この記事はトレタ Advent Calendar 2022の9日目の記事です。
こんにちは。トレタでサーバーサイドエンジニアをしている川村です。
私が担当しているプロジェクトでは、MVCに少し要素を足したような構造からクリーンアーキテクチャを意識した構造へと変更するリファクタリングを実施しています。
その一環として値オブジェクトを導入しており、このオブジェクトを作っていくなかで「どっちがいいんだ?」とちょっともやもやしていたことがあったので、アドカレを機会に検討しました。
2通りのオブジェクト定義
なにかの名前(文字列)用の型を作ろうと思った時、以下2通りの作り方があるかと思います。
*判別のために型名の後半にベースの型名をつけてます
- stringをベースにした型
stringとして取得する関数とコンストラクタも定義してます。
type NameString string
func (ns *NameString) String() string {
return string(*ns)
}
func NewNameString(name string) NameString {
n := NameString(name)
return n
}
- structをベースにした型
こちらも同様にstringとして取得する関数とコンストラクタも定義してます。
type NameStruct struct {
value string
}
func (ns *NameStruct) String() string {
return ns.value
}
func NewNameStruct(name string) *NameStruct {
return &NameStruct{
value: name,
}
}
この2つのパフォーマンス差や使用感の違いなどについて考えていきたいと思います。
パフォーマンス
Goには標準でベンチマークツールがあるのでそれを使ってパフォーマンスを計測してみました。
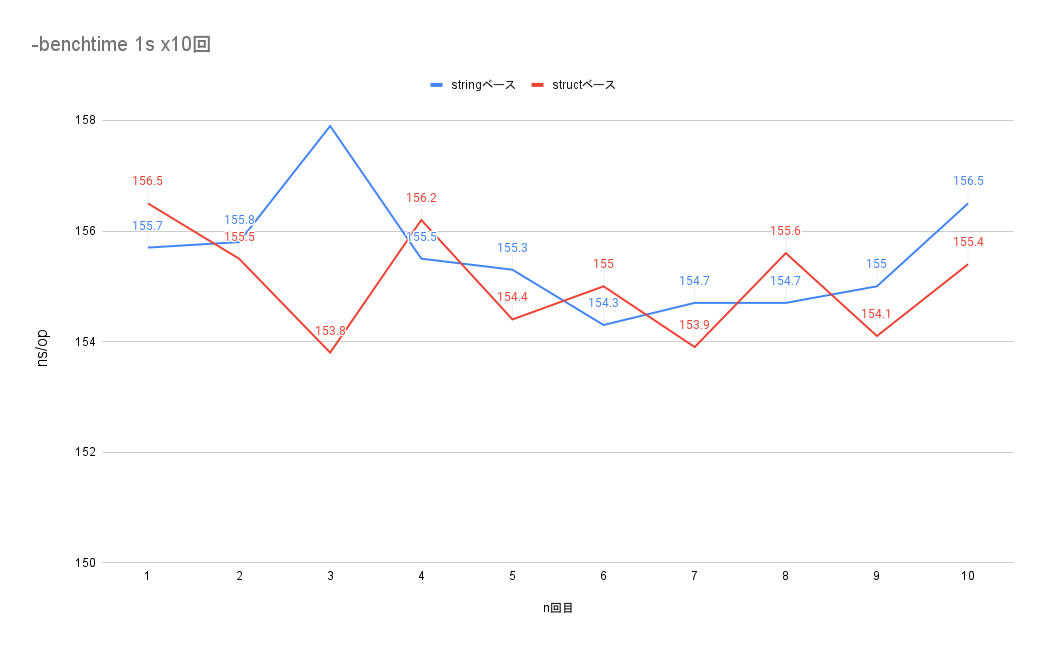
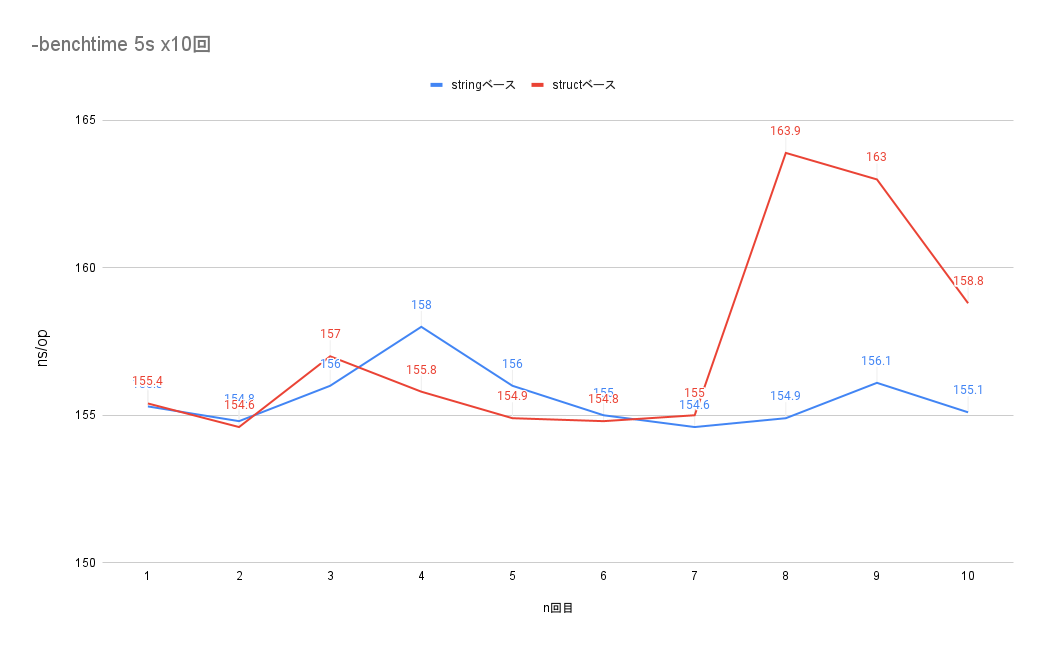
結果を先に書いてしまうとほぼ差はないのでこの点ではどちらでも良さそうでした。
(Stringをベースにした型の方が都度キャストするので多少重いのではないかと思っていたので意外でした)
ベンチマークのコード
ランダムな5文字をそれぞれの型にして、直後にstringとして取得する処理を繰り返し実行してパフォーマンスを計測します。
func BenchmarkNameString(b *testing.B) {
rand.Seed(time.Now().UnixNano())
for n := 0; n < b.N; n++ {
s := RandomString(5)
n := domain.NewNameString(s)
n.String()
}
}
func BenchmarkNameStruct(b *testing.B) {
rand.Seed(time.Now().UnixNano())
for n := 0; n < b.N; n++ {
s := RandomString(5)
n := domain.NewNameStruct(s)
n.String()
}
}
// 指定桁数のランダムな文字列を生成する
// こちらからお借りしました: https://off.tokyo/blog/go言語でランダムの文字列を生成する最良な方法/
func RandomString(n int) string {
var letter = []rune("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789")
