はじめに
Order-Embeddings of Images And Languageという論文を読んだのでまとめていきます。
1. 対象とするトピック
1.1 キーワード
Order-Embeddings 論文
1.2 経緯
キャプション生成のように、CVとNLPを組み合わせた研究が現在注目されています。キャプション生成では画像の抽象化でキャプションを生成しています。このように入力を抽象化したものが出力となる関係は他にも存在します。例としては、 words (単語) と hypernymy (上位語) の関係や、sentences (文章) と textual entailment (含意関係) の関係が挙げられます。これらは下図のような意味論的階層構造の例だと言っています。
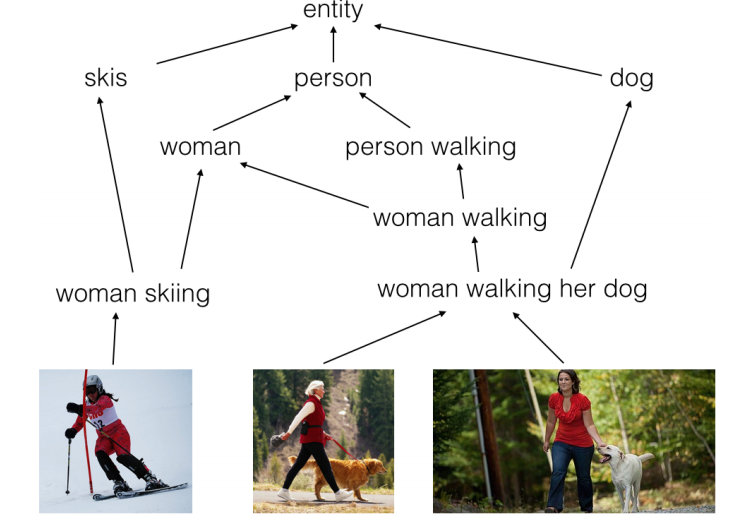
この意味論的階層構造をモデル化することがこの論文の目標となっています。なお、特徴量空間に埋め込む点は慣習に倣っています。先行研究では似ている物体同士の距離が近くなるように埋め込まれています。つまり、空間上では距離が保存されています。一方でこの論文では埋め込みの際に、上述した階層構造が保存されています。以降はこの埋め込みをorder-embeddingと呼称します。
2. 問題定義
上記の目標達成のために、まずは汎用的な問題を定義しています。それがpartial order completionです。基本的には識別を行う問題となっています。まず、正例と負例を与えます。その後新たに与えられたデータが正負どちらであるか識別します。具体的な定義は以下の通りです。
正例: $P = {(u, v)} \subset (X, \preceq_X)$
ただし、$(X, \preceq_X)$は半順序集合
負例: $N$
ただし、$N$は順序のない集合
データ: $(u', v')$
2. 理論
2.1 Learning Order-Embeddings
以下のような関数 (Order-Embedding) を学習することが上記の問題への解決策となっています。
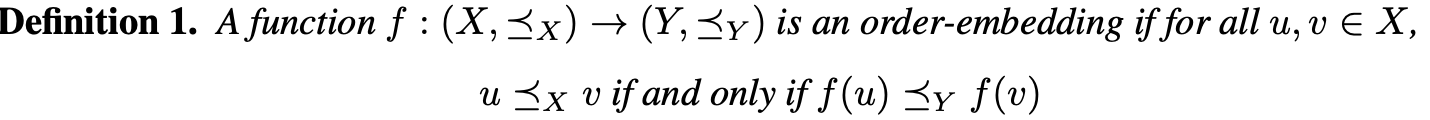
この定義に基づき、
Y, \preceq_Y, f
をどのようなものに決定すればいいかを考察していきます。
2.2 埋め込む空間の決定
空間を決定するために、まず空間が満たすべき性質を考察しています。その性質は以下の2つです。
