人工知能(AI)とは
人工知能(AI)とは
人工知能とは何か
「人工知能(Artificial Intelligence)」という言葉は、1956年にアメリカで開催されたダートマス会議において、ジョン・マッカーシーが初めて使った言葉である。
「人工知能」は、推論、認識、判断など、人間と同じ知的な処理能力を持つ機械(情報処理システム) である
人工知能のレベル
レベル1:単純な制御プログラム
・すべての振る舞いがあらかじめ決められており、その通りに動くだけ
例)エアコンの温度調整、洗濯機の水量調整
レベル2:古典的な人工知能
・探索・推論、知識データを利用することで、状況に応じてきわめて複雑な振る舞いをする製品
例)掃除ロボット、診断プログラム
レベル3:機械学習を取り入れた人工知能
・非常に多くのサンプルデータを基に入力と出力の関係を学習した製品
例)検索エンジン、交通渋滞予測
レベル4:ディープラーニングを取り入れた人工知能
・特徴量とは、学習対象となるデータにおいて、学習結果に大きく影響する特徴の度合いのこと
・その特徴量を自動的に学習するサービスや製品
例)画像認識、音声認識、自動翻訳
AI効果
・人工知能で何か新しいことが実現され、その原理がわかってしまうと、「それは単純な自動化で会って知能とは関係ない」と結論付ける人間の心理的な効果
・AI効果により人工知能の貢献は少なく見積もられすぎていると主張するAI研究者も存在する
人工知能とロボットの違い
・ロボットの脳にあたる部分が人工知能である
・人工知能の研究とは**「考える(知的な処理能力)」という「目に見えないもの」**を中心に扱っている学問である
人工知能研究の歴史
1946年、アメリカのペンシルバニア大学でエニアック(ENIAC)という17,468本物真空管を使った巨大な電算機が開発された。これが世界初の汎用電子コンピュータとされている。
人工知能という言葉は、エニアックの誕生から10年後の1956年にアメリカで開催されたダートマス会議にて初めて使われた。ダートマス会議には、マーヴィン・ミンロキー、ジョン・マッカーシー、アレン・ニューウェル、ハーバート・サイモン、クロード・シャノンなど、著名な研究者たちも参加した。
特にニューウェルとサイモンは、世界初の人工知能プログラムといわれるロジック・セオリストをデモンストレーションし、数学の定理を自動的に証明することが可能であることを示した。問題はヒューリスティックに解決された。ヒューリスティックとは、ある程度正解に近い解を見つけ出すための経験則のこと。
人工知能研究のブームと冬の時代
★第1次AIブーム(探索・推論の時代)
・1950年代後半~1960年代
・特定の問題に対して解を提示できるようになったことがブームの一因
・しかし、迷路や数学の定理の証明のような簡単な問題(「トイ・プロブレム」)は解けても、複雑な問題は解けないことが明らかになり、1970年代には人工知能研究は冬の時代を迎える。
第2次AIブーム(知識の時代)
・1980年代
・データベースに大量の知識をため込んだエキスパートシステムと呼ばれる実用的なシステムがたくさん作られた。
・日本では、政府によって「第五世代コンピュータ」と名付けられた大型プロジェクトが推進された。
・しかし、知識の蓄積・管理の大変さが明らかになっていき、1995年ごろから再び冬の時代に突入する。
第3次AIブーム(機械学習・特徴量表現の時代)
・2010年~
・機械学習やディープラーニングの登場がブームの背景にある。
・人間を超える「超知性」の誕生(シンギュラリティー)の可能性に対する懸念を広め、不安と期待をさらに高めた。
・シンギュラリティーが起こると、人工知能が自ら知的システムを改善するスピードが無限大となり、何が起きるか予想できなくなると未来学者のレイ・カーツワイルは主張している。
・「人工知能が人間より賢くなる年」は2029年、「シンギュラリティー」が起きる年は2045年だと予想されている
・2010年代中頃から生成AIの研究が活性化した。
・自然言語処理の分野では、**大規模言語モデル(LLM)**と呼ばれる技術やその応用技術が次々と開発された。
人工知能分野の問題
★トイ・プロブレム
・コンピュータで扱えるように、本質を損なわない程度に問題を簡略化したもの
・第1次AIブームの時代、数学の定理の証明やチェスや主義で人間に勝利するなど大きな成功を収めた。しかし、これらはトイ・プロブレムであり、現実世界の問題はずっと複雑である。
★フレーム問題
・1969年にジョン・マッカーシーとパトリック・ヘイズが提唱した人工知能における重要な問題。
・「現在実施しようとしていることに関係のある事柄だけ選択することが、実は非常に難しい」ことを指す。
・ロボットは考えすぎて無限にフリーズしたり、行動のみを遂行して合理的ではないなど、解決すべき問題がたくさんある
★チューリングテスト
・イギリスの数学者アラン・チューリングが提唱した
・別の場所にいる人間がコンピュータと会話をし、相手がコンピュータだと見抜けなければコンピュータには知能があるとするもの
・1966年にジョセフ・ワイゼンバウムによって開発された**イライザ(ELIZA)**は、精神科セラピストを演じた。その結果、本物のセラピストであると信じる人も現れた
・ローブナーコンテスト:1991年以降、チューリングテストに合格するような会話ソフトウェアを目指すコンテスト。毎年開催されている。
・現在もまだチューリングテストにパスする会話ソフトウェアは現れていない
強いAIと弱いAI
・アメリカの哲学者ジョン・サールが1980年に発表した論文の中で提示した区分である。
・強いAI:適切にプログラムされたコンピュータは人間が心を持つのと同じ意味で心を持つ。また、プログラムそれ自身が人間の認知の説明である。
・弱いAI:コンピュータは人間の心を持つ必要はなく、有用な道具であればよい。
・数学者のロジャー・ペンローズは「強いAI」は実現できないと主張している
・ジョン・サールは、「強いAI」は実現不可能だと主張した。それを説明するために「中国語の部屋」という思考実験を提案している。
★中国語の部屋

①部屋には英語しかわからない人が閉じ込められている。
②部屋の中には中国語の完璧なマニュアルがある。
③中国語での受け答えを繰り返すと、外の人は「中の人は中国語を理解している」と判断するが、それは誤りである。
・まるで知能があるような受け答えができるかを調べるというチューリングテストに合格しても本当に知能があるかはわからないという議論である。
・これは、チューリングテストを拡張した、心がどこに存在するのか、あるいは意味はどこにあるのか、という問題に対する思考実験だといえる。
★シンボルグラウンディング問題(記号設置問題)
・1990年に認知科学者のスティーブン・ハルナッドにより議論されたもので、記号(シンボル)とその対象がいかにして結びつくかという問題。
・人間の場合、「シマ」の意味も「ウマ」の意味もよくわかっているため、本物のシマウマを初めて見たとしても、「あれが話に聞いていたシマウマかもしれない」とすぐに認識できる。
・ところが、コンピュータは「記号(文字)」の意味が分かっていないため、「シマウマ」という文字はただの記号の羅列に過ぎず、「これがあのシマウマだ」という認識はできない
・コンピュータにとって、「シマウマ」という記号と、それが意味するものが結びついていない(グラウンディングしていない)ことが問題である。これはシンボルグラウンディング問題と呼ばれる。
★身体性
・人間には身体があるからこそ物事を感知したり、思考したりできるという考えがある。このようなアプローチは**「身体性」に着目したアプローチ**と呼ばれる。
★知識獲得のボトルネック
・1970年代後半はルールベース機械翻訳が一般的であった
・1990年以降は統計的機械翻訳が主流となった。しかし、一般常識がないため正しく訳せないという問題を持つ。
・人間が持っている一般常識は膨大で、それらの知識をすべて扱うことは極めて困難である。
・コンピュータが知識を獲得することの難しさを、知識獲得のボトルネックと呼ぶ。
・2010年ごろから、ニューラル機械翻訳というディープラーニングを用いた機械翻訳が登場し、知識獲得のボトルネックを乗り越えることを期待されている。
人工知能をめぐる動向
探索・推論
迷路(探索木)
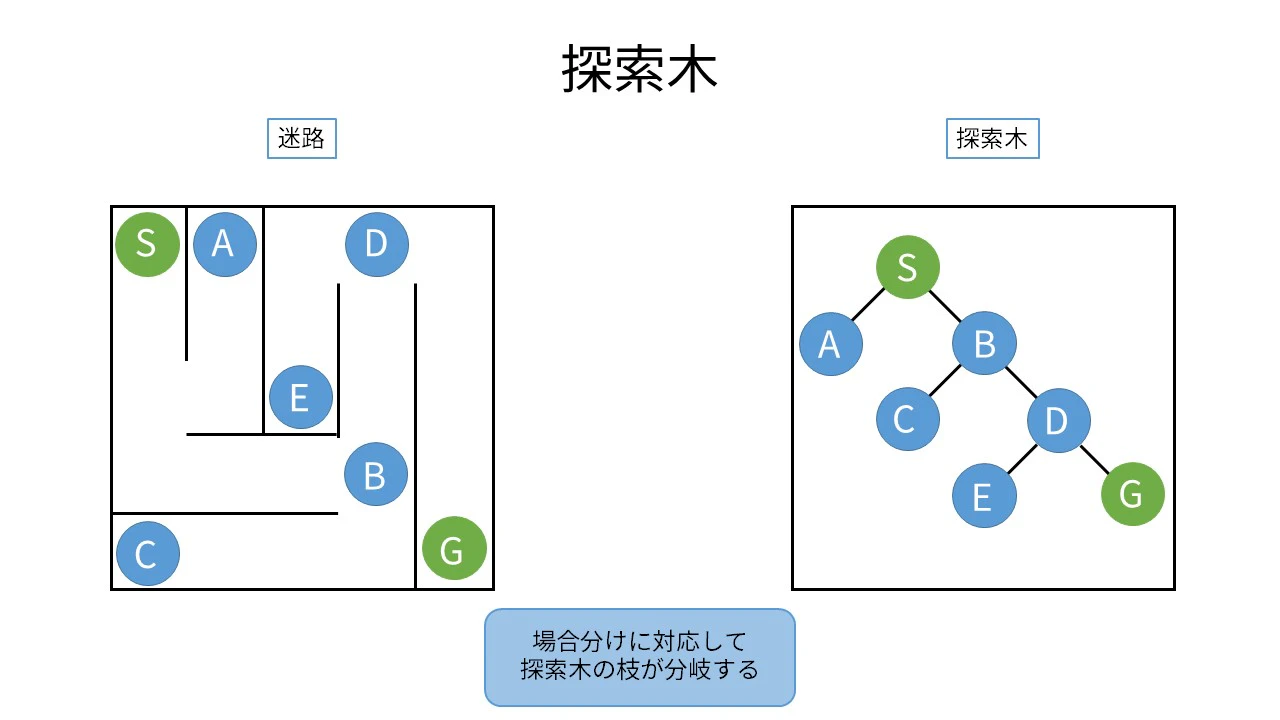
・迷路の問題をコンピュータで扱えるような形式に変換することが必要
・分岐と行き止まりに記号を付け、枠を取り去るとツリー構造をしていることがわかる。これを探索木と呼ぶ。
・ゴールにたどり着くには場合分けを続ける必要がある。探索にかかる時間は検索する方法によって変わる。
・基本的な検索手法として、幅優先探索、深さ優先探索という2つの方法がある。
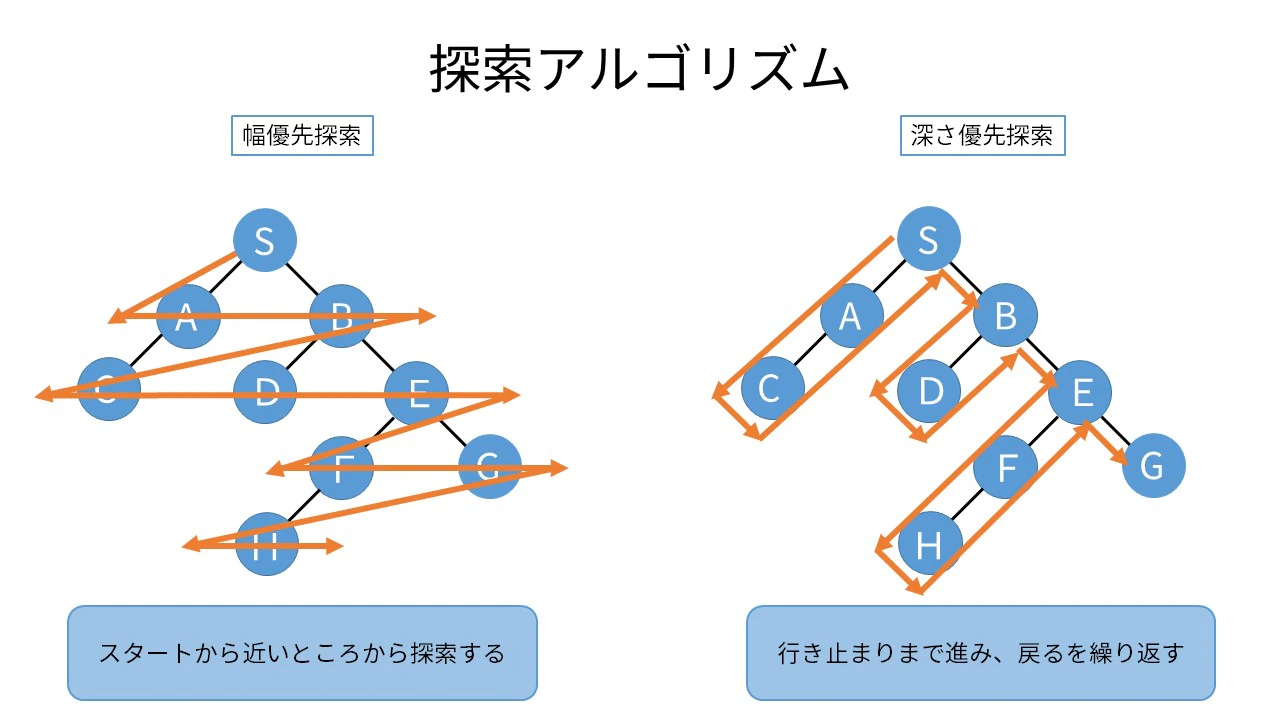
★幅優先探索
・出発点に近いノード順に検索する
・最短距離でゴールにたどり着く解を必ず見つけることができる
・しかし、立ち寄ったノードをすべて記憶しておかなければならないので、複雑な迷路になると、メモリ不足で処理を続行できなくなる可能性がある
★深さ優先探索
・あるノードから行けるところまで行って、行き止まりになったら1つ手前のノードに戻って探索を行うということを繰り返す
・メモリはあまり必要ない
・しかし、解が見つかったとしてもそれが最短であるとは限らない
ハノイの塔
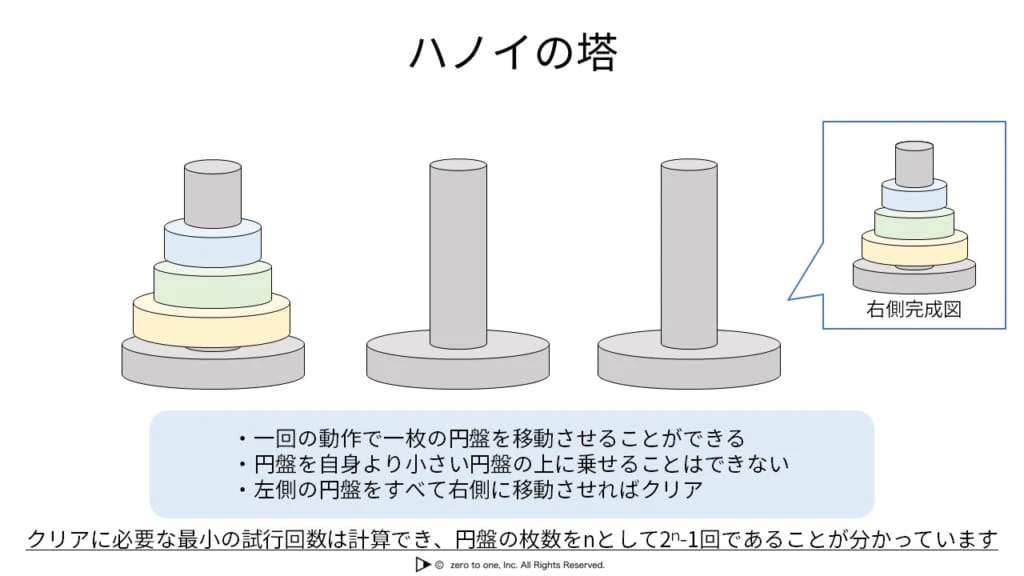
・探索木を使ってハノイの塔というパズルを解くことができる
・クリアに必要な移動回数は2^n-1回である。n=円盤の枚数
ロボットの行動計画
・ロボットの行動計画も探索を利用して作成できる。
・プランニングと呼ばれる技術であり、古くから研究されている。
★STRIPS(Stanford Research Institute Problem)
・あらゆる状態**<前提条件>**について、**<行動>**と**<結果>を記述しておけば、目標とする状態に至る行動計画を立てることができる
・この、<前提条件><行動><結果>という3つの組み合わせで記述するSTRIPSが有名
★SHRDLU
・1968年から1970年にかけてテリー・ウィノグラードによって開発されたシステム
・英語による支持を受け付け、コンピュータ画面に描かれる「積み木の世界」に存在する様々な物体を動かすことに成功
・この成果はのちにCycプロジェクト**に引き継がれていく
ボードゲーム(オセロ・チェス・将棋・囲碁)
・すべての組み合わせをしらみつぶしに探索することは不可能
・そこで、効率よく探索するためにコストの概念を取り入れる
・あらかじめ知っている知識や経験を利用してコストを計算すれば、探索を短縮できる。この時に利用する知識をヒューリスティックな知識と呼ぶ
★Mini-Max法
・考え方は単純であり、自分の番では自分が有利(つまり自分のスコアが最大)になるように手を打つべきで、逆に相手の番では相手が有利になるように相手は手は打つはずだとということを前提に戦略を立てる
αβ法
・Mini-Max法は単純なゲーム戦略であるが、論理的に感が手無駄な探索が生じる。
・その無駄を省く方法をαβ法と呼ぶ。
・評価する必要のないノードを探索対象から外す。
・βカット:スコアが最小となるものを選択する局面(つまり、相手の局面)で、探索する必要のない自分の枝を切り落とす行為
・αカット:スコアが最大となるものを選択する局面(つまり、自分の局面)で、探索する必要のない相手の枝を切り落とす行為
モンテカルロ法
・コンピュータが人間に勝つのが難しいのは、ゲーム盤のスコア(コスト関数)に問題があるということがわかってきた
・モンテカルロ法では、ゲームがある局面まで進んだらスコアで局面を評価することを放棄してしまう。その代わり、2人の仮想的なプレイヤーを演じて、とにかく終局(プレイアウト)させる。
・これを複数回実行することで、勝率の高い方法がわかり、ゲームのスコアを評価できる。
・人間がスコアのつけ方を考えるよりも、とにかく数多く打って最良のものを選ぶという評価方法の方が優れていることがわかった。
・しかし、19×19の囲碁では、全く歯が立たない状況が続いた。モンテカルロ法はブルートフォース(力任せ)で押し切る方法なので、探索しなければならない組み合わせの数が増えると、立ち行かなくなる。
・AlphaGoはディープラーニングの技術を使って人間のプロに勝利した。
知識表現
★イライザ(ELIZA)
・1964年から1966年にかけてジョセフ・ワイゼンバウムによって開発された人口無脳の元祖
・あたかも本物の人間と対話しているような錯覚(イライザ効果)に陥る
エキスパートシステム
★マイシン(MYCIN)
・1970年代にスタンフォード大学で開発された血液中のバクテリアの診断支援をするルールベースのプログラム
・69%の確率で正しい処方をすることができた
★DENDRAL
・スタンフォード大学のエドワード・ファイゲンバウムは1960年代に未知の有機化合を特定するエキスパートシステムを開発した。1977年に実世界の問題に対する技術を重視した「知識工学」を提唱し、1970年代後半から1980年題にわたり多くのエキスパートシステムが開発されるようになった
知識開発のボトルネック(エキスパートシステムの限界)
・専門家が持つ知識の多くは経験的なものであり、暗黙的であるため、上手にヒアリングで聞き出さなければならなくなった。
・このような事情から、知識獲得のための知的なインタビューシステムなどの研究もおこなわれた。
・知識ベースの構築において、数が膨大になると矛盾等が生じ知識ベースを保守するのが困難になることも分かった
・コンピュータで知識を扱うための方法論が注目されるようになった
意味ネットワーク
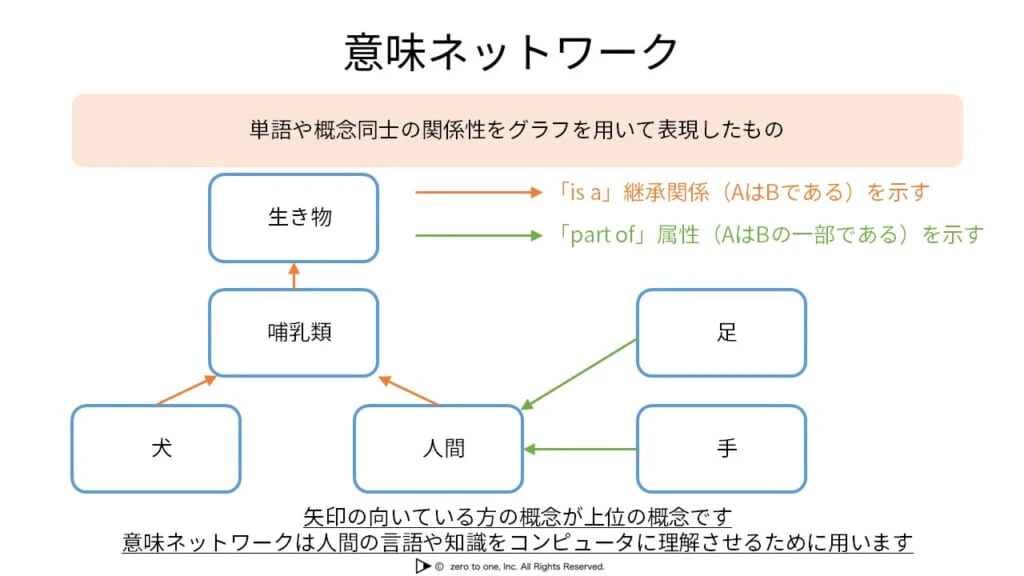
・「概念」をラベルの付いたノードで表し、概念間の関係をラベルの付いた矢印で結んだネットワークとして表す
・「is-a」の関係は継承関係を表し、例えば「動物は生物である」「哺乳類は動物である」ことを表現する。
・「part-of」の関係は属性を表し、例えば「目は頭部の一部である」「肉球は足の一部である」ということを表現する。
オントロジー(概念体系を記述するための方法論)
★Cycプロジェクト
・ダグラス・レナートによって1984年からスタートしたすべての一般常識をコンピュータに取り込もうというプロジェクト
・現在も継続中
★オントロジー
・知識を体系化する方法論が研究されるようになり、これがオントロジーの研究につながる。
・オントロジーは、エキスパートシステムのための知識ベースの開発と保守にはコストがかかるという問題をきっかけに発生している。
・オントロジーとは、本来は哲学用語で存在論(存在に関する大系理論)という意味。人工知能の用語としてはトム・グルーパーによる「概念化の明示的な仕様」という定義が広く受け入れられている
・オントロジーの目的は知識の共有と活用である。そこで、知識を記述するときに用いる「言葉(語彙)」や「その意味」、また「それらの関係性」を、ほかの人とも共有できるように、明確な約束事として定義している
・意味ネットワークは記述方法についての約束事は決まっていない。
・オントロジーにおいて、「is-a」の関係と「part-of」の関係は特に重要。
★「is-a」の関係
・上位概念と下位概念の関係を表し、その関係には推移律が成立する
例)A>BでありB>Cであれば、A>Cという関係が自動的に成立する
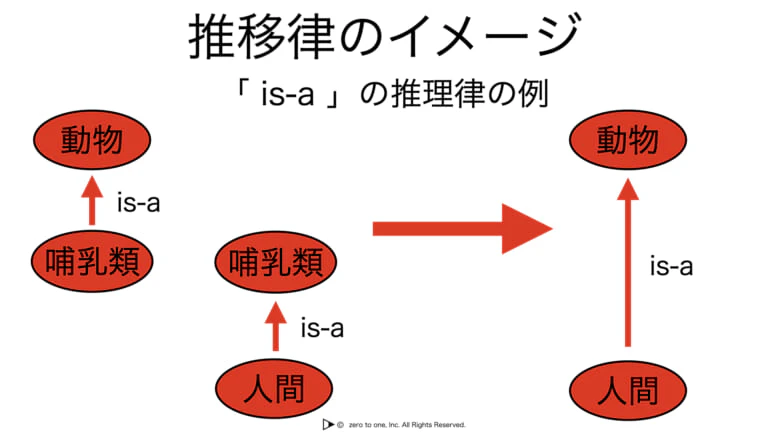
・じゃんけんでは成立しないなど、関係の種類によって推移律が成立する/しないは異なる
「part-of」の関係
・全体と部分の関係を表している
・推移律が成立するとは限らない
・「part-of」にはいろいろな種類の関係があり、最低5種類の関係があることがわかっている
★オントロジーの構築
・ヘビーウェイトオントロジー(重量オントロジー):
構成要素や関係について哲学的な考察が必要なため、人間が関わる傾向が強く、時間やコストがかかる。
