はじめに
私は長い間事務職をしてきました。仕事でExcelやAccessでのデータ集計をしているうちに、もっと高度なデータ分析が出来るようになりたいという思いが強くなり、データ分析の研修を3ヶ月受講しました。データを集計した実績の結果だけでなく、未知の予測が出来るという事にデータ分析の楽しさを覚えて日々勉強中です。
記事の概要
kaggleの中からWalmartの売上データを使用し、売上を予測する機械学習モデルをPythonで構築しました。
今回はPythonの学習定着を重要視しているため、複数の分析手法を使ってみてどのモデルの精度が良いのかを検証しました。
このデータセットは45店舗のデータが1つになっています。全ての店舗のデータをバラバラに分析するということは、非常に多くの情報が得られる一方で、店舗ごとの特性や違いを見失ってしまう可能性もあります。そこで、今回は全店舗をまとめて分析し全体の売上トレンド、季節変動、外部要因との関係性などを把握することとします。
[使用したデータ] https://www.kaggle.com/datasets/yasserh/walmart-dataset
データの概要
アメリカの大手スーパーマーケットWalmartの過去の売上に関する時系列データです。
このデータには、以下の項目があります。
- Store - 店舗番号
- Date - 売上データの日付
- Weekly_Sales - その週の売上総額
- Holiday_Flag - 特別な休日かどうかを示すフラグ (0: 非祝日, 1: 祝日)
- Temperature - 平均気温
- Fuel_Price - 平均燃料価格 ※単位は華氏(°F)
- CPI – 消費者物価指数
- Unemployment - 失業率
- 休日のイベント
スーパーボウル: 2010 年 2 月 12 日、2011 年 2 月 11 日、2012 年 2 月 10 日、2013 年 2 月 8 日
労働者の日: 2010 年 9 月 10 日、2011 年 9 月 9 日、2012 年 9 月 7 日、2013 年 9 月 6 日
感謝祭: 2010 年 11 月 26 日、2011 年 11 月 25 日、2012 年 11 月 23 日、2013 年 11 月 29 日
クリスマス: 2010 年 12 月 31 日、2011 年 12 月 30 日、2012 年 12 月 28 日、2013 年 12 月 27 日
【実行環境】
Google Colaboratory
Python 3.10.12
Pythonによるデータ分析と準備
1. データの読み込み
Google DriveにCSVファイルを保存、DriveをGoogle colaboratoryにインポートします
#Googleドライブからファイルを読み込むための準備
from google.colab import drive
drive.mount("./content")
必要なライブラリをインポートします
#ライブラリのインポート
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#データの読み込み
df = pd.read_csv("/content/content/MyDrive/Walmart.csv")
df.head()
上から5行までを表示してCSVデータが読み込まれているか確認します。

2.データの確認
データ分析をする前に、データの内容を確認します。
どのようなデータなのかを知ること、データに欠損が無いかを知ることは、データ分析においてとても重要なので、時間がかかっても確認することが重要です。
#データ型の確認
df.info()
データの行は6435行、8つのカテゴリがあります。
各カテゴリのデータ型は質的変数と量的変数が混在していることがわかります。
- int 整数型
- float 浮動小数点型
- object オブジェクト型

日付の型をdatetime型に変換し、データの期間を確認します。
# 日付をdatetime型に変換
df['Date'] = pd.to_datetime(df['Date'], format='%d-%m-%Y')
#日付から期間を確認
print(df['Date'].min())
print(df['Date'].max())
日付の型を変換しました。このデータの期間は2020-02-05~2012-10-26であることがわかります。

次に、データ内に欠損(ブランク)があるかどうかを確認します。
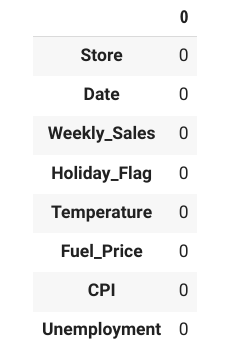
#欠損値の確認
df.isnull().sum()
データに欠損(ブランク)が無いことを確認できました。
3.特徴量の確認
- 要約統計量を使う
describe()メソッドを使うと、各列の平均や標準偏差・最大値・最小値・最頻値などの要約統計量を取得できます。
#数値データの統計量を確認
df.describe()
【統計量からの考察】
■売上のばらつき
Weekly_Salesの標準偏差(std)が大きく、売上に大きなばらつきがあることがわかります。特定の週に高い売上があり、特別なイベント等があった可能性を示しています。
■季節性の影響
店舗数を見ると45店舗あるので店舗により温度差があるのかもしれませんが、気温のデータだけをみると温度に変動があり、売上に影響を与えている可能性があります。

