はじめに
自分と仲間用に「Pythonではじめる機械学習」をまとめました。
本記事は特に、教師あり学習についてです。
こちらのGithubのコードをお借りしています。
言語はPythonですのでお忘れなきように。
超基本からいきますので困らないと思います。基本的にwindowsでやってます。
機械学習には大きく分けて教師あり学習と教師なし学習がある。

(引用元:https://mining-activity.com/unsupervised_learning/)
教師なし学習は次元圧縮法やクラスタリング法、教師あり学習は分類法や回帰法に大別されることがこの図よりわかります。
必要な道具を用意しよう
Anaconda(アナコンダ)
機械学習を使う際によく使われるディストリビューション(必要な道具が最初からすべて入っている嬉しいやつ)というもの。
具体的には...
・NumPy(ナムパイ)
・SciPy(サイパイ)
・matplotlib(マットプロットリブ)
・IPython(アイパイソン)
・Jupyter Notebook(ジュピターノートブック)
・scikit-learn(サイキットラーン)
が含まれる。
windowsでのインストールはこちら
Macでのインストールはこちら
Macでは「Anaconda-Navigator」という可愛いUIのもので開発できます!
インストールしたら、windowsであればAnaconda Promptから起動できます!


こんなウィンドウが表示されてpythonと打ち込むとpythonが起動できます。
必要なライブラリ
Jupyter Notebook
コマンドプロンプトでガツガツコードを書いていても仕方ないので、より見やすく、使いやすくするのがJupyter Notebookです。
Anacondaに最初から入っているので、特別インストールする必要はありません!
使い方はシンプルで、Anaconda Promptでjupyter notebookとするだけです。
Macではanacondaをインストールした時に自動で入ってくるアプリのAnaconda Navigatorから「notebook」をLaunch!
cdコマンドで機械学習用のフォルダに移動してからjupyter notebook!

そうすると、webブラウザがURL:localhostってやつで起動されたはずです。localhostというのは自分のPCの環境内ってことです。webブラウザだからと全世界にオープンされたわけではないのでご心配なく。
↓僕の場合すでにファイルが入っているのでこうなってます。
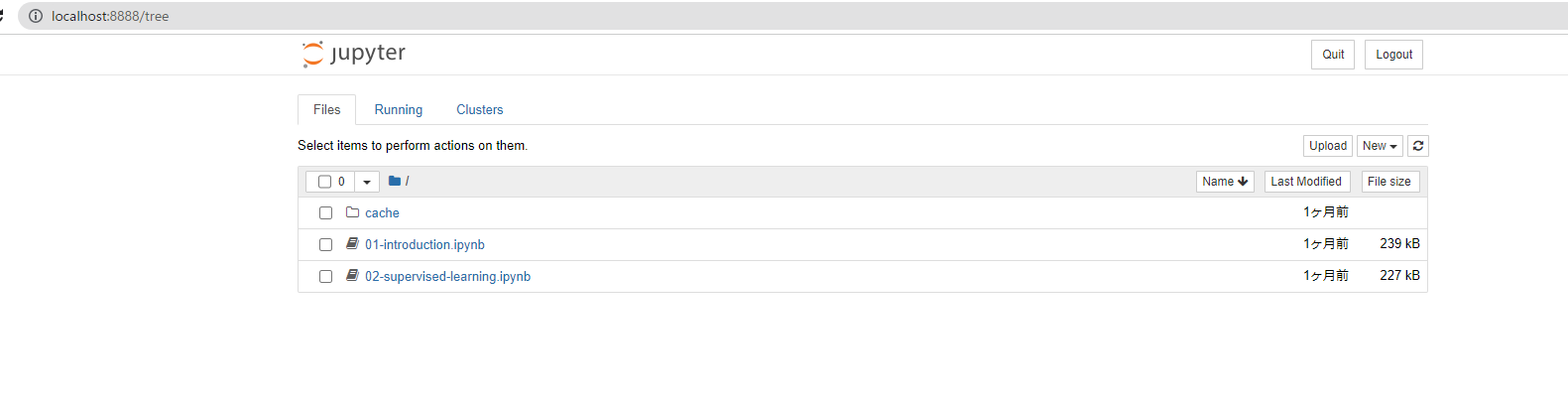
NumPy
コマンドプロンプトの四則演算だけでは対応できないので、それを補う計算用のツールです。
Anacondaに入っています。
jupyter notebookでNumpyの具体的なコードを書いてみましょうか。
右上のNewから新しいファイルを作りましょう。この時、Python3というものを選んでください。

