Python における分散処理を利用したプログラムの高速化の検討
前置き
- Python ではマルチスレッド、マルチプロセスを使用して分散処理ができる。
- しかし、Python (cpython) のマルチスレッド処理では、
(いくつかの例外を除いて) グローバルインタプリタロック (GIL) が発生するため、
実際には並列にタスクが実行されないことに注意する必要がある。 - マルチプロセスでは、GIL は発生しないが、プロセス間通信 (タスクの入出力データ) のオーバーヘッドを考慮する必要がある。
実験内容
- 次のサンプルタスクを一定数用意する。
- タスク1: ループ
- 特徴:
- グローバルインタプリタロックがかかる処理がタスクのほぼ全体を占める。
- タスクの入出力データサイズは小さい。
- 特徴:
- タスク2: ランダムバイト列の生成
- 特徴:
- グローバルインタプリタロックがかかる処理がタスクのほぼ全体を占める。
-
random.randbytes()の処理で GIL が発生 (1スレッドのみが実行可能)
-
- タスクの入出力データサイズは小さい。
- グローバルインタプリタロックがかかる処理がタスクのほぼ全体を占める。
- 特徴:
- タスク3: バイト列のハッシュ値計算
- 特徴:
- グローバルインタプリタロックがかかる処理は少ない。
-
hashlib.sha256()の処理では GIL は発生しない1 (複数スレッドで並行して実行可能)
-
- タスクの入出力データサイズは大きい。
- グローバルインタプリタロックがかかる処理は少ない。
- 特徴:
- タスク1: ループ
- 次の分散処理の手法を試行する。
- シングルスレッド (メインスレッドのみ使用して逐次処理)
- マルチスレッド (
ThreadPoolExecutorを使用して分散処理) - マルチプロセス (
ProcessPoolExecutorを使用して分散処理)
- すべてのタスクの実行が完了するまでの時間を計測し、どのタスクにどの分散処理の手法が適しているかを調べる。
- 処理時間は python の
timeitライブラリを使用して計測する。
- 処理時間は python の
環境
- OS: Ubuntu 20.04 LTS 64bit
- CPU: AMD Ryzen 7 3700X
- Python: 3.9.6
固定パラメータ
- タスク数: 64
- スレッド数/プロセス数: 16 (=CPU論理コア数)
処理時間の内訳の推定
- シングルスレッドの場合:
- 合計処理時間 = タスク処理時間
- マルチスレッドの場合:
- 合計処理時間 = タスク処理時間 + スレッド生成/同期
- マルチプロセスの場合:
- 合計処理時間 = タスク処理時間 + プロセス生成/同期 + 入出力データのプロセス間通信
タスク1: ループ
タスク
# Global Interpreter Lock: yes
# Input/Output data size: small
def loop(num_loops: int):
for _ in range(num_loops):
pass
処理時間 (グラフ)
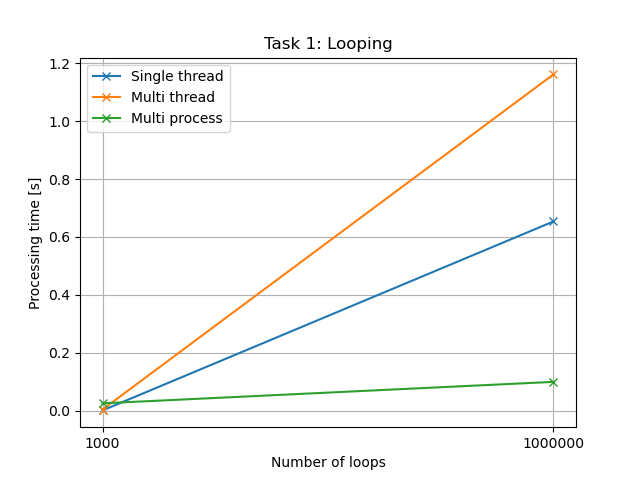
処理時間 (テキスト)
| ループ回数 | シングルスレッド | マルチスレッド | マルチプロセス |
|---|---|---|---|
| 1000 | 0.0006138367999938054 | 0.0037137518999998064 | 0.025069069400001354 |
| 1000000 | 0.6534605909999982 | 1.161619658199993 | 0.09922226029998456 |
タスク2: 乱数生成
タスク
# Global Interpreter Lock: yes
# Input/Output data size: small
def rand(length: int):
random.randbytes(length)
処理時間 (グラフ)
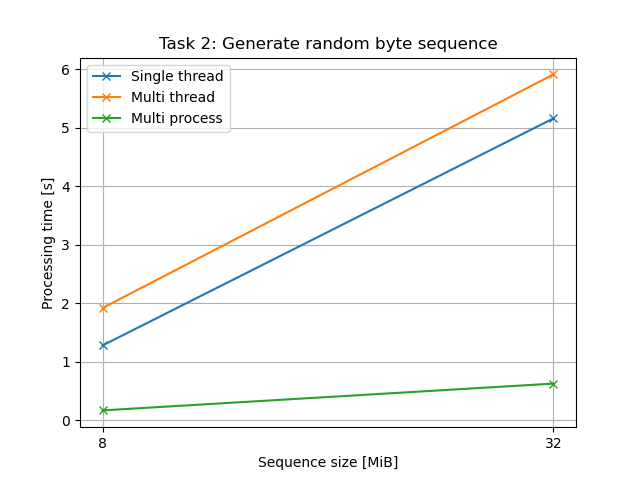
処理時間 (テキスト)
| 乱数列の長さ [MiB] | シングルスレッド | マルチスレッド | マルチプロセス |
|---|---|---|---|
| 8 | 1.2767773889999945 | 1.9168338630000108 | 0.16640982060000625 |
| 32 | 5.157601761899992 | 5.909415012499994 | 0.6245478162999916 |
タスク3: ハッシュ計算
タスク
# Global Interpreter Lock: no
# Input/Output data size: large
def hash(data: bytes):
hashlib.sha256(data).hexdigest()
処理時間 (グラフ)
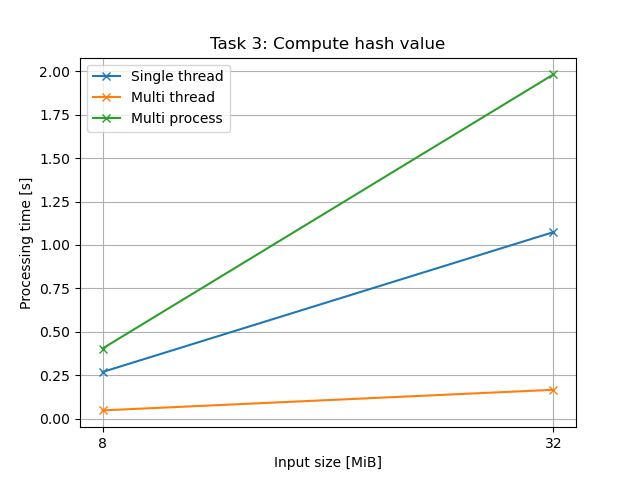
処理時間 (テキスト)
| データ長 [MiB] | シングルスレッド | マルチスレッド | マルチプロセス |
|---|---|---|---|
| 8 | 0.2683214218000103 | 0.04705624759999409 | 0.4036606014999961 |
| 32 | 1.0742257852999955 | 0.16579936089999592 | 1.98284267250001 |
まとめ
- シングルスレッドを選択するべきケース:
