統計データを過去2年分再集計(大きめデータ対象に多数のクエリを実行するのでI/O負荷=High)していたらCloudWatchアラームが届いて「あー、バーストバランス。痛い目にあったなぁ」と懐かしくなったので記事化。
ポイント
- RDSのストレージに汎用SSDを選択して、サイズが小さいボリュームサイズ(例えば100GBとか)で運用しているRDSはバーストバランスが枯渇(0%)すると突然、激重になる。
- 普段はIOPS性能が3,000 IOPSまでバーストされているので気づかない
- 100GBだと300 IOPSまで性能が落ちる。
- バーストバランス枯渇するのはある日突然。データ増とアクセス増で徐々に忍び寄るのが怖い。
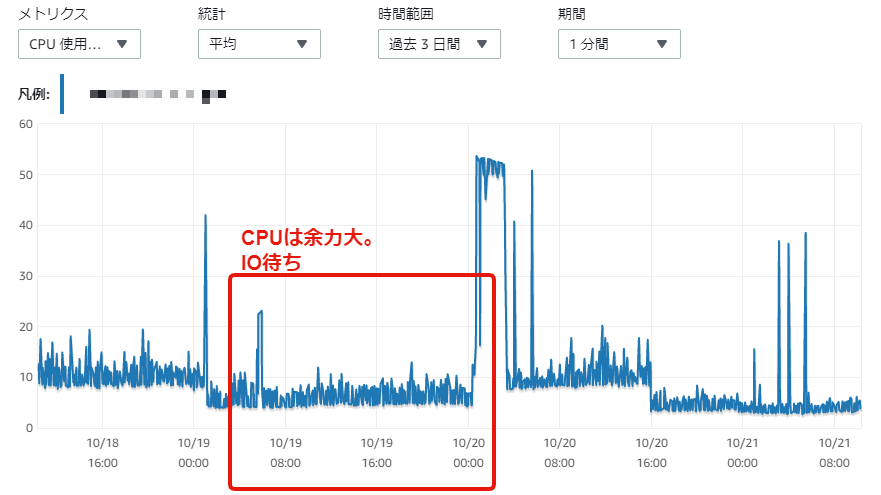
- この時、CPUやメモリはむしろ余裕がある(参考スクショを末尾に掲載)
- ので、バーストバランス枯渇問題を知らないと原因特定に時間を要する
- Webアプリのバックエンドだと不安定な挙動となる
- リクエストの全てがエラーになるわけではない。
- 一部はサクサク動く。一部は遅く。一部は接続エラーとなるのでややこしい
- コンバージョンが平時より少なくなるがそこそこあるので、コンバージョン監視が役に立たずに発見が遅れる
参考記事
以下が、原因がわからずに冷や汗かいていた時に救われた記事.感謝です。