これができたらおk。ファイル名はpracticeとでもしておきます。

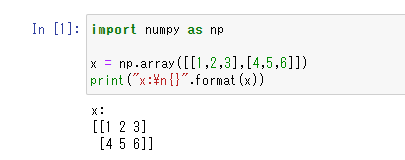
import numpy as np
x = np.array([[1,2,3],[4,5,6]])
print("x:\n{}".format(x))
コピペでも大丈夫です。Runをしましょう。

行列が出力されましたね。
いま書いてもらったNumPy配列は非常に重要なのですが、気を付けてほしいのが次の図のように配列の中に複数の配列が入っているという構造になっていることです。

SciPy
NumPy同様に高度な計算を行うためのライブラリです。これもAnacondaに入っております。
最も使うのはscipy.sparseというもので、疎行列(成分のほとんどが0)を表します。
いずれ具体的に使うときに学びましょう。
matplotlib
グラフ描画ライブラリです。これもAnacondaに入っております。
Jupyter notebookでは%matplotlib inlineか%matplotlib notebookとすることでブラウザ上に図を表示できます。
%matplotlib notebook
import matplotlib.pyplot as plt
# -10から10までを100個に区切った列を配列として生成
x = np.linspace(-10, 10, 100)
# sin関数を用いて2つ目の配列を作成
y = np.sin(x)
# plot関数は、一方の配列に対して他方の配列をプロットする
plt.plot(x, y, marker="x")

pandas
データの変換、解析用のライブラリです。データをExcelやRDB(リアルタイムデータベース)などに入出力することができます。
次の例ではPython用語でいうところの辞書をつかって配列を構成しています。
Pythonのリスト、辞書などが怪しい人はこちら
import pandas as pd
# 人を表すデータセットを作る。
data = {'Name': ["John", "Anna", "Peter", "Linda"],
'Location' : ["New York", "Paris", "Berlin", "London"],
'Age' : [24, 13, 53, 33]
}
data_pandas = pd.DataFrame(data)
# pandas.DataFrameを用いると綺麗に表示できる
display(data_pandas)
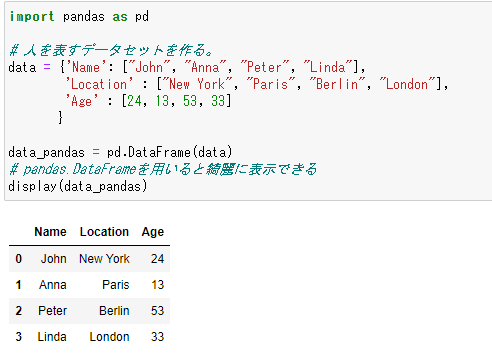
このテーブルに対していろいろな操作をすることができる。
例えば、必要な情報だけを抽出したいなら次のようにする。
# Ageが30を超えるすべての行を取り出す
display(data_pandas[data_pandas.Age > 30])

mglearn
「Pythonではじめる機械学習」にはじめから付いている本書で学習する人に向けたライブラリです。機械学習用のデータがいろいろと入っていて、後々使うこともあるかもしれません。
Anaconda promptでpip install mglearnとしてインストールしておきましょう。
scikit-learn
機械学習をやる中で一番大切なライブラリです。サンプルデータが揃っており、教師あり、なし学習用のアルゴリズムが始めからすべて入っています。これを用いて機械学習を進めていきます。
Anacondaに始めから入っているので心配はいりません。具体的な使い方は次回見ていきましょう。
以上が、とりあえず必要な道具たちです。Part2以降、これからコードを実行するときは明示していなくても次のようにライブラリをインストールしていると思って下さい。(必要であれば、Jupyter Notebookのファイルの一番上に書くことをおすすめします。)
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import mglearn
from IPython.display import display
import sklearn
from sklearn.datasets import make_blobs