Cycプロジェクトが現在まで続いていることもその一例
・ライトウェイトオントロジー:
完全に正しくなくても使えるものであればよいという考え
Webデータを解析して知識を取り出すウェブマイニングやビッグデータを解析して有用な知識を取り出すデータマイニングで利用されている
・セマンティックWeb:Webサイトが持つ意味をコンピュータに理解させ、コンピュータ同士で処理を行わせるための技術
・LOD(Linked Open Data):コンピュータ処理に適したデータを公開・共有するための技術
ワトソンと東ロボくん
★ワトソン
・IBMが開発した
・Question-Answering(質問応答)という研究分野の成果であり、ウィキペディアの情報を基にライトウェイトオントロジーを生成して解答している
・質問の意味を理解しているのではなく、質問に含まれるキーワードと関連しそうな答えを高速に検索しているだけ
・ライトウェイトオントロジーの活用できる環境が整ってきており、現在は幅広い分野で活用されている
★東ロボくん
・東大合格を目指す人工知能
・読解力に問題があり、何らかの技術的なブレイクスルーがない限り東大合格は不可能という理由から2017年に開発が凍結された
機械学習・深層学習
機械学習
・人工知能のプログラム自身がデータから学習する仕組みのこと
・サンプルデータの数が多ければ多いほど望ましい学習結果が得られる
・十分なデータが蓄積されるまでは、大量のデータを必要としない手法が主流であった。その1つがルールベースの手法である。
・現在でも日用品から金融システムなど、高速かつ高い信頼性が求められるシステムで広く利用されている。一方で、想定外の状況に対応することは難しいというデメリットもある
・機械学習はビッグデータというキーワードとともに注目を集めるようになった
・機械学習は元々パターン認識の分野で長年蓄積されてきた技術だが、ユーザーの好みを推測するレコメンデーションエンジンや迷惑メールを検出するスパムフィルターなども機械学習よって実用化されたアプリである。
・機械学習では**「注目すべきデータの特徴」の選び方が性能を決定づける。例えば、ビールを出荷するとき、「店舗の壁の色」に注目しても意味がない
・特徴量:注目すべきデータの特徴を量的に表したもの
・特徴量表現学習:機械学習自身に特徴量を発見させるアプローチ
・ディープラーニング:「特徴量表現学習」を行う機械学習アルゴリズムの一種**
・ニューラルネットワーク自身が複数ステップのコンピュータプログラムを学習できる:前に実行された命令の実行結果を利用してプログラムを作成できる
・この視点に立てば、特徴量は入力データとは無関係で、与えられた問題を解くために必要な処理(プログラム)に役立つ情報が特徴量として抽出されていると考えられる
ディープラーニング
・パーセプトロン:アメリカの心理学者フランク・ローゼンプラットが1958年に提案した学習可能なニューロンモデルの元祖
1969年にマービン・ミンスキーらによって、「パーセプトロンは直線で分離できない分類問題に対応できない」というパーセプトロンの限界が明らかとなり、ブームが下火になっていく。1940年代から1970年代初期はニューラルネットワークの第1次ブームと呼ばれる。
・ディープラーニング:深く多層化したニューラルネットワークを使って、データに潜む特徴を自動的に学習する手法
初めは、最後の層のニューロンだけを学習させることが一般的な限界だった。
1986年、多層パーセプトロン(複数のパーセプトロンを階層的に接続したもの)とその学習法(誤差逆伝播法)をデビット・ラメルハートらが提案し、ミンスキーらが指摘したパーセプトロンの限界を解決できることがわかると、第2次ニューラルネットワークブームが起きた。
・ネオコグニトロン:1979年に福島邦彦が発表した生物の視覚系の神経回路を模倣したニューラルネットワーク
・LeNet:ネオコグニトロンと同等なアイデアを採用した「畳み込みニューラルネットワーク」の構造。1989年、ヤン・ルカンによって名付けられた。
アメリカのベル研究所からヴァプニクらが開発した「サポートベクターマシン」が機械学習のアプローチとして人気を集めるようになり、第2次ニューラルネットワークブームは1990年代中頃に終焉した。
★ILSVRC(ImageNet Large Scale Visual Recognition Challenge):画像認識の精度を競い合う競技会
・2012年にトロント大学のジェフリー・ヒントンが率いるSuper Vision(チームの名前)が圧倒的な勝利を収めた。(エラー率15.3%という衝撃的な結果)
・この勝利をもたらしたものが**新しい機械学習の方法「ディープラーニング」**であった。この時に開発されたニューラルネットワークのモデルはAlexNetと呼ばれる。
・2015年には人間の画像認識率である4%を追い抜き話題となった。
LLM(大規模言語モデル):大量の言語データを学習する能力を持つ、大規模なニューラルネットワーク
・トランスフォーマー(Transformer):単語と単語の関係性(これは「アテンション(注意力)」と呼ばれる方法を使って求められる)を広範囲にわたって学習する
・これにより、様々な文脈で使われる単語の意味やニュアンスを深く理解したり、任意の単語間の関係性を複数同時に効率よく計算したりすることが可能になった。
・事前学習:与えられた大量の文章を学習することで、一般的な言語の構造、文法、語彙などの基本を学ぶこと
・ファインチューニング(微調整):特定のタスクや応用分野に焦点を当てた訓練
・こうすることで不適切な表現等を避け、文脈に合った論理的な回答を生成することができる。
機械学習の具体的手法
代表的な手法
教師あり学習
・与えられたデータ(入力)を元に、そのデータがどんなパターン(出力)になるのかを識別・予測するもの
例)過去の売り上げから、将来の売り上げを予測、与えられた動物の画像が何の動物かを識別
・回帰問題:連続値を予測する問題
・分類問題:離散値を予測する問題
★線形回帰
・データの分布があったときに、そのデータに最も当てはまる直線を考える
・次元が大きくなっても問題ない
・線形回帰に正則化項を加えた手法としてラッソ回帰、リッジ回帰がある。
・単回帰分析:1種類の入力だけを用いて行う回帰分析
・重回帰分析:複数種類の入力を用いる場合
★ロジスティック回帰
・分類問題に用いる手法
・シグモイド関数をモデルの出力に用いる
・与えられたデータが正例(+1)になるか、負例(0)になるかの確率が求まる。基本的に0.5を閾値として正例・負例を分類する
・多クラス分類の場合は、ソフトマックス関数を用いることになる
・2クラス分類問題:予測したい出力が2種類
・多クラス分類問題:予測したい出力が3種類以上
★ランダムフォレスト
・決定木をそれぞれ並列に学習するため、決定木の数が増えすぎても制度が悪くなることはない
・それぞれの決定木のパラメータを制御することで汎化性能を高める
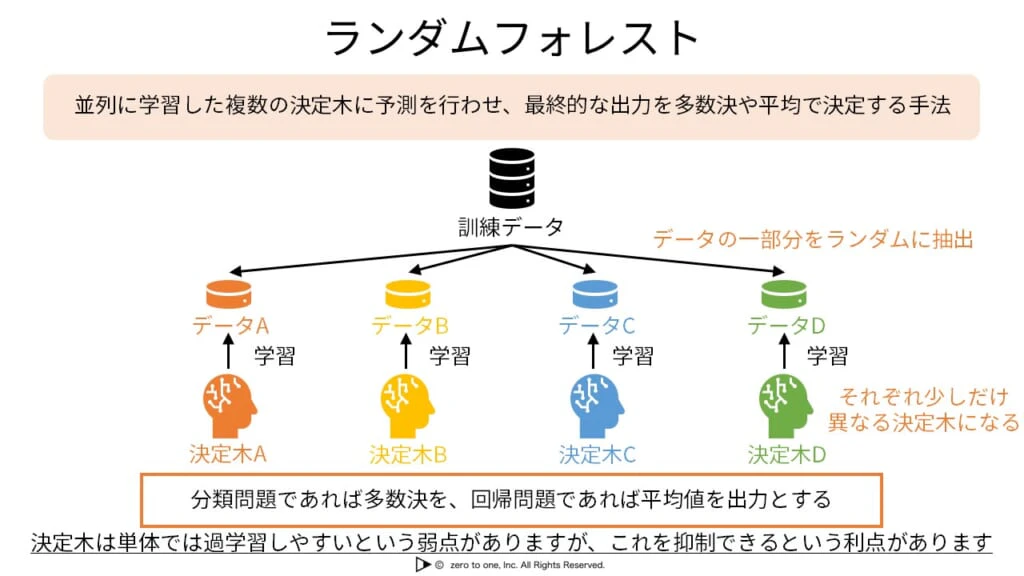
・ブーストトラップサンプリング:それぞれの決定木に対してランダムに一部のデータを取り出して学習に用いること
・複数の決定木を作成するため、予測結果はそれぞれの決定木で異なる場合が発生する。そのため多数決をとってモデルの最終的な出力を決定する
・アンサンブル学習:複数のモデルで学習させること
・バギング:全体から一部のデータを用いて複数のモデルを用いて学習する方法
・つまり、ランダムフォレストはバギングの中で決定木を用いている手法
★ブースティング
・バギングと同様、複数のモデルを学習させるアプローチをとる
・バギングは複数のモデルを並列に学習し、ブースティングは直列に学習する
・AdaBoost:直前のモデルが誤認識してしまったもデータの重みを大きくし、正しく認識できたデータの重みを小さくする。GBDTライブラリではない。
・最終的に弱識別器を1つのモデル(強識別器)として統合する
・勾配ブースティング:各データの出力と予測の差をまとめた目的関数を最小化するために勾配降下法を用いた手法
・XGBoostというアルゴリズムによって高速に学習計算をすることができるようになった。オープンソースのGBDTライブラリである。
・しかし、ブースティングはバギングよりも学習に時間がかかってしまう。一方、得られる予測制度は高くなる傾向にある
★サポートベクターマシン(SVM)
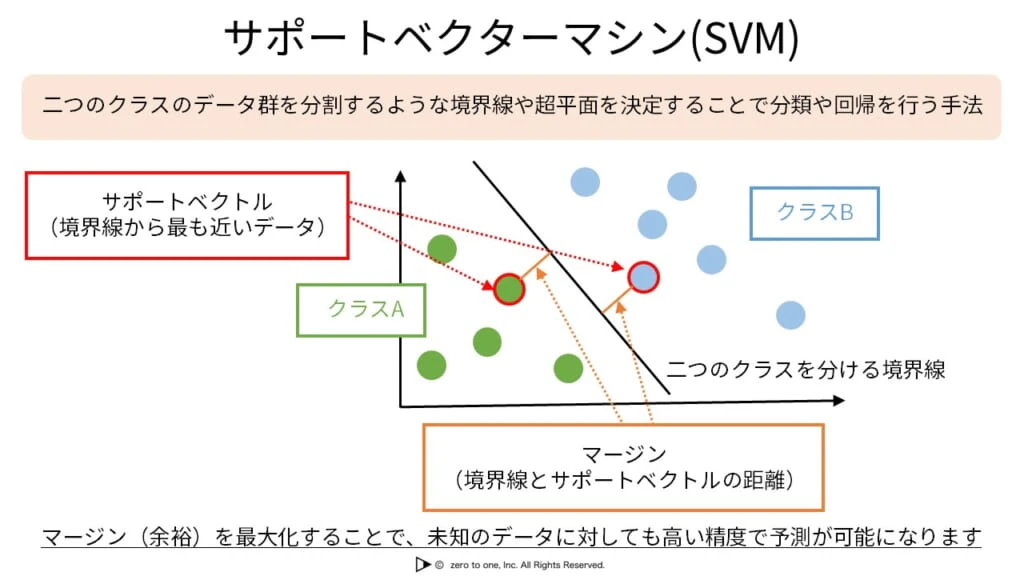
・異なるクラスの各データ点との距離が最大となるような境界線を求めることで、パターン分類を行う
・この距離を最大化することを、マージン最大化という
・データをあえて高次元に写像することで、その写像後の空間で線形分類できるようにするというアプローチがとられた。
・この写像に用いられる関数のことをカーネル関数という。その際計算が複雑にならないようにするテクニックのことをカーネルトリックという
★自己回帰モデル(ARモデル)*
・対象とするデータは時系列データ(重要)
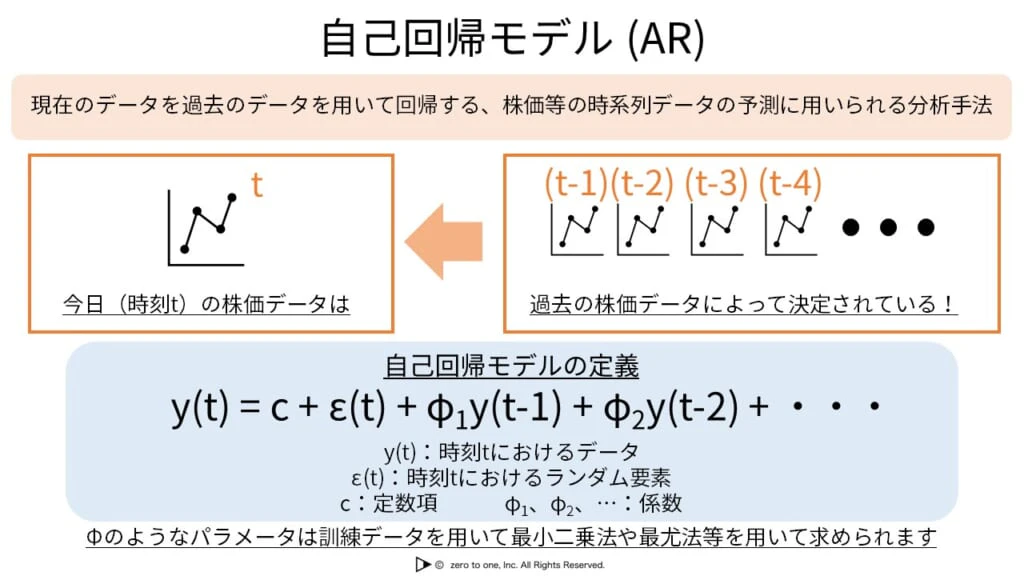
・ベクトル自己回帰モデル(VARモデル):自己回帰モデルの入力がスカラーではなくベクトル
教師なし学習
・用いるデータには出力がなく、入力データそのものが持つ構造・特徴を対象に学習する
★階層なしクラスタリング(k-means法)
・元のデータからグループ(クラスタ)構造を見つけ出し、それぞれをまとめる
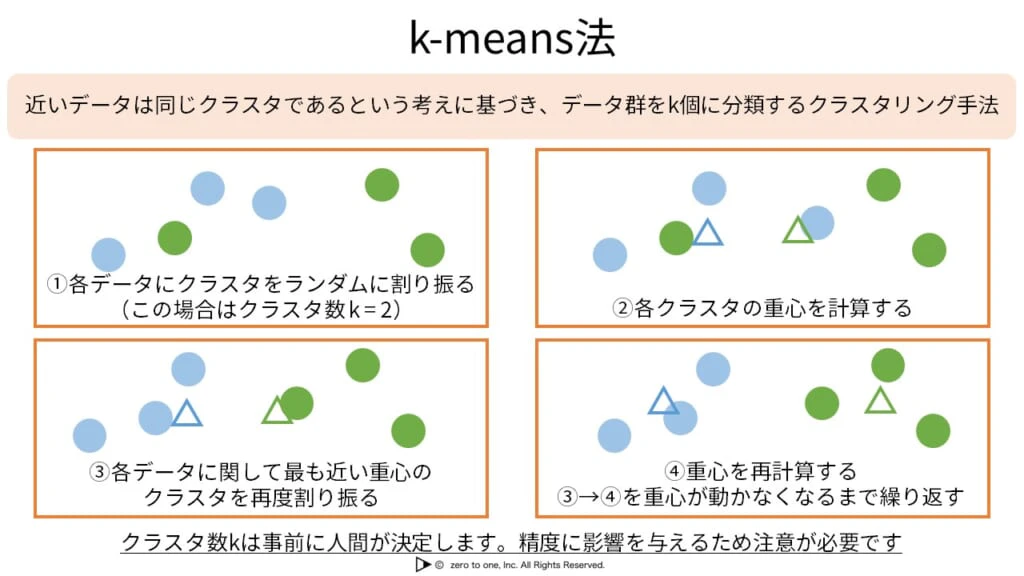
★階層ありクラスタリング
・k-means法はデータを別々のクラスタに並列に分類するが、階層ありクラスタリングではクラスタの階層構造を求めるまで行う
・代表的な手法にウォード法や最短距離法などがある
・これを表す樹形図のことをデンドログラムという
★主成分分析(PCA)
・データの特徴量間の関係性、すなわち相関を分析することでデータの構造をつかむ手法
・特に特徴量の数が多い場合に用いられ、相関を持つ多数の特徴量から、相関の無い少数の特徴量へと次元削減することが目的
・次元削減の手法として、他には**特異値分解(SVD)**も、主に文章データを扱う場合によく用いられる。
・多次元尺度構成法(MDS):2次元への次元削減・可視化手法
・t-SNE:2次元・3次元への次元削減・可視化手法
★協調フィルタリング
・レコメンデーションに用いられる手法の一つ
・「対象ユーザーは買っていないが、似ているユーザーは買っている商品を推薦する」というもの
・コールドスタート問題:ほかのユーザーの情報を参照するため、事前にデータがない限り、推薦を行うことができないという問題
・コンテンツデータベースフィルタリング:商品側に何かしらの特徴量を付与し、特徴が似ている商品を推薦する。コールドスタート問題を回避できる
★トピックモデル
・複数のクラスにデータを分割するのが大きな特徴
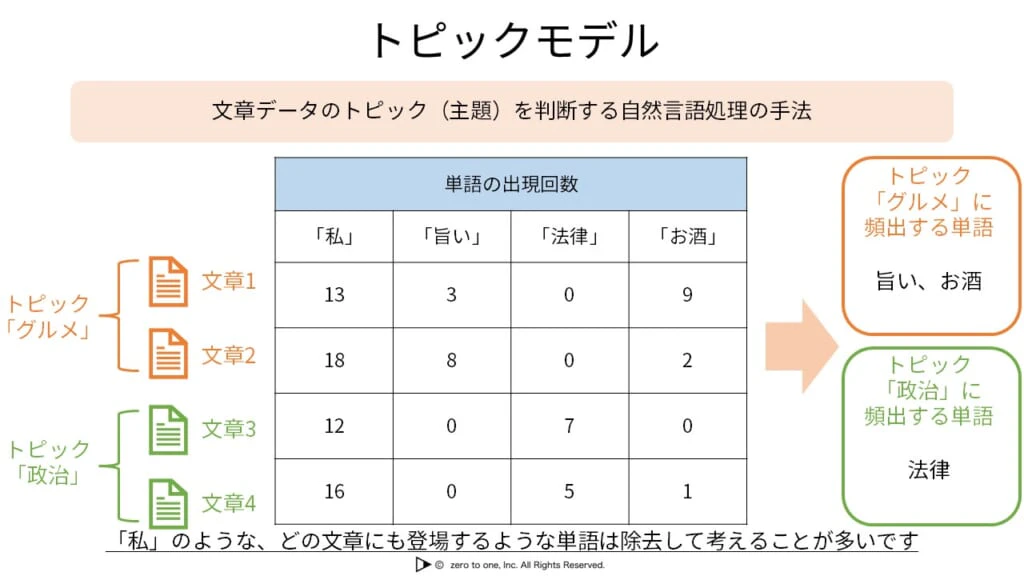
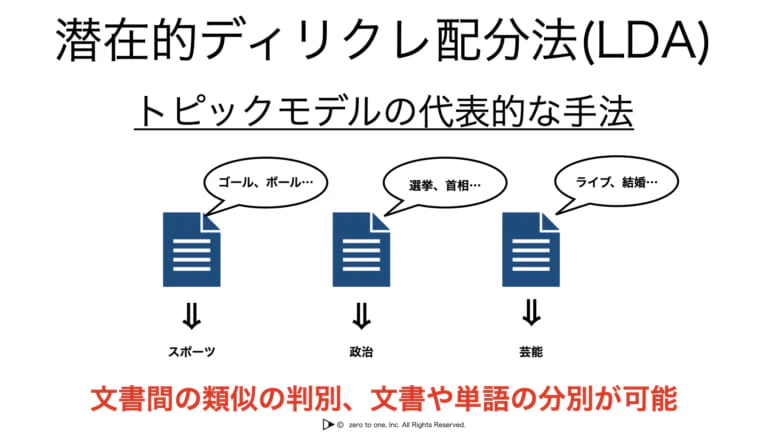
・潜在的ディリクレ配分法(LDA):トピックモデルの代表的な手法
・文書集合から各文書におけるトピックの混合比率を推定する手法
・1つの文書には複数の潜在トピックが存在すると仮定する
強化学習
・行動を学習する仕組み
・ある環境下で、目的とする報酬(スコア)を最大化するためにはどのような行動をとっていけばよいかを学習する
・状態、行動、報酬のやり取りを1時刻ごとに進めて考える
・割引率:将来価値を現在価値に割り引く際に使う率
・例)「今の100円と1年後の100円なら今の100円の方が価値がある」
★パンディットアルゴリズム
・強化学習では将来の累積報酬が最大となるような行動を選択する必要がある
・一連の行動の組み合わせは無数にあるため、行動の選択肢を考えるべきかが大きな課題。そこで用いられる考え方が活用と探索
・活用:現在知っている情報の中から報酬が最大となるような行動を選ぶ
・探索:現在知っている情報以外の情報を獲得するために行動を選ぶ
・活用と探索はトレードオフの関係にあり、どうバランスをとるのかがカギである。そこで用いられるのがパンティットアルゴリズム(バランスを取りましょう、というもの)
・ε-greedy方策:基本的には活用、すなわち報酬が最大となる行動を選択するが、一定確率εで探索、すなわちランダムな行動を選択する
・UCB方策:期待値の高い選択肢を選ぶのを基本戦略としつつ、それまで試した回数が少ない行動は優先的に選択するというもの
・方策:ある状態からとりうる行動の選択肢、およびその選択肢をどう決定するかの戦略
★マルコフ決定過程モデル
・マルコフ性を仮定したモデルのこと
・マルコフ性:現在の状態から将来の状態に遷移する確率は、現在の状態にのみ依存し、それより過去には一切依存しないという性質
・逐次的に計算を繰り返すことにより、現在の値には過去の情報がすべて織り込まれていることになる。
★価値関数
・状態価値関数:各状態における価値を表す関数
・行動価値関数:ある状態から次の状態に移る行動の価値を表す関数、この関数の値をQ値と呼ぶ
・Q値を最適化する手法にはQ学習やSARSAがある
★方策勾配
・最適な方策を求めるのは非常に難しいが、直接最適な方策を見つけ出そうというアプローチも存在する
・方策勾配法:方策をあるパラメータで表される関数とし、そのパラメータを学習することで、直接方策を学習していくアプローチ
・ロボット制御など、特に行動の選択肢が大量にあるような課題で用いられる
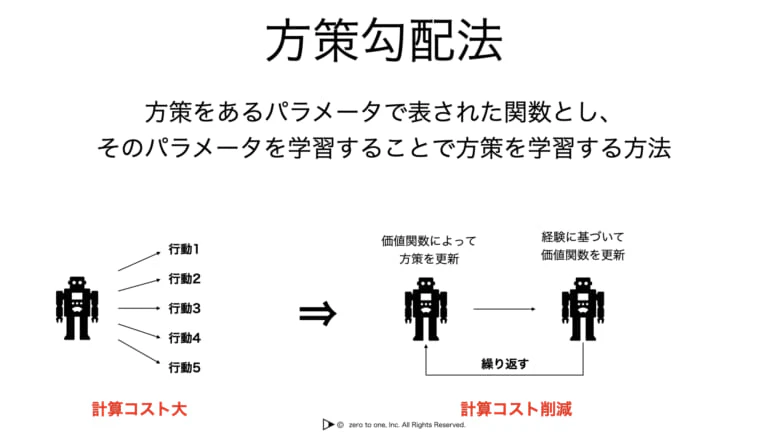
・具体的な手法として、REINFORCEがあり、AlphaGoにも活用されている
・価値関数ベースおよび方策勾配ベースの考え方を組み合わせたActor-Criticというアプローチも存在する
モデルの選択・評価
・適切なモデルの評価は、未知のデータに対しての予測能力を見ること
・疑似的に未知のデータを作り出すために、学習用のデータを訓練データとテストデータに分割する。
・このようにデータを分割して評価することを交差検証という
・ホールドアウト検証:事前にデータを訓練データとテストデータに分割する方式
・全体のデータが少ない場合、たまたまテストデータに対する当てはまりがよくなってしまう可能性が高くなる。
・k-分割交差検証:訓練データ、テストデータの分割を複数回行い、それぞれで学習、評価を行うというアプローチ。また、さらに訓練データが訓練データ、検証データに分割される場合もある
予測誤差
・具体的なモデルの良し悪しを評価する基準として、予測誤差を使うアプローチがある
・平均二乗誤差(MSE):予測値と実際の値の差分をそれぞれ2乗し、総和を求めたもの
・二乗平均平方根誤差(RMSE):平均二乗誤差のルートをとったもの
・平均絶対値誤差(MAE):2乗の代わりに絶対値をとったもの
正解率・適合率・再現率・F値
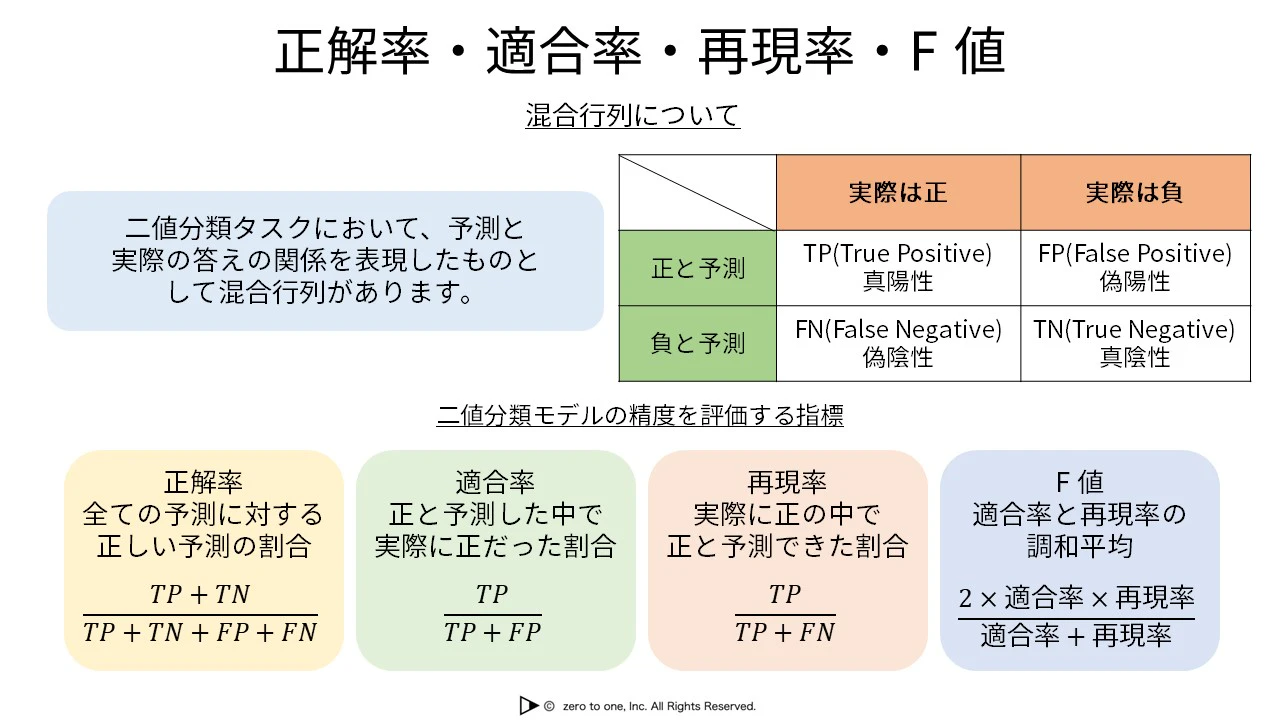
混同行列
・真陽性(TP):実際陽性、予測も陽性
・偽陽性(FP):実際陰性、予測は陽性
・偽陰性(FN):実際陽性、予測は陰性
・真陰性(TN):実際陰性、予測も陰性
<評価指標>
・正解率(Accuracy):正しく予測できた確率
・適合率(陽性適合率)(Precision):陽性と予測したうち、正しく予測できた確率
・再現率(真陽性率)(Recall):実際は陽性だったうち、正しく陽性であると予測できた確率
・F値(F measure):適合率と再現率の調和平均
・正解率はモデルの評価としてよく用いられる。しかし、適切でない場合もある
例)工場において、「不良品はめったにないから1万個すべて正常」と予測し、3つ不良品があった場合正解率は99.97%になるが、不良品を全く見つけられていないため実用的ではない。
・この場合は、「実際に不良品である者のうち、どれだけ不良品と見抜くことができたか」を見るのが適切
・いずれの指標でも、モデルの性能はテストデータを用いて評価・比較する
