北海道をこよなく愛するピーターです。
本日2022/6/24㈮のホットニュースは尼崎市が全市民約46万人の個人情報が入ったUSBを紛失するです。
そして見つかりました。
新情報はこれから出てくるとは思いますが、「パスワードに関する情報(ヒント) は漏らしてはいけない」 のいい教材になったと思います。
そこで今回はパスワードを破るにはどれだけの時間がかかるかを、条件別に求めてみました。
ざっと計算しただけなので、抜け漏れはあります。
もしそもそもの計算式が違うよ等あればご指摘いただけると幸いです。
候補となる文字列と計算時間
候補となる文字列
パスワードに使用できる文字列は以下が考えられます。
・アルファベット
・数字
・特殊文字
これらをコードで確認しました。
結果は以下の通りです。1文字につき94個の選択肢があります。
したがってパスワードの桁数をnとすると、94^n通りのパターンが想定されます。
import string
list_alphabet = string.ascii_letters #大文字・小文字のアルファベット
list_digits = string.digits #0~9
list_punctuation = string.punctuation #特殊文字 !など
list_candidate = list_alphabet + list_digits + list_punctuation
print(len(list_candidate)) # 94
print(list_candidate)
#abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
計算時間
計算は弊社アークエルテクノロジーズで支給されるmacPCを用いて行いました。
下記コードによると、1億通りの計算には約19秒かかるようです。
これを基準に今後計算していきます。
from itertools import combinations
import time
start = time.time()
cnt = 0
for i in combinations(list_candidate,13):