- 相関行列を使う
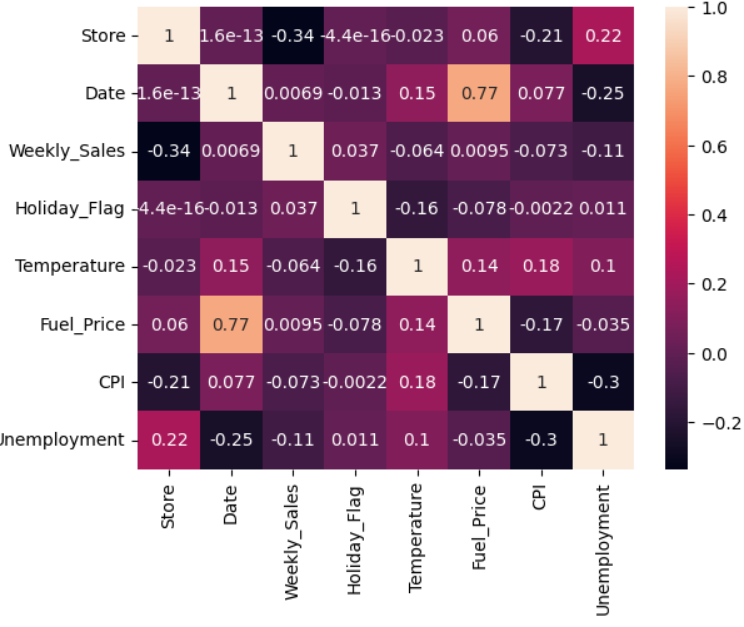
全てのカテゴリ間にどのような相関があるか確認します。相関行列に記述されている相関係数は、2変数間の直線的関係の強さを示します。相関係数は[−1,1]の実数です。相関係数が1に近ければ「正の相関」、相関係数が-1に近ければ「負の相関」があると言います。また、相関係数が0に近ければ「無相関」であると言います。
# 特徴量の相関行列を可視化
sns.heatmap(df.corr(), annot=True)
plt.show()
【相関からの考察】
売上と正の相関:日付・イベント・燃料費
売上と負の相関:温度・CPI・失業率
■Weekly_SalesとHoliday_Flagに正の相関があり、祝日がある週に売上が増加する可能性を示しています。
■Holiday_Flagは他の変数との相関が比較的低いことがわかります。これは、祝日が売上やその他の変数に与える影響が限定的であるか、他の変数との間に直接的な関係がないことを示しています。
4.モデルの選定と学習
売上に影響を与える要因を特定して、予測モデルを構築します。
- ランダムフォレストを使う
決定木のアンサンブルモデルで予測精度が高いランダムフォレストを使用します。データセットを訓練データと検証データに分割してモデルの予測と評価を行います。未知のデータに対する予測性能を評価するために、訓練データの一部を検証データとしました。(割合は訓練70%、検証30%)
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# データのコピーを作成
new_df = df.copy()
# 特徴量とターゲットの分割
X = new_df.drop(columns=['Weekly_Sales'])
y = new_df['Weekly_Sales']
# 訓練データとテストデータに分割
X_train, X_test, 78, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# カテゴリ変数のエンコーディング
X_train = pd.get_dummies(X_train)
X_test = pd.get_dummies(X_test)
# Date列をエポック時間に変換
X_train['Date'] = X_train['Date'].astype(int) / 10**9
X_test['Date'] = X_test['Date'].astype(int) / 10**9
print(X_train.dtypes)
# モデルの定義と学習
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 評価
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
【評価】
結果は以下のとおりでした。
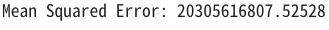
値はかなり大きくモデルの予測が実際の値から大きく外れています。
外れ値があまりに大きいのでパラメータ調整でなく、ランダムフォレスト以外のモデルを試してみることにします。
- XGboostを使う
XGboostは勾配ブースティングと呼ばれるアンサンブル学習と決定木を組み合わせた手法です。インポートしたライブラリは、XGBoost、mean_squared_error(平均二乗誤差を計算するための関数)です。
今回の説明変数は温度・燃料費・CPI・失業率、目的変数は売上です。
【モデル(XGBRegressor)の指定】
objective='reg:squarederror' 回帰問題である
colsample_bytree=0.3 各決定木で使用する特徴量の割合
learning_rate=0.1 学習率
max_depth=5 決定木の最大深さ
alpha=10 L1正則化項の重み
n_estimators=100 決定木の数
import xgboost as xgb
from sklearn.metrics import mean_squared_error
#データの作成
df_2 = df.copy()
# 説明変数と目的変数の設定
X = df_2[['Temperature', 'Fuel_Price', 'CPI', 'Unemployment']]
y = df_2['Weekly_Sales']
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# XGBoost回帰モデルの作成
xg_reg = xgb.XGBRegressor(objective='reg:squarederror', colsample_bytree=0.3, learning_rate=0.1,
max_depth=5, alpha=10, n_estimators=100)
# モデルのトレーニング
xg_reg.fit(X_train, y_train)
# 予測の実行
preds = xg_reg.predict(X_test)
# 平均二乗誤差の計算
mse = mean_squared_error(y_test, preds)
print("Mean Squared Error: %f" % mse)
【評価】
結果は以下のとおりでした。