・訓練データにのみ通用するモデルは不適切であり、この状態は過学習もしくは過剰適合(overfitting)という。
ROC曲線とAUC
・正解率とは異なった観点のモデル評価指標として、ROC曲線とAUC
・ROC曲線:閾値を変えて、真陽性率と偽陽性率をプロットしていく
・真陽性率:実際は陽性だったうち、正しく陽性であると予測できた確率
・偽陽性率:実際は陰性だったうち、間違えて陽性であると予測した確率
・AUC:ROC曲線より株の面積のこと
モデルの選択と情報量
・モデルを複雑にすればするほど複雑な表現ができるが、過学習してしまう可能性もある
・オッカムの剃刀:「ある事柄を説明するためには、必要以上に多くを仮定すべきでない」という指針
・「では、どれくらいモデルを複雑にすればよいのか」の目安として情報量基準という指標が用いられる
・赤池情報量基準(AIC)とベイズ情報量基準(BIC)
ディープラーニングの概要
ニューラルネットワークとディープラーニング
単純パーセプトロン
・入力層と出力層の二層のみから構成されるシンプルなネットワーク
・出力が0か1の値をとるようにすることで、正例と負例の分類を可能にする
・シグモイド関数を用いることで、0から1の値をとるようにし、閾値の調整をすることもできる
・このような、層の間をどのように伝播させるかを調整する関数を活性化関数という。
多層パーセプトロン
・単純パーセプトロンは線形分類問題しか解くことができない
・そこで、入力層ー出力層以外にさらに層を追加するというアプローチが考案された
・層を追加したモデルは多層パーセプトロンと呼ばれる
・入力層と出力層の間に追加された層を**隠れ層(中間層)**という
モデルの学習
・多層パーセプトロンによってモデルの表現力は向上したが、実際に適切な予測を行うにはモデルの学習が必要
・重みをどのような値にすべきか決める必要がある
・パラメータ:学習によって求める値のこと
・ハイパーパラメータ:モデルの構造や振る舞いを決めるものの、最適化計算で求めることができない値のこと
・ニューラルネットワークでは、予測誤差を**誤差関数(損失関数)**とし、「誤差関数を最小化する」というアプローチをとる
ディープラーニングの基本
・ディープラーニングとは、隠れ層を増やしたニューラルネットワークである
・「ディープラーニング」は人工知能の研究分野を指す
・ニューラルネットワークのモデル自体はディープニューラルネットワークと呼ぶ
ハードウェアの制約と進歩
・ムーアの法則:「半導体の性能と集積は、18カ月ごとに2倍になる」という経験則
・隠れ層を増やそうとしても、計算に耐えられる半導体が必要であるため、ディープラーニングの進歩は半導体の性能・集積がカギを握ることになる
・CPU:コンピュータ全般の作業を処理する役割を担う
・GPU:画像処理に関する演算を担う、大規模な並列演算処理に特化
・ディープラーニングでは行列やベクトルによる計算が主であり、同じような計算処理が大規模で行われるため、GPUは向いている
・GPGPU:画像以外の目的での使用に最適化されたGPUのこと
・GPGPUの開発をリードしているのはアメリカの半導体メーカーであるNVIDIA社
・TPU(Tensor Processing Unit):Google社が開発したテンソル(ベクトルや行列)計算処理に最適化されたチップ
ディープラーニングのデータ量
・バーニーおじさんのルール:「モデルのパラメータ数の10倍のデータ数が必要」という経験則
誤差関数
★平均二乗誤差関数
・平均二乗誤差をそのまま誤差関数として用いる
・数学の最小値を求める問題と同じ流れで、「微分してゼロになるような値を求める」ことになる
★交差エントロピー誤差関数
・交差エントロピー:2つの確率分布がどれくらい異なるかを定式化したもの
・これを誤差関数として利用したのが交差エントロピー誤差関数であり、分類問題でもっと用いられる誤差関数
・交差エントロピーの式がシグモイド関数やソフトマックス関数に含まれる指数計算と相性がいいため、分類問題で用いられていた(今は機械が自動で計算してくれる)
★その他の誤差関数
・距離学習:データ間の類似度を推定するための手法
例)顔認証、類似データの検索
・これをディープラーニングに応用した手法を深層距離学習と呼ぶ
・Siamese Network(誤差関数としてContrasive Lossを使う)
・Triplet Network(誤差関数としてTriplet Lossを使う)という手法が有名
・ディープラーニングの発展によって、生成問題も精度高く実現できるようになった
・生成モデル:「今観測できているデータは何らかの確率分布に基づいて生成されるはずだ」という考えに基づいて、そのデータを生成している確率分布をモデル化しようと試みている
・目的はデータ分布になるべく近いモデル分布を求めることであるため、両者の分布の「ズレ」を誤差関数として定義すればよい。
・この「ズレ」を測る指標として、**カルバック・ライブラー情報量(KLダイバージェンス)とイェンゼン・シャノン情報量(JSダイバージェンス)**がある
・深層生成モデル:生成モデルにディープラーニングを活用したモデル
・深層生成モデルの一つである**変分オートエンコーダ(VAE)**は、カルバック・ライブラー情報量をベースとした誤差関数(目的関数)が最適化計算に用いられる
正規化
・過学習に対する対応策を総じて正則化と呼ばれる
・誤差関数にペナルティ項を課すという手法が広く用いられている
★L1正則化:一部のパラメータの値をゼロにすることで、不要なパラメータを削減することができる
・L1ノルムは重みなどモデルパラメータの各成分の絶対値の和に相当する
・線形回帰に対してL1正則化を適用した手法をラッソ回帰と呼ぶ
★L2正則化:パラメータの大きさに応じてゼロに近づけることで、汎化された滑らかなモデルを得ることができる
・L2ノルムは各成分の2乗和の平方根であり距離に相当する
・線形回帰に対してL2正則化を適用した手法をリッジ回帰と呼ぶ
・両者を組み合わせた手法をElastic Netと呼ぶ
・ゼロではないパラメータで正則化するL0正則化もあるが、計算コストが非常に大きくなるため一般的には用いられない
★ドロップアウト:モデルの学習の行い方を工夫することで過学習を防ぐアプローチ
・**ランダムにニューロンを「除外する」**という工夫をして毎回形の異なるネットワークで学習を行う
・ドロップアウトは内部的にアンサンブル学習を行っていることになる
最適化手法
・実際のモデル学習では、解析的に買いを求めるのではなく、アルゴリズムを用いて、最適解を探索するというアプローチをとる
★勾配降下法:**「勾配に沿って降りていくことで解を探索する」**手法
・イテレーション:何回繰り返し計算したかを表すもの(kで表す)
・学習率:勾配に沿って一度にどれだけ降りていくかを決めるハイパーパラメータ(αで表す)
★バッチ勾配降下法(最急降下法):全データの予測誤差の総和を用いて更新式の計算をすること
・バッチとはデータのかたまりを表す
・バッチを用いて学習を行うため、バッチ勾配降下法による学習のことをバッチ学習と呼ぶ。バッチ学習とは用意した学習データすべてを利用して学習する手法のこと。
★確率的勾配降下法:すべてのデータの中からランダムなデータ1つのみで勾配を求め、ランダムなデータ1つのみで勾配を求め、パラメータを更新していく作業をデータ数だけ行う方法
・確率的勾配降下法を用いた学習を、バッチ学習に対してオンライン学習という
・全データ数が1000だった時、バッチ学習では1000個のデータの誤差計算してから更新計算を1回行う
・オンライン学習では1個のデータを用いた誤差計算を1000回行う。オンライン学習では全データを1回使うまでのイテレーション数が多くなる
・イテレーションと区別して、全データを用いる回数をエポックと呼ぶ。例のオンライン学習では、1エポック=1000イテレーションになる
・バッチ学習ではエポック数とイテレーション数は一致する
★ミニバッチ勾配降下法:全データをいくつかのデータセットに分割し、そのデータセットごとに更新計算を行う
・バッチサイズ:各データセット内のデータ数のこと
・例えば、全データが1000個の時、各データセット内のデータ数が50であれば、バッチサイズ=50となる。この時全データは20のデータセットに分割され、イテレーション数は20となり、1エポック=20イテレーションということになる
・バッチサイズやエポックはハイパーパラメータになる
勾配降下法の問題と改善
・勾配降下法では、「見せかけの最適解」であるかどうかを見抜くことができない
・局所最適解:見せかけの最適解のこと
・大域最適解:本当の最適解のこと
・局所最適解を防ぐ方法として、学習率の値を大きく設定する方法がある。山を越えるよウにすればよい。
・探索し続けてしまうという問題が発生するため、適切なタイミングで学習率の値を小さくしていくことが必要
・3次元以上ではほかの問題も発生
・鞍点:ある時限から見れば極小であるものの、別の次元から見ると極大となってしまっているもののこと
・一度鞍点に陥ると、そこから抜け出すことは困難になる(このような停留状態をプラトーという)
・局所最適解を避けるために、どの方向に沿って勾配を進んでいる時に学習率を大きく(あるいは小さく)すべきかを考える必要がある
・モーメンタム:1990年代に提唱された、最適化の進行方向に学習を加速させることでプラトーから抜け出す手法
・ディープラーニングのブームを受けて、モーメンタムよりさらに効率的な手法が立て続けに考案された。
・古いものから、Adagrad,Adadelta,RMSprop,Adam,AdaBound,AMSBoundなどがある
・過度に最適解の探索をすると、過学習につながる。そこで用いられる手法が早期終了
・ジェフリー・ヒントンはearly stoppingのことを"Beautifrul FREE LUNCH"と表現している。これは、ノーフリーランチ定理という、**「あらゆる問題で精度のいい汎化最適化戦略は理論上不可能」**であることを意識して発せられた。
・二重降下現象:一度テストデータに対する誤差が増えた後、再度誤差が減っていく
・ハイパーパラメータの最適化をしたい場合、様々な値で実験して予測性能を比較するしかない
・ハイパーパラメータチューニング:ハイパーパラメータの値を調整していくこと
・ハイパーパラメータの探索手法として、グリッドサーチ、ランダムサーチがある
★グリッドサーチ:候補となるハイパーパラメータすべての組み合わせでモデルの構築を行う
・ある程度ハイパーパラメータの値が絞られている時に用いられることが多い
・組み合わせの数だけ学習時間が増えることに注意が必要
★ランダムサーチ:確率分布に基づいた乱数を発生させ、その乱数をハイパーパラメータとしてモデルの構築を行う
・制度は保証されないが、現実的な時間内で行うことが可能
・他にはベイズ最適化や遺伝的アルゴリズムといった手法が存在する
・探索に時間がかかるのが難点
誤差逆伝播法
・ネットワークの出力と正解ラベルとの誤差から各ニューロンの重みを修正する
・勾配降下法を用いてニューラルネットワークの学習をする際に、微分計算を誤差逆伝播法を用いて効率よく行う
・誤差逆伝播法のメリットは計算の効率化だけでなく、「どのニューロンが予測結果に寄与している/していないを判別できる」という点もある
・「モデルのどの部分がその予測結果をもたらしているのかわからない」という信用割当問題を解決できているといえる
・誤差逆伝播法によりモデルを多層化することも容易になった。
・それにより生じる問題が勾配消失問題や勾配爆発問題である。勾配値が小さくなりすぎてしまったり大きくなりすぎてしまったりする。
活性化関数
シグモイド関数と勾配消失問題
・誤差逆伝播法によるパラメータ更新の際、「活性化関数を微分する」という操作がある
・ニューラルネットワークの活性化関数としてシグモイド関数が使われていたが、これを微分すると最大値が0.25になり、隠れ層をさかのぼるごとに活性化関数の微分がかけ合わさって伝播していく誤差はどんどん小さくなっていく
・その結果、多くの隠れ層があると、入力層付近の隠れ層に到達するまでには、もはやフィードバックするすべき誤差がほぼ0になってしまい、勾配消失問題が発生している
tanh関数
・出力層においてはシグモイド関数でなければ出力を確率で表すことができないため変えることはできない
・出力を得る前の隠れ層に関しては、任意の実数を非線形に変換することができる関数でさえあれば、どんな関数であろうと活性化関数として用いるのに特に問題はない
・隠れ層の活性化関数を工夫するというアイデアは、第3次AIブームの前から実践されており、良い結果が得られたのはtanh(ハイパボリックタンジェント)関数である
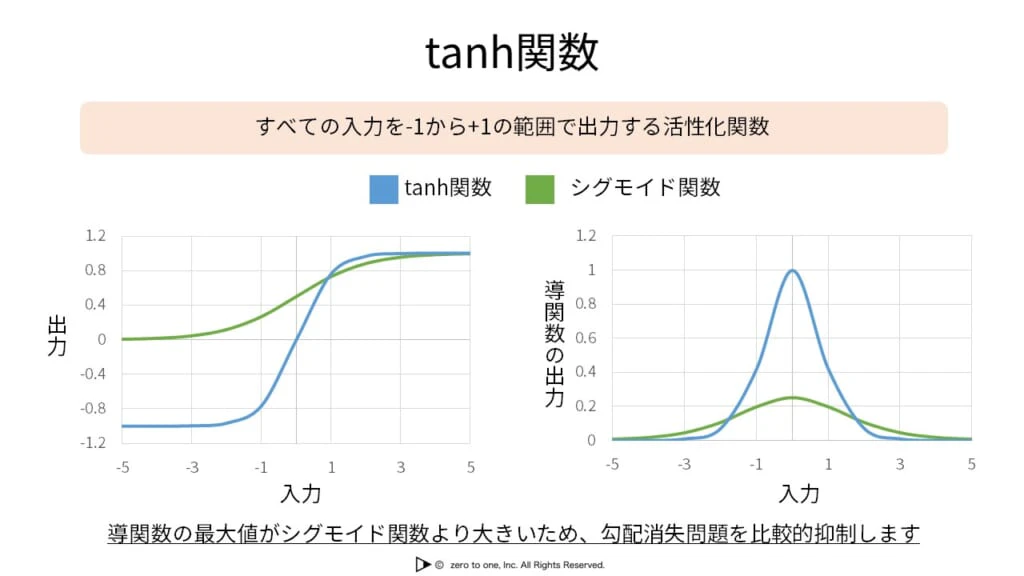
・-1から1の範囲をとる
・tanh関数の微分の最大値は1であるため、勾配が消失しにくい
ReLU関数
・tanh関数よりも勾配消失問題に対処できるのがReLU関数である
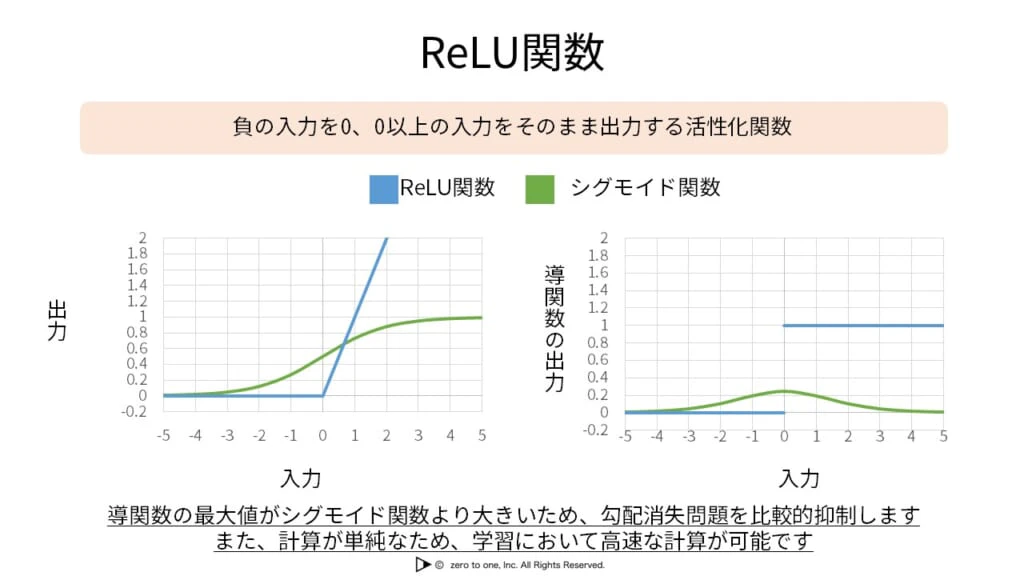
・xが0より大きい時、常に微分値は1が得られるため、誤差逆伝播の際に勾配が消失しにくい
・一方で、xが0より小さい時は微分値も0になるため、学習がうまくいかない場合がある
・派生形として、Leaky ReLU関数があげられる
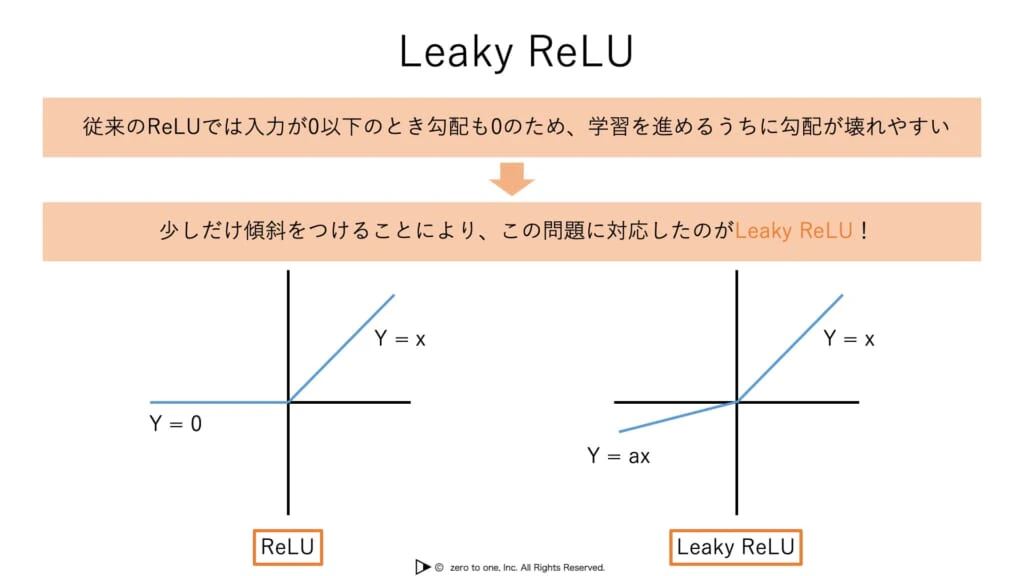
・x<0において、わずかな傾きを持っている
・必ず良い結果を返す活性化関数とは限らない
・他には、Parametric ReLU(x<0部分の直線の傾きを学習によって最適化しようとする)やRandomized ReLU(複数の傾きをランダムに試す)がある
ディープラーニングの要素技術
ネットワークの構成要素
畳み込み層
・フィルタ(またはカーネル) を用いて、特徴を特徴マップとして抽出する畳み込み処理(convolution) を行う
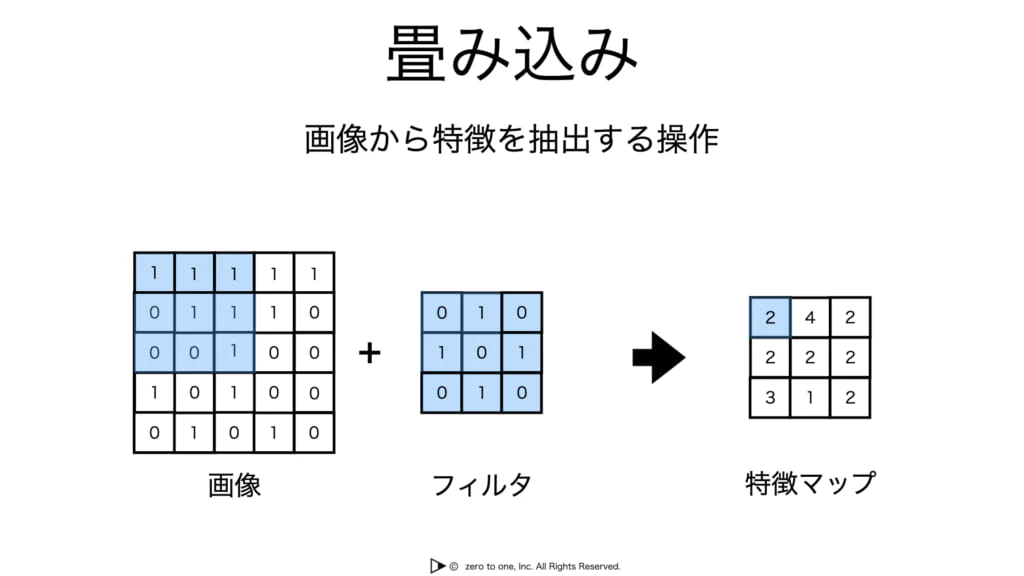
・フィルタの値の学習にも、誤差逆伝播法が用いられる
・畳み込み処理を適用すると、特徴マップのサイズは「フィルタサイズ-1」分小さくなる
・入力と同じサイズの特徴マップにしたい場合、パディング処理を適用する
・入力の上下左右に要素をつかし、0の値で埋める。この時、「(フィルタサイズ-1)/2」分を上下左右に追加する
・畳み込み処理では、フィルタを重ねる位置をずらしていく
・そのずらし幅をストライドと呼ぶ
★Atorus Convolution(Dilated Convolution) **
・特徴マップの感覚をあけて広い範囲に対して畳み込み処理を行う
・こうすることにより、計算量を増やさずに広い範囲の情報を集約することができる
Depthwise Separable Convolution
・空間方向とチャネル方向に対して独立に畳み込み処理を行う
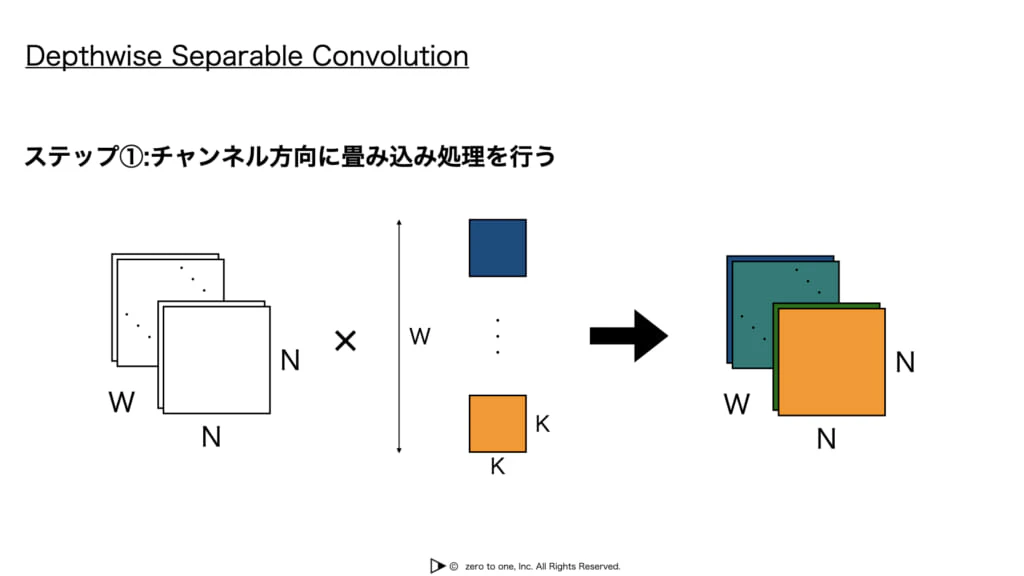
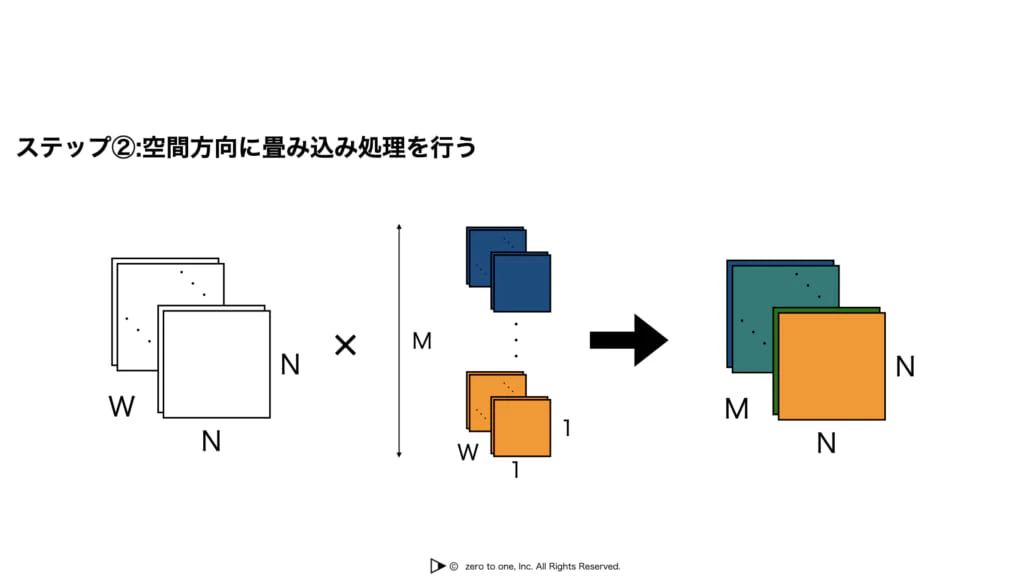
・空間方向はDepthwise Convolution**、チャネル方向はSeparable Convolutionと呼ぶ
プーリング層
・プーリング処理とは、特徴マップをルールに従って小さくする処理
・これをダウンサンプリングあるいはサブサンプリングと呼ぶ
・ある小領域ごとの最大値を抽出する**最大値プーリング(max pooling) や平均値プーリング(average pooling) **がある
・特徴を集約し、特徴次元を削減する効果がある
・また、画像のずれに対する頑健性を持ち、不偏性を獲得する
全結合層
・層に入力された特徴に重みをかけて、総和した値をユニットの値とする
・CNN(LeNet)では、畳み込み層/プーリング層を繰り返した後、全結合層を積層する
・全結合層を用いず、特徴マップの平均値を1つのニューロンの値にするGlobal Average Poolingと呼ばれる処理が用いられることもある
