はじめに
今回は、スプラトゥーン3において各イベント(スタート、キル、デス、フィニッシュ)が起きた時間を自動で解析するWebアプリの紹介をします。
ソースコードはこちらにあるので興味のある方はぜひ覗いてみてください。
ツールの紹介
このツールでは、スプラトゥーン3において各イベント(スタート、キル、デス、フィニッシュ)が起きた時刻を自動で解析してくれます(下のgifは開発中のものです)。

動画をアップロードして解析ボタンを押してしばらくすると、各イベントの名前とその時刻が表示され、時刻をクリックすると動画がその時刻に飛んでイベントの発生を動画で確認することができます。
内部設計について
全体の構造

フロントエンドにReact、バックエンドにFastAPI、動画の解析にランダムフォレストを使っています。
フロントエンド
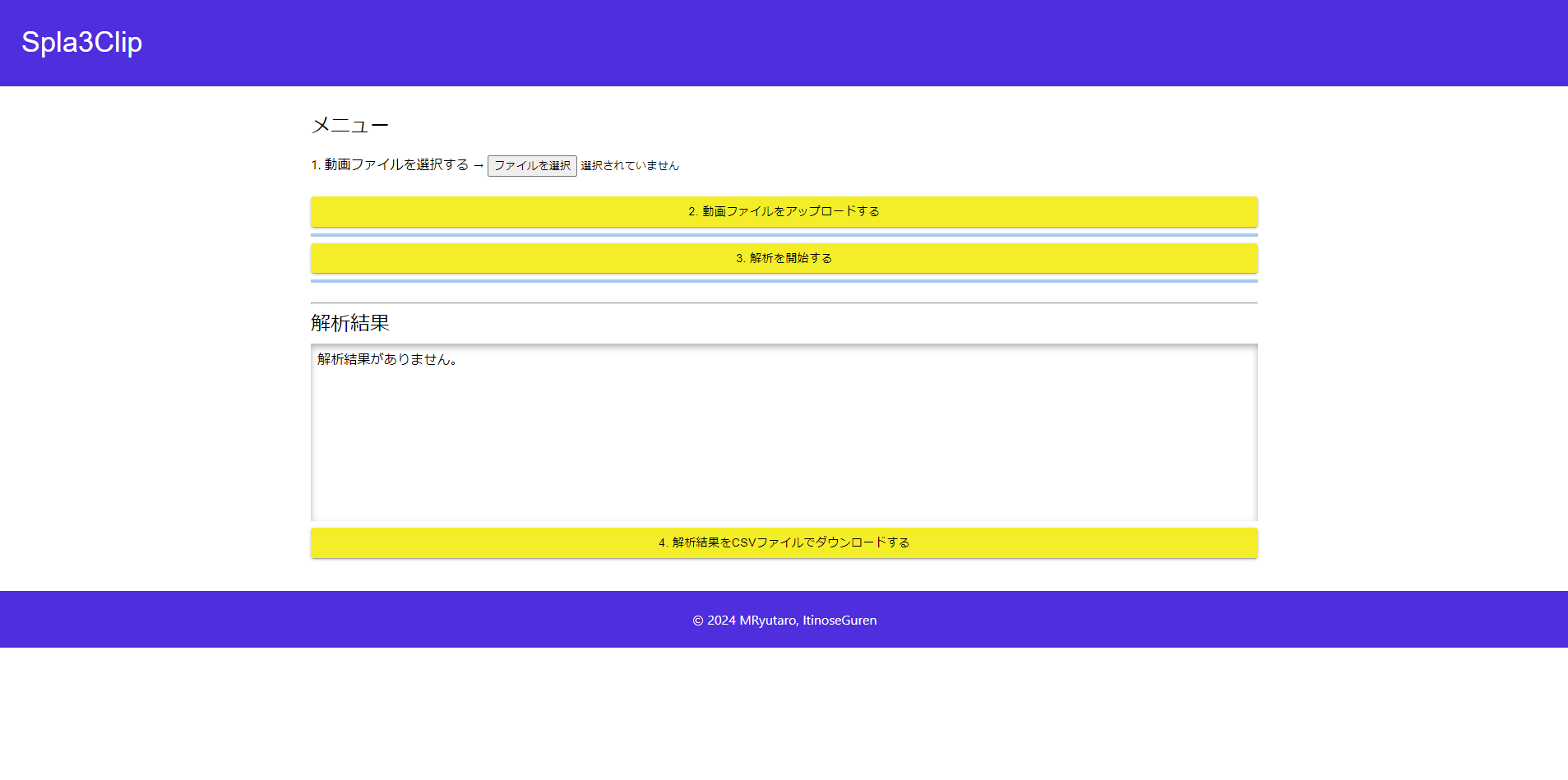
フロントエンドの開発にはReactを使い、本番環境ではビルドファイルをuvicornで配信するようにしました。
詳しく説明すると長くなるので特徴的な機能だけピックアップして紹介します。
解析の進捗状況のリアルタイム表示