上記の記事が公開されたときは「残り」を確認するすべがなかったようですが、現在はメトリクスが存在してRDSコンソールでモニタリング可能です。
キーワード「バーストバランス/Burst Blance」がわかってしまえば色々と有用な情報があります。以下はAWS公式。
汎用 SSD ストレージのパフォーマンスは、ボリュームサイズの影響を受けます
汎用 SSD ストレージを使用すると、DB インスタンスは 540 万 I/O クレジットの初期 I/O クレジットバランスを受け取ります。
この最初のクレジットバランスは、30 分間で 3000 IOPS のパフォーマンスバーストを維持するために十分です。
ボリュームは、ボリュームサイズの各 1 GiB あたり 3 IOPS というベースラインパフォーマンスレートで、
I/O クレジットを取得します。
例えば、100 GiB の SSD ボリュームの場合、ベースラインパフォーマンスは 300 IOPS になります。
対策
クエリチューニング
弊社が枯渇に見舞われたのは、あるサービスの本番運用からちょうど1年経過した頃。
ユーザビリティを向上させる改修(その画面を表示した場合に自動で一覧データ取得)を行ってからしばらくしてからです。
表示するデータは最大50件ですが、検索対象となるテーブルは50万件くらいあり、Indexが効かない抽出条件があり、それによりIO負荷が高まるといったものでした。
(やや場当たり的ですが)検索条件のデフォルトに「直近3ヶ月」という条件を設定することで回避しました。