・特徴マップの値をすべて使用して全結合することがなくなるため、パラメータ数を削減できる
スキップ結合
・「超」深層になると学習時に誤差を入力層近くまで逆伝播しにくくなることにより、識別精度が落ちるという問題がある
・層を飛び越えた結合であるスキップ結合がResNetで導入された。
・これにより、層が深くなっても層を飛び越える部分は伝播しやすくなったり、様々な形のネットワークのアンサンブル学習になっている。
正規化層
・特徴の分布のばらつきを抑制するために、正規化処理を行う
★バッチ正規化:各層で活性化関数をかける前の特徴を正規化する
・特徴の正規化する範囲を変えることで、レイヤー正規化(データごとに全チャネルをまとめて正規化)、インスタンス正規化(データごとに各チャネルを正規化)、グループ正規化(データごとに複数のチャネルをまとめて正規化)などがある
・正規化は強力な手法であり、学習がうまくいきやすくなるだけでなく、科学しにくくなるという利点もある
リカレントニューラルネットワーク
回帰結合層
・時系列データを扱うために、ネットワークの中間状態を次の入力の処理に利用する回帰結合層が考案された
・この回帰結合層を含むネットワークをリカレントニューラルネットワーク(RNN) と呼ぶ
・代表例として、過去に入力された単語列から次に来る単語を予測する言語モデルがある。
・Pretrained Modelsの基礎になっている
RNNの基本形
・RNNはエルマンネットワークと呼ばれる構造で、回帰結合層の情報を伝播して、次の時刻の入力とともに利用する。自然言語処理などで利用される。
・これに対して出力層の情報を伝播して、次の時刻の入力とともに利用するモデルをジョルダンネットワークと呼ぶ。ロボットの運動制御などで利用される。
LSTM
・RNNは勾配消失問題を抱えている。また、「今の時点では関係ないけれど、将来の時点では関係ある」という入力が与えられた際、重みは大きくすべきであると同時に小さくすべきであるという矛盾が起こるという入力重み衝突という問題がある
・同様に、出力に関しても出力重み衝突が発生し、学習を妨げることとなった
・こうしたいくつかの問題を解決するために考えられたのがLSTMと呼ばれる手法
・LSTMはLSTMブロックと呼ばれる機構を導入し、時系列情報をうまくネットワーク内に長期保持することを可能としている
・大まかは、誤差を内部にとどまらせるためのセルと、必要な情報を必要なタイミングで保持、消却させるためのゲートから成っている
・セルはCECとも呼ばれ、誤差を内部にとどめ、勾配消失を防ぐためのものになる
・一方、ゲートは入力ゲート、出力ゲート、忘却ゲートの3つからなり、前の2つはそれぞれ入力重み衝突、出力重み衝突のためのゲート機構になる
・忘却ゲートはリセットの役割を果たす
・LSTMは計算量が多いため、簡略化したGRUという手法が用いられるときもある
・GRUではリセットゲート、更新ゲートが役割を果たす
Bidirectional RNN
・時間情報の途中がかけていてそれが何かを予測したい場合、過去と未来両方の情報を使って予測した方が効果的である
・Bidirectional RNN:RNNを2つ組み合わせることで、未来から過去方向も含めて学習できるようにしたモデル
エンコーダ-デコーダ
・入力が時系列なら出力も時系列で予測したい場合に対応したモデルを、sequence-to-sequence(seq2seq) という
・土台となるアプローチは2つのRNNを組み合わせるRNNエンコーダ-デコーダという手法
・モデルは大きくエンコーダとデコーダの2つのRNNに分かれており、エンコーダが入力データを処理して符号化(エンコード)し、符号化された入力情報を使ってデコーダが複合化(デコーダ)する
・画像を入力としてその画像の説明文を生成するImage Captioningと呼ばれるタスクでは、エンコーダは画像を処理するためCNNが用いられ、デコーダでは自然言語文を出力するためRNNが用いられる
RNNの学習
・RNNでは、これまでに与えられた情報をどの程度現在の情報に反映するかを学習することになる。そのため、誤差を過去にさかのぼって逆伝播させる。
・これには、時間軸に沿って誤差を反映していく、**Back Propbagation Through Time(BPTT) **を用いる
・ある時刻の情報をRNNに入力すると、その時刻に対する出力が得られる。入力数と出力数は一致する
・言語モデルにおいて、いくつかの単語を順に入力したとき、次に来る単語を予測し、これを正解の単語と比較して誤差を計算する。次に入力する単語は、1つ前の単語を入力したときの正解データそのものである。
・このように、正解データを次の入力データとして利用することを**教師強制(Teacher Forcing) **と呼ぶ
Attention
・RNNの応用によって、様々な時系列タスクで高い精度を達成するようになったが、どの時刻の状態がどれだけ次の状態に影響するかまでは直接求めていない
・「時間の重み」をネットワークに組み込んだAttentionも時系列タスクで精度の向上に貢献した
・例えばImage Captioningにおいて、入力された画像のどこに注目して説明文を生成しているかを可視化することができる
トランスフォーマー
トランスフォーマーの基本形
・トランスフォーマーはニューラル機械翻訳の新たなモデルとして提案された
・トランスフォーマー登場前、入力文と出力分の橋渡しに使われたAttention機構は特にSource Target AttentionもしくはEncoder-Decoder Attentionと呼ばれている
・トランスフォーマーはエンコーダとデコーダからRNNを排除し、代わりにSelf-Attentionと呼ばれるネットワーク構造を採用している点が最大の特徴
・これにより、遠い位置にある単語同士の関係もうまくとらえることができるようになり、機械翻訳の精度もさらに向上した
RNNの問題点
・入力データを時間軸に沿って必ず1つずつ順番に読み込む逐次処理が必要になるため、並列計算ができず、処理速度が遅くなる
・時系列の最初の時刻に入力した情報の影響が時間の経過とともに次第に薄れてしまう
・これらの問題を解決した新たなニューラルネットワーク構造として、2017年にトランスフォーマーが提案された
Self-Attention(自己注意機構)
・入力文内の単語間又は出力文内の単語間の関連度を計算したもの
・各単語がその文内でどのような役割を持つかをうまくとらえることができる
・すべての計算が並列に行え、高速に処理できる
・Self-Attentionは語順の情報が失われている
・トランスフォーマーではこれを回避するために、位置エンコーディングと呼ばれる単語の出現位置に固有の情報を入力に付加する
・これにより、間接的に単語の位置情報や単語間の位置関係を考慮することができる
・トランスフォーマーではエンコーダもデコーダもSelf-Attentionを用いているが、仕組み上の違いが2点ある
・1点目は、デコーダはSorce-Target Attentionにより入力文の情報も利用する点
・2点目は、未来の情報は使えないという点
クエリ、キー、バリューによるAttentionの計算
・トランスフォーマーで使われているSouurce-Target AttentionとSelf-Attentionはどちらもクエリ、キー、バリューという3つの値を用いて計算される
・データベースにキーベクトルとバリューベクトルのペアがいくつか格納されており、与えられたクエリベクトルに対して各キーベクトルを用いて各ペアの重要度を計算し、バリューベクトルの値を重要℃で重みづけして足しあえあせたものを出力するというイメージ
・Sorce-Target Attentionではクエリとしてデコーダの中間状態を利用し、キーとバリューはエンコーダの最終出力を利用する
・これにより、デコーダの状態に応じて、次の出力を決める際に必要となる入力の情報が適切に参照できるようになる
・Self-Attentionでは、これら3つの値はすべて自分自身をコピーして利用する
・これにより、例えば各単語のベクトル表現を、同じ文内の他の単語との関係性を考慮して計算することができる
Multi-Head Attention
・実際には視点の異なるいくつかのパターンでクエリとキーとの関係を見る方がいい
・これを実現するため、Attentionの計算を並列に行うものをMulti-Head Attentionと呼び、各Attentionの計算をHeadと呼ぶ
オートエンコーダ
基本的なオートエンコーダ
・オートエンコーダとは、可視層と隠れ層の2層からなるネットワークであり、可視層(入力層)→隠れ層→可視層(出力層)の順に伝播し、出力される
・可視層は入力層と出力層がセットになったもの
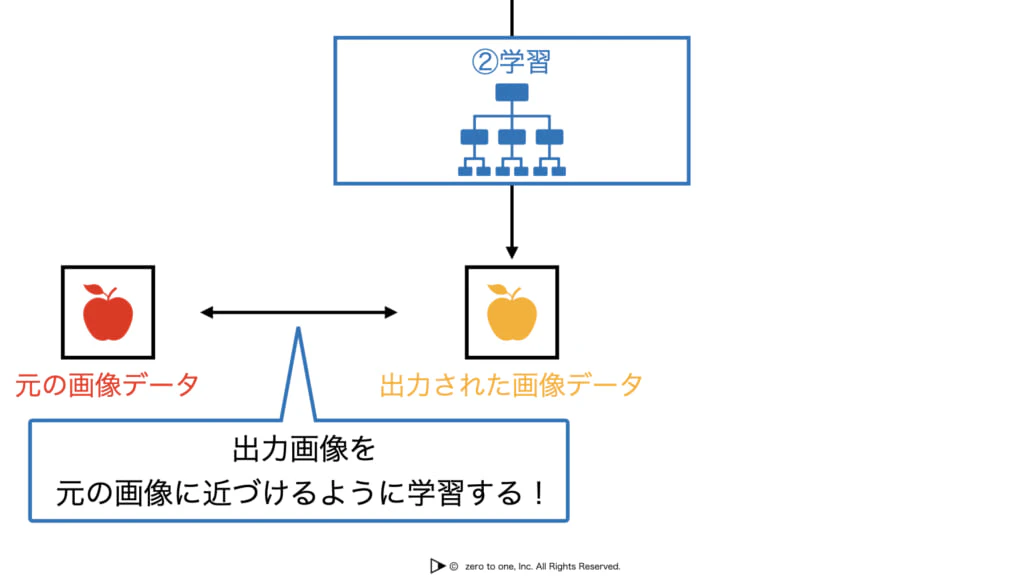
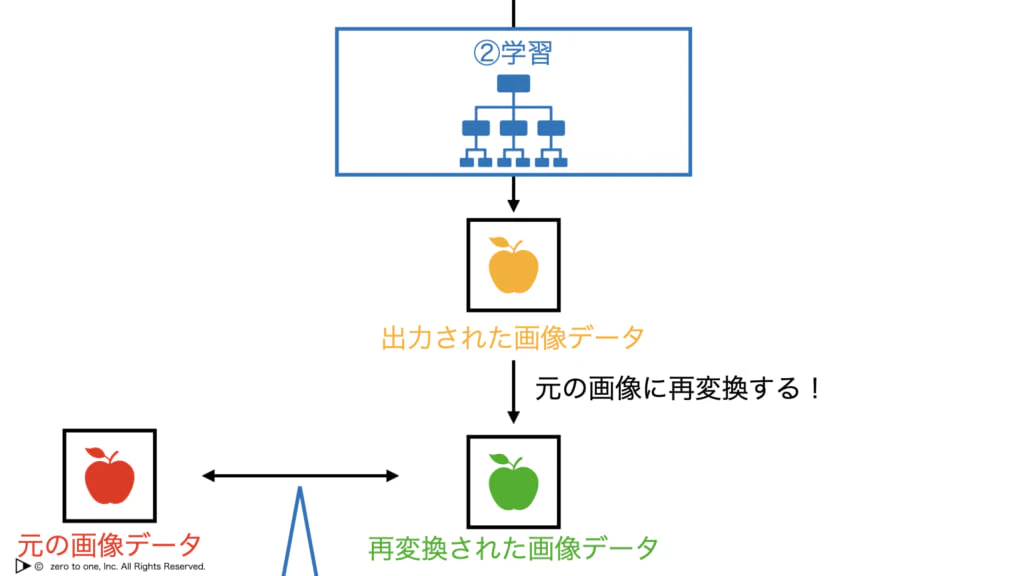
・オートエンコーダは「入力と出力が同じになるようなネットワーク」であり、つまり手書きの"3"を入力したら数字画像の"3"を出力するようにネットワークが学習するということ
・この学習により、隠れ層には「入力の情報が圧縮されたもの」が反映されることになる
・入力層の次元よりも、隠れ層の次元を小さくしておくことで、情報が圧縮される
・入力層→隠れ層における処理をエンコード、隠れ層→出力層における処理をデコードという
積層オートエンコーダ
・オートエンコーダを積み重ねることでできたディープオートエンコーダ
・オートエンコーダAの隠れ層が、オートエンコーダBの可視層になる
・層が積み重なっても、順番に学習していくことにより、それぞれで隠れ層の重みが調整されるため、全体で見ても重みが調整されたネットワークが構築される
・このオートエンコーダを順番に学習していく手順のことを、事前学習という
変分オートエンコーダ
・入力データを圧縮表現するのではなく、統計分布に変換する。すなわち、平均と分散で表現するように学習する
・入力データは統計分布のある1つの点となる
・エンコーダが入力データを統計分布のある1点となる潜在変数に変換する
・デコーダは統計分布からランダムにサンプリングした1点を復元することで、新しいデータを生成する
・VQ-VAE:潜在変数を連続値ではなく離散値にした応用手法
・infoVAE:潜在変数とデータの相関を高めることで生成の精度を上げた応用手法
・β-VAE:VAEの目的関数において正則化を工夫することにより画像の特徴を洗剤空間上でうまく分離し、画像生成を行いやすくした応用手法
ディープラーニングの応用例
画像認識
画像データの入力
・RGB画像は縦と横だけでなく奥行きを持つ3次元である
・この画像データに適した構造として考えられたのが畳み込みニューラルネットワーク(CNN)
・通常のニューラルネットワークでは縦一列の情報に変換するが、画像は、縦横の位置関係が重要な意味を持つ
・CNNでは2次元のまま入力として扱うため、画像データに適している
ネオコグニトロンとLeNet
・CNNは、視覚野の神経細胞の2つの動きを模してみようという発想から生まれている。
・1つ目は、単純型細胞(S細胞):画像の濃淡パターンを検出する
・2つ目は、複雑型細胞(C細胞):特徴の位置が変動しても同一の特徴であるとみなす
・この2つの細胞の働きを最初に組み込んだモデルはネオコグニトロンと呼ばれ、福島邦彦らによって考案された
・微分(勾配計算)を用いないadd-if silentと呼ばれる学習方法を用いる
・その後、1998年に、ヤン・ルカンによって、LeNetと呼ばれる有名なCNNのモデルが考えられた。
・畳み込み層と**プーリング層(サブサンプリング層)**の2種類の層を複数組み合わせた構造をしている
・誤差逆伝播法を用いて学習する
データ拡張
・データの水増しに相当する
・データの拡張手法について、
Cutout:ランダムな場所を値0の正方形領域で置き換える
Random Erasing:画像中のランダムな場所をランダムなノイズの長方形領域で置き換える
Mixup:2枚の画像を混ぜ合わせた1枚の画像を使う手法
CutMix:1枚の画像のランダム正方形領域を、もう1枚の画像を同じサイズで切り抜いたもので置き換える手法
・これにより、過学習が抑制される
物体認識タスク
・識別対象としている物体クラスすべてに対する確信度を出力し、その確信度が最も高い物体クラスを識別結果として出力する
・画像認識の精度を競うコンペティション(ILSVRC)において、2012年に**AlexNet(アレックスネット)**が従来手法を圧倒し、ディープラーニングに基づくモデルとして初めて優勝した
・AlexNet以降、畳み込み層とプーリング層の繰り返しをさらに増やした、より深いネットワークのモデルが続々と登場した
・VGGは、16層まで積層している
・各畳み込み層のフィルタサイズを3×3に統一し、プーリングを行った次の畳み込み層からフィルタ数を2倍に増やすというシンプルな設計。
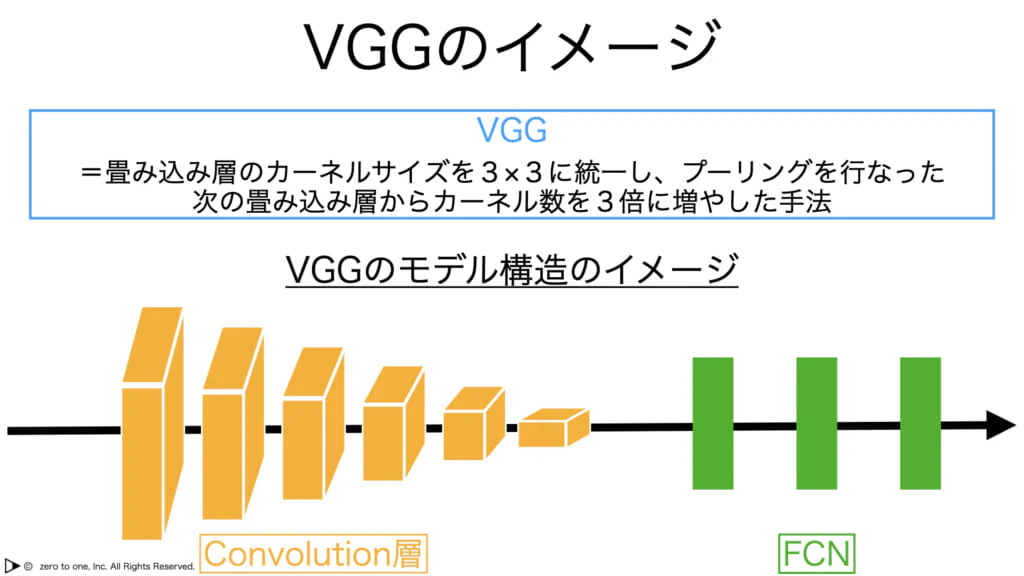
・GoogLeNetは、2014年にILSVRCで優勝した
・層を深くするだけでなく、同時に異なるフィルタサイズの畳み込み処理を行うInceptionモジュールを導入している
・途中に認識結果を出力する層を追加し、学習の際に誤差を逆伝播する仕組みを取り入れている
・「超」深層になると識別精度が落ちるという問題に直面した。
・この問題を解決するスキップ結合を導入したResNetが、2015年に優勝した
・152層の構造で、(1000クラスの識別対象内で)人間の識別精度を超えることができている
・以降、ResNetが主流のモデルとなり、フィルタ数を増やしたWide ResNetやスキップ結合を工夫したDenseNetなど派生モデルが登場している
・2017年は、Attention機構を導入したSqueeze-and-Excitation Networks(SENet)が優勝した
・ネットワークの層数を深くすると、パラメータ数が増加する。
・モバイル端末などの使用できるメモリ量が限られている環境でも利用できるよう、MobileNetは、畳み込み層にDepthwise Separable Convolutionを用いてパラメータ数を削減している
・学習により準最適なネットワーク構造の探索を行うことが注目されている
・Natural Architecture Search(NAS)では、RNNと深層強化学習を用いてネットワーク構造を探索する
・RNNが出力した各層のフィルタサイズやフィルタ数などをもとにネットワークを作成し、学習及び評価する
・そして、認識精度が高くなるように深層強化学習によりネットワークを生成する部分を学習する
・この時、生成する単位をResNetのResidual Blockのような塊にする工夫を導入したNASNetや、認識精度だけでなくモバイル端末での計算量も考慮する工夫を導入したMnasNetなどもある
・非常に時間がかかる一方、EfficientNetという優れたネットワーク構造も誕生している
・単に高精度なだけでなく、転移学習に有用なモデルとして、様々なコンペティションに活用されている
物体検出タスク
・入力画像に移る物体クラスの識別とその物体の位置を特定するタスク
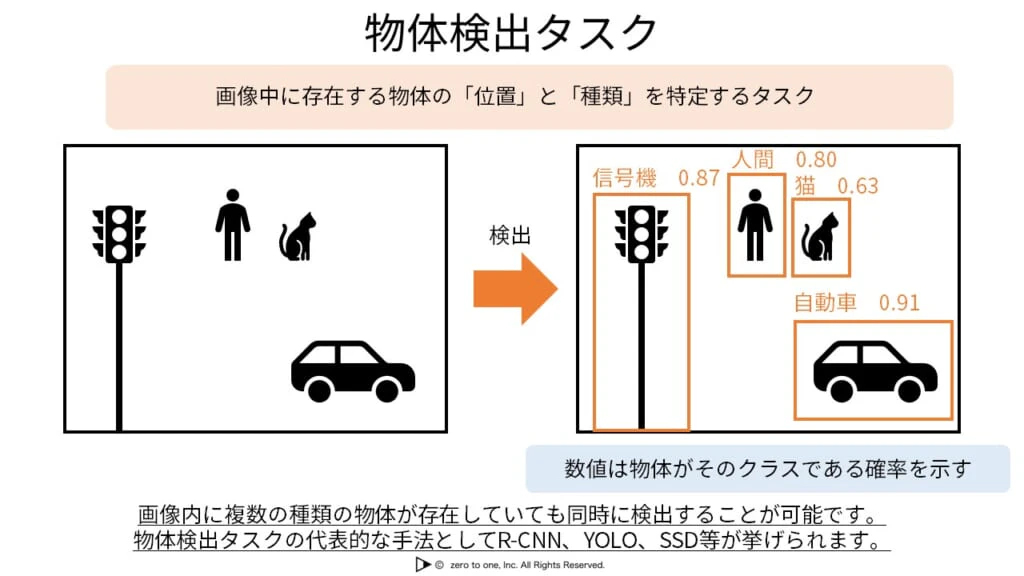
★2段階モデル
・大まかな物体の位置を特定した後、その物体クラスを識別する
・R-CNNとその後継モデルやFPNがある
・R-CNNでは候補を一定のサイズにして、CNNに入力し、サポートベクターマシンによりクラス識別を行う
・画像の分割数を絞ることで演算回数を減らし、高速化することができた
・R-CNNの構造を簡略化して、高速化されたモデルがFast R-CNN
・R-CNNに対してCNNを使う回数が1回で済むため、高速化に成功した
・さらに高速化したモデルがFaster R-CNN
★1段階モデル
・位置の特定とクラスの識別を同時に行う
