この記事は、こちらのページを日本語化したものです。
機械学習と生成型AIの概要
機械学習の全体像
人工知能(AI)のサブセットである機械学習(ML)は、ビジネス上のより良い意思決定に役立ちます。
機械学習は、機械がデータを分解し、そこから学習して、結果を生成するプロセスです。これらの結果を使用して、主要なビジネス上の意思決定(教師あり学習)、顧客のセグメント化(教師なし学習)、または広告の配置(強化学習)を行うことができます。
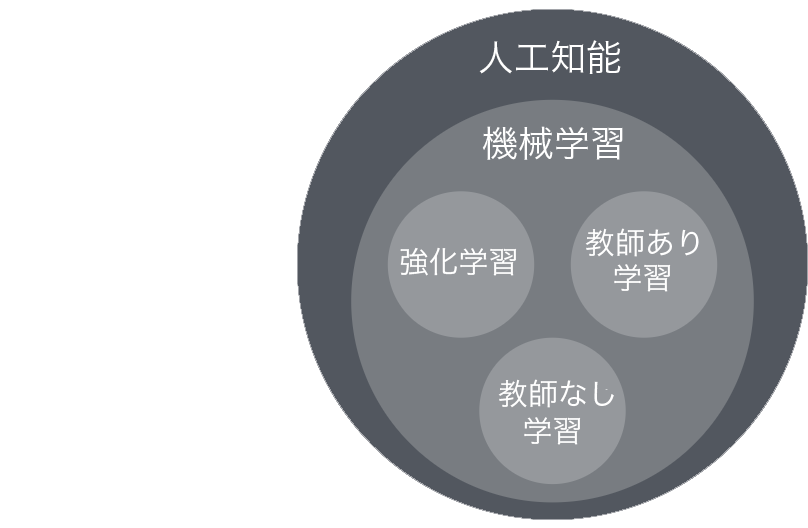
強化学習
強化学習モデルは経験から学習し、時間の経過とともにどのアクションが最高の報酬につながるかを識別できます。強化学習では、エージェントは環境を調査して、指定されたタスクを実行する方法を学びます。結果が良好なアクションを実行し、結果が不良なアクションを回避します。
強化学習は、AWS DeepRacerで使用される機械学習のタイプです。
機械学習技術
人工知能(AI)のサブセットである機械学習(ML)は、ビジネス上のより良い意思決定に役立ちます。
機械学習は、機械がデータを分解し、そこから学習して、結果を生成するプロセスです。これらの結果を使用して、主要なビジネス上の意思決定(教師あり学習)、顧客のセグメント化(教師なし学習)、または広告の配置(強化学習)を行うことができます。
教師あり学習
教師あり学習は、予測または分類を生成するために使用される手法です。目標は、入力データと出力データを取得し、2つの変数間のドットを接続する方法についてアルゴリズムをトレーニングすることです。その結果、アルゴリズムは新しい入力から値を分類または出力する方法を学習します。

教師なし学習
教師なし学習を使用して、入力データの分布をよりよく理解します。ドットを出力変数に接続する代わりに、入力変数の間にドットを接続しようとしています。後でこの情報を使用して、教師あり学習ベースのアルゴリズムを開発できます。
AWS DeepComposerで使用される生成AIテクニックは、音楽の基本的なパターン分布を理解して、新しい音楽を生成します。

ジェネレーティブAI
One of the most promising advances in AI in the past decade.