# print(i)
if cnt == 100_000_000:
break
cnt += 1
time.time() - start #18.99993395805359 → 1億通りで19秒
パスワードが分かっている時と、ヒントだけでは突破できない場合
今回の事件では「パスワードは13桁」であるということを記者会見で発表してしまいました。
13桁だから安全ですということを伝えたつもりだったのでしょうが、悪意ある人間にヒントを与えたという観点から炎上してしまいました。
これを計算してみました。
#パスワードの桁数がわからない時
from scipy.special import comb
cnt = 0
for i in range(1,14):#1桁から順に13桁まで総当りすれば、突破される
base = 93 ** i
cnt += base
print(cnt) #39352601922816053863145793
上記は桁数がわからないときの組み合わせ総数です。ものすごい組み合わせです。
93 ** 13 #38929455665581472638810893
上記は桁数が分かっているときの組み合わせ総数です。ものすごい組み合わせですが、上から二桁目が違うので大きく違うことはなんとなくわかります。

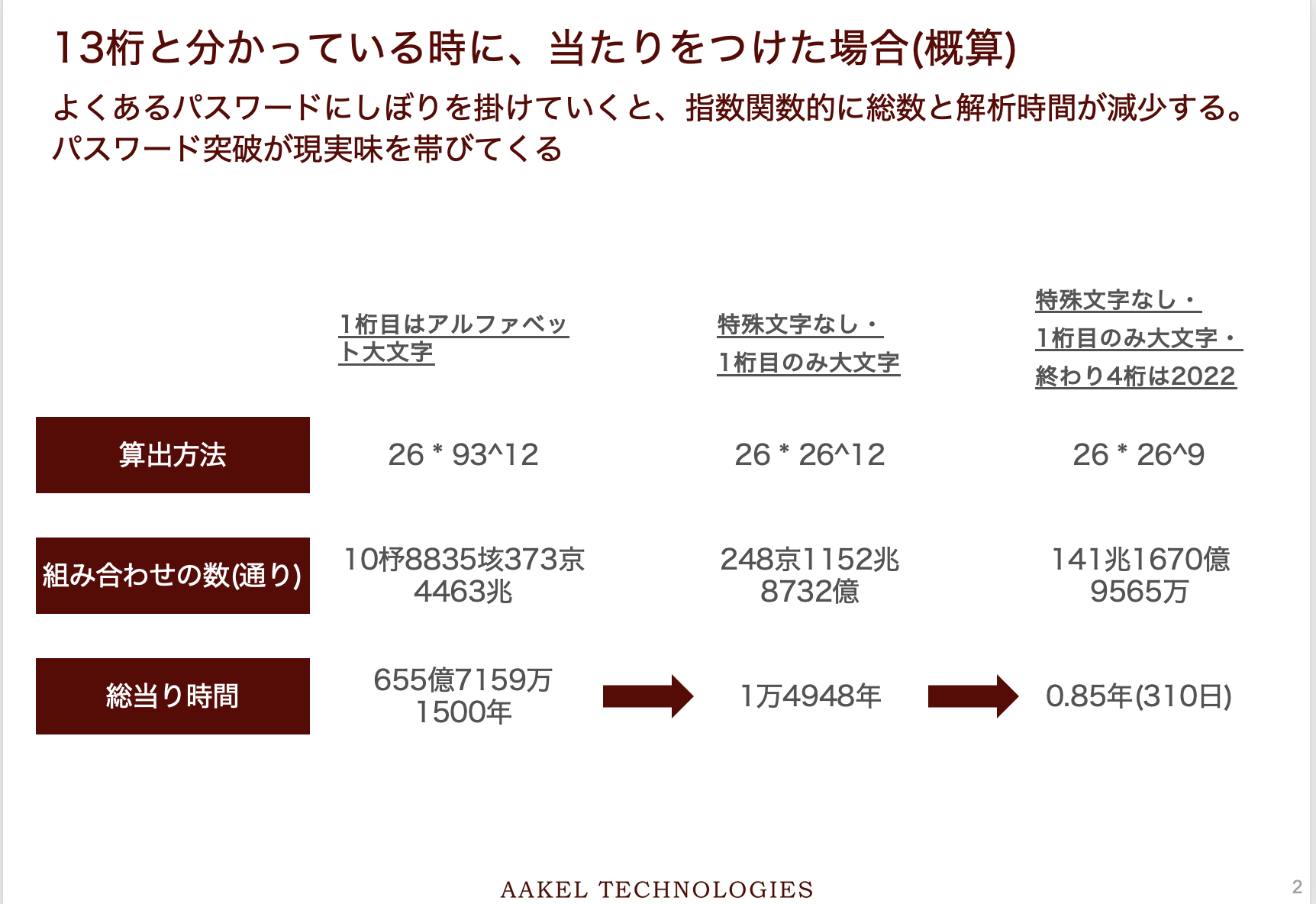
ヒントと状況をもとにあたりを付けた場合
上記の計算では天文学的な数字になりますので、13桁というのが分かったからといって突破されるわけではないことがわかりました。
しかし、これは完全なる総当りです。人間の意思を介在させれば短縮可能です。
以下の3パターンを考えました。
・1桁目は確定で大文字アルファベット(例:Amazon@WSec2!)
・1桁目のみ大文字で特殊文字は使わない(例:Amazonawsec22)
・1桁目のみ大文字で特殊文字は使わず、終わり四桁が西暦(例:Amazonaws2022)
3つ目の事例が今回噂されているパターンです。13桁である他にも、「毎年更新しているから安心です」 というヒントも漏らしています。
