はじめに
こんにちは、KDDIアジャイル開発センターのはしもと(仮名)です。
2023年11月6日にアメリカ サンフランシスコにて開催された OpenAI Dev Day 2023。
イベント終了後から公開されていた Opening Keynote だけではなく、その他のセッションの模様も Youtube にアップロードされ始めました!!!!(ありがてえ!)
ここでは、セッションを動画見た瞬間「これ理解せずにLLM使ってアプリ開発してるのはまずい!」と個人的に感じた、"A Survey of Techniques for Maximizing LLM Performance" のセッションについての内容をかいつまんでまとめたいと思います。
セッション全体をスコープとするととても書ききれる気がしないため、本記事ではセッション冒頭約15分の内容を取り上げます。
セッションについて
45分と少し長いものの、自動翻訳で日本語字幕をつけることも可能なので、ぜひ元動画を観ることをおすすめします。
スピーカーは、OpenAI 社の John Allard 氏、Colin Jarvis 氏の2名です。
本セッションでは、プロンプトエンジニアリング、情報検索拡張生成(RAG)、ファインチューニングなど、LLM(大規模言語モデル)の性能を最大限に引き出すための技術が具体例とともに解説されています。
導入
LLMを手懐けようったってそうはいかないから!(意訳)

ヨッ!!!出ました """Optimizing LLMs is hard""" !!!!
2枚目のスライドででかでかと表示されたこの言葉、爆裂インパクト大賞ですね。
関連するフレームワークやコンテンツが多く登場する中、LLMを最適化することは最重要事項のひとつであるものの、それに対する明確な解決策は存在しない
この要因は大きく2つ
- 何が問題なのかを正確に知るために必要な、シグナルとノイズの分離が難しい
- LLMにおけるパフォーマンス測定は非常に抽象的である
→ 何が問題なのか、どのくらい問題なのかを知ることが困難な上、分かったところでどのアプローチを取るべきかを知ることもまた難しい
最適化手法とその効果
現在、LLMのパフォーマンス最適化において頻繁に取られるアプローチは以下の3つ。
プロンプトエンジニアリング
LLMに入力するプロンプトを工夫することで性能を上げる手法。
明確な指示の重要性
- LLMは与えられた指示に基づいて動作し、指示が明確であるほど、期待する結果に近づく
複雑なタスクの分解
- 複雑な問題を解決する際は、それを小さな部分に分解し、ステップバイステップで解決していくことが効果的である
- LLMに考える時間を与えることも効果的
ユースケースによってはこれだけでも十分な性能が得られるようになる
→ より複雑な問題を解決するためには、以下の手法と組み合わせる。
検索拡張生成(RAG)
LLMのコンテキストウィンドウに外部の知識を取り込ませる手法
外部情報の組み込みによる回答の質の向上
- LLMの知識を柔軟に拡張することができ、回答精度の向上が期待できる
レイテンシーの増加
- 大量のコンテキストを与えようとすると、その分トークン数が増加し、結果として推論にかかるコストとレイテンシーが増加する
RAGの効果を最大化するには、実際に必要な文書のみを適切に検索・選択する工夫が必要不可欠となり、検索アルゴリズムを見直したり、プロンプトエンジニアリングと上手く併用することが求められる。
ファインチューニング
事前学習済みのLLMをさらに特定のデータセットで訓練し直す手法
タスク特価のモデル調整
- ファインチューニングによってLLMのふるまいを目的のタスクに特化させることが可能