b := make([]rune, n)
for i := range b {
b[i] = letter[rand.Intn(len(letter))]
}
return string(b)
}
実行コマンド
go test -count 10 -bench . -benchmem -benchtime 1s // または5s
実行環境
- Goバージョン: 1.19.4
- CPU: 2.7 GHz クアッドコアIntel Core i7
- RAM: 16 GB 2133 MHz LPDDR3
結果
メモリについては全て32 B/op 2 allocs/opでした。
5s実行した時のstructベースの値が8回目で少し跳ねてますがPCの他の処理の影響かなと解釈しています。
最初に書いてしまいましたが、数値を見て頂ければわかる通りどちらも処理時間としてはほとんど差はありませんでした。
-
各回1秒実行で10回実行した場合の1opの実行時間のグラフ
-
各回5秒実行で10回実行した場合の1opの実行時間のグラフ
補足
ちなみに文字列をランダム生成ではなく、固定にするとどちらも↓このような結果になり一瞬でおわります。
BenchmarkNameString-8 1000000000 0.2493 ns/op 0 B/op 0 allocs/op
流石に0 allocs/opという事はないのでは...?と思うので、おそらくコンパイラで最適化がかかってほぼ何も処理してないような状態になっているのではないかと推測しています。
それぞれの特徴・使用感など
3つの観点で比較してみます。
| プリミティブベース | structベース | |
|---|---|---|
| インスタンスの作り方 | コンストラクタで引数をキャスト | コンストラクタで引数をフィールドに保存 |
| 型変換の仕方 | レシーバーをキャスト | フィールドの値を返す |
| コンストラクタの強制 | できない | (実質)できる |
インスタンスの取得と型変換については内部でやることは違いますが、呼び出し側としてしては NewName(str), name.String() のような見え方になるのでこの点については変わりありません。
コンストラクタが強制できるか(コンストラクタを通さずに値の入ったインスタンスを作れるか)が大きな違いかなと思いました。
プリミティブな型をベースにした場合、型を公開するので好きな場所で勝手にインスタンスを作れてしまいますが、structベースの場合は、実際の値を格納するフィールドを非公開にできるので、コンストラクタを使わないと初期値の入ったインスタンスしか作れません。
stringなどプリミティブな型をベースにした方がコード的にはシンプルで直感的かなという印象ですが、インスタンスの取得にコンストラクタを強制する意味ではstructをベースにした方が良いかもしれないですね。
実際どっちを使っているか
今行っているリファクタではプリミティブな型をベースにする方法を取ってみています。
オープンソースの用に不特定多数が手を加えたり利用するわけではないので、コンストラクタの使用については実装者の心がけとレビューで弾いていけると思うのでとくに問題ないかなと考えています。
ただ、Goの標準パッケージやpkgsiteのソースを眺めてみると、そもそもここまで細かい型付けはしていなかったりもするので、この方式で良いのか、どこかで破綻するのかまだ分かりません。
値オブジェクトに限らずプロジェクト全体のパッケージ構成などまだまだ模索中で、これからもより良い構造を求めてリファクタを続けていきたいと思っています!
トレタではより良い構造を一緒に考えてくれる仲間を募集中です!