はじめに
千葉大学/Nospareの米倉です.今回は感染症の数理モデルで良く使われる,SIRモデルの解説とそのベイズ推定について紹介します.
SIRモデルとは
西浦(2021)に基づきSIRモデルを解説します.ここでは個人の異質性は考慮せず,全員等しく感染しやすく,回復しやすいことを暗に仮定します.
SIRモデルとはコンパートメントモデルと呼ばれるモデルの一種で,感染症が流行している母集団(人口)をいくつかのコンパートメント(区間)に分類して分析をするモデルです.
具体的にはSIRモデルは母集団を
- Susceptible(感受性人口)→未感染かつ免疫を獲得していない人口.
- Infected(感染性人口)→感染症に感染した人口.
- Recovered(回復者人口)→免疫を獲得した人口or隔離された人口.
の3つの状態に分割します.この上で以下のような仮定を置きます.
- 感染したらすぐにSからIに移行する.
- 人口の中でIのみが二次感染を引き起こす.
- 感染期間は指数分布に従う.
- 感染性期間の後にIはRに移行する.
- 回復後は免疫を獲得し,再感染しない(RからSやIに移行しない).
これらの仮定の下で,次の様にSとIとRのダイナミクスを記述します.
新規感染はSとIの接触によって起こりますが,この時「単位時間当たりのSとIの接触率」を$\beta$とします.つまり単位時間あたり,SからIには$\beta$SIに比例して人口が移動する,感染がおこる頻度が$\beta$SIであるとします.
一方で,IからRには$\gamma$に比例して人口が移動するとします.つまり,単位時間当たり$\gamma$に比例して感染者は回復します.
以上をまとめると,次のような常微分方程式
$$\frac{dS(t)}{dt}=-\beta S(t)I(t)\
$$
$$\frac{dI(t)}{dt}=\beta S(t)I(t)-\gamma I(t)
$$
$$\frac{dR(t)}{dt}= \gamma I(t)
$$
を得て,これをSIRモデルと言います.3つの式の和を取れば,
$$
\frac{d}{dt}(I(t)+S(t)+R(t))=0
$$
であることに注意してください.
SIRモデルの挙動と再生産数
モデルのパラメーター$(\beta,\gamma)$の値でSIRモデルの挙動は異なります.$I(t)$に関する式を変形すると,
\begin{align}
\frac{dI(t)}{dt}&=\beta S(t)I(t)-\gamma I(t)\\
&= I(t)(\beta S(t)-\gamma)
\end{align}
となります.定義より$I(t)$は非負なので,$(\beta S(t)-\gamma)$が正の値,つまり$$\frac{\beta S(t)}{\gamma}>1$$ならば$I(t)$は増加,つまり感染者数は増加します.
N=1を時間を通じて一定の標準化して人口($N=S(t)+I(t)+R(t)$)とすると,$t=0$の時$S(0)=N=1$,つまり感染初期においては全員が感受性人口と仮定できるので,$\frac{\beta S(t)}{\gamma}$は$\frac{\beta}{\gamma}$となり,これを「基本再生産数,$R_0$」と呼びます.
$R_{0}$が1ならば1人の感染者は1人の感染者,2ならば1人の感染者は2人の感染者を生むので,$R_0<1$ならば$I(t)$は0に収束,つまり感染が収束することとなります.逆に$R_0\geq 1$ならば感染者数は増加していくことになります.
$R_{0}$は「ほかに感染者がおらずワクチン接種やロックダウン等の政策介入がされていない時」の仮想的な値です.一方で対策時の再生産数を「実行再生産数,$R_t$」といい,これは先ほどの$\frac{\beta S(t)}{\gamma}$に他なりません.
この様にSIRモデルを通して$R_0$や$R_t$をモニタリングすることで,感染症の流行具合を把握することがある程度可能になります.
SIRモデルのパラメーターのベイズ推定
まずデータとして,Rのライブラリー"outbreaks"にある1978年にイギリスのボーディングスクールで発生した,H1N1型のインフルエンザのパンデミックについてのデータ,influenza_england_1978_schoolを用います.
このデータは1/22から2/4にかけて,763名の学生の内,512名が感染したデータです.中身は日付,その日ベッドで静養していた学生の数,その日に回復した学生の数です.次の図は横軸に日付.よく軸にその日にベッドで静養していた学生の数をプロットしたものです.