過去10年間で最も有望なAIの進歩の1つ。
ジェネレーティブAIは、人間とコンピュータの創造性の可能性の世界への扉を開きます。スケッチを画像にして製品開発を加速し、複雑なオブジェクトのコンピュータ支援設計を改善することまで、さまざまな業界で実用的なアプリケーションが出現しています。
生成AIを使用すると、コンピューターは特定の問題の根本的なパターンを学習し、この知識を使用して入力(画像、音楽、テキストなど)から新しいコンテンツを生成できます。
活用事例
エアバス
継続的な取り組みの一環として、エアバスは、オートデスクのジェネレーティブデザインを適用して、パフォーマンスと安全性の基準を超える軽量部品を開発することにより、複数の航空機の構造部品を再考しています。
NASA JPL
何百万マイルも離れた惑星(Jupiterは地球から3億6500万マイル)にある着陸船の設計とエンジニアリングの課題に対処するために、JPLとオートデスクは複数年にわたる共同研究プロジェクトに取り組んでいます。JPLは、オートデスクの生成設計技術のカスタムアプリケーションを使用して、宇宙探査のための設計および製造プロセスへの新しいアプローチを模索しています。
グライドウェル研究所
Glidewell Dentalは、画像から詳細な3Dモデルを再構築することに長けているGPUを利用した生成敵対ネットワークをトレーニングしています。彼らは王冠デザインの深度マップをGANと組み合わせています。このネットワークでは、1つのネットワークが画像を生成し、2番目のネットワークがそれらの画像を検査します。これにより、元の歯よりも解剖学的に細かい歯冠ができます。
ジェネレーティブAIプレイグラウンド
人間かAIか?
作曲とは、私たちが独自に人間と考える創造性の行為です。機械は、音楽の連続した構造を再現することを学び、後続の音符の可能性の離散的なセットから選択できる必要があります。
音楽はポリフォニックです—さまざまな楽器で同時に演奏される複数のノートストリーム。ピアニストがコードを保持している間、ギタリストはより速いノートを演奏し、機械学習タスクに複雑さを加えます。
ジェネレーティブミュージックの例
AWS DeepComposerで利用できる生成AIネットワークには、U-NetとMuseGANの2つのタイプがあります。
U-Netアーキテクチャは、もともと画像を生成するために作成されました。ネットワークは、音楽を解釈する前に画像のような表現に変換します。このように音楽をエンコードおよびデコードすることにより、ネットワークは音楽の一般的な表現を学習できます。
MuseGANアーキテクチャは、音楽を生成するために特別に構築されており、各楽器と曲全体のコンポーネントがあります。各楽器の固有の特性をキャプチャし、それらが互いに調和して全体的な歌を生成する方法を把握できます。
ジェネレーティブAI — GAN
ジェネレーティブAIアルゴリズム
ジェネレーティブAIは幅広いカテゴリのアルゴリズムであり、最も一般的なものはジェネレーティブアドバサリアルネットワーク(GAN)、変分オートエンコーダー(VAE)、自己回帰(AR)モデルなどです。
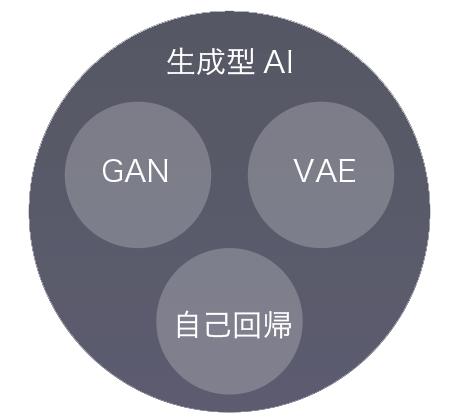
ジェネレーティブAIアルゴリズム
ジェネレーティブAIは幅広いカテゴリのアルゴリズムであり、最も一般的なものはジェネレーティブアドバサリアルネットワーク(GAN)、変分オートエンコーダー(VAE)、自己回帰(AR)モデルなどです。