・処理を単純にできるため、高速な処理を実現できることが期待されている
・YOLOとその後継モデルやSSDがあ
・デフォルトボックスという短形領域のテンプレートパターンを複数用意しておくことで、縦長や横長の物体を検出しやすくしている
セグメンテーションタスク
・画像の画素ごとに識別を行うタスク
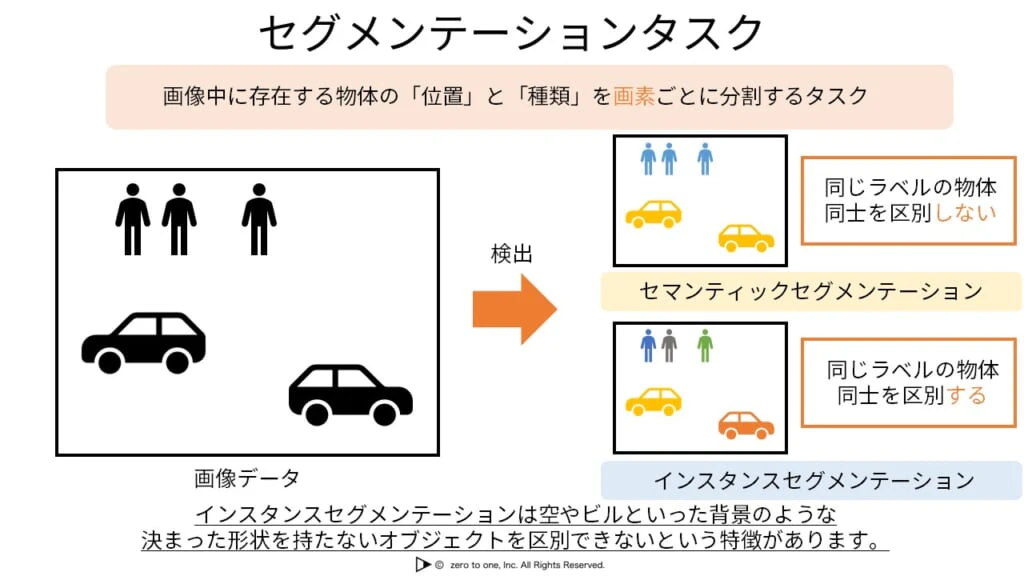
・セマンティックセグメンテーション:画像全体を対象とする
・集団の歩行者などを一人ひとり分離することはできない
・インスタンスセグメンテーション:物体検出した領域を対象とする
・一人ひとり分離できる
・背景などの数えられないものはそもそもクラス分けを行わない
・パノプティックセグメンテーション:個々の物体を分離しつつ、道路や建物などはひとまとめにする
・CNNを用いると1つの画素に広い範囲の情報を集約しているため、1画素ごとにクラス識別ができるようになる
・CNNをセマンティックセグメンテーションタスクに利用した方法をFCN(Fully Convolutional Networkという
・畳み込み層のみで構成されている
・FCNの最後の特徴マップは入力画像に対して小さいため、出力を入力画像サイズまで拡大すると解像度が荒いセグメンテーション結果になる
・畳み込み層とプーリング層を繰り返し積層することで小さくなった特徴マップを徐々に拡大する構造を採用した方法にSegNetがある
・エンコーダで特徴マップを小さくし、デコーダで大きくしていく
・オートエンコーダ形式で、デコーダ時にエンコーダ時のpooling位置を参照してup samplingする
・デコーダ側で特徴マップを拡大して畳み込み処理する際、エンコーダ側の特徴マップを同じサイズになるよう切り出して利用するU-Netというモデルもある
・X線画像の医療画像診断に用いられている
・エンコーダとデコーダの間にPyramid Pooling Moduleという複数の解像度で特徴を捉えるモジュールを追加したPSPNetがある
・エンコーダの出力に異なるサイズのpoolingをし、それらのデコーダに入力する
・大域的なコンテクストと局所的な細かい情報どちらも得ることを可能にしたディープラーニングセグメンテーションタスク
・セマンティックセグメンテーションタスクでは広い範囲の情報を集約することが重要であり、畳み込み層ではDilated convolutionまたはAtrous convolutionが利用されている
・Atorous convolutionを導入したモデルがDeepLab。Atorous convolutionは畳み込みのデータ間隔を広げたものを使うこの間隔は畳み込みではdilationとも呼ばれる
・エンコーダの出力に異なるdilationの畳み込みを行い、それらをデコーダに入力する
・さらにSegNetやU-Netのようなエンコーダとデコーダの構造、PSPNetのような複数解像度の特徴を捉える機構(ASPP)を採用したモデルは**DeepLabV3+**とよばれている
姿勢推定タスク
・人の頭や足、手などの間接位置を推定するタスク
・関節の位置は人の姿勢により大きく異なるため、信頼度によるアプローチが有効
・Convolutional Pose Machines:CNNを多段に組み合わせて徐々に各骨格の信頼度マップを高精度化する
・OpenPose:複数の人の骨格を同時に推定できるようにした手法
・OpenPoseはParts Affinity Fieldsと呼ばれる骨格間の位置関係を考慮した処理を導入している。これにより複数人いても同一人物の関節をつなぎ合わせることが可能
マルチタスク学習
・複数のタスクを1つのモデルで対応することをマルチタスクとい
・Faster R-CNNやYOLOなどの物体検出タスクは物体クラスの識別と物体領域の位置検出を同時に行っているためマルチタスクともいえる
・Mask R-CNNは、Faster R-CNNによる物体検出だけでなく、セグメンテーションも同時に行うマルチタスクのモデル
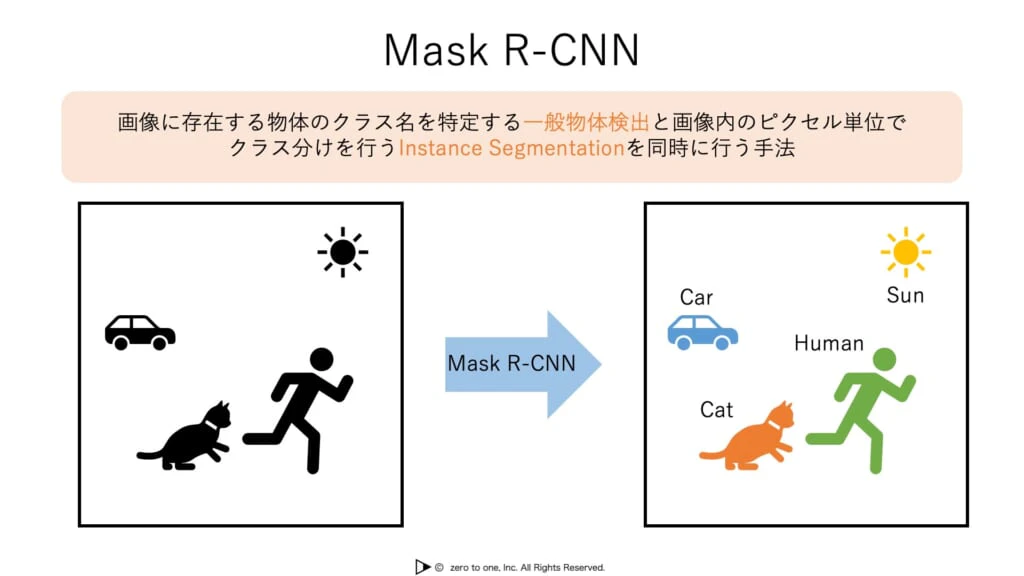
音声処理
音声データの扱い
・音声は本来アナログなデータだが、コンピュータで扱うために離散的なデジタルデータ変換する必要がある
・この変換処理をA-D変換という。音声はパルス符号変調(PCM)という方法でデジタルデータに変換することが一般的
・高速フーリエ変換(FFT):音声信号を周波数スペクトルに変換する際に用いられる
・メル尺度人間が感じる音の高低に合わせた尺度
・音の中で「音色」の違いは周波数スペクトルにおけるスペクトル包絡(スペクトル上の緩やかな変動)の違いと解釈する
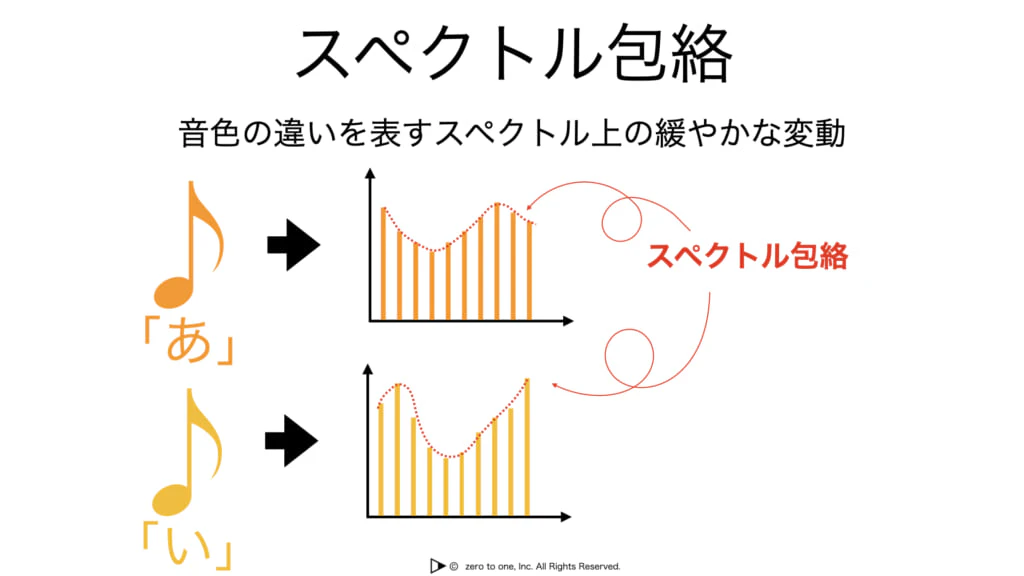
・スペクトル包絡を求めるためには、メル周波数ケプストラム係数(MFCC)を用いる
・スペクトル包絡を求めるといくつかの周波数でピークを迎えることがわかる
・このピークをフォルマントと呼び、フォルマントのある周波数をフォルマント周波数と呼ぶ
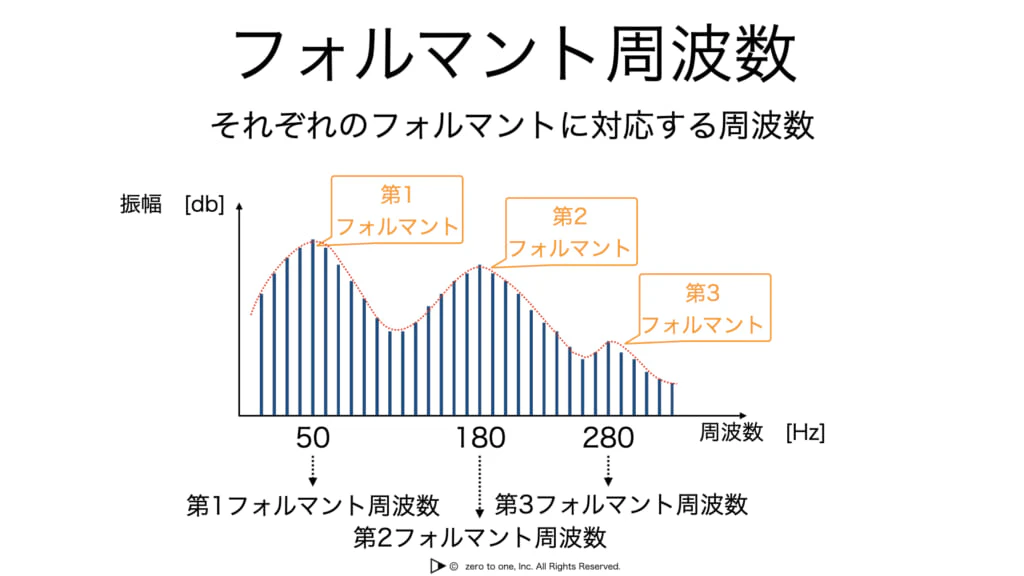
・入力された音韻(言語によらず人間が発生する区別可能な音)が同じであればフォルマント周波数は近い値となる
音声認識
・与えられた音声データをテキストに変換して出力する技術で、Speech-to-Text(STT)とも呼ばれる
・音響モデルとして長い間標準的に用いられているのが**隠れマルコフモデル(HMM)**である。音素ごとに学習することによってより多くの語彙に対応可能となっている
・RNNの場合、音声データを時系列で逐次入力していき、入力に対する音声の音素を出力するしかし、入力した音声データの時系列の数と、認識すべき政界の音素の数は必ずしも一致しない
・そこで、Connectionist Temporal Classification(CTC)を用いる。出力候補として空文字を追加し、さらに連続して同じ音素を出力した場合には縮約する処理を行う
・音声認識技術を応用するためには、多くの解決すべき課題がある
・例えば機械との対話において、機械がより適切な応答を返すために、人間の音声の感情分析を行う必要がある
・自動議事録作成では誰のお発話化を推定する話者識別が必要になる
音声合成
・与えられたテキストを音声に変換して出力する技術で、Text-to-Speech(TTS)とも呼ばれる
・波形接続方式:ある話者の様々な音素の波形をあらかじめデータベース化しておき、これらを組み合わせて音声合成を行う手法
・パラメトリック方式:声の高さや音色などに関するパラメータをHMMなどによって推定し、これを基に音声を合成する手法
・パラメトリック方式の方が合成の質が低いとされていた
・WaveNet:2016年にDeepMindから発表されたディープラーニングを用いたパラメトリック方式の音声合成モデル
・音声合成の質を劇的に向上させた
・CNNなどで使われる畳み込み処理を行っている
自然言語処理
テキストデータの扱い方
・単語を単位とすると、文字列は複数個の単語を並べたものとして表現できる
・これを単語n-gramと呼ぶ

・n=1,2,3の時、順にそれぞれユニグラム、バイグラム、トライグラムと呼ぶ
・文や文章をそこに出現する単語の集合として表現することを考える
・これをBag-of-Words(BoWと呼ぶ。これにより単語を単位として分野文書などを表現できる。
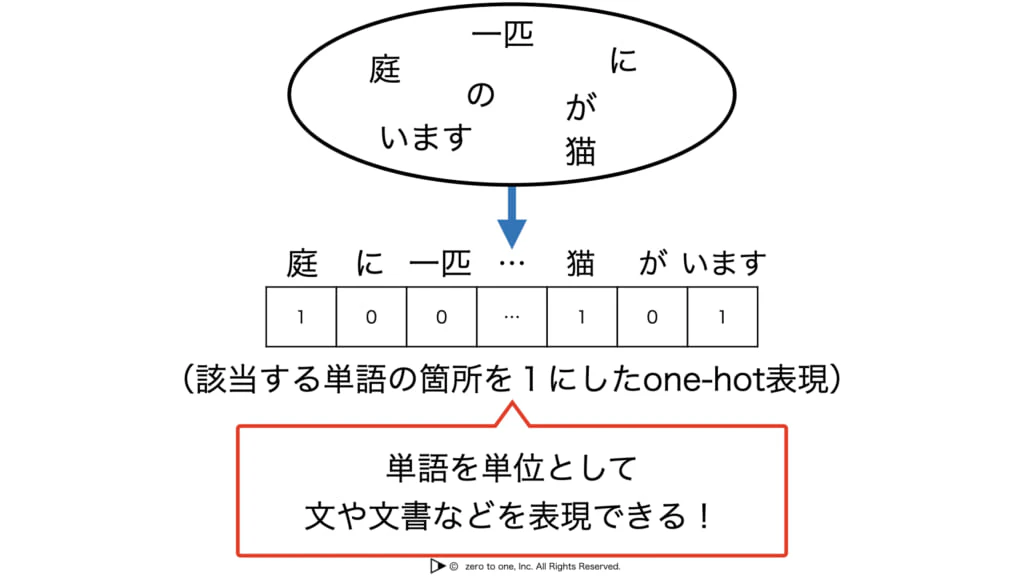
・文書の数×出現しうる単語の数のテーブルを作って各文書をベクトルで表現する
・BoWでは単語がばらばらに保存されており、出現順序の情報は失われてしまう。
・そこでn-gramとBoWを組み合わせたBag-of-n-gramsを利用することもある
・ニューラルネットワークでは数値列(ベクトル)しか扱えないので、単語もベクトルとして入力する必要がある
・典型的な方法は、各単語に異なる整数値を順に割り当てしID化し、このIDに相当するベクトルの次元の値だけが1で他がすべて0となっているワンホットベクトルに変換するというもの
・TF-IDF:単語の重要度のようなものを計算する手法の1つ
・TFは1つの文章内での単語の出現割合であり、IDFはある単語が出現する文章の割合の逆数をとり、対数をとったもの
・ワンホットベクトルは情報が疎であり、次元数が単語の種類数と等しいため、非常に高次元であるという特徴がある。
・このような単語の表現を局所表現と呼ぶ。局所表現では単語同士の意味の近さを考慮することがない
・そのため、連続的で、情報が密であり、次元数の低いベクトルに変換することを考える
・このような単語の表現を分散表現や単語埋め込みと呼ぶ
・word2vec:単語の分散表現を得る代表的な手法
・word2vecは「単語の意味は、その周辺の単語によって決まる」という分布仮説という言語学の主張をニューラルネットワークとして実現したもの
・word2vecにはスキップグラムとCBOWという2つの手法がある
・スキップグラムとは、ある単語を与えて周辺の単語を予測するモデルであり、CBOWはその逆で周辺の単語を与えてある単語を予測するモデルである
・トマス・ミコロフらによって新たに開発された、word2vecの延長線上にあるfastTextというライブラリがある
・変更点は、単語埋め込みを学習する際に単語を構成する部分文字列の情報も含めること
・これにより訓練データには存在しない単語であっても単語埋め込みを計算したり、活用する単語の語幹と語尾を分けて考慮したりすることを可能にした
・また、fastTextは学習に要する時間が短い
・word2vecやfastTextで得られる分散表現は各単語1つだけであるが、これだと多義性を持つ単語やほかの特定の単語と結びついて特別な意味を持つ単語などを正しく扱うことができない
・ELMo:文脈を考慮した分散表現を得る手法
事前学習モデル
・事前学習+転移学習という枠組みで様々な応用タスクを高精度に解くことができるモデルが2018年に提案された
・word2vecやELMoも事前に大規模なデータを使って学習をしている点は同じだが、タスクに応じた別のニューラルネットワークを用意して応用タスクを解く
・GPTやBERTは事前学習と同じモデルを使って応用タスクを解くことができるという違いがある
★GPT(Generative Pre-Training)
・事前学習として大規模なコーパスを用いた言語モデルの学習を行う
・トランスフォーマーのデコーダと似た構造を持ったネットワークを用いている
・以下のような言語理解タスクを解くことができる
評判分析:与えられた分の最後の状態を使って、(positive/negative/neural)を判定する
自然言語推論(含意関係認識):与えられた2つの文書の内容に矛盾があるか、一方が他意を含意するかを判定するタスク
質問応答:文章とこれに関する質問文が与えられ、適切な回答を選択肢の中から選ぶタスク。しばしば常識推論が必要となる
意味的類似度判定:2つの文が与えられ、これらが同じ意味であるかを判定するタスク
文書分類:与えられた文書がどのクラスに属するかを予測するタスク。評判分析タスクもこれに含まれる
・これら様々な言語理解タスクをまとめた**General Language Understanding Evaluation(GLUE)**ベンチマークというデータセットが公開されており、世界中の研究者がこのデータセットでの精度を競っている
★BERT
・google社が開発した事前学習モデルで、トランスフォーマーのエンコーダを利用しているため、入力される分全体が見えていて、通常の言語モデルによる学習が行えない
・代わりにMLMとNSPという2つのタスクにより事前学習を行う
・MLMは文内の単語のうち一部をマスクして見えないようにした状態で入力し、このマスクされた単語を予測させるタスク
・NSPは2つの文をつなげて入力し、2つの文が連続する文かどうかを判定するタスク
・転移学習ではGPTでも解くことができた様々な応用タスクを解くことができる
・さらに、品詞タグ付けや固有表現解析を行ったり、SQuADのような回答の範囲を予測するタイプの質問応答タスクを解いたりすることも可能
大規模言語モデル
・2022年11月に登場したChat-GPTはテキストデータからの言語モデルの学習だけでなく、生成された応答が適切かどうかを人間が判断し、その判断結果から強化学習を用いることでより高精度な応答を生成するようになった
・これを**RLHF(Reinforcement Learning from Human Feedback)**と呼ぶ
自然言語処理のタスク
・形態素解析:分を形態素という単位に分割する
・品詞などの判別も行うため、分かち書きされている英語等についても形態素解析を行う
・構文解析:分全体の構造を求める
・検索エンジンに代表される情報検索、文書要約、機械翻訳、対話システムなどの応用タスクも自然言語処理が関係する
・世界中の研究者はGLUEベンチマークというデータセットでの精度を競っている
深層強化学習
深層強化学習の基本的な手法と発展
・深層強化学習:ディープラーニングと強化学習を組み合わせた手法
・深層強化学習は、状態や行動の組み合わせが多い場合の学習を可能にした
・2013年に深層強化学習で最も基本的な手法であるDQNがDeepMind社から発表された
・ニューラルネットワークの入力は状態であり、出力層の各ノードは各坑道の価値となる。
・Q関数以外の行動選択の部分はQ学習と変わらない。つまり、DQNはQ関数の近似計算だけをニューラルネットワークで下請けさせる
・Q学習では、ある特定の状態に対して1つの状態価値(Q値)を割り当てて、その行動価値に対する学習を行っていた
・1ピクセル違うだけで別の状態と認識され、考えられる状態数が膨大になるため、デジタルゲームやロボットの制御に適用するには非現実的だった
・そこでDQNではゲームや実世界の画像をそのままディープニューラルネットワークの入力とし、行動候補の価値関数や方策を出力として学習するというアプローチをとる
・DQNでは、経験再生やターゲットネットワークという新しい学習手法が導入されている
・経験再生:環境を探索する過程で得た経験データをリプレイバッファと呼ばれる機構に保存し、あるタイミングでこれらの学習に使う手法
・これにより、学習に使うデータの時間的偏りをなくし学習の安定化を図っている
・ターゲットネットワーク:現在学習しているネットワークと、学習の時間差分がある過去のネットワークに教師のような役割をさせる手法
・これにより、価値推定を安定させる
・DQNの登場以降、様々な拡張手法が発表された
ダブルDQN、優先度付き経験再生:経験再生やターゲットネットワークの使い方を工夫した
デュエリングネットワーク、カテゴリカルDQN、ノイジーネットワーク:ディープニューラルネットワークのアーキテクチャや出力を工夫した
・これらをすべて組み合わせたRainbowと呼ばれる手法に発展している
・Rainbow以降も、内発的報酬と呼ばれる報酬の工夫により、きわめて難易度の高いゲームにおいても人間以上のパフォーマンスを発揮する手法が発表されている
深層強化学習とゲームAI
・深層強化学習の応用で最も盛んな分野の1つは、囲碁や将棋などのボードゲームをはじめとしたゲームの攻略を行うゲームAIである
<ボードゲームにおけるゲームAI>
・モンテカルロ木探索:複数回のゲーム機の展開によるランダムシミュレーションを基に近似的にいい打ち手を決定する手法
★AlphaGo
・2016年、トップ棋士に勝利し世界に衝撃を与えた
・モンテカルロ木探索に深層強化学習の手法を組み合わせて圧倒的な強さに到達している
★AlphaGo Zero
・人間の棋譜データを用いた教師あり学習は一切行わず、最初から自己対戦を行って得たデータのみで深層強化学習を行う
★Alpha Zero
・囲碁のみならず、将棋やチェスなどの分野でも多くのゲームAIを圧倒する性能を持つようになった
<その他のゲームにおけるゲームAI>
