はじめに
千葉大学/Nospareの米倉です.今回はGoogle colaboratory(Colab)上でのStanの使い方を解説しようと思います.ほぼ備忘録ですので,細かい誤りや非効率な部分が多分含まれます.ご了承下さい.またStanの詳しい使い方の説明ではありません.
なんでColab上でStanを動かしたいか
Stanとは,ベイズ推定を簡単に行うための確率言語のことで,多くの方が使用していると思います.R上で動かすものをRstan,Python上で動かすものをPystanと特にいいます.Stan自体は非常に便利なのですが,使えるようにするまでのセットアップが結構めんどくさいです.例えばC++のコンパイラーをインストールしたりしなくてはいけません.またWindowsを用いていると,例えばRがonedriveを何故か参照して,日本語名ファイルを認識できないため,エラーが発生します.人によっては些細な問題点だと思いますが,教員からすると生徒のPC環境一個一個を把握している暇はないので,こういった問題は避けたいのが本音です.
素晴らしいことに,ColabにはデフォルトでPystanが使えるようになっており,自分で環境設定をする必要がありません.有難うございます.Google.
Stanファイルの作成
まずは何らかのエディターでstanファイルを作成します.残念ながらColab上でStanファイルそのものを作成するのは適していないので,僕はRstudioを用いて作成しています.ここがちょっと二度手間と言うか残念な点ではあり,Rstanを自分で設定できる人はColabを使う必要がないと思う点です.今回は以下の様な単回帰モデル+無情報事前分布を考え,reg.stanとして保存しました.
data{
int N;
real Y[N];
real X[N];
}
parameters{
real beta_0;
real beta_1;
real<lower=0> sigma;
}
model{
for (i in 1:N){
Y[i] ~ normal(beta_0+beta_1*X[i],sigma);
}
}
必要なライブラリーのインポート
まずはPystanや,作図・データフレーム用のライブラリーをColab上でインポートします.
# pystanのインストール
import pystan
# 作図用ライブラリ
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
# 結果の可視化用ライブラリ
!pip install arviz
import arviz
# データフレーム用のライブラリ
import pandas as pd
これで準備は完了です.arvizはMCMCのアウトプットを可視化する際に必要となるライブラリーですが,これは現状pipしないといけないようです.
データとstanファイルのアップロード
次にデータとStanファイルをアップロードします.データは松浦さんのギットハブより,data-salary.txtというデータを取得しました.アップロードできていると,以下の画像のようになると思います.
データの可視化
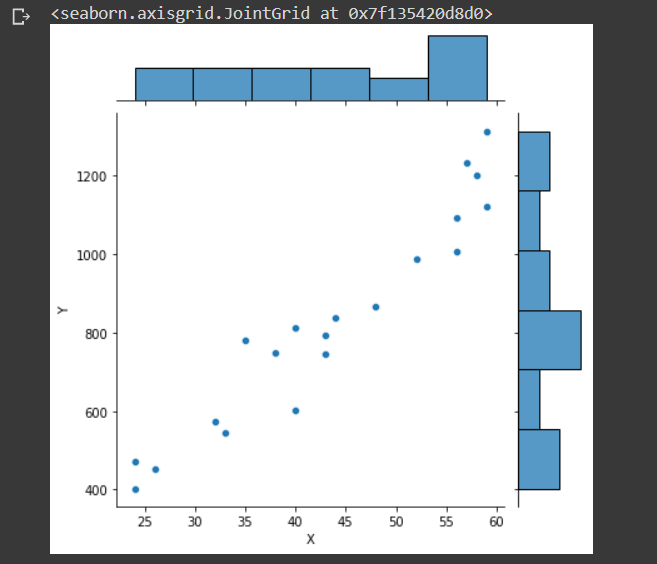
ここでは上手くデータがセット出来てるか否かを確認するために,seabornのjointplotで,ヒストグラム付きの散布図をプロットしています.
d = pd.read_csv('data-salary.txt')
df = pd.DataFrame(d)
x = df.iloc[:, 0] #年齢
y = df.iloc[:, 1] #年収
n = len(x) #サンプルサイズの取得
# サンプルデータの可視化
sns.jointplot(x = x, y = y)
Stanファイルのコンパイル
次にreg.stanという名前のStanファイルをコンパイルします.ここが一番時間がかかり,2-3分ほどかかるときもあります.
sm = pystan.StanModel(file = '/content/reg.stan')
正常にコンパイルできると,

みたいなメッセージが出るはずです.
