背景
昨今大規模言語モデルが話題の中心であるが、深層強化学習の領域も2023年付近から大きな進展を見せている。深層強化学習における困難が実用化の妨げになっていたが、基盤モデルや模倣学習の領域の進展によりそれを乗り越える研究成果が出てきている。今回は、深層強化学習における従来の困難と研究の方向性について説明する。
そもそも「強化学習」とは?
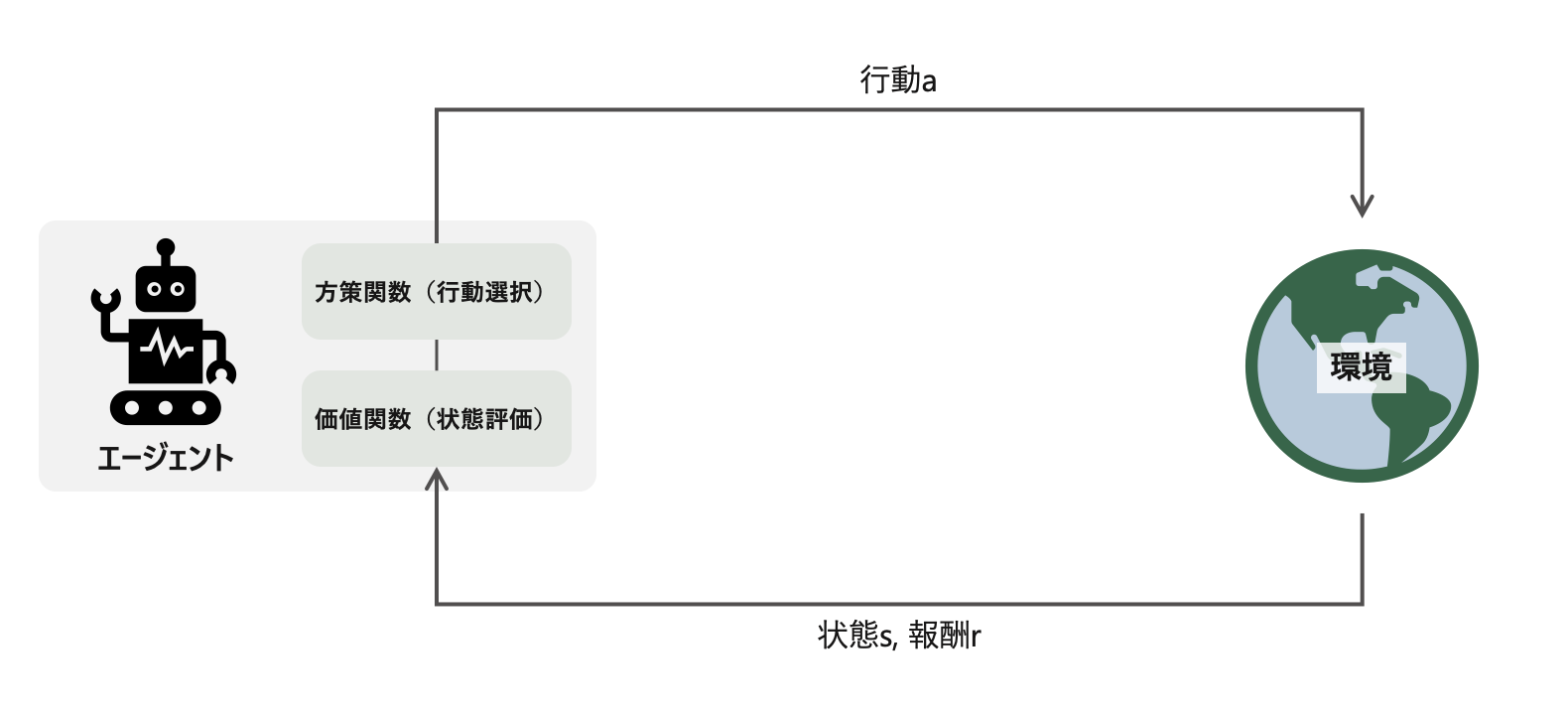
強化学習の問題設定は、エージェントが行動aを決定し、環境から得る報酬rを最大化する問題設定である。エージェントは、状態sと報酬rを入力に、現在の状態の価値を価値関数で評価したり、行動の選択を方策関数で行ったりする。深層強化学習では、方策関数や価値関数を深層学習で近似的に学習するアプローチである。
AlphaGoは最も有名な深層強化学習の応用例です。AlphaGoは、18の世界タイトルを獲得していた伝説の囲碁棋士「イ・セドル」と2016年3月に対戦し、AlphaGoが4対1で勝利している。
なぜ「強化学習」の実用化が進まないのか?
