はじめに
機械学習APIを作りたいとき、なるべくサーバの保守をしないで済むようにしたい場合、あまり高機能なものをやるわけではなければAWSのLambdaでサーバレスなシステムを作ることによって安価・迅速に実現したくなることがあると思います。
その場合、詰まるところがいくつかあったのでまとめてみました。
すぐにLambdaにLayerをアップロードしたいという方はGithubにコードをあげておいたのでこちらをご確認ください。
Lambda-Layers
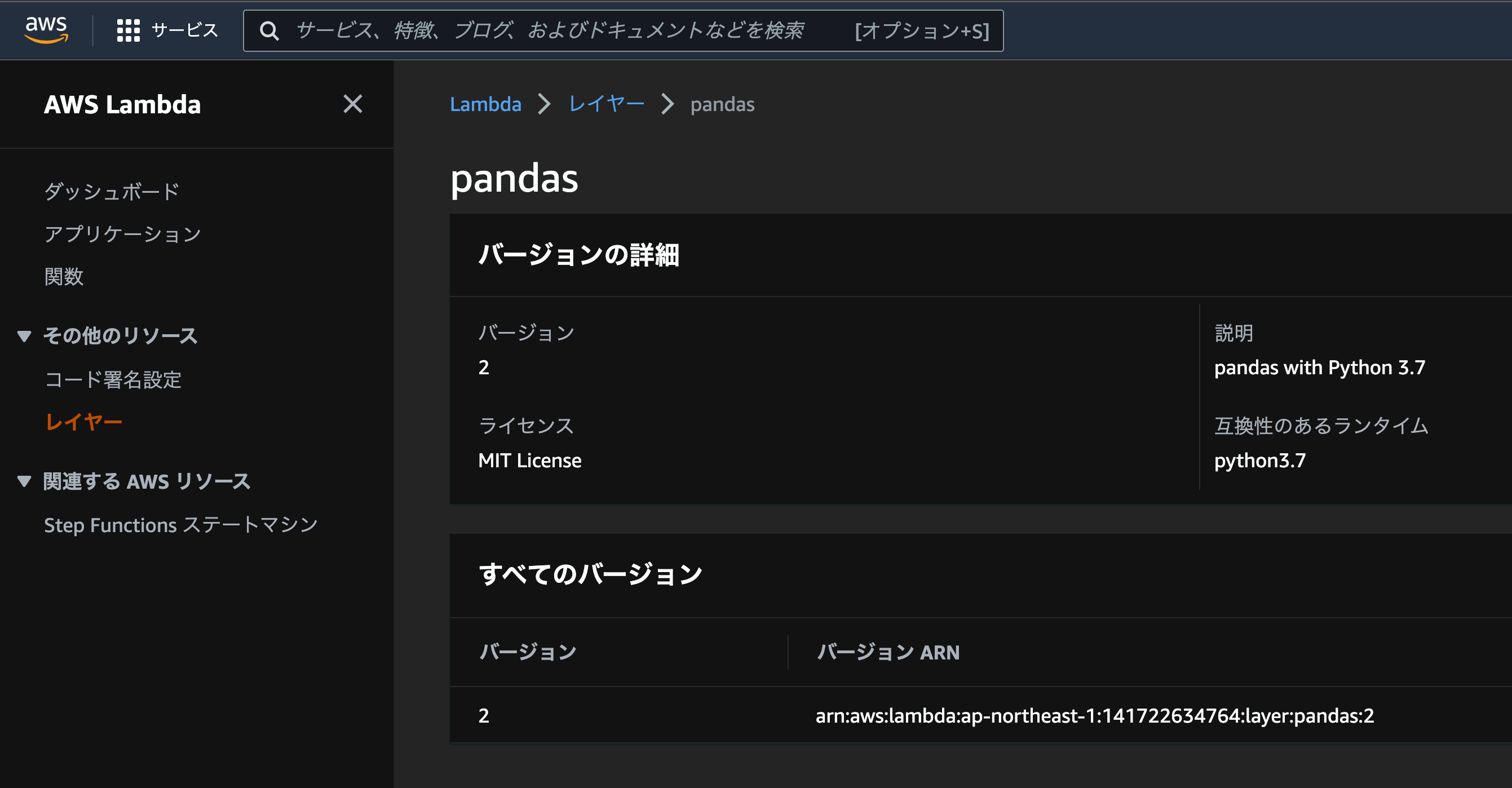
Lambdaは機械学習関連のパッケージはおろか、numpyやpandasも標準でインストールされていません。そのため、必要なライブラリのコードをLambda-Layersにアップロードする必要があります。
LambdaのOS(AmazonLinuxもしくはAmazonLinux2)に合わせる
では、pip install -t ./python pandas && zip -r pandas.zip pythonなどしてzipファイルをLambda-Layersにアップロードすればいいかというと、pandasなどのOS依存ライブラリはMacやWindowsのローカルで行ってもだめで、OSをLambdaと合わせる必要があります。
どのPythonバージョン(ランタイム)のOSがどれに対応するのかはこちらをご確認ください。
AmazonLinux(もしくはAmazonLinux2)のEC2を立ててpip install -t ./python pandas && zip -r pandas.zip pythonするという方法もあるかと思いますが、個人的にはDockerを使うのがいいと思います。(後述)
Lambda-Layersのファイルサイズ制限
