0 にごく近い値の数値表現 "非正規化数" とその計算時間について
※本記事は, デノーマルフラッシュの速度改善効果 からきっかけを得て執筆しています.
浮動小数点数について
コンピュータで小数を扱うとき, 小さな値から大きな値まで幅広く扱えるよう, 浮動小数点方式がよく使われる.
小さな値では, 小さな "ずれ" が相対的に大きな誤差になってしまうため, 高い分解能で表現し,
大きな値では, 小さな "ずれ" は相対的に小さな誤差のため, おおまかに表現している.
浮動小数点数の丸め誤差を視覚化したグラフが分かりやすいので引用する.1

ある数値 $x$ があったとき, これをコンピュータで扱える形式に変換するには, 正規化という処理が行われる.
IEEE754 32bit 浮動小数点数 (binary32) における正規化は, $x$ を
$$x = (-1)^{sign} \cdot 2^{exponent - 127} \cdot (1.fraction)$$
と分解し, sign exponent fraction の順にメモリに格納する.

余談
指数部を -127 しているのは, 浮動小数点数同士を大小比較を容易にするためである.
→ メモリ上の 32bit を 32bit 符号あり整数として解釈しても, 大小比較ができる.
→(指数に関していえば) 負の指数, 1の指数, 正の指数 が 0-255 (正確には 1-254) にマッピングされるため.
非正規化数について
浮動小数点数の正規化の手順は述べたが, 小数にはこの正規化数として (諸々の事情により) 表せない数 というものもある.
0, 無限大, NaN(非数), そして非正規化数である.
非正規化数は, 正規化数として格納しようとしたとき, 指数部がアンダーフローしてしまう (0以下になってしまう) 数のことである.
具体的には $2^{-126}$ より小さい数である. (binary32 の場合)
※ $2^{-126}$ は多くの処理系で FLT_MIN というマクロで定義されている.
非正規化数は, 指数部からアンダーフローした部分(...という表現が正しいかは自信ない)を 23bit 分の固定小数点数として表現する.
例
例えば, $2^{-127}$ を考えてみる.
- (符号部は正なので
0b0) - (指数部は
0b00000000)- $2^{-126}$ が表されていると考える
- 残りの部分
$2^{-127}=2^{-126} \cdot 2^{-1}$ となるため, アンダーフローした部分は $2^{-1}$
つまり,0b10000000000000000000000
補足
$2^{-126}$, $2^{-127}$ の数値表現を確認するプログラム(python)を補足として示す.
import numpy as np
def main():
x = np.array(pow(2.0, -126), dtype=np.float32)
y = np.array(pow(2.0, -127), dtype=np.float32)
print(f"2^-126: {x:e} 0b{x.view(np.int32):032b}")
print(f"2^-127: {y:e} 0b{y.view(np.int32):032b}")
if __name__ == "__main__":
main()
# 2^-126: 1.175494e-38 0b00000000100000000000000000000000
# 2^-127: 5.877472e-39 0b00000000010000000000000000000000
非正規化数の計算速度と Flush-to-Zero について
これまで説明したように, 正規化数と非正規化数では計算アルゴリズムが異なる.
基本的に正規化数を扱うことを念頭に演算回路が設計されているため, 非正規化数の計算速度は正規化数のそれより遅くなることが予想される.
非正規化数により計算速度が低下する問題を回避する方法として, 非正規化数を強制的に 0 として扱う機能 (ゼロフラッシュ) が, x86_64 や ARM CPU に実装されている.
x86_64 (amd64)
- x86_64 (amd64) では浮動小数点演算は SSE レジスタで行われる.
- MXCSRレジスタ (Mmx Sse Control Status Register ?) で浮動小数点演算を制御できる.
- MXCSRレジスタの FZ, DAZフラグがそれぞれ 非正規化数の出力, 入力値のゼロフラッシュを制御する.
- つまり,
- MXCSRレジスタ>FZフラグが1の場合, 演算結果が非正規化数になったとき, 代わりに 0 を返す.
- MXCSRレジスタ>DAZフラグが1の場合, 演算の入力値が非正規化数の場合, 代わりに 0 として入力する.