2016年3月に囲碁で人間を超える能力を示したにも関わらず、その後2024年2月時点で「強化学習」の実用的な活用例はそう多くありません。強化学習を社会実装するには次の難しさが存在する。
- 困難1: エージェントの常識の無さ
- 困難2: エージェントの汎用性の低さ
- 困難3: シミュレーターの作成が困難
以降これらの困難の説明と、解決に向けた研究の方向性を紹介する。
強化学習における困難とそれぞれへの最新研究の方向性
困難1: エージェントの常識の無さ
困難
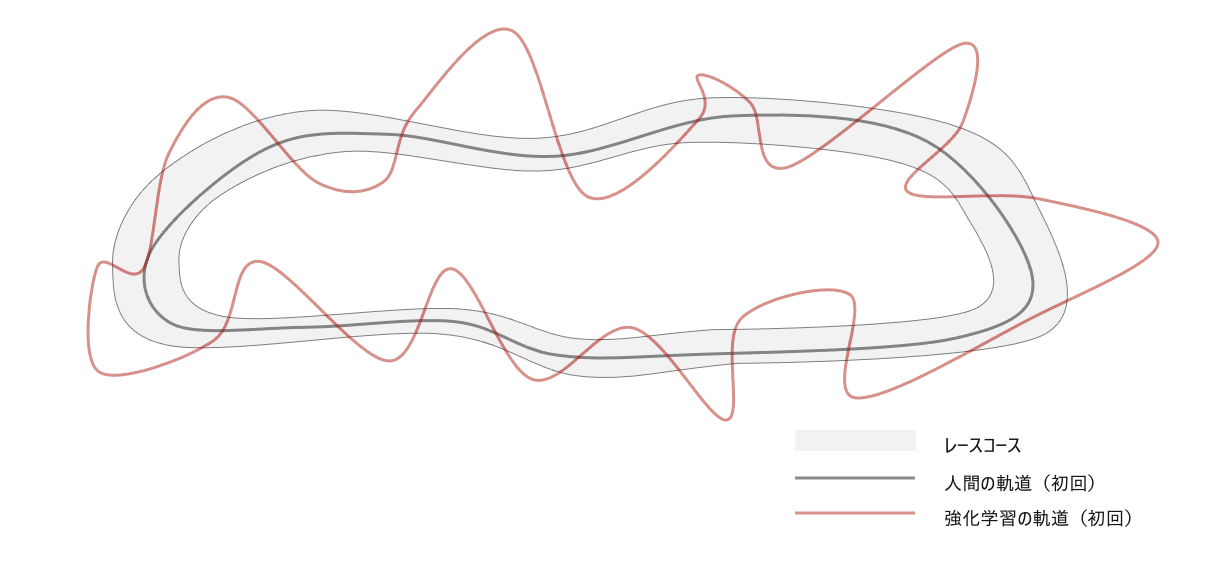
オープンエンドな環境に放り込まれたエージェントは、取りうる選択肢が多すぎて、何をすべきなのか判断できなくなるフレーム問題に陥る。エージェントは、学習の初期において無作為な行動を行い、どのような行動が良いか探索する。一方、人間は生まれてから培われた人間世界における「常識」を踏まえて、良い行動を推定しながら試行錯誤することができる。例えば、レーシングゲームを行う場合、人間は道の上を通ったほうが良いと「常識」的にわかっていますが、強化学習の場合は、レースにかかった時間(報酬)をもとに、何度も試行錯誤して初めて、道の上を通るとスコアが良くなることを理解する。
フレーム問題
レースの学習における初回の挙動違い(人間と強化学習)
解決の方向性:内発的動機の報酬を導入
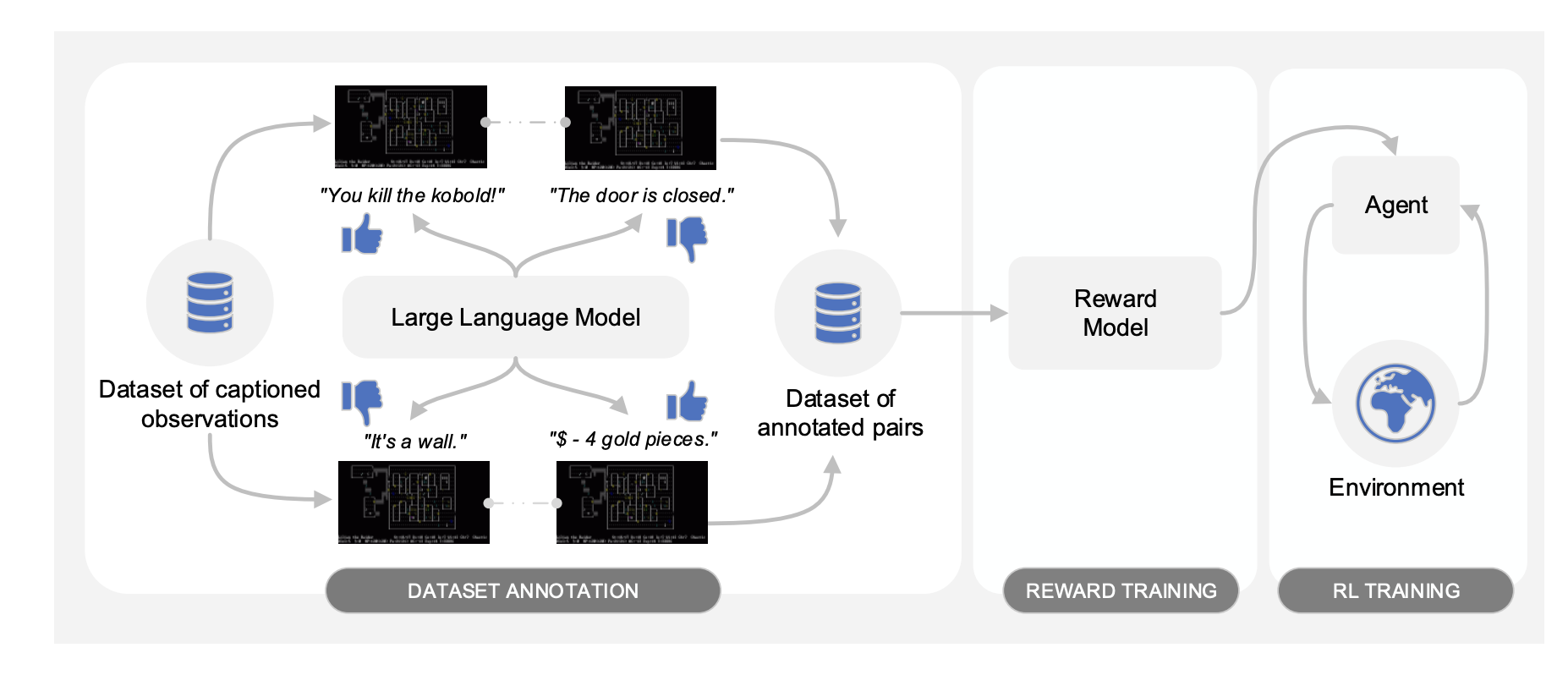
