本記事について
本記事は日常の業務の中でOCRを利用し画像から情報を取り出す際に精度が上がる(かもしれない)画像の前処理についてまとめたものです。
今回は駅でよく見る掲示板を例にしました。


これらの画像に画像処理を行ってOCR(今回はGCPのvisionAIを使う)へ入力し、欲しい情報を取り出す。
※https://www.photo-ac.com/
より取得
以下pythonと画像処理でよく使うopenCVを用いて解説を行う。
1.画像処理
1.1 グレイスケール
グレースケールとは、画像などに使われる色の種類・範囲を表す用語の一つで、白と黒とその中間の何段階かの灰色のみを用いること。
(https://e-words.jp/w/%E3%82%B0%E3%83%AC%E3%83%BC%E3%82%B9%E3%82%B1%E3%83%BC%E3%83%AB.html)
昔の白黒写真のようなもので白と黒の割合のみで表現されている画像をイメージしてください。
例えば画像1をグレイスケール化するとこのようになります。

この処理を行うことにより画像の中から色の情報を大部分取り除き、形と明るさの情報が残る。
今回のOCRとは関係ないですが、もし画像分類や物体認識を行う際。その物体の色を無視し、形のみに注目させたい場合この手法を用いることで生じる利点があります。
画像においてグレイスケール化することにより、処理に必要な情報量の削減が可能になる。
カラー画像では縦横と3色の3次元情報から構成されている。それぞれの色は0~255で表されている。
よって、縦横100のカラー画像が持つ情報は1001003 の3万もの数値が含まれている。
対して、縦横100のグレイスケール画像は100*100の1万の数値と1/3に減少する。
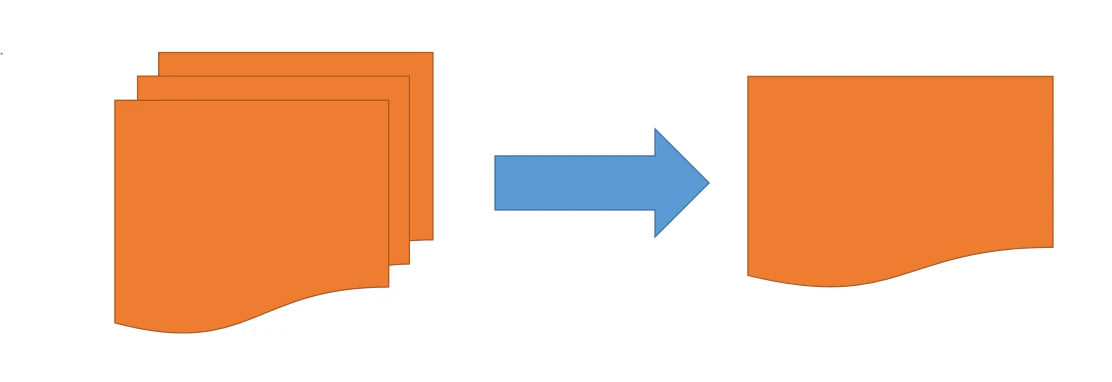
これにより、画像自体のデータサイズが小さくなりパソコンの容量での負担を減少する。処理する情報量が減ることにより、必要なRAMのサイズが小さくなり、処理速度が上昇するという利点がある。
1.2 二値化
画像に対して、ある一定のしきい値を決め、それ以上とそれ以下で値を完全に黒と白に二極化させる。
今回に関しては例えば光っている部分の文字のみを読み込みたいという目的で使用できたり、黒い文字のみを読み込む目的でも使用できたりする。

電光掲示板において

こういった画像を入力した際、光っていない部分までも読み取られてしまうことがある。そこでグレイスケイルと二値化を行うことで、光ってない部分をすべて黒に変え、形を消すことが出来る。その逆もしかり。

黄色はうまく出来ていますが、オレンジは光の強さが弱いですね……
1.3 形を検出
1.3.1 エッジ検出
画像の中に含まれる色の違う境界を検出する。
例えるなら、パンダの黒い部分と白い部分の境界を検出
以降この画像を例に進める。

