深層強化学習のパッケージ調査
背景
- 深層強化学習の仕事で使う必要が出てきたが、パッケージが乱立しており、どのパッケージが最適なのか不明であった。
- どのパッケージが最も使い勝手が良さそうか比較評価した。
- また、選択したパッケージの簡易的な利用方法を取りまとめた。
- 今回は、あくまでもパッケージ調査に主軸を置いており、理論面は書籍等の媒体を参考にしてください。
深層強化学習のパッケージ調査
深層強化学習のパッケージの基本構成
- 強化学習は、環境とエージェントで構成されている。
- 環境とエージェントは分離してパッケージ化されていることがほとんど。
- 今回は調査した環境とエージェントそれぞれのパッケージについて比較調査した。
深層強化学習パッケージの比較
環境のパッケージ
- 元々有名なプロジェクトであった、openai/gymやgoogle-deepmind/dm_controlがサポート終了し、後継のパッケージにプロジェクトが継承している様子。
- openAI/gymが最も利用されていたこともあり、文献やトラブルシューティングはopenai/gymのforkである、Gymnasiumが入門には適していそう。
| 名前 | URL | プロジェクトの状態 | Github Star | できること | |
|---|---|---|---|---|---|
| openai/gym | https://github.com/openai/gym | 終了 | 8.7K | ゲームから歩行の物理シミュレーションまで、幅広く環境を提供している。 | |
| Gymnasium(openai/gymのfork) | https://github.com/Farama-Foundation/Gymnasium | 継続中 | 4.4K | OpenAI Gymのforkであり、後継のパッケージ。 | |
| google-deepmind/dm_control | https://github.com/google-deepmind/dm_control | 終了 | 3.4K | MuJoCoの前身のパッケージ。 | |
| google-deepmind/mujoco | https://github.com/google-deepmind/mujoco | 継続中 | 6.5K | MuJoCo は、Multi-Joint Dynamics with Conntactの略である。ロボット工学、生体力学、グラフィックスとアニメーション、機械学習、および環境と相互作用する多関節構造の高速かつ正確なシミュレーションを目的とする汎用物理エンジン。 |
エージェントモデルのパッケージ
- openAIのStable Baselinesからforkし、後継として開発されているのがStable Baselines3がである。
- Stable Baselines3は、現在も継続開発カスタマイズ性も高く、研究用途では最も使い勝手が良さそう。
- RLlibは、Rayというクラウド分散型でスケーラブルなAI開発を支援するパッケージの強化学習機能である。
- RLlibは、本番実装のための利用に適しているが、カスタマイズ性が低く研究用途に向いていない。
- 活発な開発が行われていたがプロジェクトが停止してしまっている、TensorforceやRL_Coachのようなパッケージが多数存在した。
| 名前 | URL | プロジェクトの状態 | Github Star | フレームワーク | 対応アルゴリズム | カスタマイズ性 | 可読性 |
|---|---|---|---|---|---|---|---|
| Stable Baselines3 | https://github.com/DLR-RM/stable-baselines3 | 継続中 | 6.9K | PyTorch | 基本のみ | 高 | 高(コメント有) |
| RLlib | https://github.com/ray-project/ray/tree/master/rllib | 継続中 | 5.0K | TensorFlowPyTorch | 多数 | 低(複雑に抽象化されている) | 高い(コメント有) |
| Tensorforce | https://github.com/tensorforce/tensorforce | 終了 | 3.3K | TensorFlow | 基本のみ | 高 | 低(コメント無) |
| RL_Coach | https://github.com/IntelLabs/coach | 終了 | 2.3K | TensorFlow | 多数 | 高 | 低(コメント無) |