この問題を解決する研究の方向性として、環境から与えられる報酬を外発的動機とし、対照的な概念として内発的動機(Intrinsic Motivation)を導入する研究がある。Metaが公開した、「Motif: Intrinsic Motivation from Artificial Intelligence Feedback」という研究である。この研究では、大規模言語モデルに良し悪しを判断させ、その判断結果を報酬に組み込むというものである。例えば、「ゴブリンを倒した。」「ドアは閉まっている。」「壁にぶつかっている。」「4ゴールド手に入れた。」と言った状況を報酬が与えられなくても、人間は良し悪し判断できるのと同じである。この手法はフレーム問題を解決する方法としても注目されている。
「Motif: Intrinsic Motivation from Artificial Intelligence Feedback」におけるエージェントのゲームプレイ

「Motif: Intrinsic Motivation from Artificial Intelligence Feedback」のアーキテクチャ
さらに、大規模言語モデルのインコンテクストラーニングの特性を利用して、内発的動機の重みも変更することができる。例えば、大規模言語モデルのプロンプトに、役割を指示すると次のように挙動が変わる。つまり、エージェントの挙動を後から変更できる汎用性も取り込むことができる。
| 役割 | 効果 |
|---|---|
| The Gold Collector | ゴールドを多く集める |
| The Decender | 最速でダンジョンをクリアする |
| The Monster Slayer | モンスターを多く倒す |
プロンプトのイメージ

プロジェクトページ
論文
困難2: エージェントの汎用性の低さ
困難
学習対象の環境が変わった場合、変更に対応することができないため、再度学習し直す必要がある。つまり、深層強化学習は、学習対象の環境に過学習しており、汎用的な性能を示さないことが問題であった。例えば、囲碁において人間を凌駕するエージェントは、オセロをプレイすることはできない。また、仮に囲碁のルールを少し変えてアレンジしたゲームであっても、エージェントの挙動を再学習させる必要がある。
解決の方向性:基盤モデルの開発
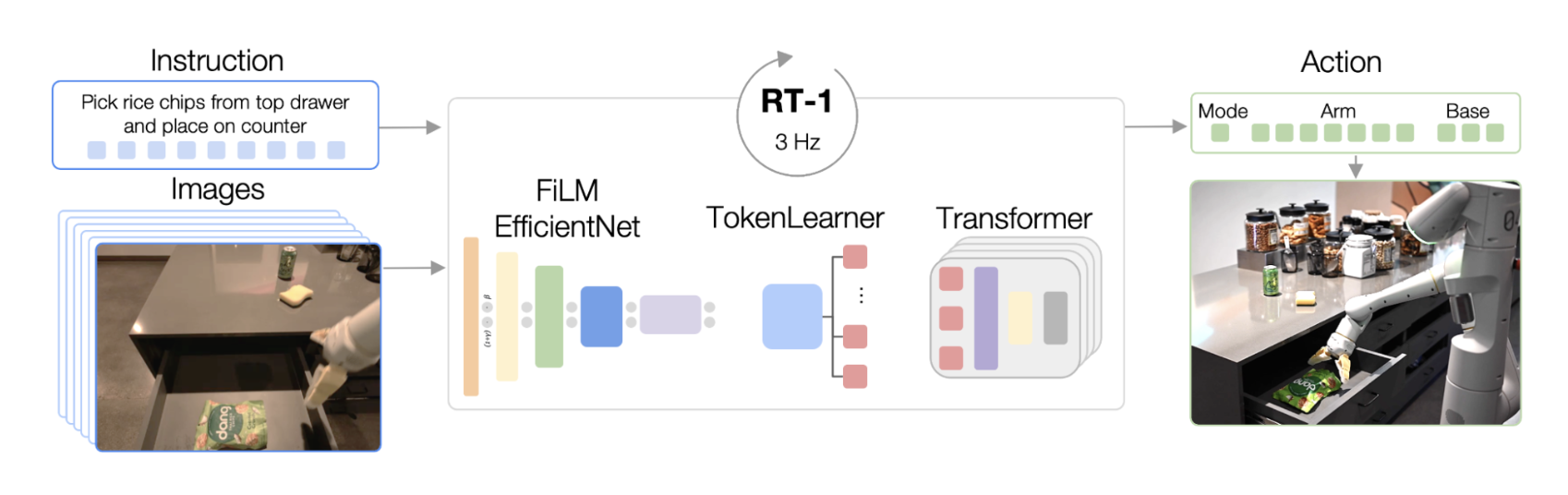
このような問題に対する解決策としては、強化学習モデルにおける基盤モデルの開発が進んでおります。有名な研究として、Google DeepMindのRT-1,2の研究があります。
17ヶ月にわたって多くの異なるオブジェクトを使った700以上のタスクをカバーする13万エピソードを、実行指示のテキストとセットで収集した。データセットに含まれる高レベルスキルのセットには、アイテムをピッキングして置く、引き出しを開け閉めする、引き出しにアイテムを出し入れする、細長いアイテムを真上に置く、オブジェクトを倒す、ナプキンを引く、瓶を開けるなどが含まれる。