- プロンプトエンジニアリングの必要性も低減することができ、結果的に入力トークン数の削減によってレイテンシやコスト削減にもつながる
高品質データの必要性
- 特定の目的を達成するためのふるまいを表現した適切なデータセット構築と評価が不可欠
- 低品質なデータを大量に使用するのではなく、少数の高品質なデータから始める
ファインチューニングにおいても、RAGと同様にプロンプトエンジニアリングは重要です。
最適化の流れ
よろしくない考え

このように、各アプローチが直線的になっているかたち。
もちろんこの流れに沿って最適化を進めることも可能ですが、RAGとファインチューニングでは解決したい問題が異なります。
そのため、ユースケースによって両方が必要になることもあれば、どちらか片方だけでよいこともあります。
拡張した考え
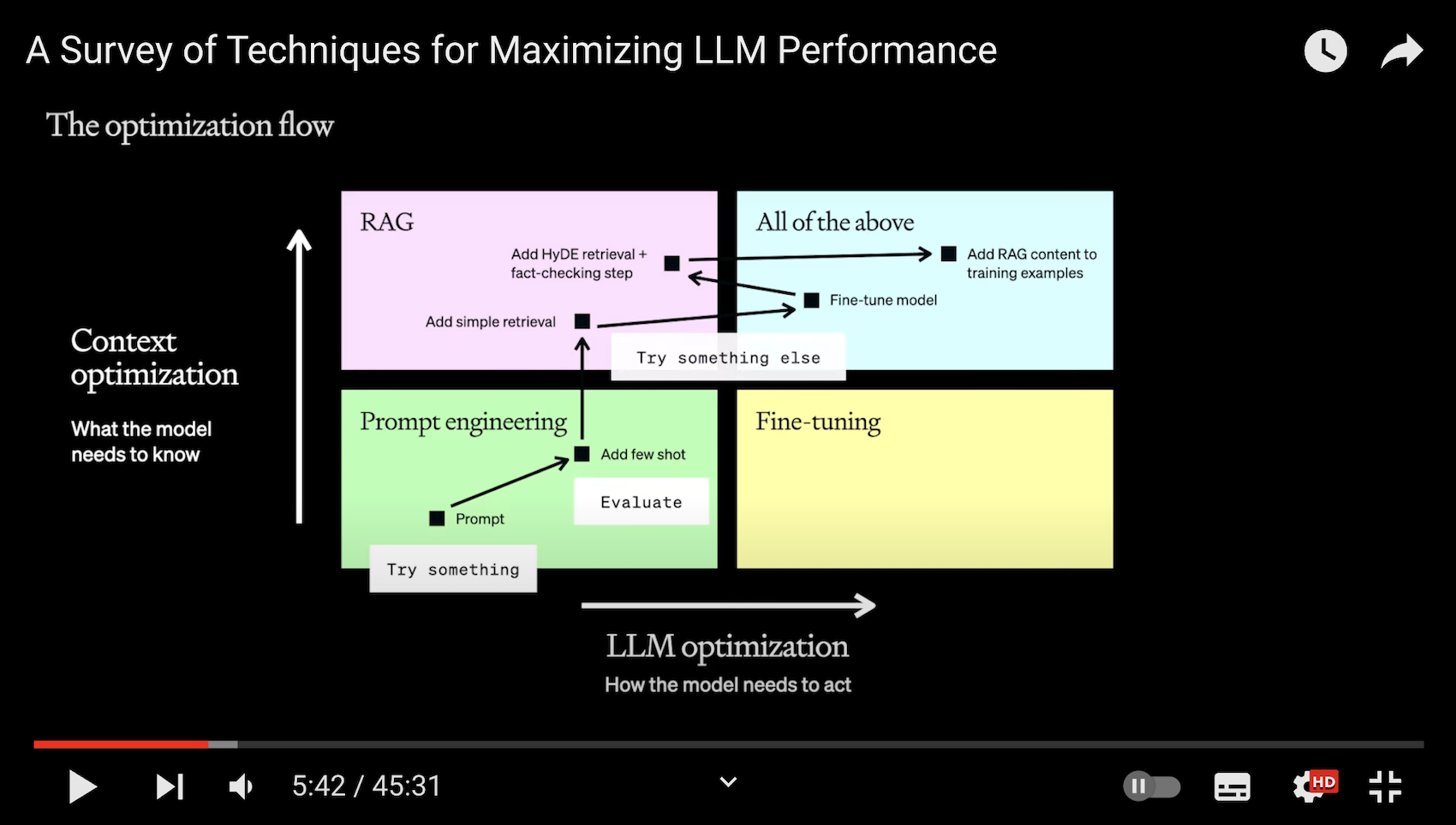
前述の原則を踏まえて拡張したものが上記の図です。
2つの軸でパフォーマンス最大化を目指すべきと語られています。
-
コンテキスト最適化(RAG)
→ モデルに対して、新しい情報や既に持っている知識と関連する知識が必要な場合はこっち -
LLM最適化(ファインチューニング)
→ モデルに対して、一貫した命令に従わせることが必要な場合はこっち
また、それぞれのアプローチの適用も直線的ではなく、横の軸(LLM最適化、ファインチューニング)と縦の軸(コンテキスト最適化、RAG)を行ったり来たりすることで、全体のパフォーマンスの向上につながるとあります。
繰り返しになりますが、ここの内容をまとめると
- RAGとファインチューニングではそもそも解決したい課題が異なる
- 全体のパフォーマンス最適化は直線的であるとは限らず、それぞれのアプローチを行き来すべきである
となります。
プロンプトエンジニアリングから始める
なぜ:ユースケースによっては、これだけで十分な性能が得られるため
前述の、「指示の明確化」や「複雑な問題の分割」、「モデルに考える時間を与える」ことも重要とされています。
ここに Few-shot Prompting/Learning を組み込むことで、RAGやファインチューニングを用いる前でも、パフォーマンス最適化を更に一段階進めることができます。
Few-shot Prompting/Learning とは、プロンプトの中に、望ましい動作の入力と出力の例を示すテクニックです。
プロンプトエンジニアリングで対応できない場合
前述の2つの軸で必要なアプローチを考え、パフォーマンス最適化を目指す。
ただし進め方にも注意
- 簡単な実装から開始する
- RAGならシンプルなアルゴリズムかつ少数のコンテキスト
- ファインチューニングなら少ないデータセット
- 性能を検証する
- RAG/ファインチューニングのアプローチを取る前の、ベースラインとなる性能と比較
- 検証した結果をもって、次のアプローチを選択する
- RAGで使用するアルゴリズムを変更する?検索対象を増やす?
- モデルのファインチューニングに使用するデータを増やす?質を見直す?
- 単純なRAGで性能向上が見られたので、もう一方の軸に関心を移す? etc...
- 選択したアプローチで検証を続ける
最初から派手なアルゴリズムとか大量のデータ使わずに、定量的に評価した性能と照らし合わせながら、方向性が正しいかを常に確認しろってことだと理解しました。胸が痛い...
最後に
備忘も兼ねて記事を作成しました。
ここに記載した内容は私なりの解釈が含まれる上、セッション内で語られていることのほんの一部でしかありません。
繰り返しになりますが、ぜひ本家のセッション動画もご覧ください。