- 抽象化: catとdogを抽象化することでmammalという単語を得られる。
- 構成: catとdogからdog chasing catという文を構成できる。
この考察に基づき、以下のように空間を決定しています。
$\preceq_Y$上では抽象化と構成が可能である。
$\preceq_Y$には全要素の上位語となる語が存在する。
勾配法での便宜上、$Y$は連続である。
上記3つの条件を満たすものとして、以下の条件(reversed product order)が定義されます。
 ただし、x,yは非負なベクトルです。
上記の条件から、より小さい値をもつほど、順序構造において上位に位置することがわかります。またこの条件から、埋め込みが単語の埋め込みでなく集合の埋め込みとも考えられます。そして、ある単語の意味はその単語の上位語全ての意味を統合したものと考えられます。
ただし、x,yは非負なベクトルです。
上記の条件から、より小さい値をもつほど、順序構造において上位に位置することがわかります。またこの条件から、埋め込みが単語の埋め込みでなく集合の埋め込みとも考えられます。そして、ある単語の意味はその単語の上位語全ての意味を統合したものと考えられます。
2.3 関数の決定
次に関数を決定します。ただし、関数についての制約が厳しいために直接求めることは困難とされています。そのため、関数を近似的に求めています。近似方法としては、損失を最小化するというお馴染みの手法を利用します。順序構造に関する損失の定義は以下の通りです。
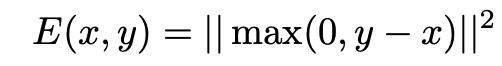
なお、上記の損失の定義から以下の関係がわかります。
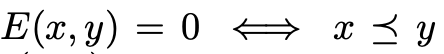
実際に学習する際は正例、負例の集合から以下の損失を定義しています。
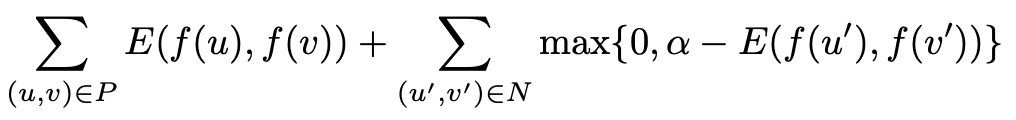
なお、αはマージンです。
3. 各タスク・実験
前節で紹介した一般的な手法を以下の3つのタスクに適用し、実験しています。
Hypernym PredictionCaption-Image RetrievalTextual Entailment / Natural Language Inference
今回は1について記載します。
3.1 Hypernym Prediction