こちらも平均二乗誤差(MSE)が非常に大きく、モデルの予測が実際の値から大きく外れていることを示しています。
改善案を考えてみました。
1.使用している特徴量が目的変数(Weekly_Sales)に対して十分な説明力を持っていない可能性があります。特徴量の選択を見直し、新しい特徴量を追加します。
2.モデルのハイパーパラメータをチューニングしてモデルの性能を向上させます。Grid SearchやRandom Searchを使って最適なパラメータを見つけます。
3.データの分割方法(train_test_split)が適切でなく、モデルの評価が正確でない可能性があります。異なる分割方法やクロスバリデーションを試してみます。
4.モデルの変更。異なるモデルを比較することで、より良い予測性能を持つモデルを見つけます。
今回は、学習のために多くのモデルを触って確かめたいのでモデルを変更して調整します。
- SARIMAを使う
今度は、時系列モデルの1つであるSARIMAモデルを使って週ごとの売上を予測します。
新たに以下ライブラリをインポートします。
statsmodels: 統計モデルを提供するライブラリ。
SARIMAX: SARIMAモデルを実装するためのクラス。
【時系列モデルの日付データ変換の流れ】
時系列モデルのため、日付のデータ(Date 列)を調整してインデックスに設定→インデックスから年、月、週の情報を抽出し、新しい列として追加→週次データを月次データに変換し、平均値を計算
【モデル(SARIMA)の指定】
Weekly_Sales 列を使ってモデルをフィッティングします。
order=(1, 1, 1) 非季節部分のパラメータ(自己回帰、差分、移動平均)
seasonal_order=(1, 1, 1, 12) 季節部分のパラメータ(自己回帰、差分、移動平均、季節周期)
forecast = results.get_forecast(steps=12)12ステップ先までの予測を行い、予測区間(信頼区間)を計算
【評価】
以下のグラフが表示されました。

- 予測の精度
予測された売上(オレンジの線)は、観測された売上(青の線)と比較的よく一致しています。これは、モデルがデータのパターンをうまく捉えていることを示しています。 - 信頼区間
予測の信頼区間(灰色の影)は、予測の不確実性を示していますが、観測されたデータの範囲内に収まっていることが多いです。モデルの予測が信頼できる範囲内であることを示せたようです。 - 全体を通して
SARIMAモデルは季節性を考慮しているため、売上の季節的な変動をうまく予測できています。特定の時期に売上が増加するパターン性があるようです。このグラフからは、4つの休日のイベントの前後に売上が増加していて、特に年末のイベントが売上に大きく影響している可能性があることがわかりました。
おわりに
今回、Pythonや機械学習を使ったデータ分析の基礎を身につけたく取り組みました。作成していくことで学習のアウトプットができ、分析の流れやコードの理解がより深まりました。様々な分析手法を研修で学んだのですが、いざ分析してみるとどの手法がフィットするか、出た結果をどう改善してよりよい分析結果を導きだすかという事に多くの時間を費やしました。大工と大工道具のように、ツールの特性や使い方を知ることがデータ分析をする上でとても重要だということに気が付きました。また、特徴量エンジニアリングのように、データの特性を知って、それをどうキレイに整えていくかの大切さも知りました。この課題を念頭において今後もデータ分析の学習を続けていきます。
知識不足ゆえ足りない点も多いかと思いますが、最後まで読んでいただきありがとうございました。