推定の実行
次にいよいよベイズ推定を行います.シードの指定,MCMCの回数,バーンインの期間,推定回数を行うかなどを指定し,dictionary形式でStanにデータを渡します.
fit = sm.sampling(
data = dict(
N = n,
Y = y,
X = x
),
seed = 1234,
iter = 5000,
warmup = 1000,
chains = 4)
推定自体はこの例ですと2秒ほどで終わり,あまり時間はかかりません.
MCMCのアウトプットの可視化
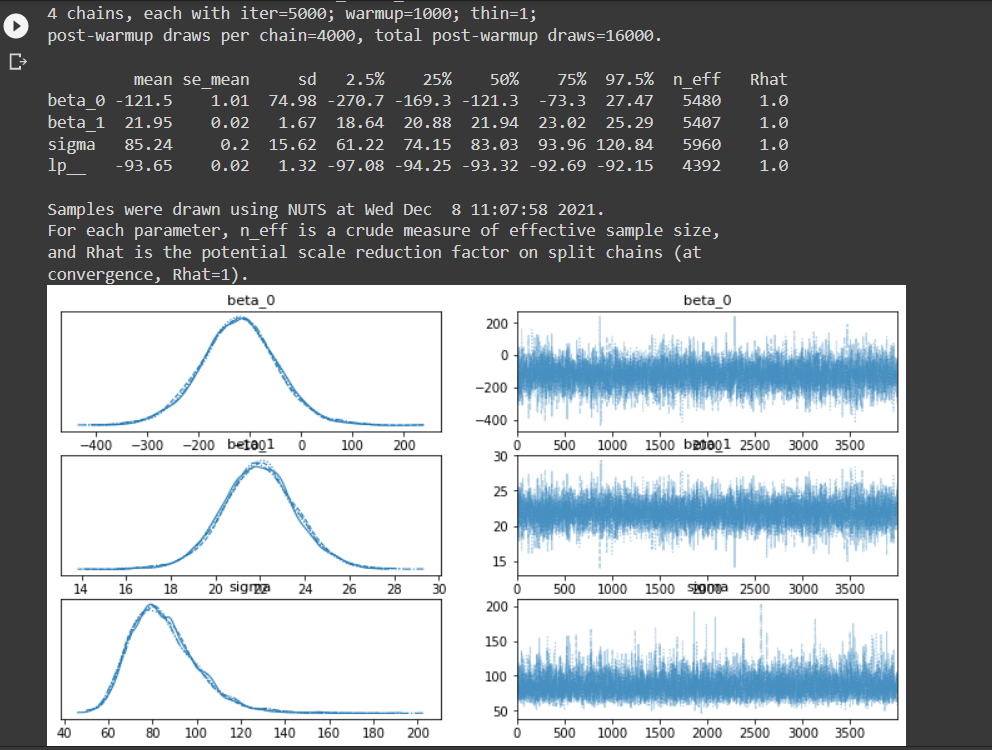
arviz等を使ってMCMCの結果を可視化します.arviz(fit)で推定したパラメータの事後分布とMCMCのトレースプロットが,chainsで指定した回数分だけプロットされます.またprint(fit)で要約統計量がアウトプットされます
arviz.plot_trace(fit)
print(fit)
おわりに
株式会社Nospareでは統計学の様々な分野を専門とする研究者が所属しております.統計アドバイザリーやビジネスデータの分析につきましては株式会社Nospare までお問い合わせください.