生成的敵対的ネットワーク
生成的敵対的ネットワーク(GAN)は、2つのニューラルネットワークが競合する機械学習ネットワークの一種です。一方のネットワークは、現実的なコンテンツ(教師なし学習)の生成を担当し、もう一方のネットワークは、生成したコンテンツを実際のデータ(教師あり学習)と区別する役割を果たします。
Generator(ジェネレーター)
GAN内のGeneratorは、現実的な外観の出力を生成するようにトレーニングされた機械学習モデルです。
ジェネレーターはオーケストラのようなものです—洗練された音楽をトレーニング、練習、生成しようとします。
Discriminator(ディスクリミネーター)
Discriminatorは入力を取り、入力が実数または生成するか否かを分類するように訓練された別のマシン学習モデルです。
Discriminatorはオーケストラの指揮者のようなものです—出力の品質を判断し、訓練された音楽のスタイルを達成しようとします。
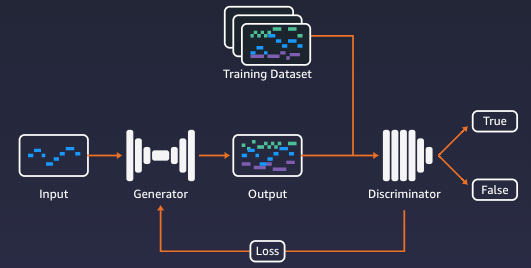
GANの動作の流れ
コンテンツ生成
最初に、Generatorはランダム入力に基づいてコンテンツサンプルを生成します。
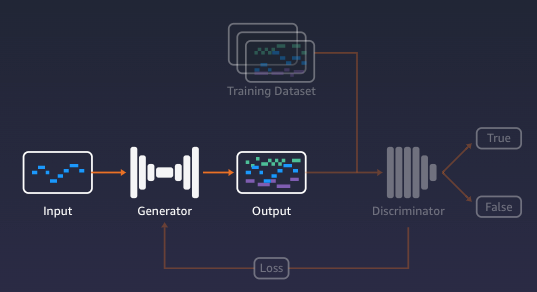
コンテンツの分類
Discriminatorは、Generatorが作成したコンテンツサンプルで、訓練されたデータセット(例:ポップ、ロック、クラシック)から特徴(例:テンポ)を探します。コンテンツサンプルがトレーニングセットに属するかどうかを決定します。
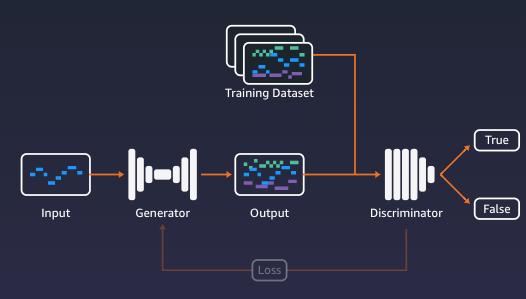
GANのトレーニング
Discriminatorの判断の結果は、両方のモデルのトレーニングに使用されます。Generatorは、Discriminatorが実際のサンプルと区別できない現実的なコンテンツを生成するために最適化するようにトレーニングされています。一方、Discriminatorは、生成されたコンテンツを検出する能力を高めるように訓練されています。
2つのモデルが互いに直接競合するこの前後の動作は、GANの敵対的な部分です。
コンピュータが音楽を理解する方法
コンピュータ音楽入門
機械学習モデルが音楽を解釈および生成できるようにするには、音楽の再生方法の正確な詳細を保持する形式で音楽を表すことが重要です。
サウンドファイルを処理する代わりに、AWS DeepComposerで使用されているような機械学習モデルがこれらの詳細を調べて、楽器や音楽スタイルを忠実に再現します。
これらの属性のいくつかを見てみましょう…
ピッチ
ピッチは、音階上の相対位置が割り当てられているトーンです。各音符には数値が割り当てられており、0から最低音まで、最高音は127まであります。
AWS DeepComposerキーボードのキーの範囲は41〜72です。オクターブ調整ボタンは、ピッチの値を12の倍数単位で上下にシフトして、ピッチを高くしたり低くしたりします。
速度
Velocityは、単一のノートが押される強さをエンコードします。キーをより速く押すと、ベロシティの値が高くなり、より大きなサウンドが作成されます。速度の値の範囲は、1(最小、ほとんど聞こえない)から127(最大)です。
