はじめに
Field-aware Probabilistic Embedding Neural Network for CTR Predictionという論文を読んだのでまとめていきます。
1. 対象とするトピック
1.1 キーワード
$CTR Prediction; Recommender Systems; Deep Neural Network$ 論文
1.2 Abstract
For Click-Through Rate (CTR) prediction, Field-aware Factorization Machines (FFM) have exhibited great effectiveness by considering field information. However, it is also observed that FFM suffers from the overfitting problem in many practical scenarios. In this paper, we propose a Field-aware Probabilistic Embedding Neural Network (FPENN) model with both good generalization ability and high accuracy. FPENN estimates the probability distribution of the
field-aware embedding rather than using the single point estimation (the maximum a posteriori estimation) to prevent overfitting. Both low-order and high-order feature interactions are considered to improve the accuracy. FPENN consists of three components, i.e., FPE component, Quadratic component and Deep component. FPE component outputs probabilistic embedding to the other two components, where various confidence levels for feature embeddings are incorporated to enhance the robustness and the accuracy. Quadratic component is designed for extracting low-order feature interactions, while Deep component aims at capturing high-order feature interactions. Experiments are conducted on two benchmark datasets, Avazu and Criteo. The results confirm that our model alleviates the overfitting problem while having a higher accuracy.
2. Theory
2.1 Problem Formulation
$i$番目のデータがクリックされる確率を予測します。

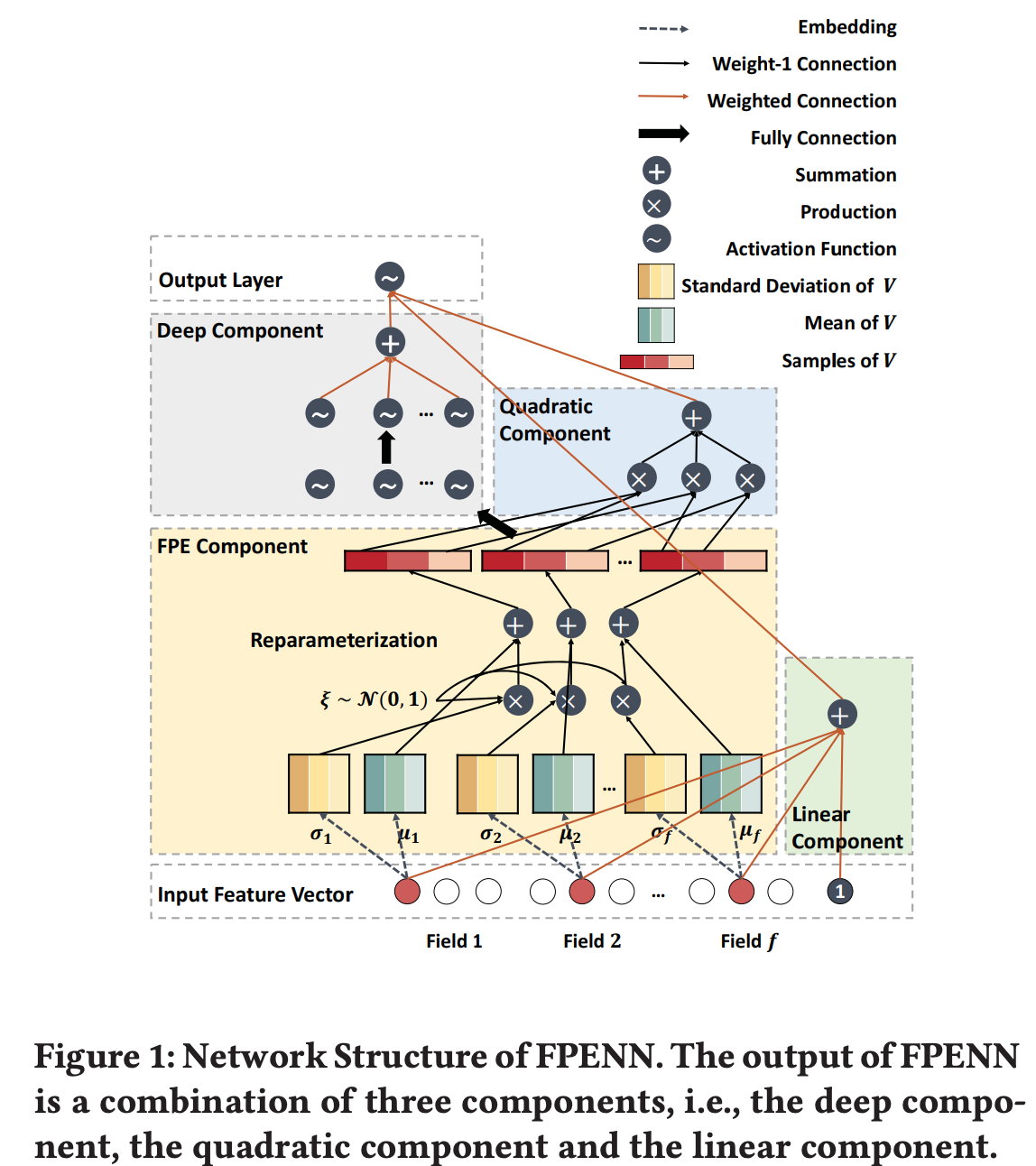
2.2 Architecture of FPENN
下図のように
- $FPE Component:$ 入力されたスパースな特徴量ベクトルを密な潜在ベクトルに埋め込む
- $Linear Component:$ 線形な関係を学習
- $Quadratic Component:$ 2次の関係を学習
- $Deep Component:$ 高次の関係を学習
します。そして、以下の式で定義される変数$z$
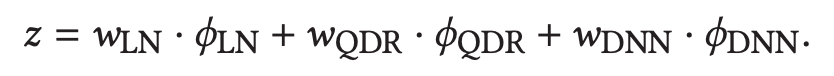
を用いて$y$を予測します。
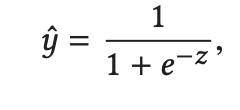
2.3 FPE Component