RT-2では、画像、言語、行動の3つのモーダリティーを入出力するような問題設定で学習を行っている。13万エピソードの行動データに加えて、インターネットからかき集めたVQAデータで言語理解と画像の状況理解に関する能力を高めている。
| モデル | 入力 | 出力 | データ |
|---|---|---|---|
| RT-1 | 言語、画像 | 行動 | 13万のエピソード |
| RT-2 | 言語、画像、行動 | 言語、画像、行動 | 13万のエピソード、インターネットからかき集めたVQAのデータセット |
RT-1のアーキテクチャ
RT-2のアーキテクチャ
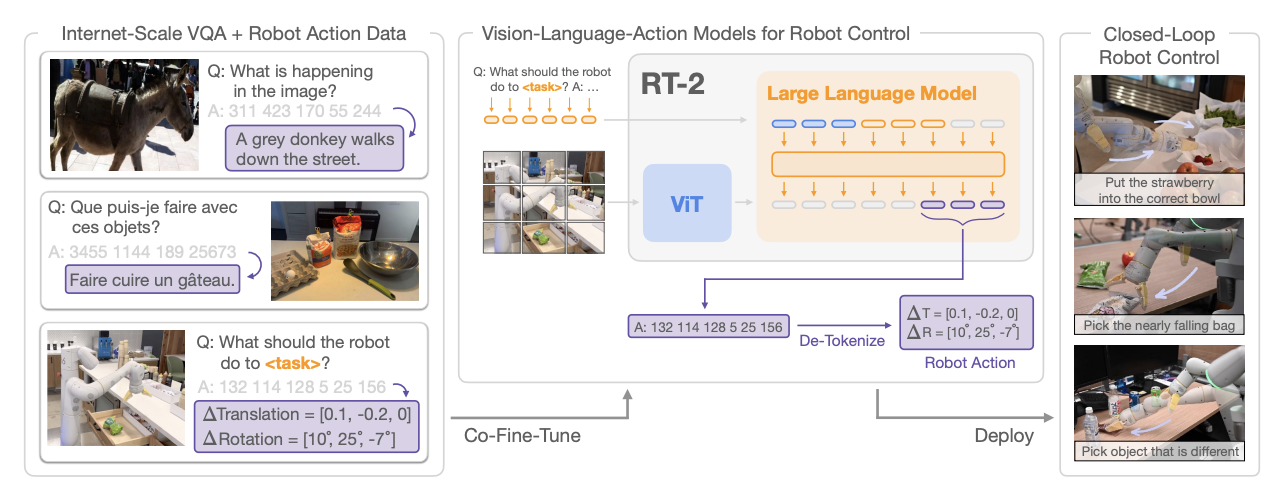
ただし、RT-1,2は、強化学習の問題設定を取り扱っているものの、アプローチとしては強化学習というよりは、言語と画像を入力としたときの、行動系列の生成であり生成系AIの問題設定である。しかし、これまで強化学習の問題設定として取り扱っていたものに対して汎用性をもたらしていることに変わりはない。
強化学習の問題設定のまま、基盤モデルにチャレンジしている研究として次の研究がある。強化学習におけるエージェントを大規模に、強化学習の問題設定で多様な設定を学習させることで、人間と同じように素早くオープンエンドの新しい3D問題に適応できる、インコンテクストラーニングの特性が強化学習でも得られていることが示されている。興味のある方はこちらをご覧ください。
ただし、個人的には、言語や画像の大規模データの恩恵受けることができる、RT-2のアプローチのほうが汎用性の観点で将来性があると考えている。