(MXCSRレジスタの詳細は 3 などを参考にしてください.)
補足
SSE が実装されていない古い 32bit CPU では x87 という別のレガシーな命令セットが使われる.
arm64
- arm64 では浮動小数点演算は VFP レジスタで行われる.
- FPCRレジスタ (Floating Point Contorl Register) で浮動小数点演算を制御できる.
- x86_64 の MXCSRレジスタとは異なり, FZフラグが出力値と入力値の両方に作用する.
(FPCRレジスタの詳細は 4 などを参考にしてください.)
実験: 非正規化数の計算速度の計測
概要
- 新旧様々な CPU を使って, ①正規化数, ②非正規化数, ③NaN の計算をする.
- 具体的な計算内容は,
a / 1.08 - a / 1.07 + a / 1.06 - a / 1.05 + a / 1.04 - a / 1.03 + a / 1.02 - a / 1.01-
aは適当な長さ(n=1048576) のベクトル. -
aの各要素は,- ①正規化数の計算: $[0,1]$ の範囲の一様乱数
- ②非正規化数の計算: $[\rm{FLT_MIN} \div 10, \rm{FLT_MIN}]$ の範囲の一様乱数
- ③NaNの計算: すべて NaN
-
- 同じ計算を適当な回数(r=1000) 繰り返して, 計算時間の平均をとる.
結果
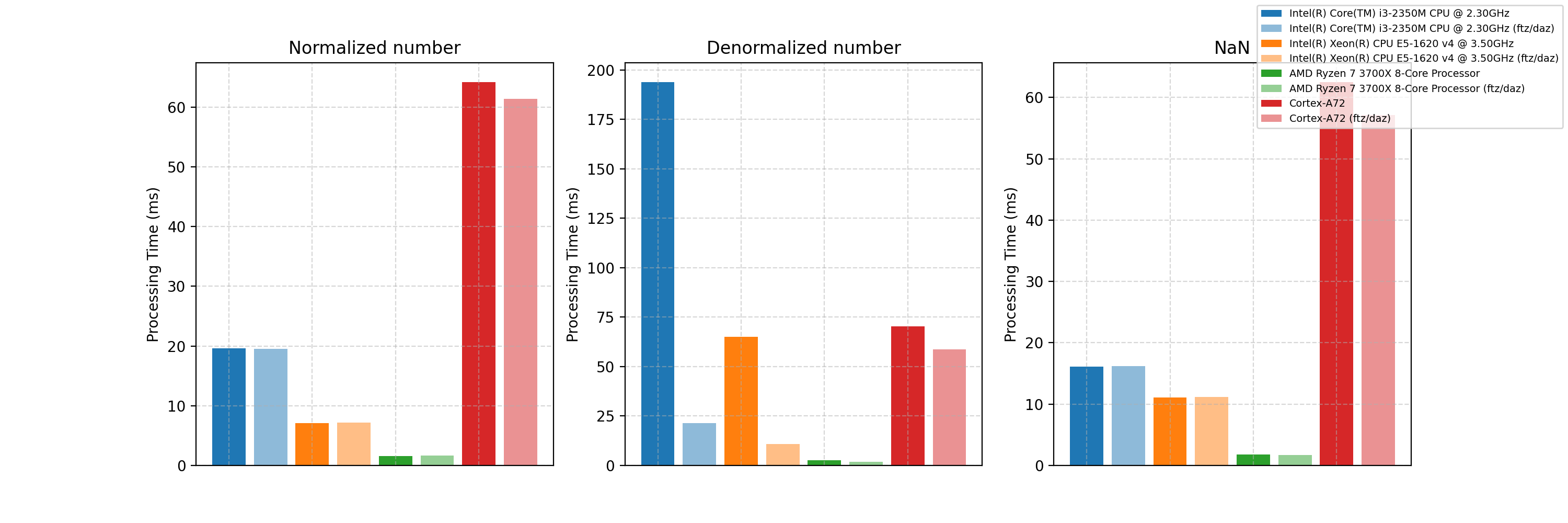
- 縦軸: 計算時間 (単位: ms)
- 左から ①正規化数の計算 ②非正規化数の計算 ③NaNの計算 の実験結果
- "Cortex-A72" は Raspberry Pi 4 Model B
まとめ
- 古いCPUでは, 非正規化数の計算が正規化数のそれに比べ非常に遅い. 新しいCPUでは, そこまで顕著な差はない.
