Anacondaにて tesseract-ocr を試したメモ。
環境
Anacondaを使って、Opencvも入れている前提だが、
TesseractというオープンソースのOCRエンジンと、それをPythonで使えるようにしたライブラリであるpytesseractを使用します。
それぞれAnaconda.orgで調べたコマンドにて仮想環境にインストールする
conda install -c conda-forge pytesseract
すぐにインストールできた。
conda install -c conda-forge tesseract
試したが、tesseractはインストール完了できず、exeでインストールする方法に作戦変更。手順は以下。
1.download,install
https://github.com/UB-Mannheim/tesseract/wiki
からtesseractのセットアップ.exeファイルを直接downloadしてインストールする方法に変更。
tesseract-ocr-w64-setup-5.3.3.20231005.exe (64 bit)をDownloadして、ガイダンス通りに言語を選択した上、インストール。
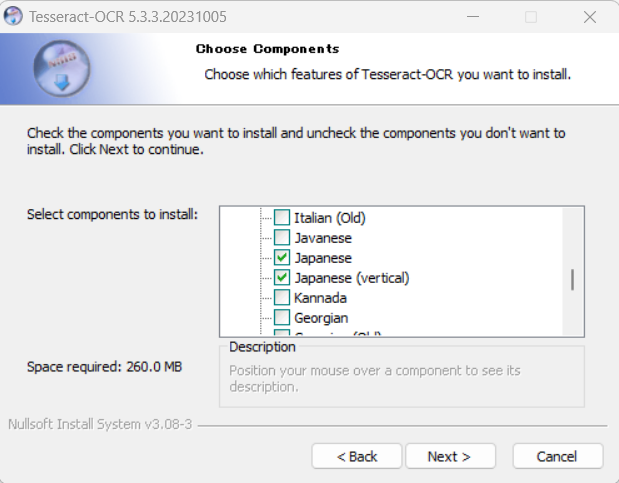
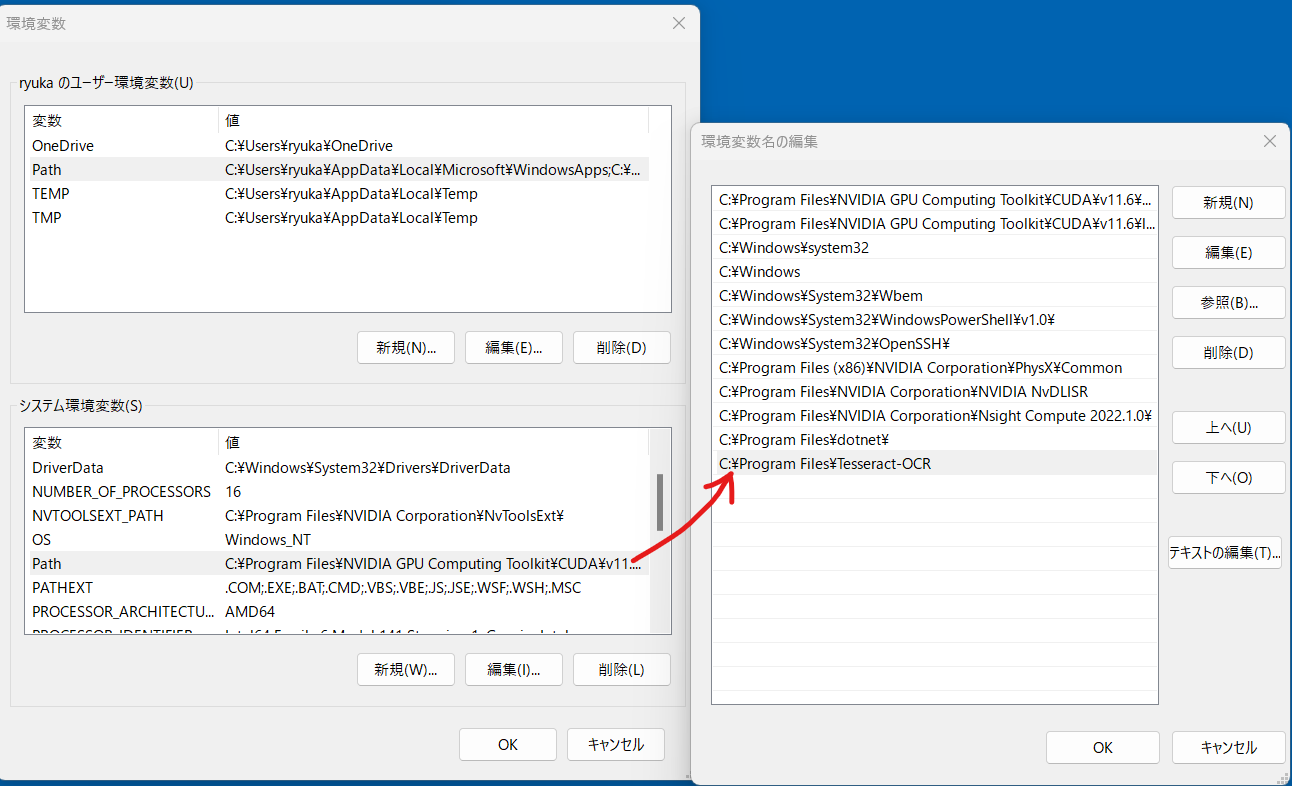
2.環境変数を設定
pathの中に"C:\Program Files\Tesseract-OCR"を追加する
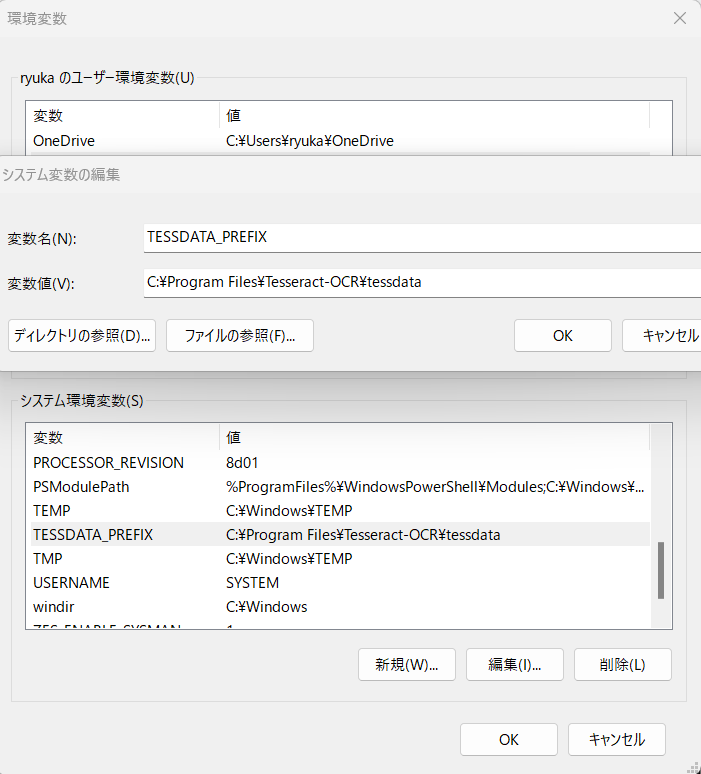
TESSDATA_PREFIX変数を新規作り、"C:\Program Files\Tesseract-OCR\tessdata"を追加しておく。
3.環境変数設定できたかを試す。AnacondaでTesseractを認識できたかをチェック。
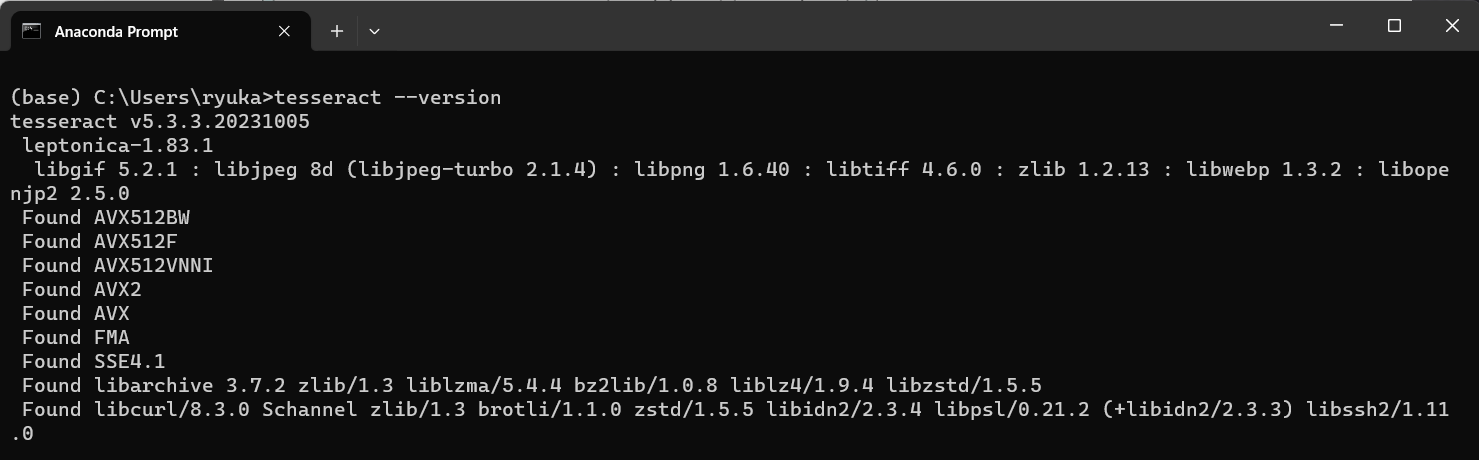
このようにVersionがちゃんと表示できたらOK。そうじゃなければ、内部コマンドじゃないと弾かれる。
4.最後、pytesseractのpytesseract.py中身を変える。tesseract_cmd = ‘tesseract’,をtesseract_cmd =r’C:\Program Files\Tesseract-OCR\tesseract.exe’に直せば、importできるようになるはず。