上述したように、FPE Componentはデータを埋め込みます。具体的には、$x \in R^d$の特徴量を$f$個のfieldにグループ化します。そして、$i (i = 1,...,d)$番目の特徴量を行列$V_i \in R^{(f-1) \times k}$に埋め込みます。ただし、$k$は潜在ベクトルの次元数です、最終的には$d \times (f - 1) \times k$次元のテンソル$V$を出力します。
2.3.1 Training
一般の確率分布での埋め込みを直接実行して場合は、サンプリングを通じたback-propagationを行うことができません。そこで連続ランダム変数を決定項と基本的な確率分布の2つに分解するreparameterization trickを用います。これを用いることで学習が可能な要素とサンプリングで得た要素を用いて埋め込みが行えます。
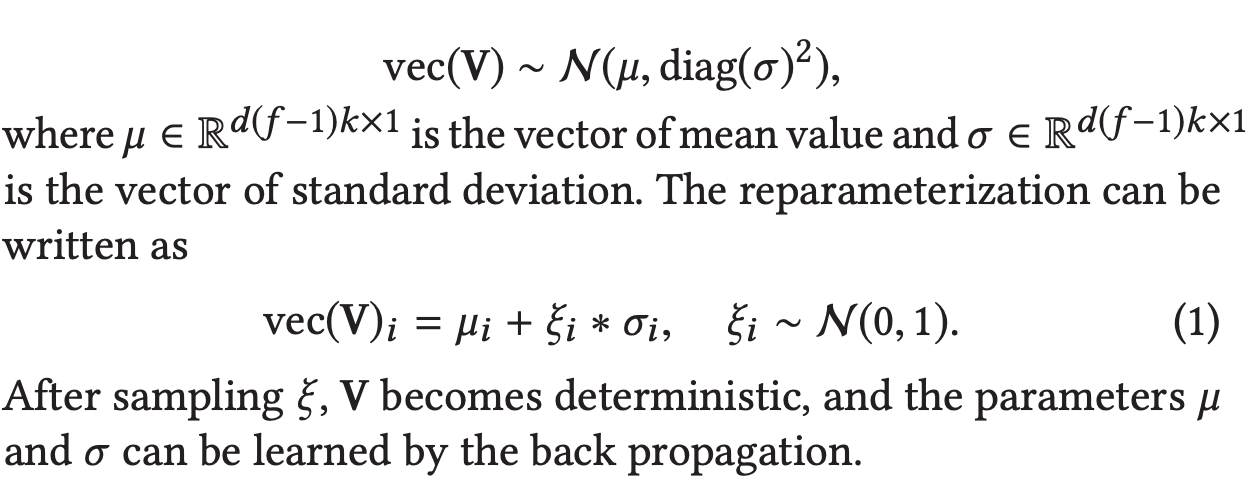
2.2.2 Testing
テストではサンプリングを行います。その際に、
- 分散の情報を利用する
- 過学習を防ぐ
ために以下二つの手法を提案しています。
2.2.2.1 TS-strategy
Thompson Samplingを元に、学習して得た分布からサンプルを行います。
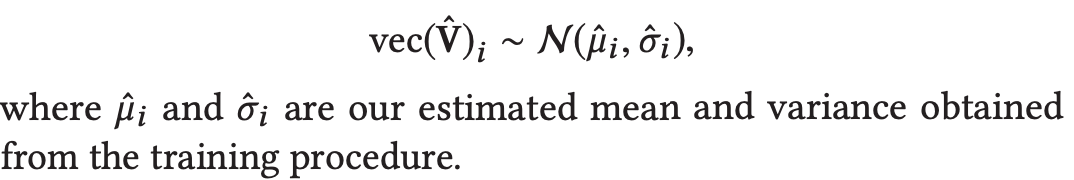
2.2.2.2 UCB-strategy
Upper Confidence Boundを用いて平均と分散のバランスを取ります。その結果、suboptimal valueを回避します。
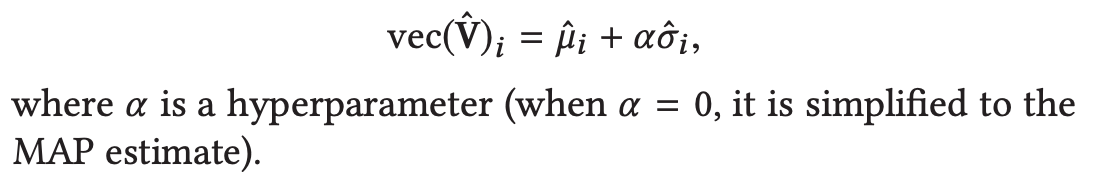
3. Experiments
3.1 Datasets
- Avazu
- Criteo
3.2 Experimental Results
3.2.1 Generalization Ability
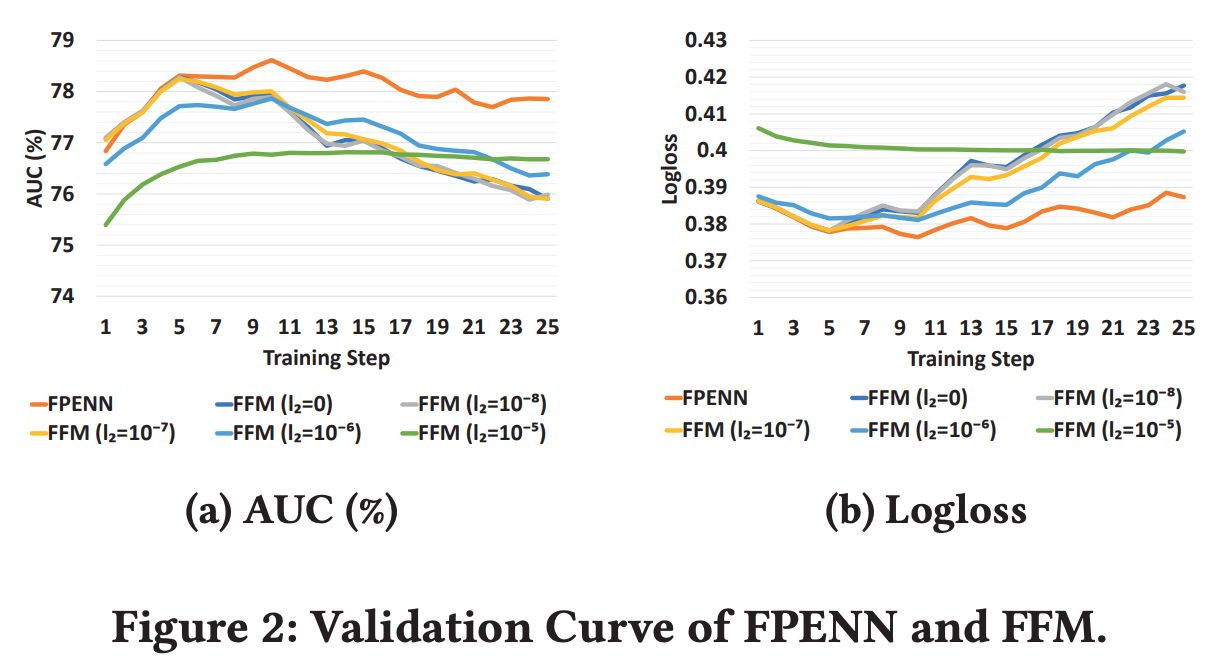
- Generalization measures the ability to predict the previously unseen data.