・リアルタイムにゲームが進行する不完全情報ゲームを対象とした手法の開発が行われている
・協調的な関係や競争的な関係を考慮して強化学習を行う必要がある
・このような複数エージェントによる強化学習はマルチエージェント強化学習と呼ばれる
★OpenAI Five
・MOBAという多人数対戦型ゲームData2において、トップチームを打倒できるゲームAI
・膨大な計算資源と学習時間が特徴
★AlphaStar
・RTSと呼ばれるジャンルの対戦型ゲームスタークラフト2において、トッププレイヤーを打倒できるゲームAI
・ResNet、LSTM、ポインターネットワーク、トランスフォーマーなど、画像処理や自然言語処理の手法も多く取り入れたネットワークを使って学習
・人工知能技術の集大成的なアルゴリズムになっている
実システム制御への応用
<実世界の性質に起因する複数の課題>
★状態や行動を適切に設定する必要がある
・連続値のセンサや制御信号のデータを一定の幅で離散化するだけでは、状態や行動の数が指数的に増大するという次元の呪いという問題に直面する
・問題に対して適切な方策を学習できるように、エージェントは入力となるセンサデータから、「状態」に関する良い特徴表現を学習する必要がある
・特に深層強化学習の文脈では、「状態」に関する特徴量表現を指して、状態表現学習と呼ぶ
・深層強化学習において、「行動」を学習する際、「左」や「右」は離散値で出力する必要があるのに対し、スピード等は連続値で出力する問題である
・このような問題は連続値制御問題と呼ばれている
★報酬設計が難しい
・強化学習では報酬関数の設計によって、得られる方策の挙動は大きく異なる
・報酬関数の設計と学習された方策の挙動の確認を繰り返して、適切に学習が行われるように報酬関数を作りこむ報酬成形が必要である
★サンプル効率が低い割にデータ収集コストが高い
★方策の安全性の担保が難しい
<課題に対する解決策>
・人間が環境やロボットに行わせたいタスクに関する事前知識(ドメイン知識)を学習に組み込むための工夫を施すことで効率的な学習を目指す手法が提案されている
★オフラインデータの利用
・事前に集めたデータ**(オフラインデータ)から方策を学習する手法も盛んに研究されている
・オフライン強化学習と模倣学習はロボット学習領域で近年盛んに研究されているアルゴリズム
・模倣学習:人間がロボットに期待する動作をロボットに対して教示することで、ロボットが方策を学習する問題設定
・この時の教示データはデモンストレーション**と呼ばれる
・オフライン強化学習:過去に集めたデータのみを使ってオフラインで強化学習を行う手法
★シミュレータの利用
・sim2real:シミュレータで学習した方策を現実世界に転移して利用する設定
・リアリティギャップ:現実世界とシミュレータで再現された世界との差異
・ドメインランダマイゼーション:シミュレータの各種パラメータをランダムに設定した複数のシミュレータを用いて生成したデータから学習する
残差強化学習
・最初に経験や事前知識、計算等による初期方策を用意し、最適な方策との差を強化学習によって学習する手法
環境のモデルの学習
・これまでの深層強化学習の手法は、環境に関する知識を明示的に学習しないモデルフリーの強化学習のアルゴリズムだった
・一方で、環境に関する予測モデルを明示的に活用しながら方策の学習を行う強化学習アルゴリズムは、モデルベース強化学習と呼ばれ、研究が進められている
・世界モデル:エージェントが、得られる情報を元に自身の周りの世界に関する予測モデルを学習して、方策の学習に活用する枠組み
データ生成
生成タスク
・ディープラーニングは、生成タスクにも応用されている
・例えば、画像が持つ潜在空間を学習すると、そこから新しい画像を生成できるようになる
・また、音声生成や文章生成に発展させることもできる
・データ生成には、**変分オートエンコーダ(VAE)や敵対的生成ネットワーク(GAN)**が用いられ、画像生成ではGANが良い成果を残している
敵対的生成ネットワーク
・GANは2種類のネットワークで構成されており、それぞれジェネレータとディスクリミネータ
・ジェネレータ:ランダムなベクトルを入力とし、画像を生成して出力する
・ディスクリミネータ:画像を入力とし、その画像が本物か(ディスクリミネータによって生成された)偽物かを予測して出力する
・ジェネレータはディスクリミネータが間違えるような偽物画像を作るように学習していく
・ディスクリミネータは偽物をきちんと見抜けるように学習していく
・これらを競い合わせることで、最終的には本物と見分けがつかないような偽物すなわち新しい画像を作り出すことを実現する
・DCGAN:GANの派生モデルで、ニューラルネットワークの代わりに畳み込みニューラルネットワークを採用している
・DCGANによって、高解像度な画像の生成を可能にしている
・Pix2Pix:ある画像データを入力し、別の画像に変換する処理
・元の画像データと変換した画像のペアが本物か偽物か予測することにより、昼の画像を夜の画像に変換するなどが可能となる
・ただし、あらかじめペアの画像を学習のために用意しておかなければいけない
・Cycle GAN:画像のペアが必要ない方法
・シマウマと馬のような別のドメイン間を行ったり来たりするように画像を生成することで、ドメインの変換を可能とする
Diffusion Model
・Diffusion Modelはデータを生成する過程を時間的な連続的な拡散のプロセスとしている
・拡散のプロセスは、画像データにノイズを加えていき、ガウス分布にする拡散過程と、ノイズから徐々にノイズを除去して画像データを生成する逆拡散過程の2つに分かれている
・学習時は拡散過程を行い、データ生成時は逆拡散過程のみ行う
NeRF
・複数の支店の画像を手掛かりに3次元形状を復元し、3Dシーンを生成する技術
・NeRHを用いることで、新たな視点の画像を生成することもできる
転移学習・ファインチューニング
学習済みモデル
・「超」深層なネットワークを学習することが可能になったが、学習に必要な計算量も膨大になった。
・もしすでに学習済みのネットワークがあれば新たに学習する必要はない
・これを事前学習済みモデルといい、ImageNetで公開されており、誰でも利用できる
転移学習
・学習する際は、出力層だけ初期化して学習する。このような学習の方法を転移学習と呼ぶ
・適用したい問題に合わせて、追加する総数を変えても問題ない
ファインチューニング
・転移学習では、適用したい問題によっては不十分な場合がある
・その場合、モデルのすべての重みを更新するよう学習する
・このような学習の方法をファインチューニングという
少量データでの学習
・転移学習やファインチューニングを行う場合、データ数はそれほど多くなくてもいい
・Few-shot学習:数枚程度のデータで学習する方法
・そのうち1つの方法として、MAML(Modal-Agnostic Meta-Learning)がある
・MAMLは、モデルの重みをどのように更新すればいいかという学習方法自体を学習する
・これをメタ学習という
・さらに少なく1つのデータで学習する方法はOne-shot学習という
・Few-shot学習やOne-shot学習は自然言語分野でもよく用いられる
・例えばChatGPTにおいて、Zero-shot学習では例題を与えずに指示だけ与える
半教師あり学習
・正解となる情報をすべてのデータにつけるのはとても手間がかかる
・半教師あり学習:正解の付いてないデータも含めて学習に利用する方法
・正解の付いているデータを利用して学習を行い、正解の付いていないデータを評価する。そして、その結果をもとに疑似的な正解をつける
・これにより、学習に利用できるデータを増やすことができる
・データに対してノイズを加えた変換後のデータと返還前のデータをそれぞれモデルに入力した際、同じような出力になるべき。この変化前と変化後のデータ間の差を最小化する考え方を一致性正則化という
・FixMatchでは、疑似的な正解ラベルと一致性正則化を組み合わせて高い精度を達成している
自己教師あり学習
・正解ラベルの無いデータセットを用いてモデルに疑似的なラベルを自動生成させる手法
・データに対する正解を利用せずに学習する
・自己教師あり学習では、プレテキストタスクという、人間があらかじめ設定した問題を学習する
・例えば、画像認識分野の場合、入力データに異なるデータ拡張を施して、モデルに入力する。モデルが出力する特徴が類似するように学習する
・これは一致正則化と同じ原理
継続学習
・認識したいクラスが増えた場合や、認識したい環境(ドメイン)が変わっていく場合など、適用範囲が広がることもある。
・このように適用範囲が増えるごとに学習を行うことを継続学習と呼ぶ
・継続学習では過去に学習したクラスを正しく認識できない破壊的忘却が起きることがある
・いかに破壊的忘却が起きないようにするかは継続学習において重要な課題である
マルチモーダル
マルチモーダルタスク
・画像とテキストなど異なるモダリティのデータを同時に取り扱う取り組みが増えている
・Image Captioningでは、画像データを入力すると、その内容のみを要約したテキストを出力する
基盤モデル
・CLIPでは、画像から抽出する特徴とテキストから抽出する特徴が同じになるように非常に大量のデータで学習する
・CLIPで抽出した特徴は、物体認識や物体検出、Visual Question Answeringなど、に利用可能
・CLIPとDiffusion Modelを用いるDALL-Eは、テキストで指定した画像を高品質に生成できるようになりました
・さらにCLIPは、学習していない新しいタスクに対しても、そのタスクの説明を与えると実行できる。これをZero-shot学習という
・これは、モデルがテキストと画像の広範な関連性をとらえる能力に起因している
・CLIPの登場以降、FlamingoやUnified-IOなど画像とテキストの関連性をとらえる特徴が抽出できるモデルが考案され、基盤モデルと呼ばれる
モデルの解釈性
説明可能AI(Explainable AI)
・モデルが「どのように予測をしているのか」も考慮しておくべき
・予測精度が向上したからこそ、その予測の根拠が求められる。
・どのようにモデルの**判断根拠を解釈し、**説明可能にするか、ということで、説明可能AIが注目されている
・LIME:入力データの特徴の一部だけを与え、その時の振る舞いを線形モデルに近似する
・Permutation Importance:入力データの特徴をランダムに入れて、振る舞いの変化を元に特徴の寄与度を測る
・SHAP:特徴量の寄与度を測ることでモデルの解釈を行う
CAM
・**Class Activation Mapping(CAM)**は、画像認識タスクに用いるモデルの予測判断根拠を示すために、「画像のどこを見ているか」を可視化する
・Global Average Poolingを最終層の手前に用いたネットワークの構造をしている
・シンプルな構造だが、判断根拠を可視化する層が決まっている
Grad-CAM
・Grad-CAMは、勾配情報を用いて指定した層における判断根拠を可視化できる
・ヒートマップを用いて可視化する
・ただし、Grad-CAMは画像が低解像度になってしまうという問題点がある
・その問題点を解決するために入力値の勾配情報も用いたGuided Grad-CAMという手法もある
モデルの軽量化
蒸留
・層が深く高精度なネットワークが学習した知識を、層が浅く軽量なニューラルネットワークに伝える方法
・蒸留を行うことで、計算コスト減少、精度向上、正則化効果、学習の効率化が期待される
・蒸留では、層が深く複雑な学習済みのネットワークを教師ネットワーク、教師の学んだ知識を伝える未学習のネットワークを生徒ネットワークと呼ぶ
・hard target:通常の学習時に用いるone-hotな正解ラベル
・soft target:教師ネットワークの事後確率
枝刈り
・ニューラルネットワークの接続の一部を切断する。すなわち重みの値を0にする処理
・マグニチュードベース:重みの値が一定より小さければ0にする
・学習後の重みについて、絶対値の小さい者から順番に削除する
・勾配ベース:勾配情報を利用する手法
・モデルにデータを入力して各クラスの確信度を主つりょ臆し、各重みの評価値を算出しその評価値が小さいものから削除する
・少しずつモデルサイズを圧縮することが多い。なぜなら、いきなり多くの重みを削除すると精度に悪影響を及ぼすから
・宝くじ仮説:モデルを学習する際に、よりよい初期値(宝くじ)を持つサブネットワークがモデル全体の中に含まれているという考え方
・このサブネットワークが枝刈りしたモデルに相当する
量子化
・重みなどのパラメータを少ないビット数で表現して、モデルを圧縮する方法
・ディープラーニングの学習では、誤差や購買などの値は小さいため、32ビット浮動小数点数を使用している
・そこまで必要としないため、学習したモデルの重みを8ビット整数にしてめもりしようりょうのさくげんをおこ
AIの社会実装に向けて
AIのビジネス利活用
・ビジネスにおいてAIを利活用する本質は、AIによって経営課題を解決し、利益を創出する点にある
・ビジネス的な成功と技術的な成功は車の両輪であり、一方だけを論点とすることはできない
・マネタイズポイントが明確でなく継続できなくなる失敗が多く起こっている
AIプロジェクトの進め方
AIプロジェクト全体像と注意すべき点
・「そもそもAIを適用する必要があるのかを考察し、利活用した場合の利益計画を立てて投資判断を行う」
・「AIを適用する必要があるのか」について、AIの特性を理解したうえで判断する必要がある
・「利活用した場合の利益計画を立てて投資判断を行う」について、利益が出るのは数十年後ということになるため、短期の資産だけでなく、コストと推論制度のバランスを中長期で見ていく必要がある
・「ビジネス・技術上に組み込むべきデータのフィードバックの機構をどのようなものにするか検討する」
・運用を継続しながら推論制度を上げていくことが現実的な進め方である
・AIを利活用する場合はBPR(Business Process Re-engineering)が発生する
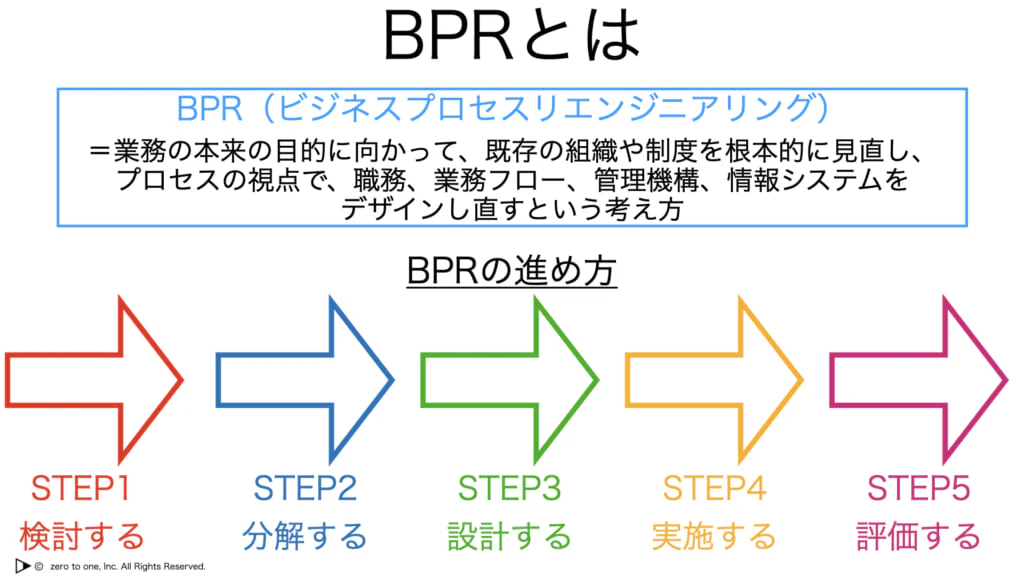

・AI導入後と導入前のコストを算出し、差が大きい場合はAIの適用箇所と技術の連携範囲を再検討する必要がある
・システムの「納品」はAIプロジェクトには向かない。サービスとして提供し運用することが望ましい。
・クラウドを使うことで、必要な時に必要な量のリソースを利用することができる
・Web APIを用いてモデルに入力データを送り推論結果を返すという方法がある
・Web API:ネットワーク越しにシステム間で情報を受け渡す仕組みのこと
・デプロイ:クラウドをはじめとしたコンピューティングリソース上にモデルを置いて利用できるようにすること
・エッジ:利用現場側に配備するリソースのこと
・計算機内でモデルを動かし、入力されたデータに対して推論結果を出力する
・開発計画を策定する
・AIプロジェクトは、
①データを確認する段階、
②モデルを試作する段階(PoC)、
③運用に向けた開発をする段階にフェーズを細かく区切り、収集されたデータの中身や学習して得られたモデルの精度
に応じて、柔軟方針を修正できるような体制が望ましい
・プロジェクト体制を構築する
・AIプロジェクトは、開発段階から多岐にわたるスキルを保有する様々なステークホルダーを巻き込んだ体制づくりが必要となる
各フェーズの進め方(プロジェクト計画)
・開発前後の重要なプロセスはフレームや概念として体系化されている
★CRISP-DM
・データマイニングのための産業横断型標準プロセスのこと
・主にデータを分析することに主題を置いており、6つのステップに分割されている
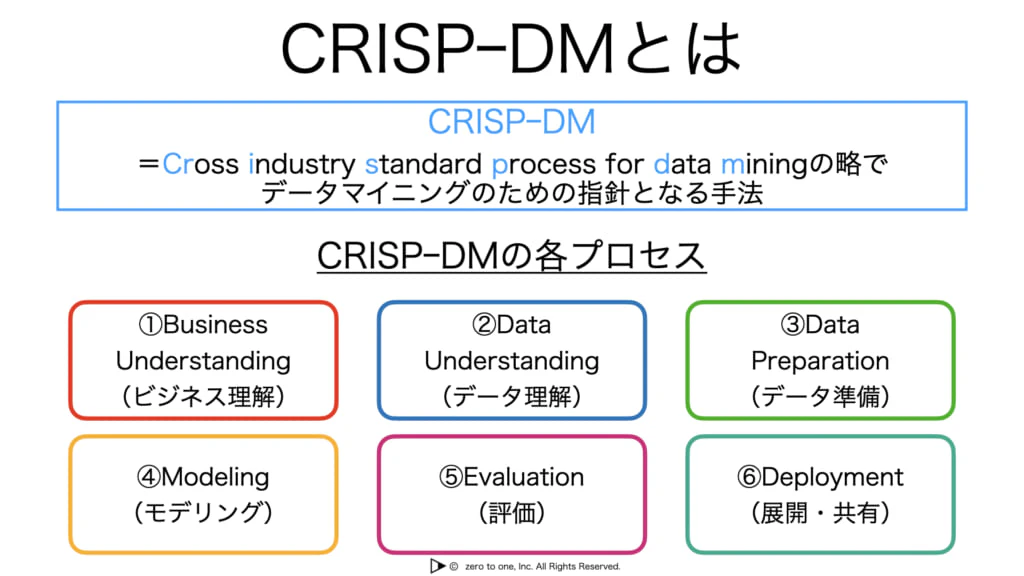
・この6つを行ったり来たりして実行する
CRISP-ML
・CRISP-DMを発展させた概念
・ビジネス理解とデータ理解が統合され、監視・保守が追加され6つのステップとなっている