困難3: シミュレーターの作成が困難
困難
深層強化学習を行うには、必ず環境が必要である。環境とは、エージェントからのアクションを受け取り、環境の状態を変更して、報酬を出力するシミュレーターである。将棋で例えると、棋士の一手がアクションで、盤面が状態であり、勝敗が報酬である。ゲームの場合、シミュレーターの作成は容易である。そのこともあり、ゲームをクリアするための強化学習の事例は、多数存在する。しかし、実問題のシミュレーターを構築するのは極めて難しい問題である。特に、報酬の設計は難しい問題である。行動が成功したときにだけ報酬を与える環境の設定であると、初期の無作為な行動の時に、報酬を獲得するまでに多くの時間がかかってしまう。成功に近づく行動に対して報酬を与える必要があるが、それを設計することは極めて困難である。例えば、頂点ピッタリに止まる問題を考える。この時の報酬が、頂点ぴったりに止まった時だけに与えられると、初期の探索時に成功事例が極めて少なく、成功までの特徴を掴むのに時間がかかってしまう。一方、成功に近づいていることを示す報酬を与えると、成功に近づく特徴を掴むことができる。例えば、頂点付近で速度が低いほど高い点数を与えるなどの報酬の設計の方法である。このように、問題設定に対する報酬の設計方法で成功可否が決まる一方で、その設計は極めて難しい問題である。
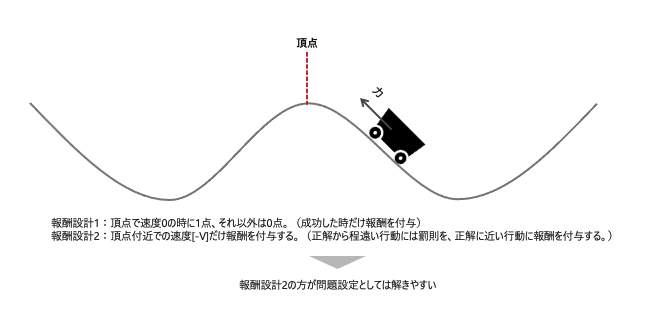
解決の方向性:行動生成による模倣学習