上のようにアップロードしてみても、LightGBMのようなサイズの大きなパッケージはアップロード時に以下のようなエラーが出ます。
Unzipped size must be smaller than 262144000 bytes
公式の記事にもあるように、ファイルサイズはzip圧縮後50MB、zip圧縮前250MBである必要があるみたいです。通常のpip installだとLightGBMの依存ライブラリのインストールも同時に行われてしまうので、この原因もうまく排除する必要があります。
LightGBMのレイヤーアップロード
上記を踏まえて実際にLightGBMのレイヤーをアップロードしてみたいと思います。
今回はServerlessFrameworkとDockerをインストールしておいてください。ServerlessFrameworkについては、
npm install -g serverless
をすることでインストール可能です。(インストール後、ターミナルを再起動などすればslsコマンドが使えるようになっているはずです)
準備ができたら、適当なディレクトリに以下の3つのファイルを追加します。ちなみにこの記事ではLightGBMのみしか紹介しないので、pandasなど他のパッケージについては冒頭にものせたGithubリポジトリを参考にしていただければと思います。今回はランタイムPython3.7でレイヤーをつくります。
FROM lambci/lambda:build-python3.7
RUN pip install --target=/opt/python/ --no-deps lightgbm
#!/bin/bash -x
set -e
rm -rf layer
docker build -t lightgbm-lambda-layer .