テンポ
テンポは、音楽の再生速度を表します。音楽は通常、特定のビートまたはメーターに追従し、演奏されるノートのリズムを動かします。このビートの速度は、ビート/分で測定されます。1分あたりのビート数が多いほど、再生速度が速くなります(テンポ)。
MIDI
MIDIのファイル形式は、レコードや店舗の音楽をコンピュータで使用される業界標準です。ファイル形式は、使用される楽器の再生テンポや、ノートのピッチやベロシティなど、押したり離したりするノートをエンコードする一連のイベントなどの詳細をエンコードします。
ピアノロールの視覚化
MIDI形式は、ピアノロールビジュアライゼーションを使用して部分的に表すことができます。これは、データの視覚化に役立ちます。時間は水平次元で表され、ピッチは垂直次元で表されます。バーは押されているノートを表します。小節の始まりは演奏されているノートの始まりであり、小節の終わりはリリースされているノートです。
ジェネレーティブAIとDeepComposer
モデルをトレーニングする
独自のモデルをトレーニングして、実践的な体験をしてください。モデルの仕組みを理解し始めます。GANには2つの競合するニューラルネットワークがあります。1つのモデルは生成的で、もう1つのモデルは識別的です。Generatorは、目的のデータ分布にマップするデータを生成しようとします。
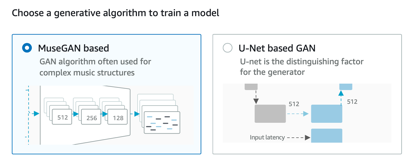
1.アルゴリズムを選択する
モデルをトレーニングする生成アルゴリズムを選択します。
2.データセットを選択
データセットとして音楽のジャンルを選択します。

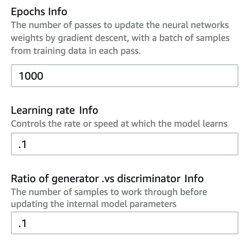
3.ハイパーパラメーターを微調整する
モデルのトレーニング方法を選択します。
モデルを理解する
トレーニング中にジェネレーターとディスクリミネーターの損失がどのように変化したかを調べます。トレーニング中に特定の音楽指標がどのように変化したかを理解します。すべての反復で固定入力に対して生成された音楽出力を視覚化します。
ミュージックスタジオ
Music Studioを使用すると、音楽を再生してGANを使用できます。まず、メロディーを録音するか、デフォルトのメロディーを選択します。次に、事前トレーニング済みモデルまたはカスタムモデルを使用して、オリジナルのAI音楽作品を生成します。
1.メロディーを録音する
AWS DeepComposerキーボードまたはコンピューターのキーボードを使用して、入力用の短いメロディーを録音します。
2.構成を生成する
入力メロディーに満足したら、モデルを選択してから、[ コンポジションを生成]を選択します。
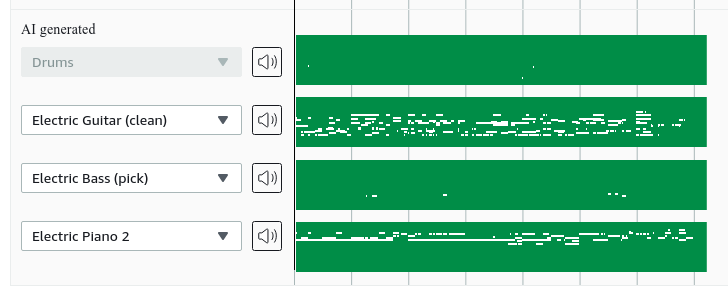
3. AWS DeepComposerは付随するトラックを生成します
AWS DeepComposerは入力メロディーを取り、最大4つの伴奏トラックを生成します。
AWS DeepComposerに飛び込む
ミュージックスタジオ
AWS DeepComposerキーボードまたはウェブブラウザを使用してメロディーを入力します。事前トレーニング済みのジャンルモデルをすぐに試すことができます。
生成モデルのトレーニング
アルゴリズムアーキテクチャを実際に試すために、トレーニングモデルを実験して評価します。