EventSourceを使って、サーバからリアルタイムで情報を受け取るというSSEを実現しました。
時刻のクリックによる動画のジャンプ
useRefを使ってvideo要素への参照を保持し、時刻をクリックしたときにその時刻をcurrentTimeに代入することで実現しました。
バックエンド
FastAPIを使いました。
詳しく説明すると長くなるので特徴的な機能だけピックアップして紹介します。
バックグラウンドタスクの追加
解析には時間がかかるため、クライアントへレスポンスを返してからバックグラウンドで解析の処理をできるようにしたいです。
そこでFastAPIの機能の一部としてデフォルトで用意されているBackgroundTasksを使います。(↓BackgroundTasksについて)
yieldとSSEによる解析進捗状況の送信
まず、yieldを使ってバックグラウンドタスクからFastAPIへ解析進捗状況のデータを渡します。(↓yieldについて)
そして次に、SSEを使ってサーバからクライアントへ解析進捗状況を渡しています。(↓SSEについて)
動画の解析
データ収集
まずは学習に使うデータを集めます。
プレイ動画をキャプチャし、1フレームごとに画像として保存しました。
集めた画像は種類ごとにフォルダに分けました。
最初はラベル付与の手間削減のために、10フレームに1枚の画像を使っていましたがこれだと誤検知が目立ったため、全てのフレームを保存してデータとして使いました。
各イベントの画像の枚数は以下の表の通りです。
| イベント | 枚数 |
|---|---|
| キル | 1365 |
| デス | 1352 |
| スタート | 11 |
| フィニッシュ | 129 |
| その他 | 10609 |
前処理
以下の流れで前処理を行いました。
- グレースケール変換
- リサイズ(横の長さ320px、縦の長さ180px)
- 2次元から1次元にフラット化
モデルの学習
モデルの学習にはPythonライブラリであるscikit-learnを使いました。
また、学習モデルにはランダムフォレストを使いました。(↓ランダムフォレストについて)
ランダムフォレストの各パラメータは以下の表の通りです。
| パラメータ | 値 |
|---|---|
| n_estimators | 100 |
| random_state | 42 |
各イベントのモデルを作成するために使用したデータの枚数は以下の通りです。
| モデルの種類 | 訓練データの枚数(80%) | テストデータの枚数(20%) |
|---|---|---|
| キル | 9579 | 2395 |
| デス | 9569 | 2392 |
| スタート | 8496 | 2124 |
| フィニッシュ | 8590 | 2148 |
学習したモデルの精度はそれぞれ下の表のようになりました。
| モデルの種類 | 精度 |
|---|---|
| キル | 約99.92% |
| デス | 約99.83% |
| スタート | 約99.86% |
| フィニッシュ | 約100% |
また、それぞれのモデルがどのあたりを見ているかを可視化したものが以下の画像です。
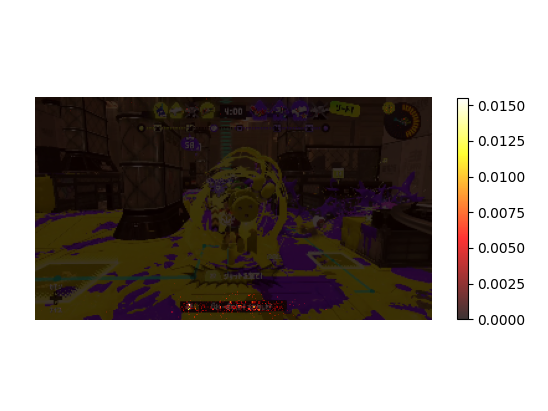
↑キル