- スレッド生成やプロセス生成に比べて、タスク自体の処理時間が相対的に小さい
- マルチスレッドまたはマルチプロセスを選択するべきケース:
- CPUバウンドなタスク (CPU使用率が高いタスク)
- マルチスレッドを選択するべきケース:
- Global Interpreter Lock が発生しないタスク
- マルチプロセスを選択するべきケース:
- タスクの入力・出力サイズが小さい (=プロセス間通信量が小さい)
- 非同期IOを選択するべきケース:
- IOバウンドなタスク
- 例: Webリクエスト, ファイルの読み書き
- IOバウンドなタスク
ソースコード全体
import argparse
import hashlib
import random
import timeit
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
from typing import Callable
def loop(num_loops: int):
for _ in range(num_loops):
pass
def rand(length: int):
random.randbytes(length)
def hash(data: bytes):
hashlib.sha256(data).hexdigest()
def experiment(
*,
task: Callable,
args: list,
kwargs: dict,
num_tasks: int,
multi_threading: bool = False,
multi_processing: bool = False,
):
if multi_threading:
with ThreadPoolExecutor() as executor:
for _ in range(num_tasks):
executor.submit(task, *args, **kwargs)
elif multi_processing:
with ProcessPoolExecutor() as executor:
for _ in range(num_tasks):
executor.submit(task, *args, **kwargs)
else:
for _ in range(num_tasks):
task(*args, **kwargs)
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("-n", "--num_tasks", default=64)
parser.add_argument("-r", "--num_repeats", default=10)
parser.add_argument("-mt", "--multi_threading", action="store_true")
parser.add_argument("-mp", "--multi_processing", action="store_true")
subparsers = parser.add_subparsers()
subparser = subparsers.add_parser("loop")
subparser.set_defaults(task=loop)
subparser.add_argument("-l", "--num_loops", type=int, default=10 ** 8)
subparser = subparsers.add_parser("rand")
subparser.set_defaults(task=rand)
subparser.add_argument("-l", "--length", type=int, default=1024 * 1024 * 32)
subparser = subparsers.add_parser("hash")
subparser.set_defaults(task=hash)
subparser.add_argument("-l", "--length", type=int, default=1024 * 1024 * 32)
return parser.parse_args()
def main():
args = parse_args()
duration = timeit.timeit(
lambda: experiment(
task=args.task,
args=(
[args.num_loops]
if args.task == loop
else [args.length]
if args.task == rand
else [random.randbytes(args.length)]
if args.task == hash
else None
),
kwargs={},
num_tasks=args.num_tasks,
multi_threading=args.multi_threading,
multi_processing=args.multi_processing,
),
number=args.num_repeats,
)
duration /= args.num_repeats
print(f"{args}: {duration} s")
if __name__ == "__main__":
main()
実行ログ