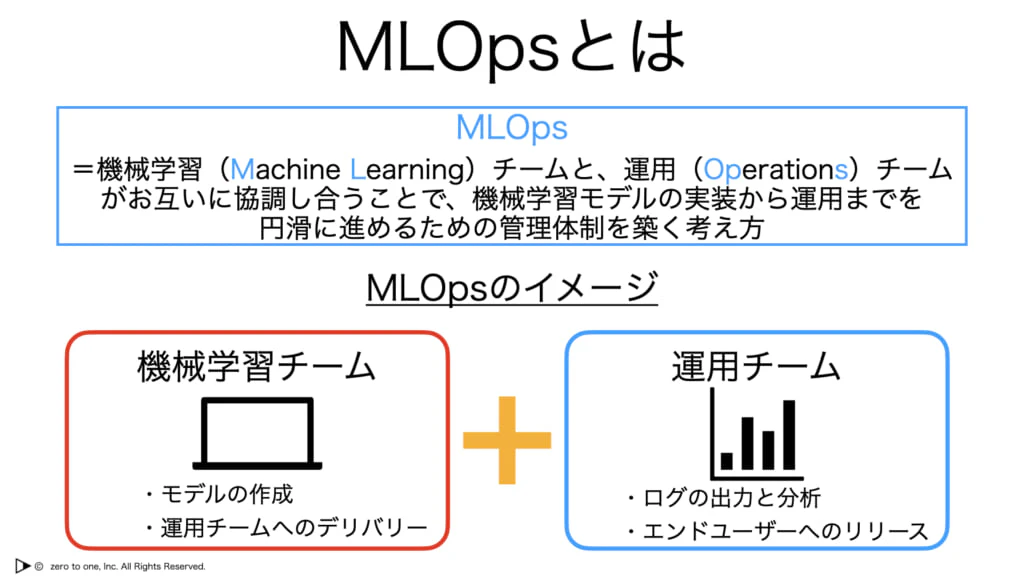
★MLOps
・AIを本番環境で開発しながら運用するまでの概念

・サービス化
・推論を行う環境やデータを蓄積する環境などを考慮することが必要
・クラウドを利用する際は、サーバの数を検討することなどが必要
・エッジの場合は、更新する仕組みの開発や故障した際の運用体制などが重要
各フェーズの進め方(実装・運用・評価)
・産学連携を行うことでプロジェクトメンバーを分散させることも1つの方法
・外部のアイデアや技術と結合し、オープンイノベーション化を計るのもイノベーションを生み出す
データの収集・加工・分析・学習
データの収集方法及び利用条件の確認
・AIプロジェクトはデータの質と量が重要
・オープンデータセット:企業や研究者が公開しているデータセット
<コンピュータビジョン分野>
・ImageNet、PascalVOC、MS COCO
<自然言語処理>
・WordNet、SQuAD、DBPedia
<音声分野>
・LibriSpeech
・オープンデータが利用できない場合、センサを利用し環境の情報を計測するアプローチがある
学習可能なデータを集める
・データを収集する際にはAIのモデルを訓練できるデータとなるように気を付けなければいけない
①データに認識すべき対象の情報が十分に含まれている必要がある
・背景と同化していたり、ぼやけている画像は望ましくない
②データの偏りをなくすことが重要
・特定のタイプに偏った出力をしたり、過剰適応したりする原因になる
③データの網羅性
・十分な制度を確保するためには、広い状況を網羅できるようにデータを準備しておく必要がある
データを加工する
・生データは不要な情報やデータ間の形式の違いがあるため、データの加工を行う
・教師あり学習の場合、正解データを作成する必要がある
・正解データは人間の手によって作成され、この作業をアノテーションと呼ぶ。人によってアノテーションがばらつくといけないため、要件を正しく定める。
・要件を決める際には。マニュアルを作成し、作業者が要件を理解できるようにする
・分析のために収集したデータの中には、様々な個人情報が含まれることがある
・保護のため、匿名加工を行う。また、生データは削除する
開発・学習環境を準備する
・AIモデルを開発する際、Pythonが一番多く使われている
・Pythonを利用して複数人と開発したり、実装済みのコードを利用したりする場合にはPython自体とそれらのライブラリのバージョンを合わせる必要がある
・環境を切り替えるためのツールとして、pyenv、virtualenv、pipenv、poetryなど様々なものがある。Dockerのような仮想環境を利用することでOSのレベルから環境の一貫性を保つこともできる
・Pythonコードを作成するための開発環境として、テキストエディタを使う方式、IDE(統合開発環境)を使うやり方、Jupyter NotebookやGoogle Colaboratoryというブラウザ上でPythonコードを編集・実行する方式がある
・テキストエディタとしてVimやEmacsが広く使われている
<広く使われるライブラリ>
・Numpy:ベクトルや行列計算など、様々な数学関数を提供
・Scipy:最適化や統計処理、特殊関数等の機能
・Pandas:表や時系列データを操作するデータ構造や演算を提供
・Scikit-learn:SVMやランダムフォレスト、k近傍法などを含むん分類問題、回帰、クラスタリングアルゴリズムを備える
・LightGBM:決定機アルゴリズムに基づいた勾配ブースティングの機械学習フレームワーク
・XGBoost:LightGBMと並ぶ、機械学習フレームワーク
・Pytorch:ディープラーニングのためのオープンソースライブラリ
・Tensorflow:Pytorchと並ぶ、ディープラーニングのためのオープンソースライブラリ。当初はDefine and Runだったが、現在はDefine by Runがデフォルト
・Pytorch lightning:ディープラーニングの様々な機能を簡潔に書くためのPytorchをベースとしたフレームワーク
・Optuna:ハイパーパラメータの自動チューニングを行うライブラリ
・TensorBoard:モデルや学習の履歴の可視化、途中過程で作成されるメディアの表示などが可能
・MLFlow:機械学習ライフサイクル(実験・再現・デプロイ)を支援するためのツール郡
・CUDA:GPU上での汎用的なプログラムを開発するためのライブラリ
・TensorRT:推論時においてNVIDIA GPUのパフォーマンスを引き出すための高速化ライブラリ
・DeepSpeed:ディープラーニングを行うための最適化ライブラリで、大規模なモデルのトレーニングを行うためのツール
・transformers:自然言語処理に特化したライブラリ
・mmdetection:最新の物体検知手法が実装されている
AIモデルを学習する
・AIモデルの学習の初期は、パラメータの設定が甘くモデルの精度が低いところから始まるため、モデルの調整によって大きな精度向上が見込める
・それ以上の精度向上はコストがかかりやすく、大幅な改善は難しい
・既存の学習済みモデルを用いて転移学習することも考えられる。こうすることで少数のデータからでも学習が安定したり精度が向上したりすることが見込める
・制度を正しく検証するためには、学習に用いたデータ以外のテストデータを用いて検証を行うことが一般的
・過適合を防ぐために、バリデーションデータを用意し、モデルの調整を行う。最終的な性能評価はテストデータを用いて行うという方法がある
・データリーク:モデルが本来知るべきでない情報にアクセスしてしまう現象。過学習の原因となる
推論を行う
・AIモデルが学習された後のステップ1は、そのモデルを用いて実際の推論を行うこと。この推論モデルは、学習モデルを元にして作成され、実際のデータに対して予測や分類を行う役割を担う
・学習の際には高性能なGPUを利用してモデルの最適化を行うが、運用時にはCPUやエッジデバイスを用いて推論を行う。そのためモデルの最適化や軽量化が必要となることがある
・環境の変化などによって当初の学習データとは異なるデータが増えてくる可能性がある。そのため、定期的にデータを再収集し、モデルを再学習あるいは微調整することがすいしょうされる
AIの法律と倫理
AIの法律と倫理
比較的頻繁に遭遇する法律は、
①個人情報保護法
②知的財産法
③契約
④不正競争防止法
⑤独占禁止法
・AIの品質は精度等だけでなく倫理的な要素も含む。倫理的にしっかりとしたAIを作ることで社会や顧客に受け入れられるようになる
AIの法律
著作権法
・AI開発では、しばしば著作権が問題になる
・著作権は、著作物を満たすものを著作した場合に発生する
・著作物とは、「思想又は感情を創作的に表現した」という点がポイント
・データは単なる事実であり著作権の保護の対象ではないが、データベースについては創作性が認められる場合に特別な規定により著作権が認められる
★著作者人格権
・著作権には大きく2つの権利が存在し、1つが財産権としての著作権であり、もう1つが著作者人格権
・著作者人格権は著作者の精神が傷つけられないように保護する権利であり、財産権とは異なり譲渡できない
★職務著作
・職務著作:従業員等が職務上行う著作のこと
・要件を満たせば会社等の法人に著作権が原則として帰属する
・業務委託先が行った著作の著作権は発注者ではなく業務委託先に帰属する
★著作権法30条の4
・著作権法30条の4はAIに関する著作権法であり、コンピュータによる情報解析に利用する場合には複製等を認めるという規定
<学習データの著作権の成否について>
★テーブルデータ
・表形式のテーブルデータの場合、ほとんどが客観的な事実であり、アノテーションも客観的事実のことが多いため、著作権が発生することはない
★画像データ
・人間がカメラを使って撮影した場合は著作権が発生するが、工場などにおいて自動撮影された場合等は発生しない
・アノテーションについては客観的事実であるため、著作権は発生しない
★テキストデータ
・人間が執筆した時点で著作権が発生する
・アノテーションについては著作権は発生しない
★プログラム
・プログラムも著作物であり、著作権が発生する
・対して、パラメータについては著作権の対象ではない
<生成AIと著作権>
★学習用データへの利用
・著作物を生成AIの学習のためにコピー等することについて、著作権30条の4により原則的に適法
★AI生成物の著作権
・生成AIが生成したコンテンツ(AI著作物)については、創作性が認められず著作権は成立しない
・ただし、人間がAIを道具として捜索したような場合など人間に創作的寄与が認められる場合には著作権の成立が認められる
★AI生成物による著作権侵害
・既存著作物に類似していることを理由に著作権侵害が成立するためには、既存著作物に依拠している必要がある
・依拠性:人間の場合は既存著作物を見ながら絵を描いたなど
・AI生成物がどのような場合に既存著作物に依存しているといえるのかについて、特に学習用データを存在するデータに類似するコンテンツを生成した場合を中心に大きな議論になっている
特許法
・特許法とは、アイデアを保護する法制度であり、与えられると該当するアイデアを排他的・独占的に利用することができる
・特許権者からライセンスを受けないと第三者がそのアイデアを使うことはできない
・実施:特許の対象となったアイデアを利用すること
・ライセンスには、他の第三者にも実施権の付与を行う通常実施権と独占的排他的な権利を付与し特許権者自身も実施できないこととなる専用実施権がある
・アイデアが発明というためには自然法則を利用していることなどが必要になる。また、発明のうち、①産業上の利用可能性、②新規性、③進歩性を主要な要件として、これらを満たすものを特許権の対象としている
・日本の特許法では先願主義という先に出願した方に特許を与えるという制度が採用されている
・従業員が行った発明について、事前に定めていれば企業等に特許権は帰属する。ただし、適切な対価を支払う必要がある
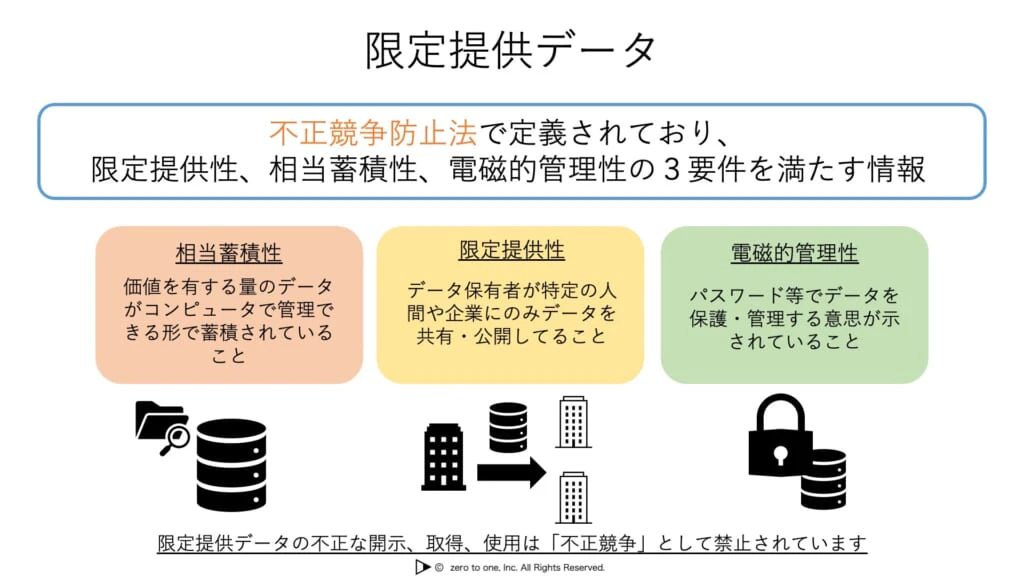
データの保護と不正競争防止法
・不正競争防止法は、営業秘密と限定提供データ**という2つの類型のデータについて保護を与えている
★営業秘密
・①秘密管理性、②有用性、③非公知性を満たす情報を、不正競争防止法は営業秘密として保護している
・しばしば争いになるのが秘密管理性である。主観的な評価だけでなく、秘密管理の意思が自蜜管理措置によって明示されている必要がある
・例えば、他の情報と区別されていたり、マル秘表記、営業秘密のリスト化、閲覧のためのパスワード設定など
★限定提供データ
・例えば人流データをイベント企業に提供するとき、非公知性を満たさないため、営業秘密によりデータを保護することができない。
・このようなデータについて、不正競争防止法において、「限定提供データ」として保護を受けることができる
個人情報保護法
★個人情報
・以下のように定義されている
①当該情報に含まれる氏名、生年月日その他の記述等により特定の個人を識別することができるもの(ほかの情報と容易に照合することができ、それにより特定の個人を識別することができることとなるものを含む)
②個人識別符号が含まれるもの
・①については、個人が識別できるかという点が重要
・②について、個人識別符号は法令で定められた番号や記号などが該当する。具体的には、指紋やDNAなどの生体情報や、運転免許証番号などの公的機関により与えられる番号も該当する
★個人データベース等
・個人情報を含む情報の複合体であって、特定の個人情報を検索できるようにしたもの
・紙媒体によるデータベースも含まれる
★個人データ
・個人データベース等を構成する個人情報
★保有個人データ
・開示、訂正、削除等の権限を有する個人データを指す
・委託により預かっている個人データは保有個人データではない
<類型ごとの規制概要>
★個人情報に対する規制
①利用目的の特定等
・個人情報の取り扱いには利用目的をできるだけ特定する必要があり、あらかじめ本人の同意なく利用目的を超えてはいけない
・また、事前又はすみやかに公表するか通知する必要がある
・通常の個人情報の場合は取得の際同委は不要だが、要配慮個人情報の場合、取得には同意が必要
②不適正な利用の禁止等
・偽りその他不正の手段により取得・利用してはいけない
★個人データに対する規制
①取得利用に関する規制
・個人データを正確・最新の内容に保ち、利用する必要がなくなったときに遅滞なく消去する努力義務が課されている
②安全管理義務
・安全管理のために必要かつ適切な措置を講じなければいけない
・従業員に対して必要かつ適切な監督を行う必要がある。委託先にも同じ
③第三者提供規制
・個人データを第三者に提供する場合、原則として本人の同意が必要(オプトイン)
・一定の条件を満たすと、第三者提供に反対をしなかった本人の個人情報を同意なく第三者に提供が可能(オプトアウト)
・一見第三者提供に見えるような場合でも、一定の場合には第三者への提供に該当しない場合がある
・最も重要な例外は委託に関する例外であり、利用目的の達成に必要な範囲内において個人データの取り扱いを委託することに伴って個人データが提供される場合には、同意が不要である
★保有個人データに対する規制
①開示請求
個人情報の本人は開示請求が可能であり、企業は応じなければならない
②訂正等の請求権
・内容の訂正、追加または削除
・利用の停止または消去
★要配慮個人情報
・本人の人種、信条、社会的身分、病歴、犯罪の経歴、犯罪によって害を被った事実など特にセンシティブな個人情報を指す
・本人の同意なく取得することができない
・オプトアウトの方法による第三者提供ができない
★匿名加工情報
・一定の匿名化した情報の比較的自由な取り扱いを認めている
・匿名加工情報とするには、特定の個人を識別することができないように加工する必要がある
・比較的自由に第三者提供できる
★仮名加工情報
・匿名化の度合いが少ない情報として、仮名加工情報という制度を設けている
・第三者提供が原則として禁止されており、事業者内部での利活用を想定した制度である
★個人関連情報
・生存する個人に関する情報であり、個人情報、仮名加工情報、匿名加工情報のいずれにも該当しないもの
・例えば、IPアドレスや閲覧履歴などがこれに該当する
・第三者に提供する場合、提供先の第三者が当該個人関連情報を個人データとして取得することが予想されるときは、提供元は本人の同意を確認しなければならない
★GDPR
・EU領域内の個人情報の保護を目的とした法
①EUの個人に商品・サービスの提供を行っている場合
②EU域内の個人の行動を監視している場合にも適用される
・日本の個人情報保護法と比較すると、
①GDPRの方が補語が及ぶ範囲が広い
②データポータビリティ権など日本にない権利が定められている
③データ保護責任者の配置等の個人情報保護法にはない義務が定められている
④データ移転に関して厳しい制限がある
⑤高額な制裁金がある
独占禁止法
・自由競争を阻害する行為を禁止することで公正かつ自由な競争を促進し、ひいては一般消費者の利益を保護等するための法律
<AIやデータに関する独占禁止法の問題>
★データの囲い込み
・巨大な事業者が不可欠なデータへのアクセスを禁じた場合は独占禁止法上の問題があるのではないかと議論されている
★AIのカルテル
・カルテル:複数の企業が連携して、商品の価格や生産量などを決める行為
・カルテルに参加している事業者間で価格決定アルゴリズムなどを用いることが議論されている
AI開発契約
<契約について>
・契約自由の原則:契約を行う・行わない、契約の内容等は基本的に契約当事者が自由に決めることができるという原則
★請負と準委任
・請負契約:仕事の完成を約束し、その結果に対して報酬が支払われる契約
・準委任契約:行為の実施のみを約束する
・また、履行割合型と成果完成型の2つがある
・履行割合型は事務の履行に対して報酬が支払われるのに対して、成果完成型は事務により得られる成果に対して報酬を支払う