CONTAINER=$(docker run -d lightgbm-lambda-layer false)
docker cp $CONTAINER:/opt layer
docker rm $CONTAINER
touch layer/.slsignore
cat > layer/.slsignore << EOF
**/*.a
**/*.la
share/**
include/**
bin/**
EOF
service: lightgbm-lambda-layer
provider:
name: aws
region: ap-northeast-1
runtime: python3.7
layers:
lightgbm:
path: layer
description: lightgbm with Python 3.7
compatibleRuntimes:
- python3.7
この状態で
sh build.sh && sls deploy
すれば、ラムダレイヤーがアップロードされたことを確認できると思います。
Lambdaのデプロイ
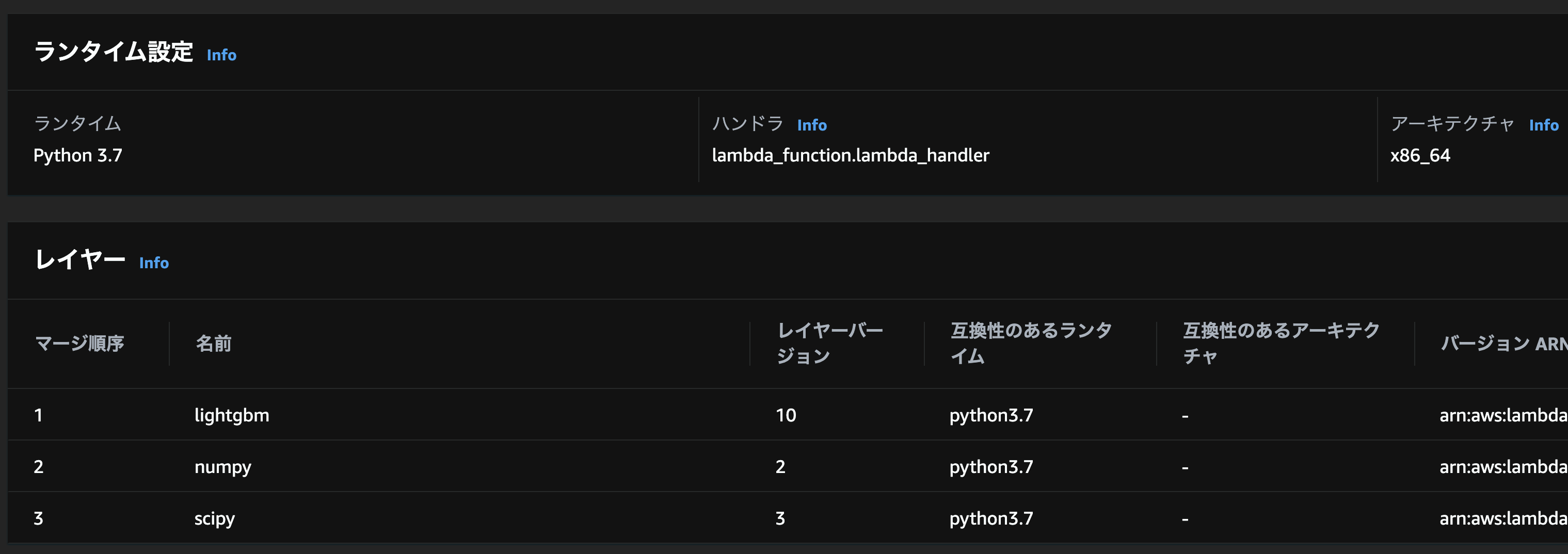
最後にLightGBMを用いたLambdaをデプロイしてみましょう。(上ではLightGBMのみのアップロードでしたが、ここでは依存パッケージのnumpyとscipyも必要です)
「Lambda -> 関数 -> 一から作成」より関数を作成し、以下のように
- ランタイム
- Python3.7
- レイヤー
- lightgbm
- numpy
- scipy
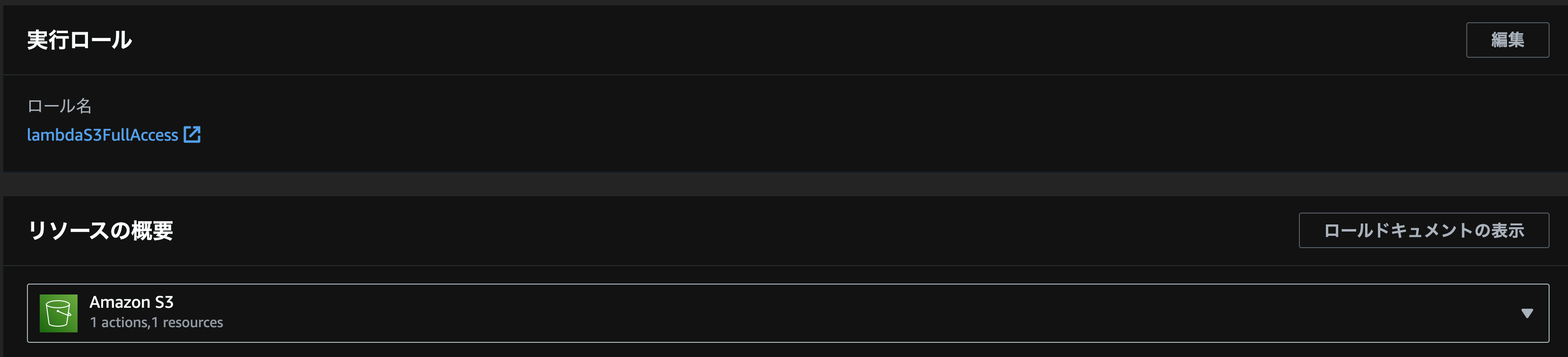
- 実行ロール
- S3のファイルの読みこり権限のあるIAMロール
