数決などを行う必要があり少々複雑となるため
今回はテスト用データの種別は1 or 2に絞って25行づつ元データより抽出してロジスティック回帰モデル作成、予測値とその正解率の算出を行う。
上記を前提に学習用・テスト用のテーブルにデータを事前に分けて実装していく
- 学習用テーブル:iris_train
- テスト用テーブル(要インメモリ化):iris_test
Pythonソース
logistic_reg_analysis.py
from asyncio.windows_events import NULL
import pandas as pd
import jaydebeapi
import os
import numpy as np
from sklearn import linear_model
def get_learn_schema(input_schema):
return ['sepal_length_cm NUMERIC', 'sepal_width_cm NUMERIC', 'petal_length_cm NUMERIC', 'petal_width_cm NUMERIC', 'species NUMERIC', 'y_pred NUMERIC']
def get_learn(context, input):
# 学習データの読み込み
conn = jaydebeapi.connect("jp.co.dw_sapporo.JDBC.JDBCDriver",
"jdbc:dwods:localhost:6001:test",
["Administrator", ""],
"C:\DrSum56\DevKit\java\jdbc\dwodsjd4.jar")
curs = conn.cursor()
sql_train = "select * from iris_train"
train = pd.read_sql_query(sql_train, conn)
# 【学習データ】説明変数
x_train = train.loc[:, ["sepal_length_cm",
"sepal_width_cm", "petal_length_cm", "petal_width_cm"]]
# 【学習データ】目的変数(アヤメの3品種(0:Setosa, 1:Versicolour, 2:Virginica))
y_train = train["species"]
# 【学習データ】配列の作成
x_train = np.array(x_train).reshape(-1, 4)
y_train = np.array(y_train).reshape(-1, 1)
# 【テストデータ】説明変数取得
x_test = input.loc[:, ["sepal_length_cm",
"sepal_width_cm", "petal_length_cm", "petal_width_cm"]]
# 【テストデータ】目的変数取得(アヤメの3品種(0:Setosa, 1:Versicolour, 2:Virginica))
y_test = input["species"]
# 【テストデータ】配列の作成
x_test = np.array(x_test).reshape(-1, 4)
y_test = np.array(y_test).reshape(-1, 1)
# ロジスティック回帰の識別器を用意
logreg = linear_model.LogisticRegression()
# 学習実行
logreg.fit(x_train, y_train)
# 識別結果(正解率)を確認
t = 'answer rate:{}'.format(logreg.score(x_test, y_test))
print(t)
# 予測結果を出力
y_pred = logreg.predict(x_test)
input["y_pred"] = y_pred
submission = pd.DataFrame(data=input)
curs.close()
conn.close()
return submission
if __name__ == "__main__":
cwd = os.path.dirname(__file__)
import dspy.emulator
# Dr.SumのビューをJDBCで参照
conn = jaydebeapi.connect("jp.co.dw_sapporo.JDBC.JDBCDriver",
"jdbc:dwods:localhost:6001:testDB",
["User", "Pass"],
"C:\DrSum56\DevKit\java\jdbc\dwodsjd4.jar")
curs = conn.cursor()
# テストデータ読み込み
sql_test = "select * from iris_test"
sql_query = pd.read_sql_query(sql_test, conn)
print("----- inputDr.Sum -----")
# inputとなるデータのスキーマ解釈を出力
dspy.emulator.show_ds_schema(sql_query)
builder = dspy.emulator.EmulatorBuilder(
sql_query,
# エミュレータにおけるPY_SCRIPT_ROOT(省略時はカレントフォルダー)
py_script_root=os.path.join(cwd, "../script"),
# エミュレータにおけるPY_DATA_ROOT(省略時はカレントフォルダー)
py_data_root=os.path.join(cwd, "../data")
)
emulator = builder.buildSerial(
# 対象のPythonファイル名(当ファイル)
py_file_path="PY_SCRIPT_ROOT/logistic_reg_analysis.py",
# 対象の実行ロジックメソッド
func_name="get_learn",
# 出力データスキーマメソッド名
schema_func_name="get_learn_schema",
)
curs.close()
conn.close()
# create_schema_mode=Trueで出力データスキーマメソッドを出力
result = emulator.execute(create_schema_mode=True)
print("----- OUTPUT -----")
print(result)
Dr.Sumで実行
SELECT
*
FROM
udtf::serial_py(iris_test, py_file_path='PY_SCRIPT_ROOT/logistic_reg_analysis.py' , func_name='get_learn' , schema_func_name='get_learn_schema' ) T
出力結果
y_predが予測値(9行目間違えてる)
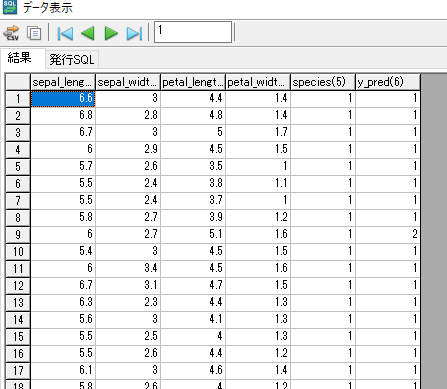
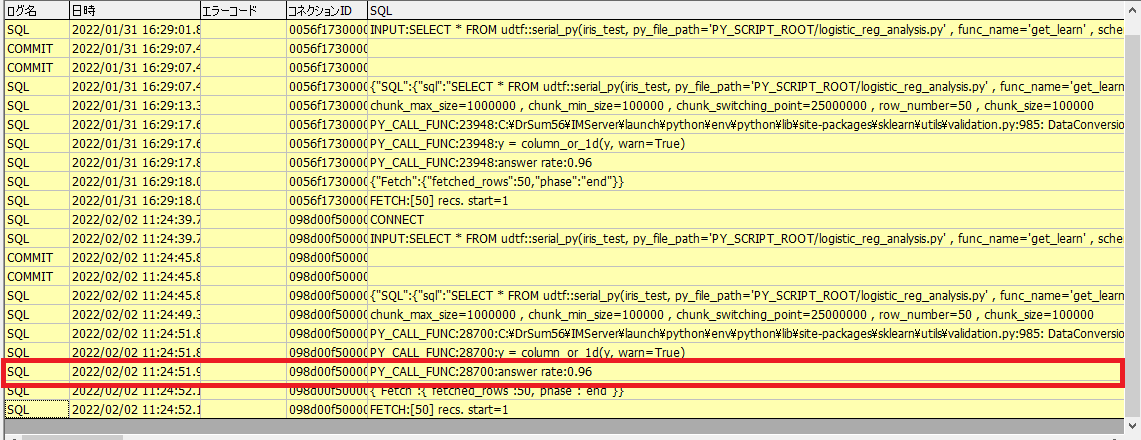
正解率:96%(0.96)
おわりに
実際運用する際はモデルを事前に学習してファイルとして保持しておくなどの対応が取れるので都度学習を実行しない場合は学習テーブル側のデータ参照は運用上不要にできる。