- We can see that the performance of our method (FPENN) drops very little as we increase training steps, while FFM under different settings drop significantly
- The probability assumption can be regarded as adding regularization to the model. As a result, the validation curve is more stable.
3.2.2 Accuracy
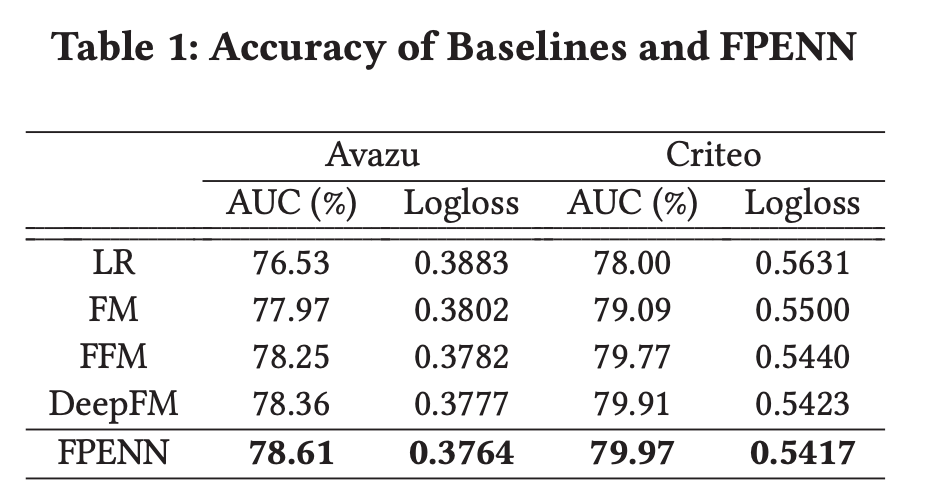
- Compared with the second best model, FPENN gives a rise of 0.32% and 0.11% in terms of AUC.
- The reason is that our model captures both low-order and high-order feature interactions with field information.
- Moreover, the model estimates different confidence levels for the learned parameters, where parameters with low confidence levels can be corrected by combining the mean and the variance information of the distribution.
References
- Weiwen Liu, Ruiming Tang, Jiajin Li, Jinkai Yu, Huifeng Guo, Xiuqiang He, Shengyu Zhang (2018). Field-aware Probabilistic Embedding Neural Network for CTR Prediction, https://dl.acm.org/doi/10.1145/3240323.3240396