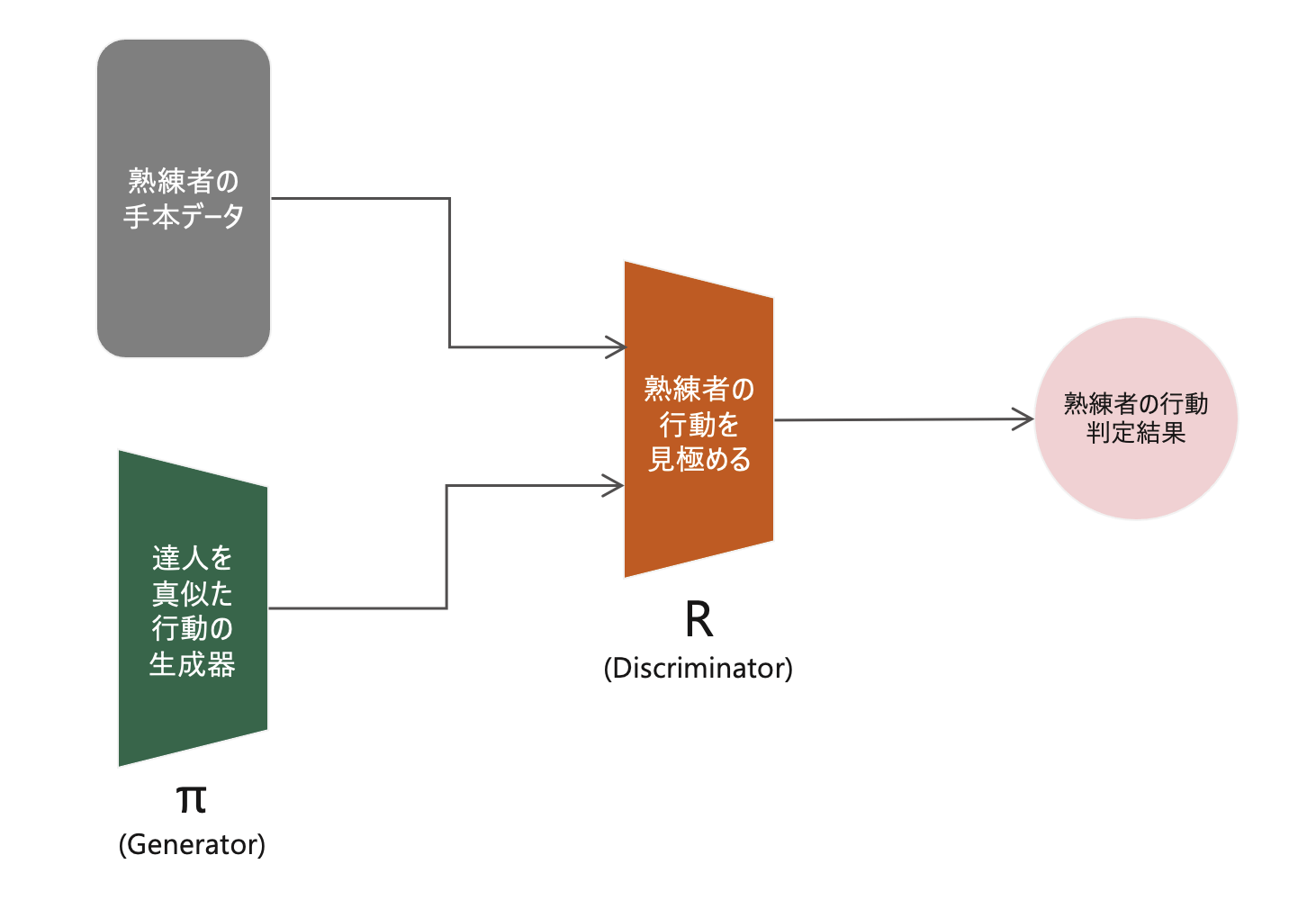
模倣学習とは、熟練者の行動と同じような行動を学習することである。強化学習の問題設定でありつつ、教師あり学習の位置付けともなっている。熟練者の行動を真似る教師あり学習なので、シミュレーターを用意する必要がそもそもなくなる。深層学習の領域における模倣学習で最も有名なのが、2016年に論文が投稿されたGAIL(Generative Adversarial Imitation Learning)である。GAN(Genera tive Adversarial Networks)のアーキテクチャにおける学習データを、画像ではなく、熟練者の行動にしたネットワーク構造を持つ。このアーキテクチャでは、GANのアーキテクチャと同様に、偽物を生成するGeneratorと本物・偽物を見極めるDiscriminatorを作成する。Generatorは、熟練者の行動と同じような行動を生成する。また、Discriminatorは、熟練者の行動を見極める役割を担う。この問題設定で学習を進めることで、Generatorから熟練者と同じような行動が生成できるようになる。
GAIL(Generative Adversarial Imitation Learning)のネットワーク構造
さらに、GANがその後、diffusion modelによって更なるブレークスルーを迎えたように、行動生成にも同様の流れをたどります。Diffusion Policyというコンセプトのアーキテクチャが登場している。