これは、会社ならあるあるで、終わり4桁を西暦にすることによって、「年に1回はパスワードを更新してください」に対応できるようにする悪知恵です。これでは終わり4桁は無いに等しいです。
この情報により、尼崎のパスワードは13桁ではありますが、実質は9桁のパスワードの安全性しかもたないと噂されています。(実際にそうなっているかはわかりません。ネット民の推測にしか過ぎません。)
さらに絞りをかけてみた
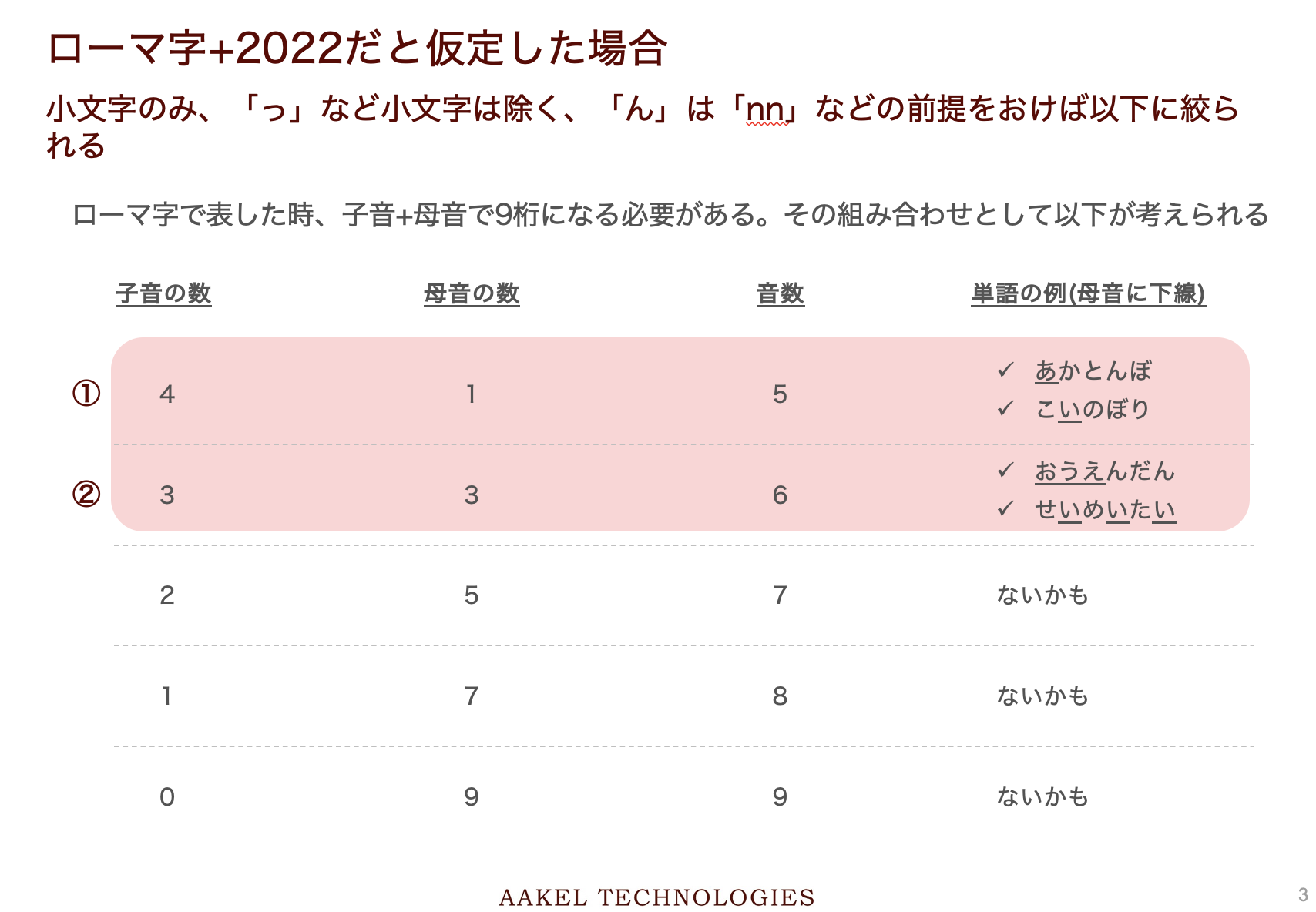
ここまでの計算では無意味な文字列を対象としています。しかしこれがそうではなく、「amagasaki」などの意味が通る文字列になっていたらどうでしょうか。もっと組み合わせは減るはずです。今回はこれを計算してみました。
ただし、以下の算出は全てのパターンを網羅していません。例えば、
・「じ」は「zi」と「ji」の表記が考えられますが、「zi」しか考慮していない
・「しゃ」など開拗音は考慮していない
などモレが存在します。
list_consonant = ['','k','s','t','n','h','m','y','r','w','g','z','d','b','p']#先頭の空文字列は母音だけの音を作るときに必要
list_vowel = ['a','i','u','e','o']
print(len(list_consonant)) #15 → 子音の選択肢は15個
print(len(list_vowel)) # 5 → 母音の選択肢は5個
for i in list_consonant:
for j in list_vowel:
print(i + j) # a i u e o ka ki ku ...

おわりに
パスワードにあたりがつけられると、組み合わせ総数を大幅に減らすことが可能であることがわかりました。パスワードに関するヒントは与えるべきではないと事例からも計算結果からもわかりました。
堅牢なパスワードの候補となるのは
・意味の通る文字列にしない
・大文字を複数個含める
・特殊文字を含める
・数字は推測されやすいものを使わない
ちなみに僕の誕生日は3月9日です。