この画像でエッジ検出を行った際
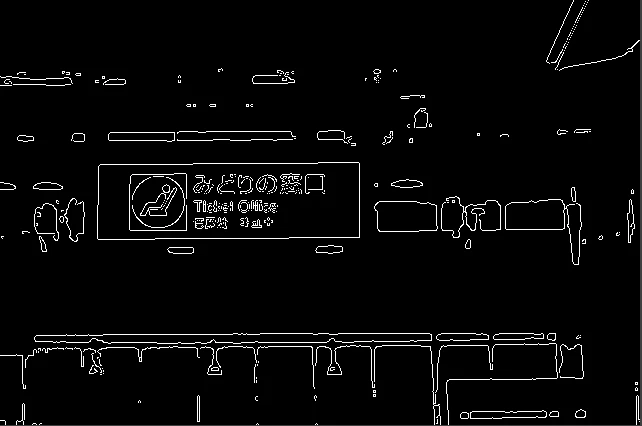
このように色の違う境界を線で表現することが可能となる。
1.3.2 輪郭抽出
先ほどのエッジに対して輪郭の抽出を行う。
そうすることで、映っている物体で分けられる形の抽出が可能となった。

1.3.3 図形抽出
最後に、抽出した輪郭に対して指定された精度以下になるように,より少ない頂点数のカーブやポリゴンで近似します.そうすることで角が取得できます。
そして今回の画像の場合4角の長方形部分の情報が欲しいので、角の数が4かつ面積が一定以上の部分を切り取ることで

必要な部分の抽出ができる。
2.精度比較with GCP visionAI
2.1.そのまま入力
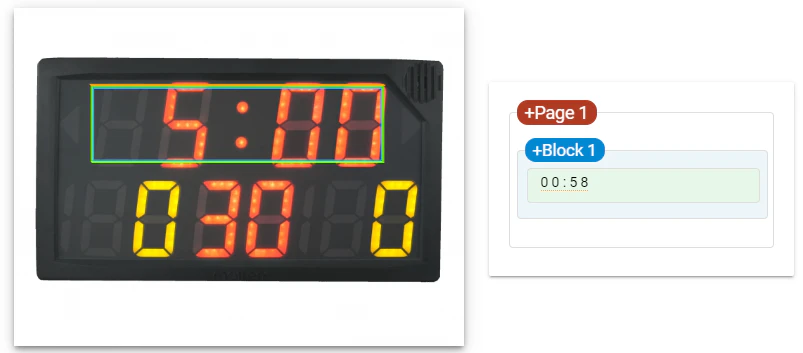
評価:こちらでは光ってない部分も検出されたことにより8という数値が出力されたと考えられる。
2.2.グレイスケイル画像を入力
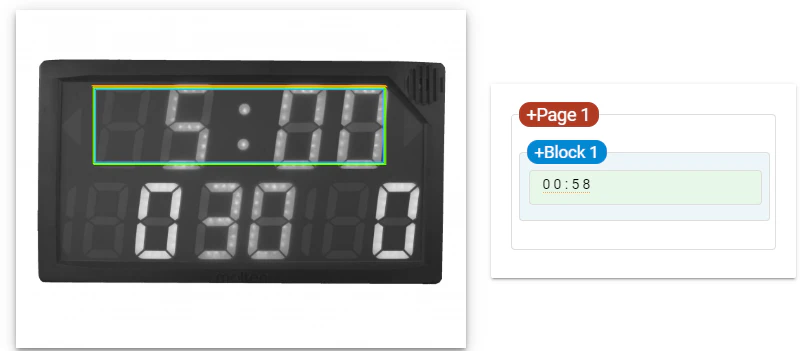
評価:色の情報はなくなったが、そのまま入力した時と同じ結果となりこの時点でも形のみで認識していると考えられる。
2.3.二値化画像の入力
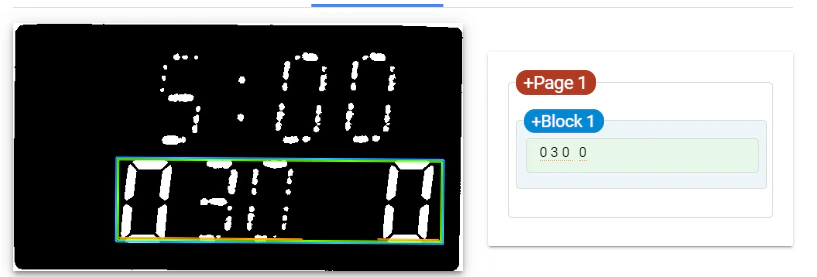
評価:上の部分が認識から外れ、下の0300が認識可能となった。上の二つと比較して精度が良くなったと考えられる。
最後に
このように画像をそのまま入力するのではなく、ある程度前処理を加えた方が、より良い処理と結果をもたらす可能性も画像系のAIを使う面白い所です。