深層強化学習のパッケージの利用
私は直近、研究用途で利用する予定であり、内部構造を把握しカスタマイズする必要があったため、Stable Baselines3を選択した。
Stable Baselines3のパッケージの使い方の詳細は、次の参考資料にわかりやすく丁寧に記述されており、すぐにキャッチアップできた。
Stable-Baselines3 Docs - Reliable Reinforcement Learning Implementations
詳細な利用方法は、上記資料に譲るとして、今回は棒を直立に立たせる制御タスクのサンプルコードを確認する。
画像参照元:
https://gymnasium.farama.org/environments/classic_control/cart_pole/
なんと、次のソースコードを記述するだけで、1~4が全て実行できる。
- 環境の構築
- PPOのモデル(方策は多層ニューラルネット)のロード
- 10,000ステップの学習
- 学習済みモデルを用いた評価
import gymnasium as gym
import numpy as np
from stable_baselines3 import PPO
from stable_baselines3.ppo.policies import MlpPolicy
from stable_baselines3.common.evaluation import evaluate_policy
env = gym.make("CartPole-v1")
model = PPO(MlpPolicy, env, verbose=0)
model.learn(total_timesteps=10_000)
mean_reward, std_reward = evaluate_policy(model, env, n_eval_episodes=100)
print(f"mean_reward:{mean_reward:.2f} +/- {std_reward:.2f}")
# mean_reward: 351.68 +/- 107.47
2019年に深層教科学習をやっていた時には、ニューラルネットをすべて1から記述していた。それから4年経って久々に調べてみると、深層教科学習を始める環境としては非常に整っており、すぐに実験がスタートできる状態で少々驚いた。
今後の展望
ここ1年間はLLMが流行っていますが、最近はLLM+αでマルチモーダルな研究が盛んに行われている。最近興味があるのが、LLM×強化学習でこの論文(Motif: Intrinsic Motivation from Artificial Intelligence Feedback )など面白いコンセプトの論文がちらほら出始めている。この論文は、RPGをクリアするエージェントにおいて、単なる強化学習による外的報酬の最大化だけでなく、常識に基づいた内的報酬を組み合わせることでスコアが高まることを示した。平易な言葉で説明すると、今までの強化学習ではRPGにおいて鍵が良いものなのか?悪いものなのか?何度も試行を繰り返さなければわからないが、内的報酬を組み込むことで人間が常識を持つように初めから良いものだと判断できる。LLMにも強化学習も簡単に利用できる環境が整っているので、この辺りの研究を自分でも実施してみたいと考えている。
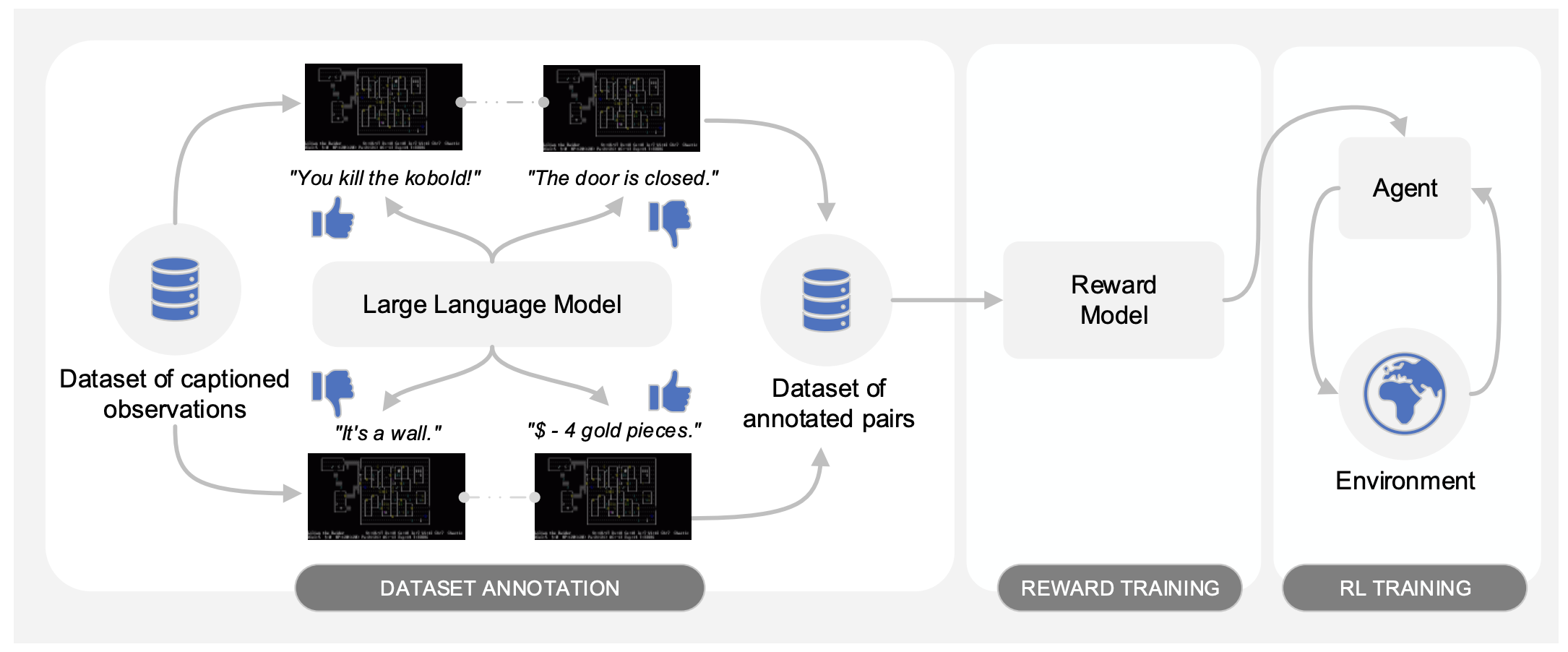
画像参照元:
Motif: Intrinsic Motivation from Artificial Intelligence Feedback
参考
The Best Tools for Reinforcement Learning in Python You Actually Want to Try
https://neptune.ai/blog/the-best-tools-for-reinforcement-learning-in-python
Stable Baselines3 RL tutorial
https://github.com/araffin/rl-tutorial-jnrr19
Stable-Baselines3 Docs - Reliable Reinforcement Learning Implementations
https://stable-baselines3.readthedocs.io/en/master/index.html