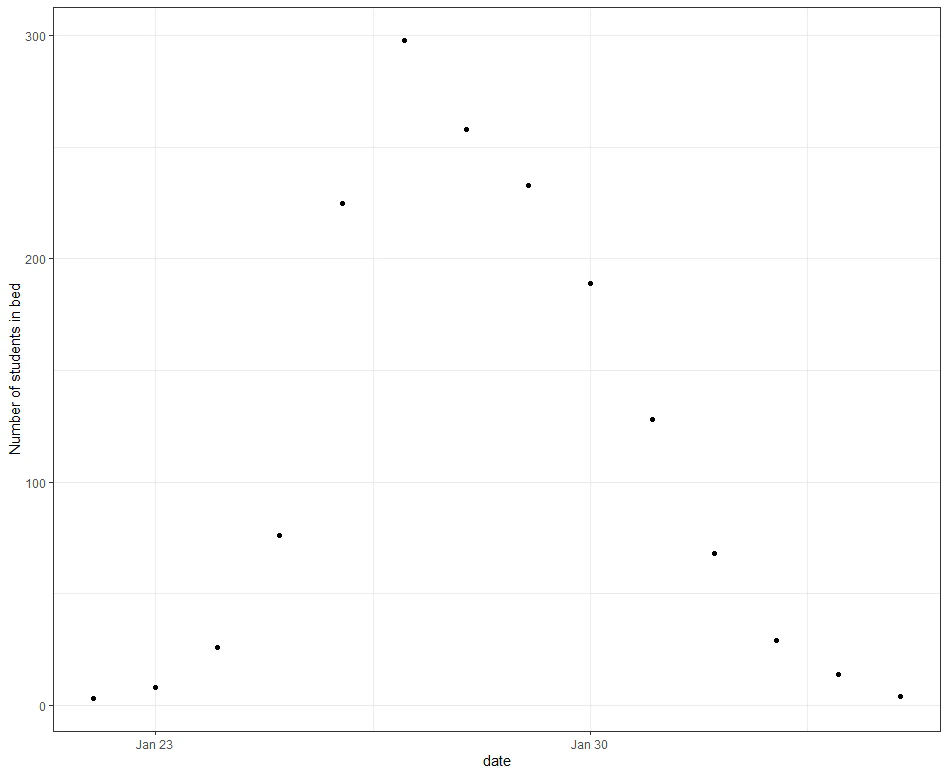
このセクションではSIRのパラメーター$(\beta,\gamma)$をデータから統計的推定する方法を解説します.統計的推定を行うのでどこかに確率項を加えてモデリングする必要がありますが,今回はGrinsztajn et al.(2021)に基づいてベイズ推定を行う方法を解説します.
観測値を$y$,パラメーターを$\theta$とし,事後分布$p(\theta\mid y)\propto p(y\mid \theta)p(\theta)$からサンプリングするのが目的です.ここで$p(\theta)$は事前分布,$ p(y\mid \theta)$は統計モデル(尤度関数)です.
パラメーター,$S(t),I(t),R(t)$の初期値を適当に決めると,常微分方程式であるSIRは何かしらの手法(例えばルンゲ=クッタ法)を用いて,数値的に解くことが出来ます.ここでそのようにして得た$I(t)$を$I(t)^M$と表記することにします.ここではこの$I(t)^M$と実際に観測された$I(t)$である$I(t)^O$=その日ベッドで静養していた学生の数を統計モデル$ p(y\mid \theta)$を用いてリンクすることにします.
特に今回は$ p(y\mid \theta)$として,以下の負の二項分布を採用します.$$I(t)^O\sim NegBin(I(t)^M,\phi),$$
ここで$\phi$は負の二項分布のdispersionパラメーターです.
よってパラメーター$\theta$は$\theta=(\beta,\gamma,\phi)$となります.事前分布として$\beta$には正の値で制限した平均2,分散1の正規分布を,$\gamma$には正の値で制限した平均0.4,分散0.5の正規分布を,$\phi$の逆数にパラメーターが5の指数分布を仮定します.
推定結果を用いると$R_0$の事後分布$p(R_0\mid y)$等も推定することができます.
Stanによる実装
先ずはSIRモデル,つまり常分方程式部分をStanで実装します.常分方程式は一般的に関数$f$をもちいて$$\frac{dy(t)}{dt}=f(y(t))$$と表現できます.SIRモデルの場合は,$y(t)=(S(t),I(t),R(t))$です.Stanではまずfuncionsブロックに
real[] f(real time, real[] state, real[] theta, real[] x_r, int[] x_i)
と一般的に常分方程式の中身を指定します.ここでfは関数名,timeは時間,stateはyの各構成要素,thetaはfを計算するときに用いるパラメーター,x_rはfを評価する実数値のデータ, x_iはfを評価する整数値のデータです.SIRモデルの場合は,
functions {
real[] sir(real t, real[] y, real[] theta,
real[] x_r, int[] x_i) {
real S = y[1];
real I = y[2];
real R = y[3];
real N = x_i[1];
real beta = theta[1];
real gamma = theta[2];
real dS_dt = -beta * I * S / N;
real dI_dt = beta * I * S / N - gamma * I;
real dR_dt = gamma * I;
return {dS_dt, dI_dt, dR_dt};
}
}
とSIRモデルを記述することが出来ます.モデルを記述したら,SIRモデルを4次のルンゲ=クッタ法を用いて数値的に解きます.StanではSIRの場合
y = integrate_ode_rk45(sir, y0, t0, ts, theta, x_r, x_i);
でSIRモデルを4次のルンゲ=クッタ法を用いて解くことが出来ます.ここでsirはsirという常分方程式を解くという指定,y0は初期値,t0は離散化するさいの時刻の初期値,tsは解を評価する時間(どれくらいの細かさで常分方程式を離散化するか),他の変数は上記と同じです.