- 古いCPUでは, Flush-to-Zero を有効にすると速度が大きく改善.
- x86_64(amd64) CPU では, Flush-to-Zero の効果は非正規化数の計算に効果あり, 正規化数, NaN の計算には効果なし.
- Cortex-A72 CPU では, Flush-to-Zero の効果は正規化数, 非正規化数, NaN すべての計算に効果あり.
プログラム 実行ログ
(実験結果の正確な数値は以下を参照してください.)
{
"Intel(R) Core(TM) i3-2350M CPU @ 2.30GHz": {
"false": {
"task_normal.time.avg": 19.573552441019274,
"task_normal.result": 0.0075087398290634155,
"task_denormal.time.avg": 193.99709720296053,
"task_denormal.result": -1.3873975835587149e-40,
"task_nan.time.avg": 16.156955018994267,
"task_nan.result": NaN
},
"true": {
"task_normal.time.avg": 19.512690744018983,
"task_normal.result": 0.0075087398290634155,
"task_denormal.time.avg": 21.48852484600684,
"task_denormal.result": 0.0,
"task_nan.time.avg": 16.201267520002148,
"task_nan.result": NaN
}
},
"Intel(R) Xeon(R) CPU E5-1620 v4 @ 3.50GHz": {
"false": {
"task_normal.time.avg": 7.105356518006374,
"task_normal.result": 0.0075087398290634155,
"task_denormal.time.avg": 65.08354406199715,
"task_denormal.result": -1.3873975835587149e-40,
"task_nan.time.avg": 11.092436301997623,
"task_nan.result": NaN
},
"true": {
"task_normal.time.avg": 7.158118054998795,
"task_normal.result": 0.0075087398290634155,
"task_denormal.time.avg": 10.72426418499981,
"task_denormal.result": 0.0,
"task_nan.time.avg": 11.142377747001774,
"task_nan.result": NaN
}
},
"AMD Ryzen 7 3700X 8-Core Processor": {
"false": {
"task_normal.time.avg": 1.5648097269986465,
"task_normal.result": 0.0075087398290634155,
"task_denormal.time.avg": 2.7105425170302624,
"task_denormal.result": -1.3873975835587149e-40,
"task_nan.time.avg": 1.7755554140039749,
"task_nan.result": NaN
},
"true": {
"task_normal.time.avg": 1.6963652360027481,
"task_normal.result": 0.0075087398290634155,
"task_denormal.time.avg": 1.81358112397902,
"task_denormal.result": 0.0,
"task_nan.time.avg": 1.6937553630596085,
"task_nan.result": NaN
}
},
"Cortex-A72": {
"false": {
"task_normal.time.avg": 64.20883447200686,
"task_normal.result": 0.0075087398290634155,
"task_denormal.time.avg": 70.41777742399516,
"task_denormal.result": -1.3873975835587149e-40,
"task_nan.time.avg": 62.53883298499659,
"task_nan.result": NaN
},
"true": {
"task_normal.time.avg": 61.41870089301574,
"task_normal.result": 0.0075087398290634155,
"task_denormal.time.avg": 58.73722034498678,
"task_denormal.result": 0.0,
"task_nan.time.avg": 57.10878042999866,
"task_nan.result": NaN
}
}
}
ソースファイル
https://github.com/s059ff/denormalized-number-performance-experiment に公開.
-
Deest, Gaël. (2017). Implementation Trade-Offs for FGPA accelerators. https://www.researchgate.net/publication/321993979_Implementation_Trade-Offs_for_FGPA_accelerators ↩
-
https://help.totalview.io/previous_releases/2021.1/HTML/index.html#page/TotalView/Intelx86MXSCRRegister.html# ↩
-
https://help.totalview.io/previous_releases/2021.1/HTML/index.html#page/TotalView/PowerFPSCRRegister_2.html# ↩