WordNetにおけるhypernym pairsを予測することでモデルの性能を評価します。なお、hypernym pairsとは2つの単語の組みのうち、前者が後者の具体例になっている組みを指します。例: (woman, person)
なお、WordNetのイメージは以下の通りです。
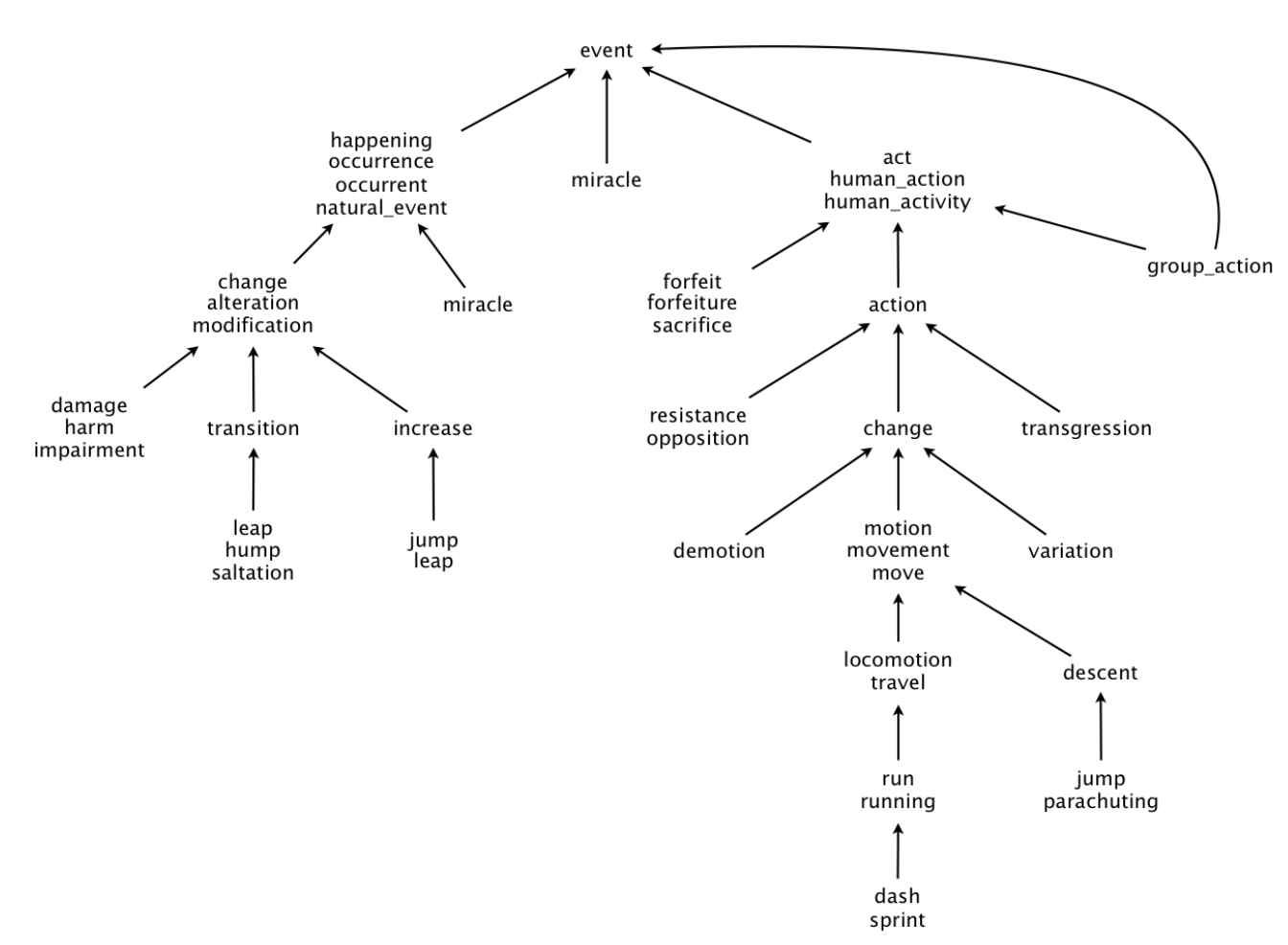
学習においては[先行研究] (https://nlp.stanford.edu/pubs/SocherChenManningNg_NIPS2013.pdf)の損失関数のみを変更しています。
3.1.1 損失関数
損失関数は以下の式で定義されます。
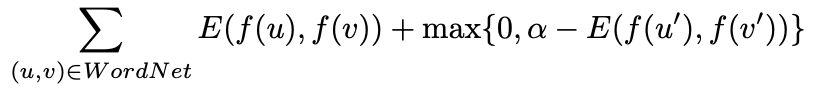
3.1.2 データセット
WordNetの推移閉包から取得可能な838073個のエッジがデータセットです。ここから、4000個のエッジをテスト用にランダムに選択し、それら以外の4000個のエッジを学習に用いています。
3.1.3 実験結果
以下のようになっています。

他の手法よりもaccuracyが優れています。
参考文献
- Ivan Vendrov, Ryan Kiros, Sanja Fidler, Raquel Urtasun (2016). Order-Embeddings of Images And Language, https://arxiv.org/pdf/1511.06361.pdf
- mmisono. 論文輪読: Order-Embeddings of Images and Language, https://www.slideshare.net/mmisono/orderembeddings-of-images-and-language
- WordNet, https://wordnet.princeton.edu/
- Socher, Richard, Chen, Danqi, Manning, Christopher D, and Ng, Andrew (2013). Reasoning with neural
tensor networks for knowledge base completion, https://nlp.stanford.edu/pubs/SocherChenManningNg_NIPS2013.pdf