次にdata部分にデータ関連を記述します.
data {
int<lower=1> n_days;
real y0[3];
real t0;
real ts[n_days];
int N;
int cases[n_days];
}
次に推定速度をあげるためにtransformed dataでデータを変換します.x_rは今回のSIRの推定では使わない,x_iは人口サイズNであるなどを記述しておきます.
real x_r[0];
int x_i[1] = { N };
}
次にパラメーター$\theta=(\beta,\gamma,\phi)$をparameterブロックで宣言します.
parameters {
real<lower=0> gamma;
real<lower=0> beta;
real<lower=0> phi_inv;
}
ここでは$\phi$ではなく$\frac{1}{\phi}$,つまり過分散パラメーターについて事前分布を与えていたことに注意してください.
transformed parametersブロックで,次のようにパラメーターを変換します.
transformed parameters{
real y[n_days, 3];
real phi = 1. / phi_inv;
{
real theta[2];
theta[1] = beta;
theta[2] = gamma;
y = integrate_ode_rk45(sir, y0, t0, ts, theta, x_r, x_i);
}
}
}
modelブロックで前述通りに事前分布や統計モデルを指定します.parameterブロックで各パラメーターにrealを指定していることに注意してください.
model {
#事前分布
beta ~ normal(2, 1);
gamma ~ normal(0.4, 0.5);
phi_inv ~ exponential(5);
#統計モデル
#col(matrix x, int n) - 行列xの第nベクトル.ここでは2列目にIに関するベクトルがあるとしている.
cases ~ neg_binomial_2(col(to_matrix(y), 2), phi);
}
最後に$R_0$や平均治癒時間$\frac{1}{\gamma}$,感染者数の予測等の計算をgenerated quantitiesブロックに書きます.
generated quantities {
real R0 = beta / gamma;
real recovery_time = 1 / gamma;
real pred_cases[n_days];
pred_cases = neg_binomial_2_rng(col(to_matrix(y), 2) + 1e-5, phi);
}
}
これらをまとめると次のStanのコード(sir_negbin.stanという名前で保存しました)が完成します.
functions {
real[] sir(real t, real[] y, real[] theta,
real[] x_r, int[] x_i) {
real S = y[1];
real I = y[2];
real R = y[3];
real N = x_i[1];
real beta = theta[1];
real gamma = theta[2];
real dS_dt = -beta * I * S / N;
real dI_dt = beta * I * S / N - gamma * I;
real dR_dt = gamma * I;
return {dS_dt, dI_dt, dR_dt};
}
}
data {
int<lower=1> n_days;
real y0[3];
real t0;
real ts[n_days];
int N;
int cases[n_days];
}
transformed data {
real x_r[0];
int x_i[1] = { N };
}
parameters {
real<lower=0> gamma;
real<lower=0> beta;
real<lower=0> phi_inv;
}
transformed parameters{
real y[n_days, 3];
real phi = 1. / phi_inv;
{
real theta[2];
theta[1] = beta;
theta[2] = gamma;
y = integrate_ode_rk45(sir, y0, t0, ts, theta, x_r, x_i);
}
}
model {
beta ~ normal(2, 1);
gamma ~ normal(0.4, 0.5);
phi_inv ~ exponential(5);
cases ~ neg_binomial_2(col(to_matrix(y), 2), phi);
}
generated quantities {
real R0 = beta / gamma;
real recovery_time = 1 / gamma;
real pred_cases[n_days];
pred_cases = neg_binomial_2_rng(col(to_matrix(y), 2), phi);}
推定結果
以上のStanファイルを以下の様にRで実行しました.