実行してみる
import sys
import pytesseract
from PIL import Image
# 画像を読み込む
image = Image.open('C:/Users/ryuka/Documents/test.png')
# 画像からテキストを探して取り出す、langは英語、日本語などのパラメータ設定できる
text = pytesseract.image_to_string(image, lang='eng')
print(text)
使う画像
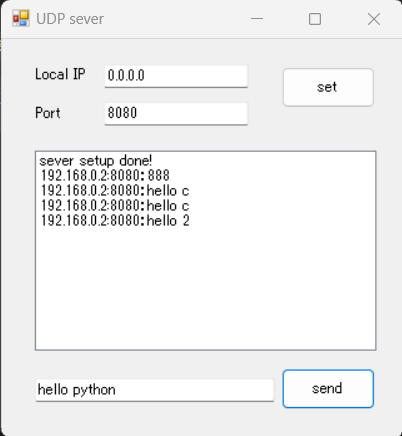
実行結果
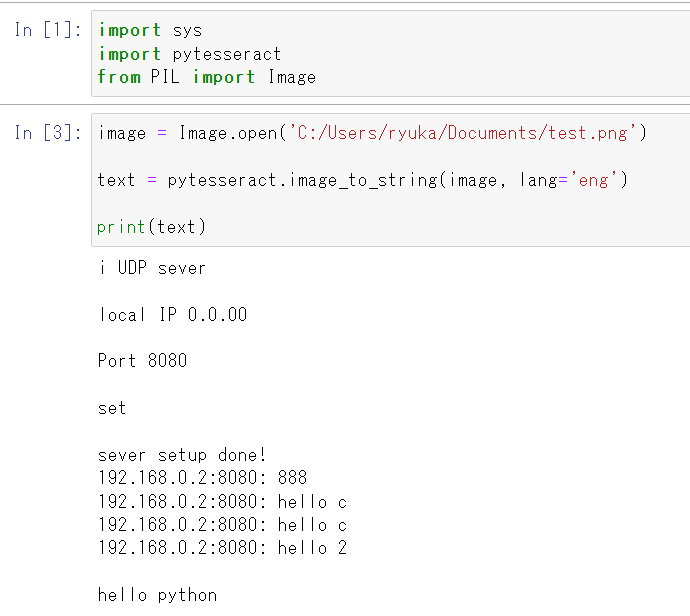
完璧ではないが、9割以上の識別はできた感じ。
memo:荒い画像で試した結果、sesseractよりもeasyOCRの方がよりよい結果が得られましたので、インストールも扱いもeasyOCRの方がおすすめ。