↑デス1

↑デス2

↑スタート
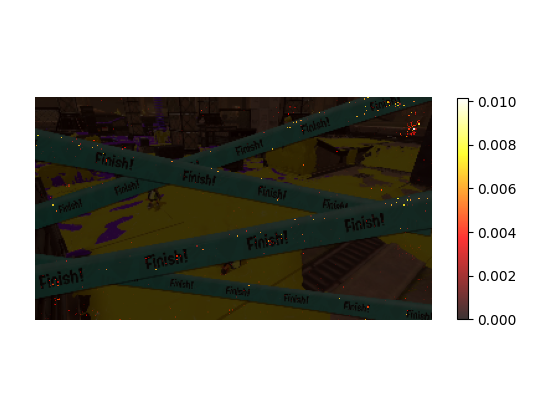
↑フィニッシュ
キルやフィニッシュはちゃんと見てほしい部分を見てくれており、精度も高いです。
一方でデスとスタートは精度が低く、見ている部分もばらついていることが分かります。
デス・スタートのモデルの精度が低い原因は、
- デス:デスの画像は2種類あるが1種類のモデルにまとめていること
- スタート:訓練データの枚数が少ないこと
かなと考えています。
また、前処理でソーベルフィルタなどを使ってエッジ検出をすればもう少し精度が上がりそうだなと思っています。
これらは今後実験していきたいです。
学習したモデルはpickleファイルとして保存しておき、推論時にそれを読み込んで使えるようにしておきました。(↓pickleファイルについて)
推論
クライアントから送られてきたデータをwhile文で1フレームごとに画像として読み込んだものに学習と同じ前処理をかけて、先ほど学習したモデルをここで使用します。
1フレームごとのモデルの多少の誤検知を許容できるようにするために、直前Nフレームの推論結果が全てキルならキルフラグ(is_killing)をTrueへ、全てnotキルならキルフラグをFalseに変化させます。
そして、キルフラグがFalseからTrueへ変化したときにキルしたと判定します。
(下の図参照)


一方で、この処理によって、あるイベントが終了してから再び同じイベントが発生するまでの間隔がNフレーム以内の場合に2つイベントが発生しているにも関わらず1つのイベントだと誤検知してしまうという問題が起こります。(下の図参照)

今回は同じイベントが続けて起こることは少ない&続けて起こっても問題ないと想定してこれは問題視していません。
さいごに
最後まで読んでいただき、ありがとうございました。
今回はスプラトゥーン3のハイライトを取得するツールを通して、機械学習をWebアプリの一部として組み込む方法を紹介しました。
外(ユーザ)から見ると機械学習が占める割合は小さいですが、このツールが便利だなと思ってもらえるためにはやっぱり機械学習の部分の精度が重要になってくるので、側の部分と中身の部分のどちらも大切だなと思いました。
今まで学んできたことを総動員して形にできたのはいい経験になったなと思います。
また、一緒に開発してくれたグレンにここで感謝を述べたいと思います。
ミスやアドバイスがあればコメントよろしくお願いします!
また、いいねとブックマークもよろしくお願いします!
もしスプラトゥーンをしている方がいれば、実際にこのツールを使ってみた感想を頂けると嬉しいです!