を設定してください。
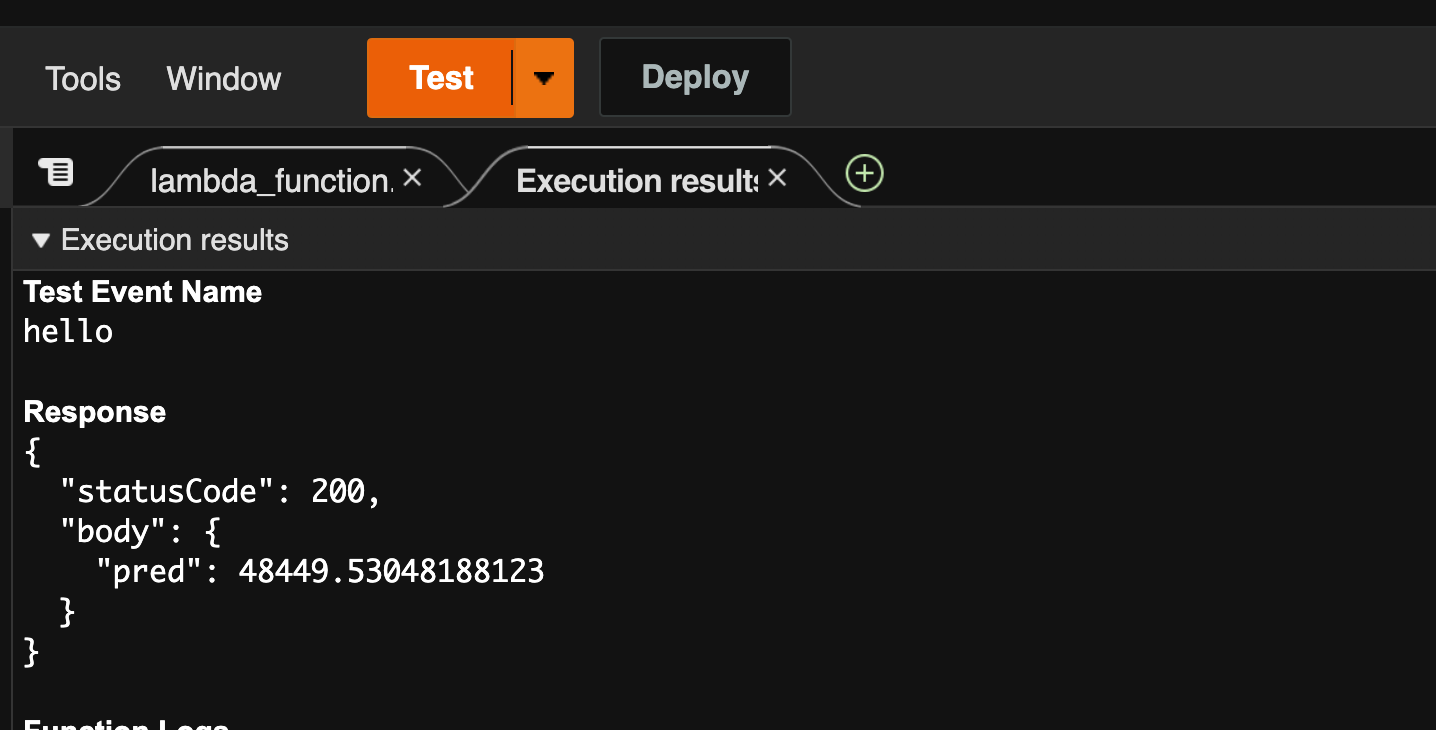
あとはlambda_function.pyをモデルの特徴量に合わせて以下のようにすれば、結果が返ってくるはずです。
import json
import pickle
import boto3
import subprocess
def lambda_handler(event, context):
# TODO implement
s3 = boto3.resource('s3')
model = pickle.loads(s3.Bucket("bucket_name").Object("object_path").get()['Body'].read())
feature_values = [[3.0, 1.0, 5.0, 7.0, 15.0]] # ここはモデルに合わせる
pred = model.predict(feature_values, num_iteration=model.best_iteration)
return {
'statusCode': 200,
'body': {
'pred': pred[0]
}
}
捕捉
上のlambda_handler関数の捕捉ですが、Lambdaではboto3は標準のパッケージとしてレイヤーを用いなくても使えます。また、関数に学習済のモデルのpickleファイルを含めるのは容量的に厳しいと思うので、S3の適当な場所に格納しておくと良いです。
S3上のpickleファイルは以下のコードで読み取れます。
import pickle
model = pickle.loads(s3.Bucket("bucket_name").Object("object_path").get()['Body'].read())