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=False, num_loops=1000, task=<function loop at 0x7ffad98b2040>): 0.0006138367999938054 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=True, multi_processing=False, num_loops=1000, task=<function loop at 0x7ff36785c040>): 0.0037137518999998064 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=True, num_loops=1000, task=<function loop at 0x7f7683b39040>): 0.025069069400001354 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=False, num_loops=1000000, task=<function loop at 0x7ff54e13a040>): 0.6534605909999982 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=True, multi_processing=False, num_loops=1000000, task=<function loop at 0x7f1b0b5b5040>): 1.161619658199993 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=True, num_loops=1000000, task=<function loop at 0x7fb1fc056040>): 0.09922226029998456 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=False, length=8388608, task=<function rand at 0x7f8177c70820>): 1.2767773889999945 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=True, multi_processing=False, length=8388608, task=<function rand at 0x7fec22e09820>): 1.9168338630000108 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=True, length=8388608, task=<function rand at 0x7ff0639e2820>): 0.16640982060000625 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=False, length=33554432, task=<function rand at 0x7f6e774d7820>): 5.157601761899992 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=True, multi_processing=False, length=33554432, task=<function rand at 0x7f7cd4a00820>): 5.909415012499994 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=True, length=33554432, task=<function rand at 0x7f7231c0a820>): 0.6245478162999916 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=False, length=8388608, task=<function hash at 0x7fc1dc3d2160>): 0.2683214218000103 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=True, multi_processing=False, length=8388608, task=<function hash at 0x7fe0bbb20160>): 0.04705624759999409 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=True, length=8388608, task=<function hash at 0x7f1e459d8160>): 0.4036606014999961 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=False, length=33554432, task=<function hash at 0x7fd5fecfd160>): 1.0742257852999955 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=True, multi_processing=False, length=33554432, task=<function hash at 0x7fa188ba8160>): 0.16579936089999592 s
Namespace(num_tasks=64, num_repeats=10, multi_threading=False, multi_processing=True, length=33554432, task=<function hash at 0x7f7264c51160>): 1.98284267250001 s