library(rstan)
library(gridExtra)
cases = influenza_england_1978_school$in_bed # 静養中の学生の数(感染者数の観測値)
# 学生の数(人口)
N = 763;
# 時間
n_days = length(cases) #全期間
t = seq(0, n_days, by = 1) #タイムステップ
t0 = 0
t = t[-1]
#初期値の設定
i0 = 1 #初期に一人感染者が人口内に出現
s0 = N - i0
r0 = 0
y0 = c(S = s0, I = i0, R = r0)
#Stanにデータを渡す
data_sir = list(n_days = n_days, y0 = y0, t0 = t0, ts = t, N = N, cases = cases)
# MCMCのイタレーションの数
niter = 10000
#コンパイル(hogehogeはスタンファイルがあるディレクトリ)
model = stan_model("hogehoge/sir_negbin.stan")
#4回の独立のチェインを求める.バーンインはそれぞれ5000
fit_sir_negbin = sampling(model,
data = data_sir,
iter = niter,
chains = 4,
seed = 0)
pars=c('beta', 'gamma', "R0", "recovery_time")
#結果のプリント
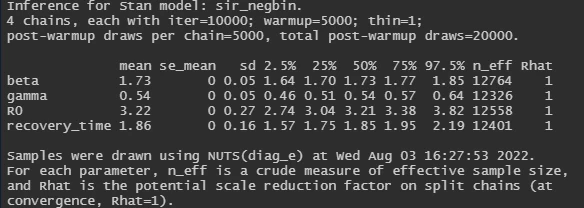
print(fit_sir_negbin, pars = pars)
#推定結果の事後密度
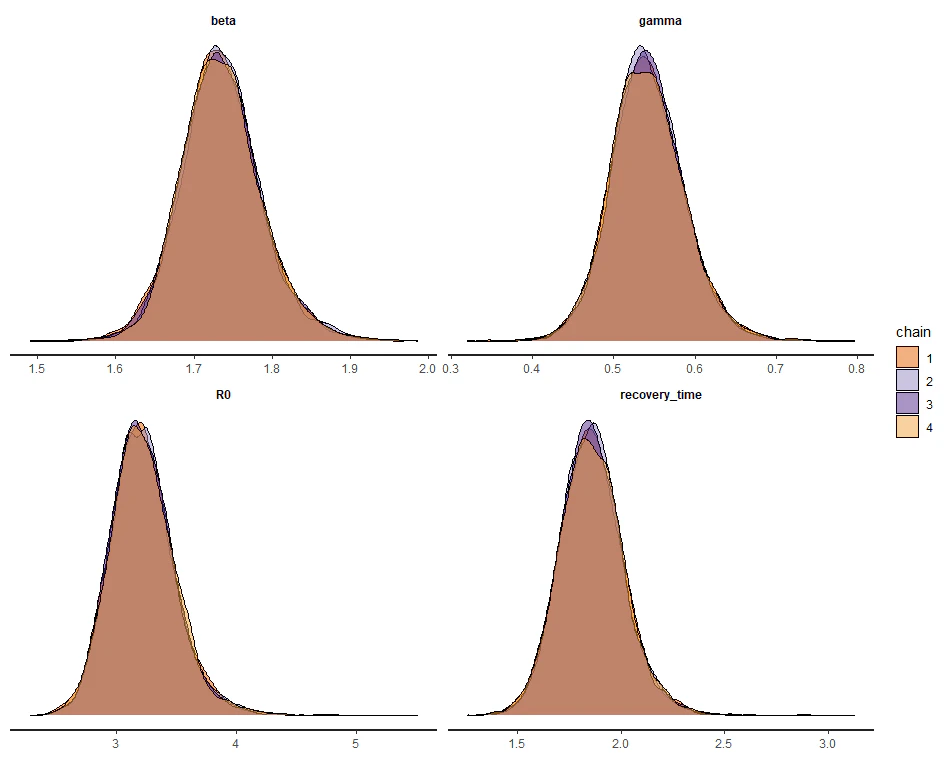
stan_dens(fit_sir_negbin, pars = pars, separate_chains = TRUE)
以下が求めた事後分布などです.
4回のチェーンの周辺事後分布は同じような形状をしており,Rhatをみても収束していることが分かります.
その他発展的トピック
この記事では一番単純なSIRモデルを解説しました.Rの後にSに一定数戻るSIRSモデルや,潜伏期間の患者(E= Exposed)を考慮した,SEIRモデル等も提案されています.詳しくはこのサイトをご覧ください.
他に例えDureau et al, (2012)では,パラメーターが時間と共に変化するという仮定を置いて,確率微分方程式タイプのSIRモデルを推定しています.
おわりに
株式会社Nospareでは統計学の様々な分野を専門とする研究者が所属しております.統計アドバイザリーやビジネスデータの分析につきましては株式会社Nospare までお問い合わせください.

参考文献
・西浦「感染症疫学のためのデータ分析入門」(2021)
・Grinsztajn et al. (2021) "Bayesian workflow for disease transmission modeling in Stan"