Diffusion Policy
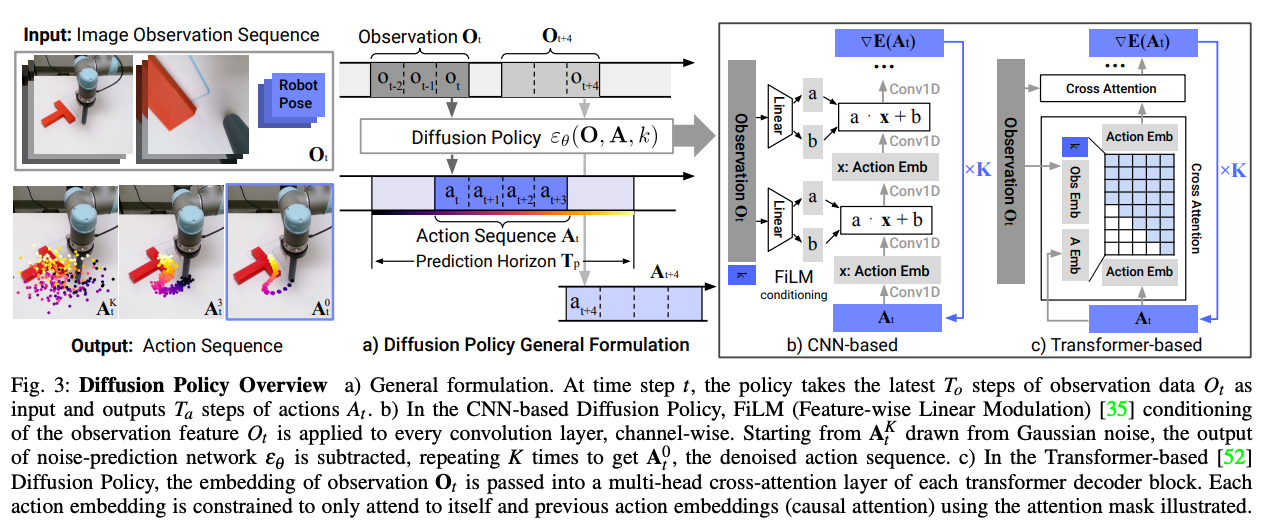
それ以外にも、トランスフォーマーのエンコーダーデコーダー構造を用いて行動系列を生成するような提案も登場している。
Action Chunking with Transformers (ACT)
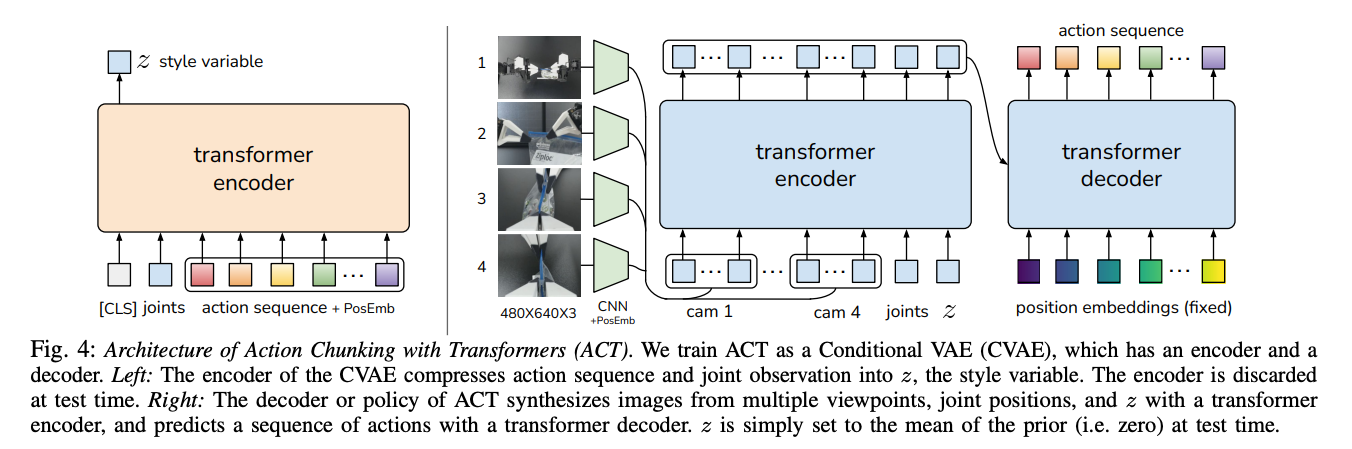

2024年に公開された、模倣学習の最新の研究成果として次のようなものが挙げられる。
2024/01/04: Mobile ALOHA
2024/02/15: Universal Manipulation Interface
模倣学習によって数十回だけ人間的な行動を教えると多少環境が変化しても、汎用的に行動を遂行することができることを示す論文が連続してリリースされた。以下動画を見て分かる通り、料理や皿洗いなど人間には簡単だが、タスク定義の抽象性から機械での実行が難しかったタスクをうまくこなせている。教育コストは数十回の人間での実行のみであり、単純作業における生産性のさらなる向上が期待できる技術である。
Mobile ALOHA ~Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation~
Universal Manipulation Interface ~In-The-Wild Robot Teaching Without In-The-Wild Robots~