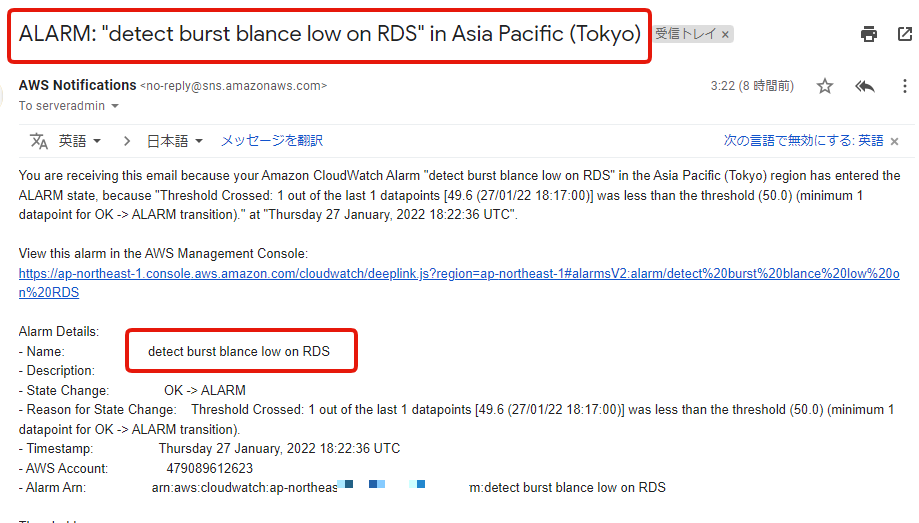
CloudWatchアラーム
徐々に忍び寄ってある時に突然大問題として顕在化するのが怖いところです。
CloudWatchアラームで監視してしきい値(下図は50%)を下回ったら、関係者に通知するようにしました。
参考/スクリーンショット
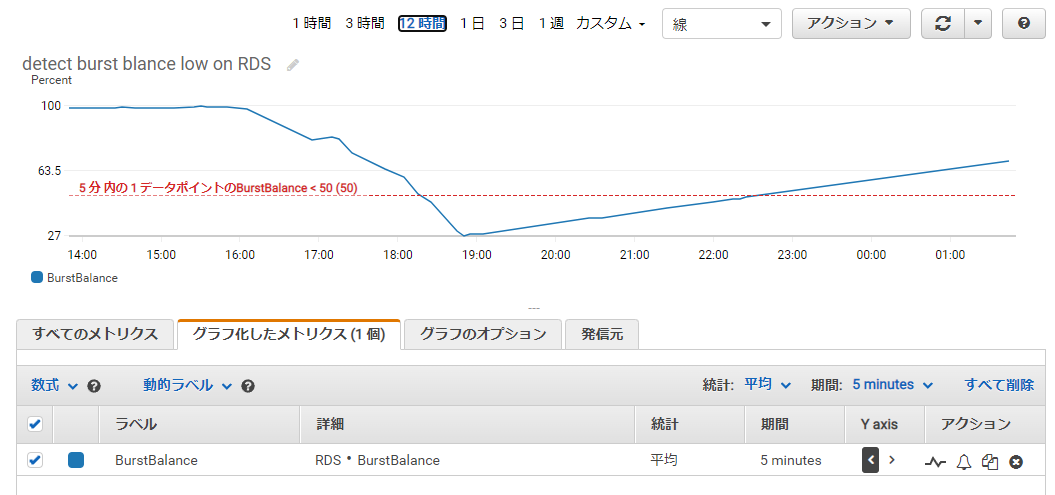
バーストバランスが枯渇した場合のメトリクスがどのようになるかスクショを記載しておきます。
バーストバランス
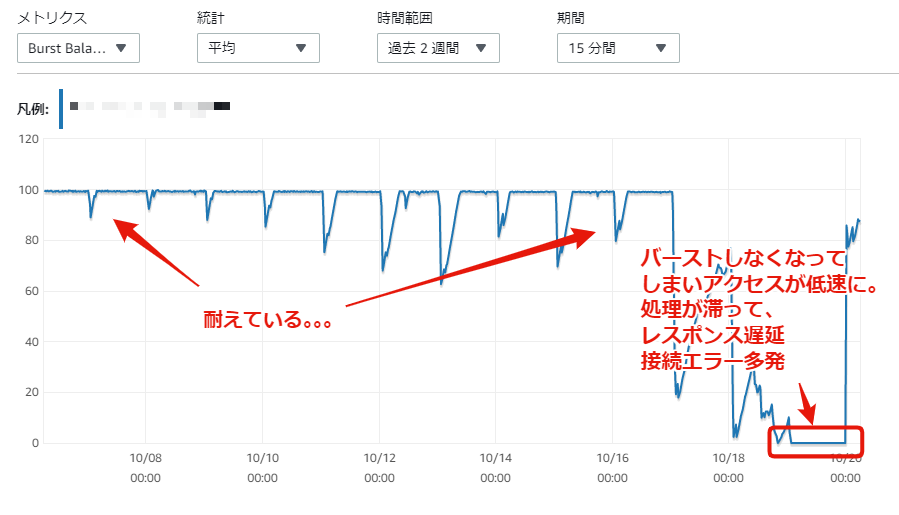
問題が発生した時にバーストバランスのメトリクスです。期間は2週間。
徐々に忍び寄っている(日中に減って、夜間に回復)のが、よくわかります。
原因となった改修から2週間経過して顕在化しました。
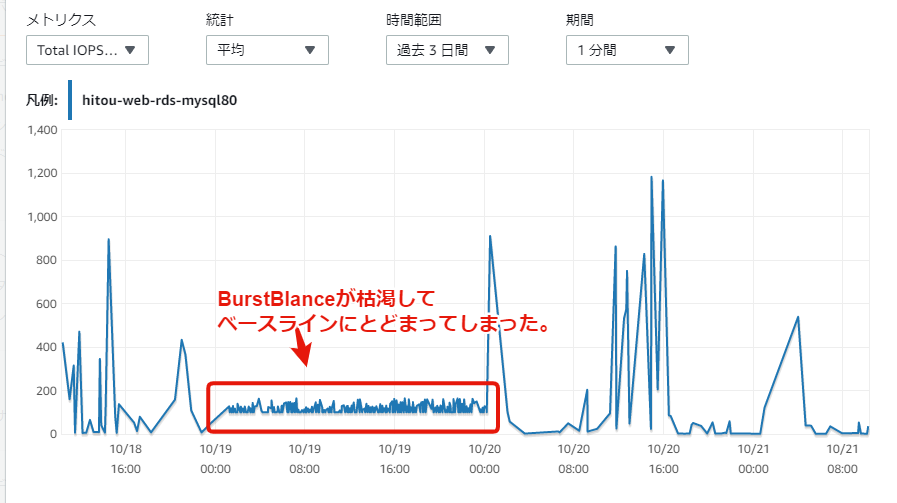
Total IOPS
バーストバランスが枯渇すると同時に、IOがバーストしなくなった(=ベースラインにはりつき)のがわかります。
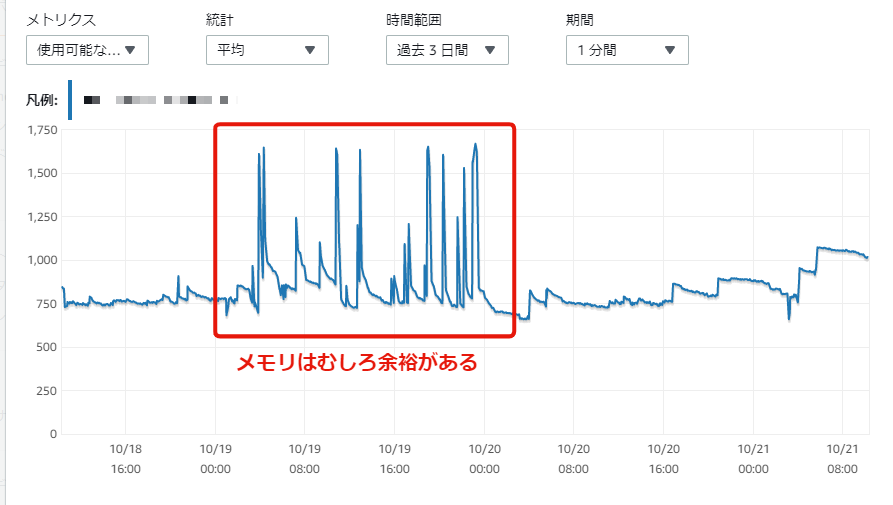
メモリ
余裕あります。
CPU
IOで詰まっているのでCPUは余力あります。(最初、CPUクレジットを疑ったので、原因特定が遅くなりました)