・成果完成型準委任では成果の実現義務はない
<AI開発契約に関するガイドラインと特徴>
・経済産業省がAI・データの利用に関する契約ガイドラインを出している
・AI開発契約の特徴について
①モデルの内容がデータの品質に存すること
②性能保証が難しい
③ノウハウの重要度が高い
<開発の流れ>
①アセスメント:AIにより解決したい課題の整理、AI以外のソリューションの有無、AIが有効かを確認する
・成果物は報告書であることが多く、準委任契約を利用するのが通常
②PoC(概念実証)により取り扱い範囲の拡大や精度向上、AI導入により生じる様々な課題の解決を図る
・調査が目的であり、準委任契約を締結する。成果物は調査結果をまとめた報告書
③実装フェーズも準委任契約で行うことが多い
・成果物はモデルであり、成果完成型準委任を利用することもある
④追加学習フェーズでは、準委任契約が一般的
・モデルだけでなく、ユーザーがモデルを動かすための通常のシステム部分の開発も同時で行うことが多い
・アジャイル形式での開発の場合、準委任契約が用いられる
・ウォーターフォール契約の場合、要件定義は準委任、実装では請負契約を用いることが多い
<知的財産権の帰属>
・パラメータやデータセットについて、知的財産権が発生するか判断し、AI開発契約でその帰属を定める
<秘密保持契約>
・秘密保持契約(NDA)は:相手方の秘密情報の守秘を約束する契約
・目的をはっきりと記載する・また、守秘義務の機関についても適切に定める
AI利用契約
・クラウド型のAIなどではサービス提供者側の判断で追加学習が行われ、出力が変わることがある。
・これはやむを得ないため、サービス提供側が責任を負わない旨を定めておくべき
AIの倫理
概要
・AIによりもたらされる望ましくない影響に対処しAIを倫理的にしていくということで、AI倫理や信頼できるAIや責任あるAIという言葉が用いられる
国内外の諸ルールと取り組み
・ハード・ロー:典型的には法律であり、公的機関が定める遵守義務が生じるルールのこと
・ソフト・ロー:業界団体や学会も定める自主規制、ガイドラインなどであり、遵守義務が生じない
・ソフト・ローの方が柔軟に対応可能
<日本政府によるルール>
★人間中心のAI社会原則
・関係者が注意すべき基本原則を述べるガイドライン
★AI利活用ガイドライン
・AIをビジネスに利活用するものが留意すべき原則を述べている
★国際的な議論のためのAI開発ガイドライン案
・AI開発者が留意すべき原則について説明している
★AI原則実戦のためのガバナンスガイドライン
・実施すべき行動目標を支持し、実践例や実務的な対応例を示している
★新AI事業者ガイドライン
・今までのAIに関するガイドラインを統合したAI事業者ガイドライン
<外国政府によるルール>
★Blueprint for an AI Bill of Rights
・アメリカ
・AIの開発や利活用等をガイドする原則を説明
★Exective Order on Safe, Secure, and Trustworthy Artificial Intelligence
・大統領令
・AIの安全性に関して政府機関に対して研究を行うことなどの指示
★AI RISK MANAGEMENT FRAMEWORK
・アメリカ商務省配下のNIST
・AIに関するリスクマネジメントのためのフレームワーク
★AI法案等
・EU
・AIを直接規制する法の制定を目指している
・リスクに応じた規制を行うリスクベースアプローチが採用されている
・賠償ルールを定めるAI責任指令案
★Ethics guidelines for trustworthy AI
・EU
・信頼できるAIのための必要事項を解説する
<国際機関によるルールや国際連携>
★Reccomendation of the Council on Artificial Intelligence
・OECD
・信頼できるAIのための5原則と、政策決定者向けの推薦事項5つ
広島AIプロセス
・高度なAIシステムを開発する組織向けの広島プロセスの国際指針、同国際行動規範
GPAI
・理論と実務の橋渡しするための国際的な取り組みで、29か国が参加
ISO42001
・AIに関する国際標準
公平性
・AIの出力が公平でないために発生する問題がある
・基本的にはデータの方にバイアスが存在することが原因
安全性
・安全性:AIによって利用者や第三者の生命・身体・財産に危害が及ばないように配慮すること
・有効性:AIがタスクに対して適切に判断ができること
・ドメインによっては安全性基準などが存在する
プライバシー
・プライバシー・バイ・デザイン:システムやAIの開発の仕様設計段階からプライバシー保護の取り組みを行う考え方
透明性とアカウンタビリティ
・透明性:情報の開示に関する事項
・ディープラーニングなどは判断過程がブラックボックス化しており、透明性が求められる
・アカウンタビリティ:AIに関して責任を負うこと
・検証可能性、検証可能性、文書化、責任者や担当組織の明確化などが重要
セキュリティ
・データ汚染攻撃、敵対的事例を用いた推論結果の操作、細工をしたモデルの配布というモデル汚染攻撃など様々な方法がある
悪用の防止
・ディープフェイク、偽情報、詐欺、AIを利用したサイバー攻撃
仕事の保護
・AIによって引き起こされる仕事の喪失から労働者を保護することは重要なこと
・協働を考えることが重要
AIガバナンス
・AIガバナンス:AIに関する価値や原則を実現するために企業が行うべき取り組み
・AIポリシー:AIの価値や原則などの目的に対して、どのように取り組んでいくかなどを述べるドキュメント
・AIリスク・アセスメント:AIが自組織や利用者、社会にどのようなリスクを負わせるのかの検討
追加知識
人工知能の定義
Ponanza:世界コンピュータ将棋選手権で優勝した将棋AI
Stockfish:たびたびTCECで優勝していたチェスAI
elmo:2017年にトップクラスだった将棋AI
ベイズ統計モデリング:ベイズの理論を用いた機械学習の手法・計算量などの観点から実務に広く応用されているとは言い難い
ELIZA(エライザ)効果:「意識的にはわかっていても、無意識にコンピュータが人間と似た動機があるように感じてしまう」
人工知能の歴史
自動計算機械:機会に自動的に計算を行わせるための理論
エニグマ(ENIGMA):ナチス。ドイツが用いていた暗号機の名前
エドサック(EDSAC):1949年開発された初期のイギリスのコンピュータ。コンピュータの基礎となるものを作り上げていった
セマンティックネットワーク(意味ネットワーク):知識をネットワーク構造で表したもの
ナレッジグラフ:インターネット上の雑多な情報から、半自動的に構築しているもの
人工知能をめぐる動向と問題
拡張知能:IBM社の人工知能の言い方
OCR:活字や手書き文字の画像データから文字列に変換する文字認識機能
数理統計・機械学習の具体的手法
正則化:学習の目的関数にペナルティとなる項を追加することで、パラメータが極端な値になることを防ぐ
例)Ridge回帰やLasso回帰
ソフトクラスタリング:観測値が各クラスタに属する割合や確率を出力し、どのクラスタに属するかを決めてしまわない方法
ハードクラスタリング:k-means法など
特異値分解について
・成分がすべて実数の行列はすべて特異値分解することができる。また、特異値分解の方が、固有値分解よりも多くの行列に対して適用することができる
SHAP:決定木系のアルゴリズムや、ニューラルネットワークの派生アルゴリズムにも多様に活用できることから、実務において使われる場面も増えてきている
LIME:SHAPの前によく使われていた。ニューラルネットワークやランダムフォレストなどの複雑なモデルを線形モデルやルールモデルに近似し、局所的説明を生成する方法
・バイアス:予測値の平均と正解値とのずれ
・バリアンス:予測値自体のばらつき
ディープラーニングの概要
・ニューラルネットワークにおいて、出力層における活性化関数について、回帰問題では口頭関数が、分類問題ではソフトマックス関数が使われている
・隠れ層の活性化関数では、主にシグモイド関数やReLU関数が使われている
★制限付きボルツマンマシン(RBM):シンプルな2層のニューラルネットワークであり、深層信念ネットワークの構成要素である
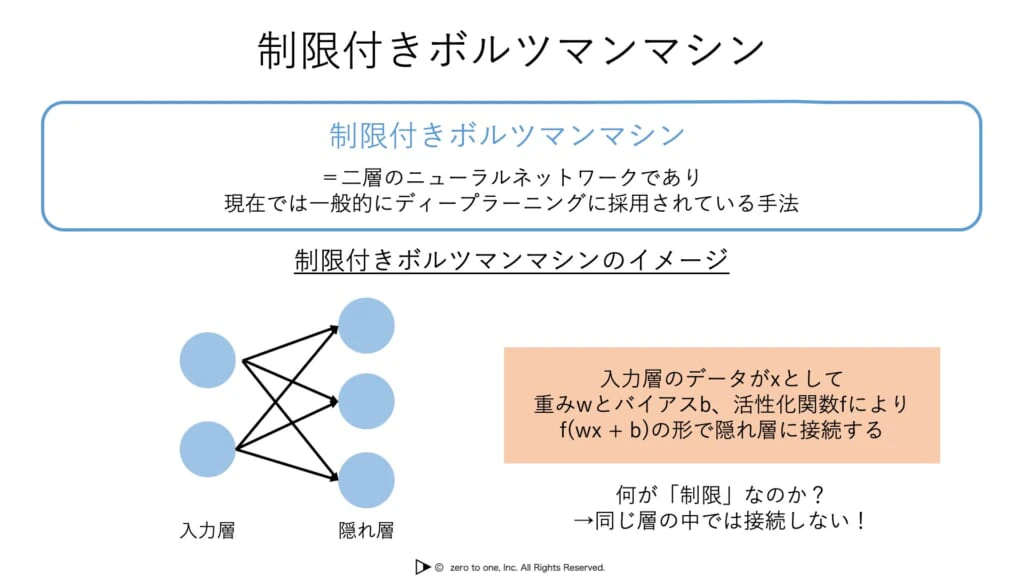
★オートエンコーダ:事前学習の一種であり、3層のニューラルネットワークである
・NVIDIA社が開発したCUBAは、GPU向けの汎用並列コンピューティングプラットフォームである
ディープラーニングの手法(1)
・tanh関数はシグモイド関数を式変形することで求めることができる
・勾配降下法について、パラメータ更新の式は、
x(更新後) = x(更新前) - (学習率) × (x(更新前)における勾配)
で表すことができ、学習率とは勾配に沿ってどれだけ降りていくかを設定する値である
・モーメンタムはパラメータの更新に完成的な性質を持たせ、勾配の方向に減速/加速したり、摩擦抵抗によって減衰したりしていくようにパラメータを更新するという工夫によって確率的勾配降下法を改善した手法である
・AMSGrad:重要でない構内に対して2乗勾配を利用して学習率が大きくなりすぎることを改善する手法
・Adam→AdaBound、AMSGrad→AMSBoundと改善された手法がそれぞれ存在する
・early stoppingをニューラルネットワークに適応する際のメリットとして、「どんな形状のネットワークでも容易に適応できる」がある
・データの白色化:データを無相関化してから標準化を行うもの
・各層で使用している活性化関数がシグモイド関数やtanh関数の場合は、ノードの初期値として、Xavierの初期値を用いると良いとされている
・ReLU関数を活性化関数として用いた場合、Heの初期値を用いるのが良いと提案されている
・画像データは縦横の2次元のデータであり、さらに色情報などが追加されると3次元のデータとなる。多層パーセプトロンでは、この画像データを入力する際に縦横に並んでいる画像を分解して、1次元に並び替えるように変形することでネットワークに入力できる形にする必要がある。したがって、この段階で画像データから物体の位置情報が失われてしまう
・CNNでは、特徴マップを1次元の数値に変換したのち、全結合層に接続している。したがって、全結合層は、多層パーセプトロンに用いられる層と同じ構造をしている
・RNN Encoder-Decoderモデルで、エンコーダは入力される時系列データから固定長のベクトルを生成し、デコーダでは固定長のベクトルから時系列データを生成する
・強化学習において、状態が遷移した後に報酬が得られなくても、方策を求めることができる。このような報酬を疎な報酬というが、学習に時間がかかることがある
・DQNを改良したDouble DQN手法について、2つの価値評価を異なるネットワークで行うことによって、偏ったQ値の過大評価を改善することができる
・DQNを改良したDueling Network手法において、Q値を分解するというアイデアのもとになったのは、行動選択が報酬の獲得にほとんど影響を与えない状態が多く存在するという洞察に基づいている
・DQNを改良したNoisy Networkは、ランダムな行動を起こし新たな行動を探索できるようになっている。ランダムなノイズを発生させるために、平均と標準偏差を学習しつつ、ガウス分布による乱数をネットワークの重みとして用いる
・AlphaGoでは、教師あり学習フェーズと強化学習フェーズの2段階で強さを高める
・教師あり学習フェーズでは、2つのネットワークを学習させる
・SL Policyはある盤面を見て次の盤面を予測する。入力データが現在の盤面状態、出力データが次の盤面状態、教師データは人間の棋譜
・Rollout PolicyはSL Policyとやることは変わらないが、予測性能を下げる代わりに計算を高速にした。入力データが現在の盤面状態、出力データが次の盤面状態、教師データは人間の棋譜
・教師あり学習フェーズで人間的な囲碁がざっくりとできるようになったため、強化学習フェーズに入る
・RL Policyは最強のPolicyとそれ以外のPolicyで対戦し、強くしていく。入力データが現在の盤面状態、出力データが次の盤面状態、教師データは自己対戦によるエピソードと報酬
・次に学習したRL PolicyとSL Policyを用いて自己対戦を行い、Value Networkという盤面を入力し勝率を予測するネットワークを学習させるためのデータセットを作成する
・入力データが現在の盤面状態、出力データが勝率、教師データは自己対戦による局面と勝敗
ディープラーニングの手法(2)
・ResNetの派生としてWide ResNetがある。ResNetの幅をよりwideにすることでモデルを深くすることなく高精度を出した。
・ここでいう幅とは畳み込み層の出力チャネル数のこと
・精度以外にも計算速度を上げるという効果も期待できる。なぜなら層を深くしないため。
・ResNetの派生モデルであるDenceNetは、ある畳み込み層の出力をそれよりも出力側の畳み込み層の出力とチャネル方向に連結する・
・ResNetは足し合わせる。
・ブロック内の各層の出力が以降の畳み込み層すべてに直接追加したため、特徴量の伝達が強化されている
・ドメインが異なるソースデータで学習したモデルをそのままターゲットデータに用いると、精度が大きく下がる。ドメインアダプテーションはこの問題を解決するための手法である
・ドメインアダプテーションでは、ソースデータとターゲットデータの分布をそろえるアプローチをとる
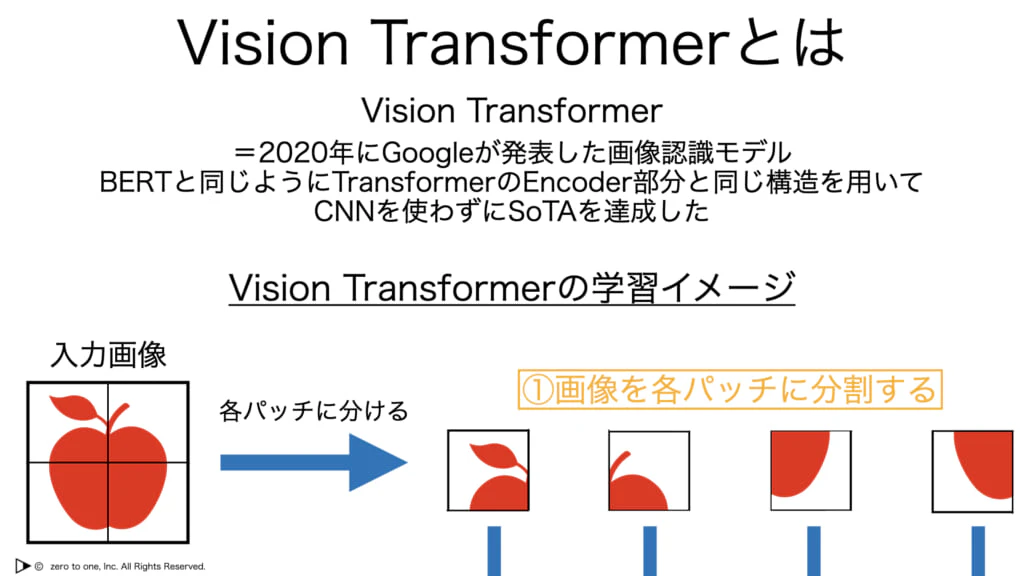
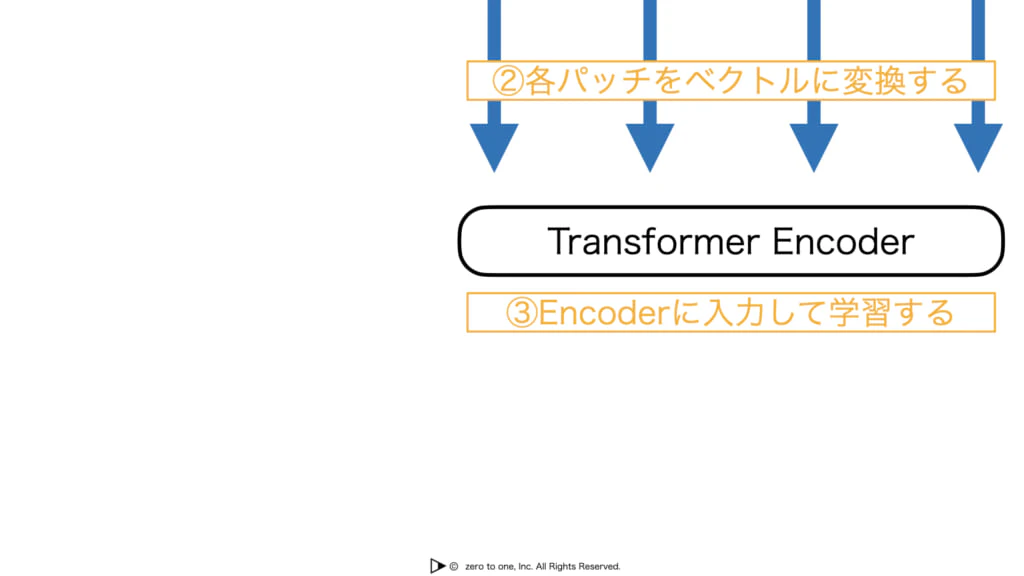
・Vision Tranceformer(ViT):自然言語処理分野から画像処理分野に持ち込まれたトランスフォーマーで、CNNを使わないモデルとして提案されている
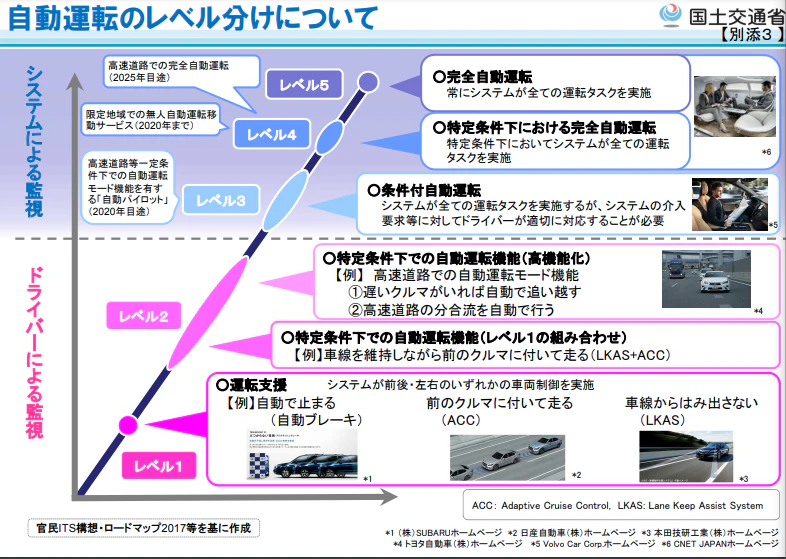
・自動運転のレベル分けについて
ディープラーニングの社会実装に向けて
・RPA:ホワイトカラー業務を自動化する技術の総称
クラス1:全プロセスを通して人間の思考判断を必要としない定型業務を自動化
クラス2:機械学習を取り入れることで人間的な思考判断を行うプロセスの自動化
クラス3:深層学習を搭載し、あらゆるデータを収集・学習し、意思決定まで行う。まだ存在しない
・SDK(Software Development Kit):ソフトウェア開発キットの略
・SOAP API:プログラミング言語やプラットフォームが異なるアプリ間でも通信できるようにするために設計された
・REST/RESTful API:HTTPプロトコルを用いた通信を採用していて、SOAP APIよりも軽量である
・アイデアソンやハッカソンは「現代社会の課題解決につながっていない」等の批判がある
・オープンイノベーションの考え方について、他社にも知的財産を使用させることで利益を得るオープン&クローズ戦略といった柔軟な方法も存在する
・フィルターバブル:見たくない情報は遮断するというフィルター機能のせいで、自分が見たい情報しか見えなくなること
・シリアスゲーム:純粋な娯楽のためではなく、教育や社会問題の解決を目的としたゲームのこと
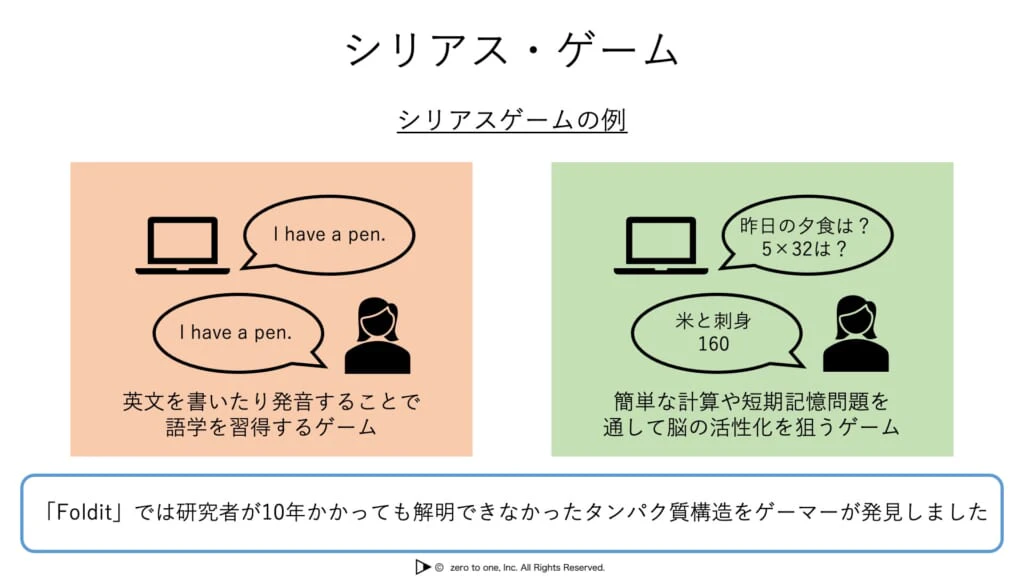
・クライシスコミュニケーション:トラブルが発生した後に行う危機管理対応
・リスクコミュニケーション:リスクに対しての事前の説明や、理解を得るために行うコミュニケーション
・DEIの原則(多様性、平等性、ほうかつせ)を守らないAIは、恩恵を受けられる人とそうでない人を生んでしまう
・機微情報:要配慮個人情報に加えて、労働組合の加盟や保健医療などのデータも含まれる。第三者提供のすべてが原則禁止
・AI開発用のデータセットを作成する場合、元となるデータ等の著作権者の承諾は原則としてひつようn